
【Python】Python入门-列表初相识
公众号:尤而小屋
作者:Peter
编辑:Peter
在之前的文章中,我们已经介绍了Python中的两种常见数据类型:字符串和数字。本文中介绍的是Python中极其重要的数据类型:列表。
在Python中,列表用一个方括号[]表示;括号里面可以是数字,字符串,布尔值(True或者False),甚至还可以嵌套列表等不同的数据类型。列表是有序的数据类型。
思维导图
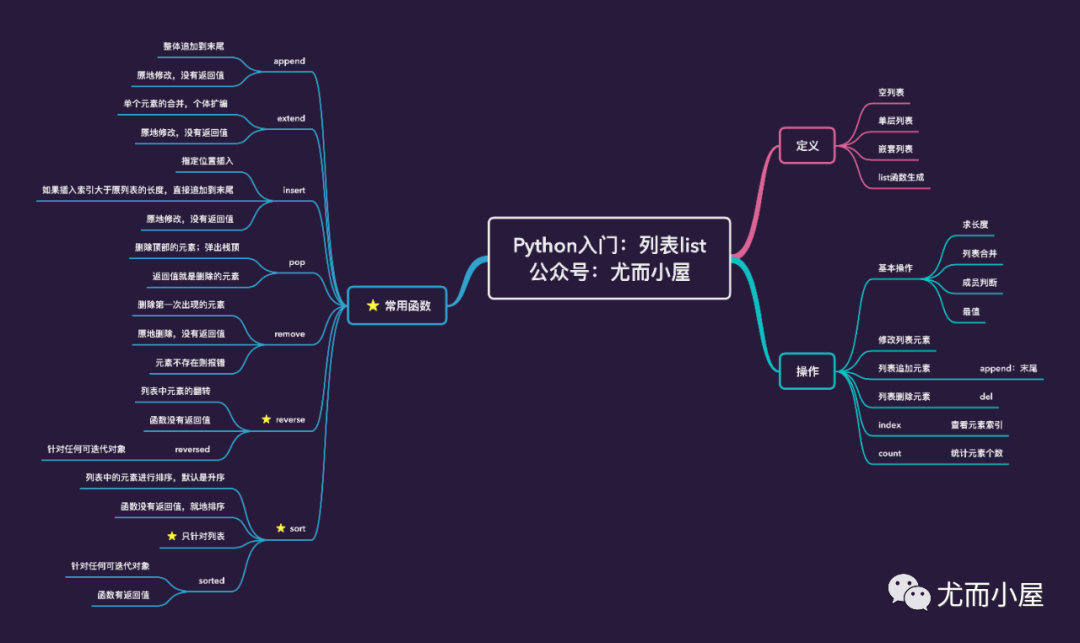
列表定义
列表的定义有多种方式:
空列表
a = [] # 定义一个空列表
a
[]
type(a) # 查看对象的类型
list
单层列表
b = [1,2,3]
b
[1, 2, 3]
type(b)
list
c = [1,2,"python"]
c
[1, 2, 'python']
type(c)
list
d = [True,True,False]
d
[True, True, False]
type(d)
list
嵌套列表
e = [1,2,[3,4],"python"]
e
[1, 2, [3, 4], 'python']
type(e)
list
通过布尔函数bool来判断一个对象是真还是假:
bool(a) # 空列表
False
bool(c) # 非空列表
True
list函数生成
list("1234")
['1', '2', '3', '4']
小结:从上面的多个例子,我们可以看到python列表中的数据类型是多样的,从数字、字符串到布尔类型,再到嵌套的列表,都是装的下的
操作
列表是Python的重要数据类型,其操作也是多样化的。
基本操作
# 1、求长度
b
[1, 2, 3]
len(b)
3
# 2、连接两个列表
b + c
[1, 2, 3, 1, 2, 'python']
c + d
[1, 2, 'python', True, True, False]
相当于是将两个列表的内容合并之后放在一个大列表中
# 3、成员判断in
f = ["python","java","php","html"]
f
['python', 'java', 'php', 'html']
"python" in f # python这个元素是否在列表f中,当然是在
True
"html" in f
True
"go" in f # go不在列表f
False
# 4、列表重复
c * 3
[1, 2, 'python', 1, 2, 'python', 1, 2, 'python']
b * 2
[1, 2, 3, 1, 2, 3]
# 5、列表求最值:根据列表中元素的字典的长度来比较
max(f)
'python'
f列表中元素的第一个字母p是最大的。当第一个字母相同比较第二个字母,y大于h;比较的是两个字母的ASCII码大小。
f
['python', 'java', 'php', 'html']
max(b)
3
min(f)
'html'
修改列表元素
之前讲过的数据类型,字符串和数值型是不能修改的,但是列表却是可以进行修改的,能够实现增删改的操作
f
['python', 'java', 'php', 'html']
len(f) # 长度为4
4
f[1]
'java'
f[1] = "c++" # 将索引为1的元素修改成c++
f
['python', 'c++', 'php', 'html']
列表追加元素
往列表中追加元素使用的是append方法;追加到原列表的末尾
f.append("javascript") # 自动追加到末尾
f
['python', 'c++', 'php', 'html', 'javascript']
列表删除元素
列表中还可以实现元素的删除,使用的是del方法
del f[1]
f # c++被删除了
['python', 'php', 'html', 'javascript']
列表常用函数
列表中有几个常用的函数,需要我们掌握:
append:将整体追加到列表的末尾 extend:列表中的每个元素进行合并,组成一个大的列表 index:查看元素的索引 insert:指定位置插入元素 pop:删除顶部的元素(弹出栈顶元素) remove:删除第一次出现的元素;元素不存在则会报错 reverse:将列表中元素的顺序颠倒过来;类比reversed sort:列表元素的排序;类比sorted
append
往列表的末尾追加元素,返回没有返回值;直接原地修改
f
['python', 'php', 'html', 'javascript']
f.append("java") # 追加到末尾
f
['python', 'php', 'html', 'javascript', 'java']
extend
列表中每个元素的个体追加;原地修改,没有返回值
print(c)
print(f)
[1, 2, 'python']
['python', 'php', 'html', 'javascript', 'java']
c.extend(f)
c # 实现列表c的整体扩张
[1, 2, 'python', 'python', 'php', 'html', 'javascript', 'java']
c.extend("go")
c
[1, 2, 'python', 'python', 'php', 'html', 'javascript', 'java', 'g', 'o']
如果上字符串元素,会自动的进行拆解之后再进行扩张追加
c.extend(["go"]) # 只追加列表的一个元素
c
[1, 2, 'python', 'python', 'php', 'html', 'javascript', 'java', 'g', 'o', 'go']
c.extend(3) # 数值型数据不能进行extend,因为它是不可迭代的(iterable)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-45-35eb2b66cb19> in <module>
----> 1 c.extend(3) # 数值型数据不能进行extend,因为它是不可迭代的(iterable)
TypeError: 'int' object is not iterable
如何查看Python中的数据类型是否可迭代?使用hasattr()方法:
hasattr(c,"__iter__") # 列表可迭代
True
hasattr("learn python","__iter__") # 字符串可迭代
True
hasattr(3,"__iter__") # 数值型数据不可迭代
False
如何查看帮助文档?使用help方法
help(list.extend)
Help on method_descriptor:
extend(self, iterable, /)
Extend list by appending elements from the iterable.
help(list.append)
Help on method_descriptor:
append(self, object, /)
Append object to the end of the list.
在上面的例子中我们发现extend和append执行之后,是没有任何返回值的,它们是在原数据上直接添加的。
lst1 = ["python","java","go"]
lst2 = [1,2,3]
id(lst1) # 查看内存地址
4452149200
lst3 = lst1.extend(lst2)
print(lst3) # 赋值的结果仍为None
None
lst1 # 其实lst1已经变化了
['python', 'java', 'go', 1, 2, 3]
id(lst1) # 内存地址并没改变
4452149200
像这种修改数据之后,内存地址仍然没有变化的操作,我们称之为原地修改,不影响对象的内存地址
二者区别
append:整体的追加 extend:个体化扩编
f
['python', 'php', 'html', 'javascript', 'java']
g = ["go","c++"]
f.append(g) # 追加整体
f
['python', 'php', 'html', 'javascript', 'java', ['go', 'c++']]
f1 = ['python', 'php', 'html', 'javascript', 'java'] # 和之前f相同
f1.extend(g) # 每个元素的追加
f1
['python', 'php', 'html', 'javascript', 'java', 'go', 'c++']
count
统计列表中每个元素出现的次数
f1.count("python")
1
f1.count("go")
1
f2 = [1,2,3,3,2,3,2,2,1]
f2
[1, 2, 3, 3, 2, 3, 2, 2, 1]
f2.count(3)
3
f2.count(4) # 元素不存在则为0,而不是报错
0
Python中有个库能够直接统计列表中每个元素的个数:Count
from collections import Counter
count = Counter(f2)
count
Counter({1: 2, 2: 4, 3: 3})
index
元素第一次出现的索引位置
f2
[1, 2, 3, 3, 2, 3, 2, 2, 1]
f2.index(1) # 1第一次出现的索引为0
0
f2.index(3) # 3第一次出现的索引为2
2
f2.index(4) # 元素不存在则会报错
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-71-568e9ea7baf1> in <module>
----> 1 f2.index(4) # 元素不存在则会报错
ValueError: 4 is not in list
insert
在指定的位置插入数据。append和extend都是在末尾添加。list.insert(i,"待插入元素"),表示在索引i之前插入元素
lst1 # 查看lst1列表
['python', 'java', 'go', 1, 2, 3]
lst1.insert(1,"c++") # 1号索引位置插入c++
同样是没有返回值,说明是原地修改,lst1已经发生了变化,但是内存地址不变。
lst1
['python', 'c++', 'java', 'go', 1, 2, 3]
len(lst1) # 长度为7
7
lst1.insert(9, "html")
lst1
['python', 'c++', 'java', 'go', 1, 2, 3, 'html']
上面的例子我们观察到,虽然lst1的长度为7,但是在9号索引之前仍是可以插入成功的
lst4 = ["go","python"] # 长度为2
lst4.insert(10,"java")
lst4 # 仍然是可以插入成功
['go', 'python', 'java']
说明当插入的索大于原列表的长度时候,会直接追加到末尾
小结:insert方法也是没有返回值的,原地修改
pop
pop方法表示的是删除顶部的元素;而且运行之后返回的就是该元素
lst1
['python', 'c++', 'java', 'go', 1, 2, 3, 'html']
lst1.pop()
'html'
通过运行结果发现:
最后面的元素被删除了 函数运行后返回的是删除的元素
lst1 # 已经没有了html元素
['python', 'c++', 'java', 'go', 1, 2, 3]
remove
删除列表中的第一次出现的某个元素,也就是说如果某个元素在列表中重复出现,只删除第一个
原地删除数据,没有返回值 重复元素删除第一个
lst5 = ["python","go","java","python","c++"]
lst5
['python', 'go', 'java', 'python', 'c++']
lst5.remove("python") # 原地删除,没有返回值
lst5 # 第一个python已经被删除了
['go', 'java', 'python', 'c++']
lst5.remove("java")
lst5 # java被删除了
['go', 'python', 'c++']
如果元素不存在呢?运行结果直接报错:
lst5.remove("html")
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-88-957c479875d4> in <module>
----> 1 lst5.remove("html")
ValueError: list.remove(x): x not in list
reverse
将列表中的元素进行翻转,函数没有返回值
lst5
['go', 'python', 'c++']
lst5.reverse() # 没有返回值
lst5 # 列表已经翻转
['c++', 'python', 'go']
对比下reversed(list_object)函数,该函数返回的是翻转后的可迭代对象:
reversed(lst5) # 翻转的可迭代对象
<list_reverseiterator at 0x109689490>
实施翻转之后是一个可迭代对象,我们需要使用list函数进行展开:
list(reversed(lst5)) # lst5再次翻转
['go', 'python', 'c++']
sort
对列表中的元素进行排序,只接受对列表的排序,中文官网学习地址:https://docs.python.org/zh-cn/3/howto/sorting.html
list.sort(key=None, reverse=False)
key : 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。 reverse : 排序规则,reverse = True 降序, reverse = False 升序(默认)。
lst6 = ["python","javascript","go","java","html","c++"]
lst6
['python', 'javascript', 'go', 'java', 'html', 'c++']
1、默认使用情况如下例子:
# 默认
lst6.sort()
lst6
['c++', 'go', 'html', 'java', 'javascript', 'python']
从第一个字母的ASCII码开始比较,如果相同就比较下一个字母;默认是升序
ord("c") # 查看c的ASCII码值
99
chr(99)
'c'
chr(1000) # 每个数值都有对应的元素
'Ϩ'
chr(400)
'Ɛ'
2、参数reverse的使用:
lst6
['c++', 'go', 'html', 'java', 'javascript', 'python']
lst6.sort(reverse=True)
lst6 # 改成了降序
['python', 'javascript', 'java', 'html', 'go', 'c++']
3、参数key的使用
student = ["xiaoming","xiaozhang","Peter","Mike","Tom","Jimmy"] # 定义新列表
student
['xiaoming', 'xiaozhang', 'Peter', 'Mike', 'Tom', 'Jimmy']
student.sort(key=len)
student
['Tom', 'Mike', 'Peter', 'Jimmy', 'xiaoming', 'xiaozhang']
根据传入参数key的len函数,求解student列表中每个原始的长度,升序排列
student.sort(key=str.lower) # 列表中的元素全部变成小写开头,再进行比较
student
['Jimmy', 'Mike', 'Peter', 'Tom', 'xiaoming', 'xiaozhang']
根据首字母的顺序进行比较,升序排列
ord("j") # str.lower函数已经全部转成了小写
106
ord("m")
109
ord("p") # 其余类推
112
关于另一个排序sorted函数,最大的不同点是:它对任何可迭代对象都可以进行排序,不仅仅是列表;同时,函数有返回值
针对任何可迭代对象 有返回值
student
['Jimmy', 'Mike', 'Peter', 'Tom', 'xiaoming', 'xiaozhang']
sorted(student) # 默认按照字母的ASCII码大小来排序
['Jimmy', 'Mike', 'Peter', 'Tom', 'xiaoming', 'xiaozhang']
sorted(student,key=len)
['Tom', 'Mike', 'Jimmy', 'Peter', 'xiaoming', 'xiaozhang']
sorted(student,key=str.lower) # 字母变成小写之后再排序
['Jimmy', 'Mike', 'Peter', 'Tom', 'xiaoming', 'xiaozhang']
针对其他可迭代对象的排序,比如字符串:
strings = "I am learning python" # 定义一个字符串strings
sorted(strings.split(),key=len)
['I', 'am', 'python', 'learning']
上面代码的含义是先对字符串使用切割函数split(默认根据空格切割),对切割之后的每个字符串求长度len,升序排列得到结果
student # 原列表是一直不变化的
['Jimmy', 'Mike', 'Peter', 'Tom', 'xiaoming', 'xiaozhang']
对嵌套列表的排序过程:
lst9 = [[5,"python"],[2,"java"],[3,"c++"],[1,"javascript"]]
sorted(lst9)
[[1, 'javascript'], [2, 'java'], [3, 'c++'], [5, 'python']]
sorted(lst9,key=lambda x:len(x[1]))
[[3, 'c++'], [2, 'java'], [5, 'python'], [1, 'javascript']]
解释下上面的代码:
lambda是python的匿名函数(后面会详细介绍)x为函数的参数 匿名函数的功能是取出列表中索引为1的元素,求出长度len 根据长度升序排列,长度最短为3(c++),最长为10(javascript)
lst9 # 没有变化
[[5, 'python'], [2, 'java'], [3, 'c++'], [1, 'javascript']]
因为sorted函数有返回值,所以对原对象是不会有影响的。往期精彩回顾 本站qq群851320808,加入微信群请扫码: