
广告行业中那些趣事系列2:BERT实战NLP文本分类任务(附github源码)

摘要:上一篇广告中那些趣事系列1:广告统一兴趣建模流程,我们了解了如何为广告主圈人群以及如何刻画用户的兴趣度。要想给用户打标签,我们需要构建数据源和标签的关联,也就是item-tag。针对数量较少的app数据源我们可以使用人工打标的方式来识别,但是对于news、用户query等数量较多的数据源则需要通过机器学习模型来进行打标。实际项目中我们使用NLP中鼎鼎大名的BERT模型来进行文本分类。
通过本篇学习,小伙伴们可以迅速上手BERT模型用于文本分类任务。对数据挖掘、数据分析和自然语言处理感兴趣的小伙伴可以多多关注。
目录
01 为什么使用BERT模型做文本分类
02 项目背景
03 BERT模型实战
01 为什么使用BERT模型做文本分类
最近几年,google提出的BERT模型是NLP领域里具有里程碑意义的大作。BERT模型有两个典型的特点:效果非常好和通用性很强。
通俗的说就是能干活,能干很多活,而且活还干得好。这是非常难能可贵的。想想以前,针对不同的NLP任务大家需要使用不同的模型去解决。但是现在使用BERT你能解决非常多NLP任务,而且效果还很好。
拿《天龙八部》里面的乔峰和慕容复举例可能有点生动。慕容复虽然看了各大门派的武功秘籍,但是还是打不过会降龙十八掌的乔峰。
本篇只是BERT小试牛刀,主要从实战的角度讲解使用BERT模型来做文本分类任务。这里再打一个小小的广告,广告系列下一篇会从理论的角度讲讲使用典型的预训练+fine tuning两阶段技术的BERT模型怎么来的。讲讲NLP里面word embedding的演化历史。怎么从word2vec到ELMO、GPT,再到最后的天之骄子BERT。
可以这么说,BERT在模型创新角度并不是很大,但是它是近几年NLP领域里重大进展的集大成者。
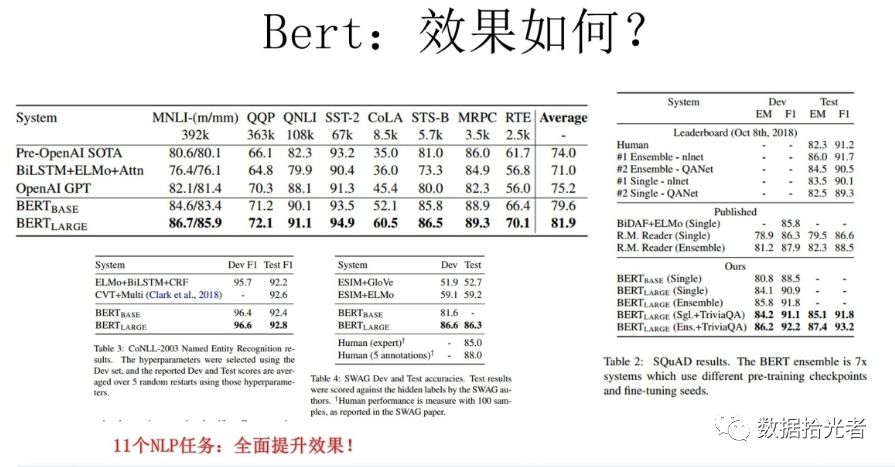
图 1 BERT效果图
讲了这么多,就是因为BERT效果好,所以我们选择BERT来做文本分类任务。
02 项目背景
我们标签团队的一个主要任务是给用户打上对应的兴趣标签,就是构建user-tag关联。通过埋点我们可以获取用户操作手机的行为,比如小A经常登录一刀传奇app,那么我们就能得到user-item的关联,item是用户操作手机的数据源,app是item的一种。
现在我们兴趣类目体系里面有个标签叫传奇游戏标签,这个标签代表一类对传奇游戏感兴趣的人群。当有一个对传奇游戏感兴趣的广告主想打广告的时候就会选择这个标签,对应的就是对传奇游戏感兴趣的一类人。
Item包括很多数据源,比如app、ad、news、query、微信小程序、site等等。之前说过因为app数据量较少,所以通过人工标注的方式来给app打标,构建item-tag的关联。
而针对news、用户query这一类数目庞大的数据源,如果全部通过人工标注的方式则费时费力,并不是很好的选择。所以一般是通过人工或者关键字匹配的方式标注一部分数据作为训练集,然后放入到机器学习模型中进行训练,最后用训练好的模型去预测新的数据,从而实现机器学习模型打标。
本篇使用NLP中的BERT模型来完成一个二分类器,来识别用户操作的news或者query是不是属于传奇游戏标签,从而判断用户是不是对传奇游戏感兴趣。
以下通过用户query进行举例。比如:
小A搜索了”成龙大哥代言的一刀传奇好玩么?”
小B搜索了”西红柿炒鸡蛋怎么做?”
小C搜索了”伽罗出装攻略”
小D搜索了”如何日入百万?”
通过这四条搜索,我们人类可以很容易的识别小A的搜索和传奇游戏标签有关,所以我们会给小A打上传奇游戏兴趣标签。而另外三个人则和传奇游戏无关,不会打上传奇游戏的标签。
现在我们需要根据用户的query,通过机器学习模型来判断用户是不是对传奇游戏标签感兴趣。这是项目背景。
通过图2可以查看如何通过query给用户打标:
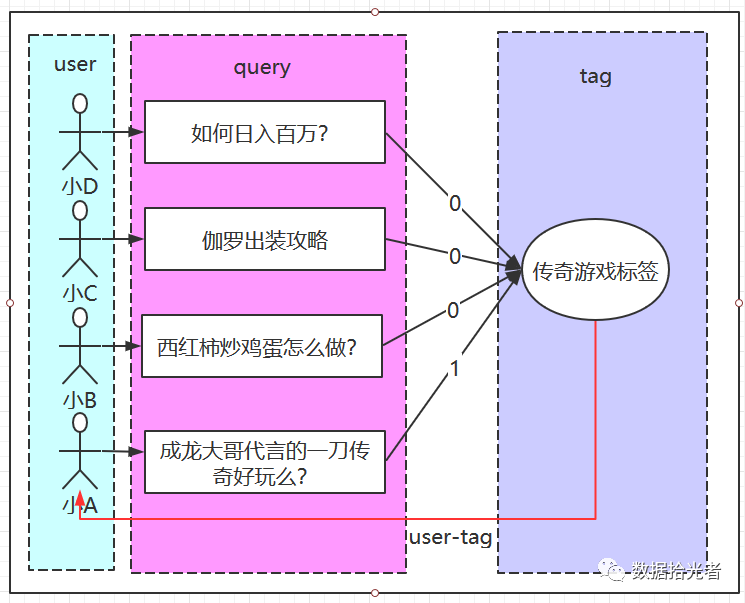
图 2 通过query给用户打标
03 BERT模型实战
通过BERT模型构建二分类器用于识别用户query是否属于传奇游戏标签。
下面是项目github链接:https://github.com/wilsonlsm006/NLP_BERT_binary-classification/。也欢迎小伙伴们多多fork,多多关注我。
项目目录结构如下:

项目主要分成四个部分:
1. bert预训练模型
这里和大家明确一个基本概念,BERT是一个预训练+fine tuning的两阶段模型。第一阶段是预训练,通过使用大量的无标注的文本从而学习到一些语言学相关的知识。而第二阶段就直接对接上层应用,你希望完成什么任务它就会不断通过微调的方式变成你想要的样子。
这里还拿传奇游戏举例。可以这么简单的理解,现在我们有个机器人小智。预训练是这样的过程,我们让机器人小智同学先看很多很多文本资料。小智同学本身不知道看这些资料是要干什么,但是就是不断的学习这些语言学知识。
而第二阶段就是fine tuning阶段,是我们明确希望小智同学做什么任务的阶段。如果我们希望小智同学来做中英翻译任务,那么我们希望输入中文,小智同学翻译为英文。我们输入“成龙大哥代言的一刀传奇好玩么?”小智同学就会翻译成对应的英文。
对应到咱们的实际项目中,如果我们希望小智同学来做文本分类任务,判断用户搜索是不是应该标注为传奇游戏标签。我们希望输入一段话,让小智同学判断这段话是不是对传奇游戏感兴趣。如果我们输入“成龙大哥代言的一刀传奇好玩么?”,小智同学就会输出感兴趣。
我们可以用BERT论文中两阶段图来生动的描述这个例子。大家不需要关注模型内部,只需要明确BERT模型任务分成两段,一个是预训练pre-training,另一个是微调fine-tuning。
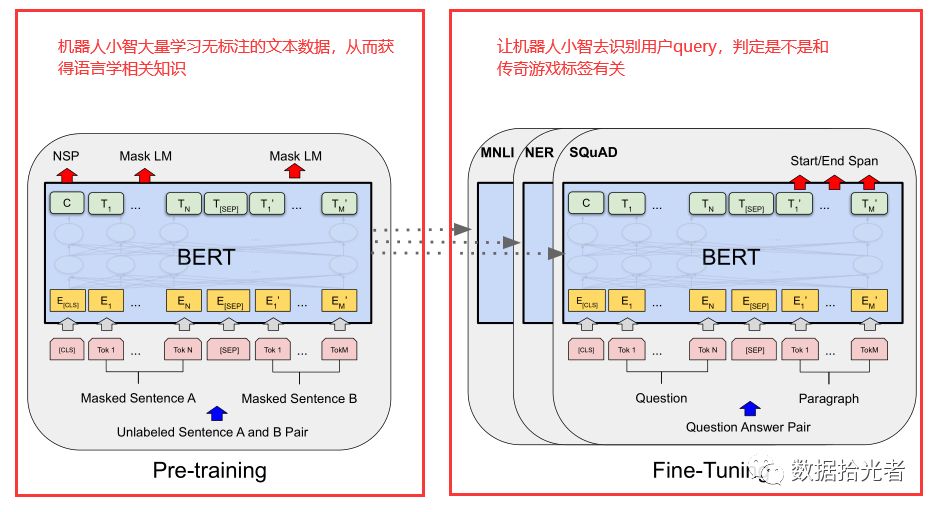
图 3 BERT 预训练+fine tuning两阶段
这是一个很简单但很实用的例子,希望大家能对BERT这种两阶段训练技术有一个非常浅显的了解。广告系列的下一面一篇我会和大家详细探讨下BERT的漫漫人生路。
而BERT预训练模型目录就是保存上面讲的第一阶段预训练学习到的知识。因为使用的无标注文本的不同,所以存在下面多个版本:

图 4 BERT预训练多个版本
https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip。下载完成之后解压,将文件中的五个部分copy到工程中bert_model目录下。
2. 训练数据集
得到BERT预训练模型之后,我们需要给模型提供一些训练数据。这个对应到刚才讲的两阶段技术中的第二段fine tuning。通过预训练阶段小智学习到了很多语言学知识。但是机器人小智并不知道到底要他做什么。而在第二阶段fine tuning的时候我们需要告诉小智希望你做一个文本分类器,判断用户搜索的一段话到底能不能打上传奇游戏标签。
如何告诉机器人小智一段话到底能不能打上传奇游戏标签?我们需要训练数据。训练数据有两个字段,第一个字段是ocr,也就是用户搜索的一句话。第二个字段是label,代表这段话是不是属于传奇游戏标签。
我们通过训练数据不断强化机器人小智来识别一句话到底是不是传奇游戏标签的能力。最终让机器人小智变成一个分类器,一个能识别用户搜索是不是应该打上传奇游戏标签的分类器。
这里小伙伴可能要问了,去哪里获取训练数据呢?
目前项目中获取训练数据主要通过人工打标或者关键字匹配的方法。人工打标就是通过人眼来判定用户搜索是不是能打上传奇游戏标签。而我们训练这个模型的最终目的也是为了让机器替代人。
关键字匹配是通过一些关键的词来识别到底应不应该打上传奇游戏标签。注意这里需要选择一些没有歧义的词来识别。如果你对传奇游戏非常了解,那么你可能会选沙巴克、麻痹戒指、战法道啥的能明确识别传奇游戏的关键词。如果选择的关键词存在歧义,很容易使训练预料不准,然后把模型带偏。比如屠龙刀这个词,虽然在传奇游戏里面有件装备叫屠龙刀,但是也容易把类似《倚天屠龙记》相关的内容误认为对传奇游戏感兴趣。
这里一定一定要注意,训练预料是否准确直接决定模型的识别能力。针对query标注的时候,也一定选择用户有明确意图的数据作为正样本。
本项目中通过csv文件来存储这些训练数据,表中有两个字段,字段顺序是ocr、label。将训练数据集划分成训练集train.csv和测试集test.csv。训练集train.csv主要用于模型训练,测试集test.csv主要用来评估模型的分类能力。训练集和测试集的比例一般为7:3,可调。这里有个小小的点需要注意,csv的格式要转化成UTF-8-BOM的格式。
3. 模型代码
模型开发语言主要使用python3,调用基于keras封装的bert模型keras_bert相关api进行开发。
通常开发阶段我们主要使用交互式jupyter notebook。开发完成后在服务器上运行或者最后上线都是整理成py脚本运行。
代码主要分成三部分:
model_train.py:这是模型训练代码。整体而言,输入的是训练集,对应项目中的train.csv,输出是一个训练好的模型,对应项目中的XXX.hdf5。
model_validate.py:这是模型验证代码。因为需要测试我们训练好的模型效果如何,所以需要用测试集进行验证。
训练集和测试集是两个完全不同的数据,可以用测试集来模拟模型上线之后的效果。测试集中的数据从未在训练集上出现过。如果模型在测试集上效果还不错,那么就具备了上线的条件。
我们主要查看的指标有精度、召回率、auc和f1得分等等。整体而言,输入的是测试集test.csv和模型XXX.hdf5,输出的是模型的一系列效果指标。
model_predict.py:当我们完成整个模型的开发和优化工作后,就可以准备模型的上线工作了。一般我们会用目前已经标注的所有数据(包括训练集train.csv和测试集test.csv)一起去训练模型。然后用最终的这个模型去预测线上的用户搜索。整体而言,输入是用户线上搜索数据和模型XXX.hdf5,输出是对这些搜索数据的预测标签。
模型验证代码和预测代码非常相似,模型预测代码本身就是模型验证代码的一部分。因为我们进行模型验证的流程是先用模型对测试集进行预测,然后对比测试集的标签和预测结果,根据测试集的实际标签和预测标签来计算各项指标。
因为平时工作较忙,所以代码规范性略差,请见谅。目前团队也在做code review,也希望今后完成的代码更加简洁易懂。共勉之!
4. 训练完成得到的模型
这里就是上面模型训练代码得到的模型,对应项目中是XXX.hdf5的文件。我们模型训练的结果就是得到一个模型。最后上线的时候也是用这个训练好的模型去预测用户的query。
总结下,到这里为止,咱们就完成了使用BERT模型来识别用户query是否应该标注为传奇游戏标签。整个项目的来龙去脉以及代码也在文章中进行了详细的讲述。小伙伴们通过本项目可以实战文本二分类任务了。你需要BERT模型去识别哪种二分类任务,给它对应的训练数据就可以了。同样的代码,我们可以用来识别网络舆论是否正向、女朋友是不是生气了以及其他等等等等的分类任务。
通过对本模型进行简单的改造,也能进行多分类任务。
本文并没有从代码层级详细解释具体的代码作用,小伙伴们可以通过注释了解一部分。后面有需要我会专门写一篇代码走读,方便大家更好的使用keras_bert来做文本分类任务。
说点轻松的
我也是19年才开始入NLP的坑。之前做数据挖掘,更多的是用传统的机器学习模型比如xgboost去做一些分类或者回归的任务。随着深度学习大火,也开始慢慢接触自然语言处理。虽然平时有很多工作,但还是抽取一切可利用的时间学习NLP的知识,实战NLP的项目,将NLP应用到实际项目中。目前也算是入了门,并且可以在团队中做NLP相关的工作。有点感慨,只要你愿意开始,什么时候都不算晚。加油吧,小伙伴们。越努力,越幸运!
总结和预告
本篇从实战的角度使用BERT模型完成了一个文本理解的二分类任务。光会实战而不懂理论是无法真正做到模型优化的。只有真正明白模型内部原理,你才会明白模型本身擅长做什么,才能更好的结合自身业务来优化模型。下一篇会从理论的角度讲解下BERT模型是怎么出现的。BERT是近几年NLP里程碑的大作,也是NLP里重大进展的集大成者。我们会从word2vec到ELMO、GPT再到最后的BERT,明白了这一步步的演化进程,大家对BERT也算有基本的了解。对于以后想从事NLP或者广告行业的小伙伴也会帮助不少。
如果对广告感兴趣的小伙伴建议看看我广告系列的第一篇文章:广告中那些趣事系列1:广告统一兴趣建模流程。对于理解我们标签团队所做的事情和业务本身至关重要。再牛逼的技术也需要去支撑业务才有价值和意义。
喜欢本类型文章的小伙伴可以关注我的微信公众号:数据拾光者。我会同步在知乎、头条、简书、csdn等平台。也欢迎小伙伴多交流。如果有问题,可以在微信公众号随时Q我哈。