
怎么快速做视频发到B站赚点小钱?
共 7362字,需浏览 15分钟
·
2021-03-31 11:36
点击上方Python知识圈,设为星标
回复100获取100题PDF
阅读文本大概需要 5 分钟
作者:pk哥
来源:Python知识圈
大家好,我是pk哥。
作为一名公众号技术博主。其实PK哥也是 b 站的一名萌新up主。也会偶尔发布下 Python 类的技术视频到 b 站上,目前总共发布了 19 个视频,最高播放量的是 34w,目前粉丝数是 3万多,开通了创作激励的话,1万播放的视频差不多能获得30元,因为并不是所有的图文都可以转为视频,技术视频一般趣味性不够的话是很难得到推荐的。
其实刚开始制作技术视频的时候并不是很习惯。因为刚开始你要学习剪辑工具。把你的项目以视频的形式展示给大家。
剪辑视频基本步骤
我剪辑视频的步骤一般是以下几个部分。
第1,选定主题,当我们选定主题之后,比如我要分享一个爬虫美女图的项目,我们首先需要先完成爬虫项目的爬取工作,先完成爬虫项目的程序代码。
第2,我会提前把文案写好,文案一般也就是文章的文字部分,也就是你视频中的字幕。文案写好之后,我们进入第3步。
第3,我会直接把刚刚写好的文案读出来进行录音。
第4,我会把刚才的录音进行剪辑。录音的时候可能有一些 NG 的部分,我们需要剪掉,还有中间停顿太长时间的,我们也需要把中间的停顿剪掉。
录音剪辑完成之后,进入第5部分,我会根据音频来填充视频的素材,这个素材包括我们的电脑录屏。或者展示项目效果的图片。还有一些素材是过渡素材。比如说有些画面,我们不知道放什么素材的时候,这个时候我们需要填充与主题有关的一些过渡素材。这些素材一般也会涉及版权问题,所以我一般是去免版权的素材网站上找。
如果是非技术up主,做视频找素材一般是等到需要这个材料的时候,就会直接去素材网站上找到对应的素材视频,然后手动下载下来。
无版权图片素材爬虫
但是作为一名技术up主,这个步骤就太慢了。能不能批量对一个主题下面的多个图片或者视频素材进行下载呢?这个时候就想到了爬虫了。我之前也写过一个项目,就是对无版权图片网站的图片进行批量爬取,根据你输入的主题关键字进行批量爬取保存。这些图片你可以把它当作视频封面或文章封面,也可以插入到文章中,做到点缀的作用。这些图片是无版权的,所以我们不用担心会侵权。不用担心会被视觉xx公司寄律师函。之前无版权图片爬虫的项目,可以看看之前的文章Python批量下载无版权图片
无版权视频素材爬虫
无版权图片有了,怎么能少了视频素材呢,接下来分享下怎么批量爬取无版权的视频素材。
我爬取的视频是和上面说的无版权图片一样的网站,也是 pixabay.com 网站。
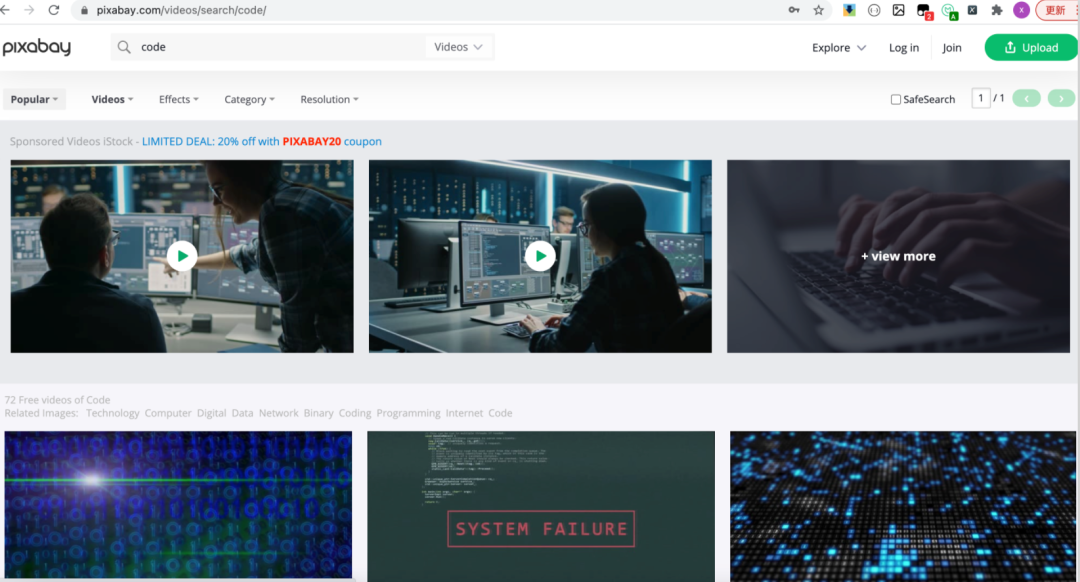
当我打开网站进入F12调试窗口。输入关键字搜索视频的时候。发现返回的接口信息都是空的,看来是被反爬处理了.
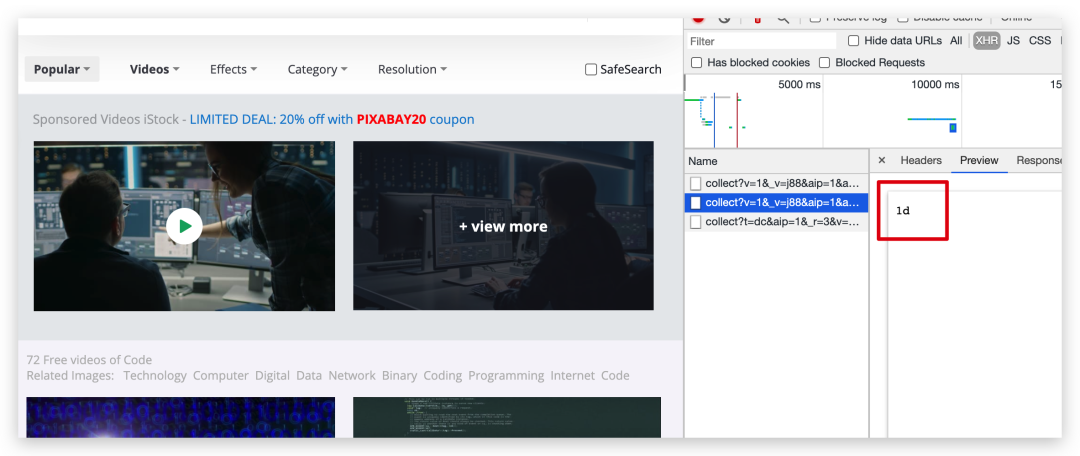
我们直接在源代码中看看能不能查看到视频的可下载链接,简单的筛查了下,这个链接放在 data-mp4 属性里面,这个属性的值前面我们加上 "http:" 放在浏览器里面是可以直接打开的,而且有下载按钮的。
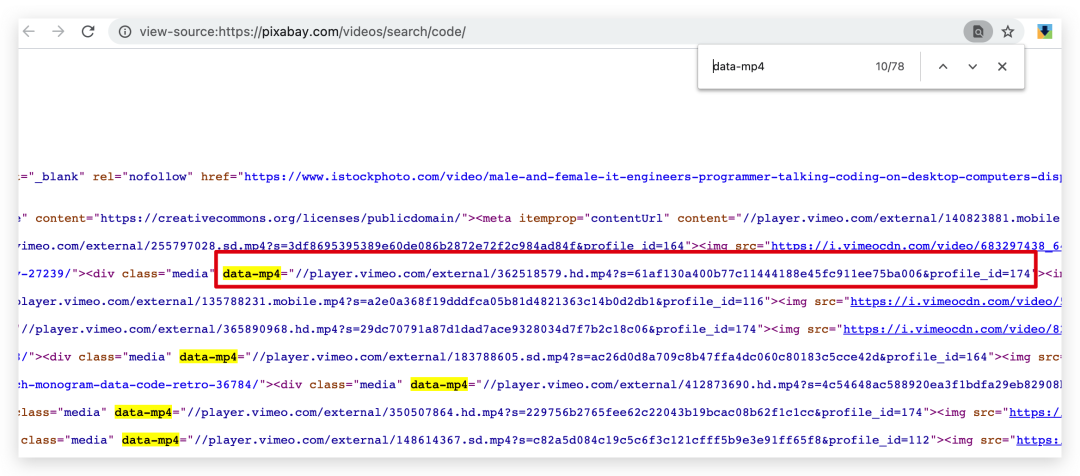
但是当我们直接去请求返回的页面源代码数据的时候,发现返回的信息和 F12 查看的不一致,登录 p 站后获取 cookie 信息再去 请求也是这样,看来这条路也被反爬了。
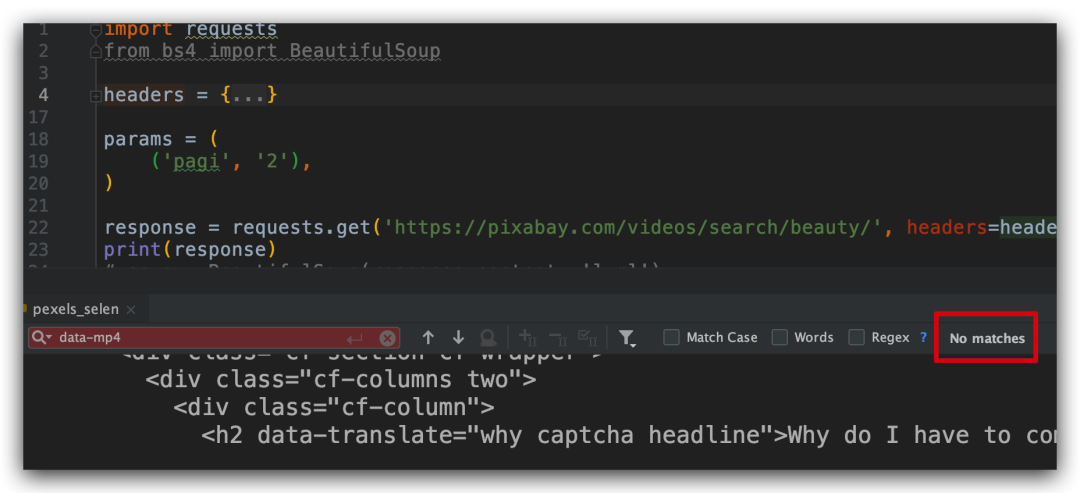
这样我们无法用 request 库直接请求接口返回数据了。那这个时候我想到了用 selenium 自动化库来获取页面视频的地址。用自动化库直接请求的话,发现返回的信息中,也没有包含 data-MP4 的 信息,也并没有我们需要的视频下载链接,所以大家不要以为用 selenium 库做爬虫就很安全,其实你用 selenium 库爬取数据如果没有任何伪装处理的话,网站服务器第一时间就知道你是个异常请求。下面的干货会教大家怎么伪装下 selenium 库不被识别从而实现爬虫,请继续往下看。
那如果我们直接用无头的 chrome 浏览器来获取网页信息呢,这个也是会被检测到的。
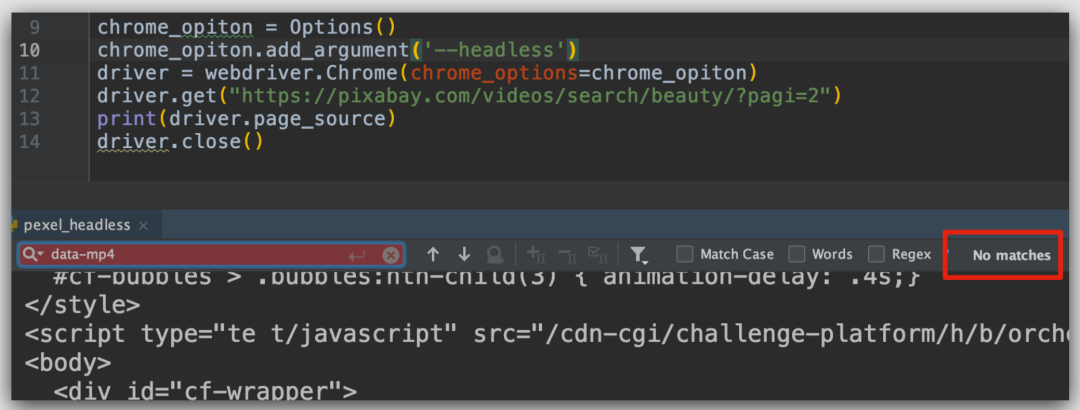
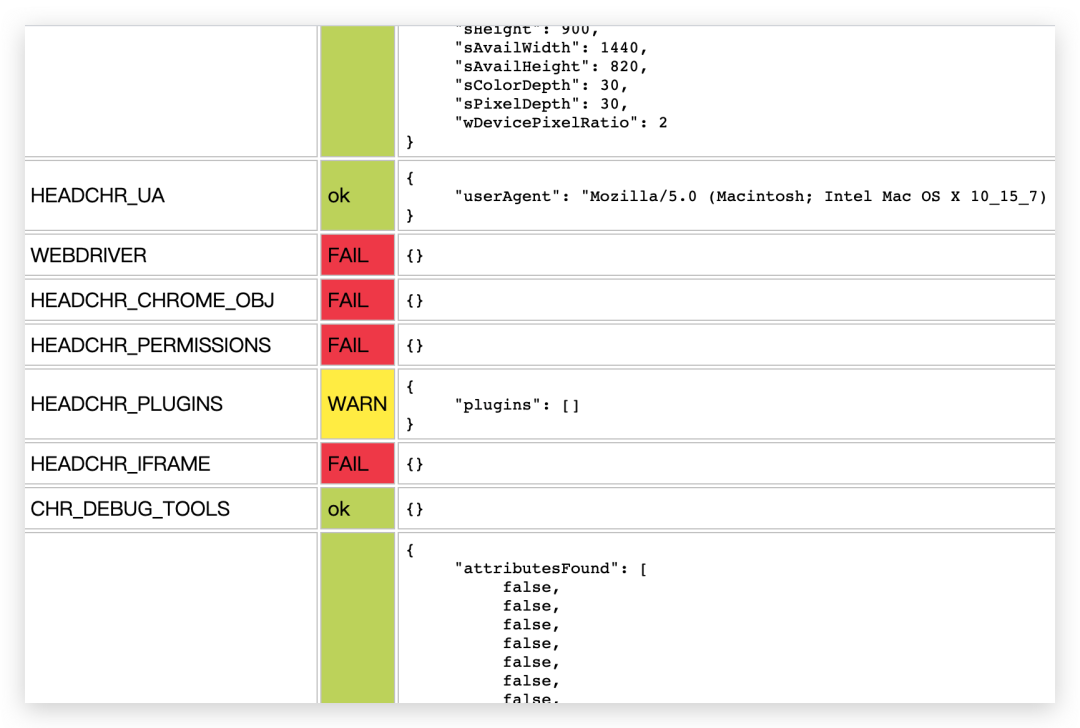
那我们怎么知道 webdriver 有哪些属性是否隐藏了呢?我们可以通过请求 Sannysoft 这个网站来查看。
我分别用selenium库和无头浏览器请求这个网站,我们看到很多特性都直接报红色,这就表示隐藏失败了,绿色才表示隐藏成功了。
import time
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = Chrome(options=chrome_options)
driver.get('https://bot.sannysoft.com/')
time.sleep(5)
driver.save_screenshot('walkaround.png')
# 你可以保存源代码为 html 再双击打开,查看完整结果
source = driver.page_source
with open('result.html', 'w') as f:
f.write(source)
搞定反爬
报红色的话,网站服务器就会知道你这个不是正常的人为请求了。我们需要加入一个大神开发的 js 文件来进行伪装,伪装后我们看看能不能隐藏掉刚才报红的属性,我稍微改动一下代码,加入js文件信息再请求。js文件获取方法我会放在文章末尾,大家自行获取。
import time
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless")
# 增加一个参数设置
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
chrome_options.add_argument('user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36')
driver = Chrome(options=chrome_options)
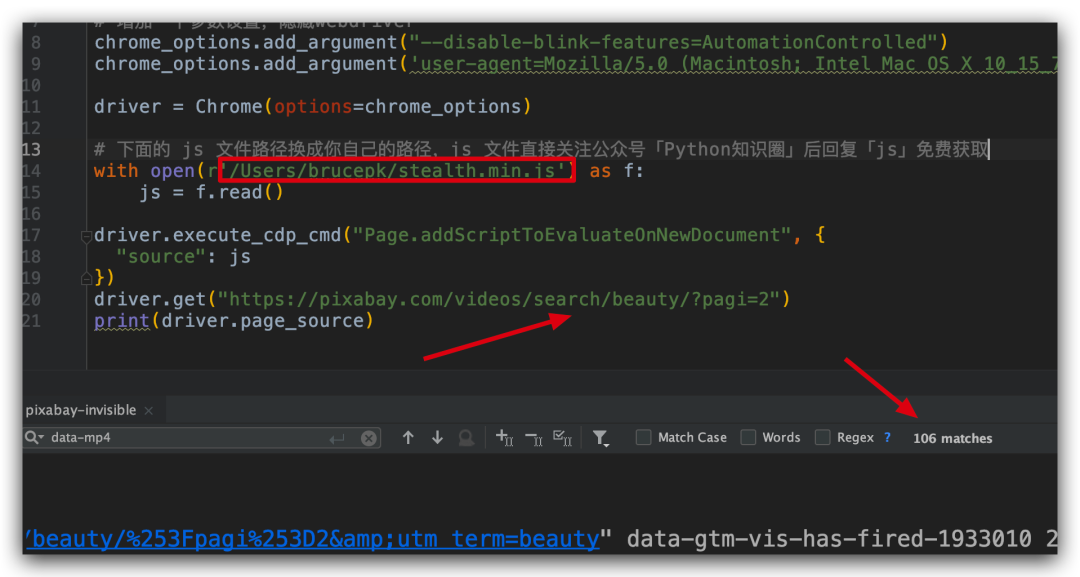
# 下面的 js 文件路径换成你自己的路径,js 文件直接关注公众号「Python知识圈」后回复「js」免费获取
with open(r'/Users/brucepk/stealth.min.js') as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
driver.get('https://bot.sannysoft.com/')
time.sleep(5)
driver.save_screenshot('walkaround3.png')
# 你可以保存源代码为 html 再双击打开,查看完整结果
source = driver.page_source
with open('result3.html', 'w') as f:
f.write(source)
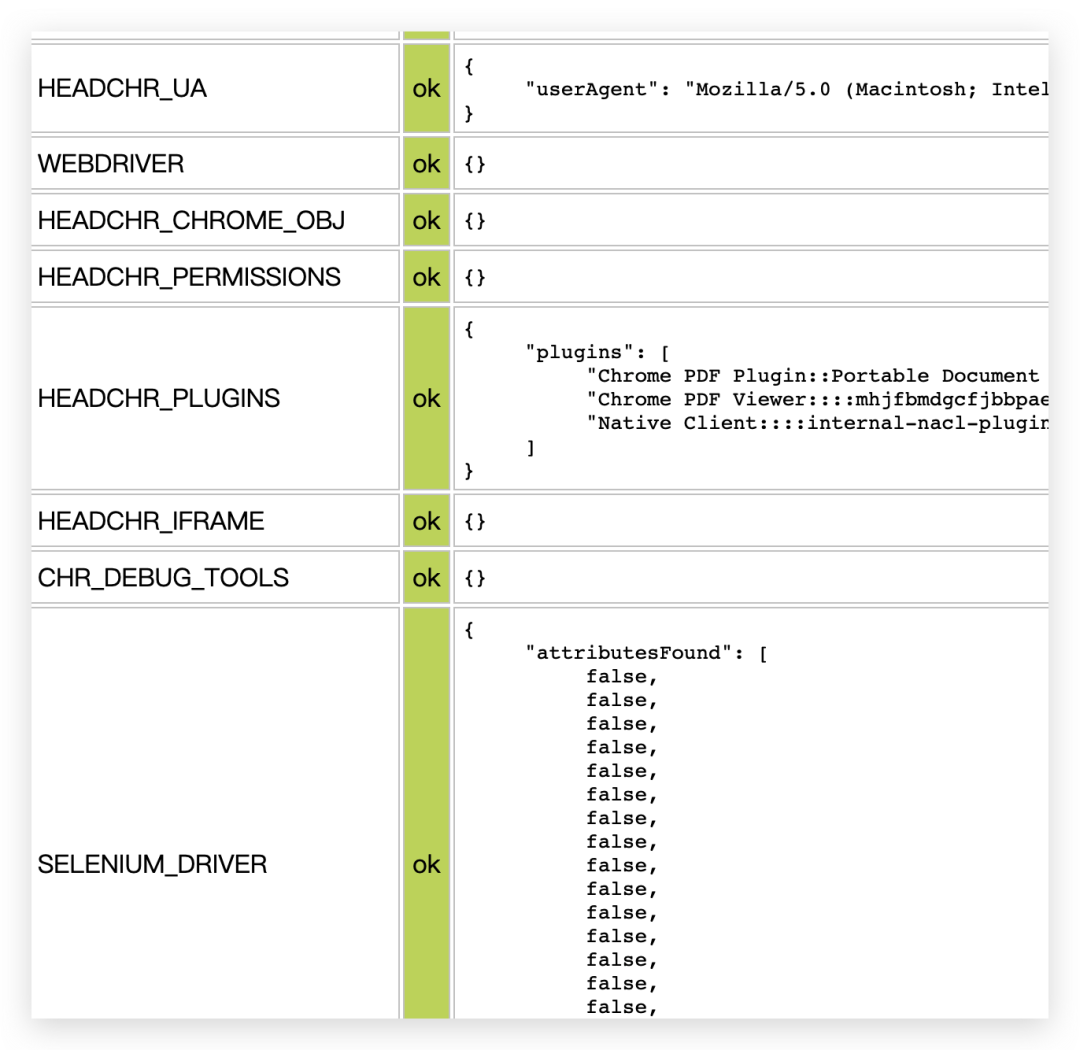
加入 js 文件后,我发现隐藏成功了,这时候我再用无头浏览器来请求,结果返回的结果中,我们可以搜索到data-mp4的信息啦,这就表示返回的信息中包含了视频的可下载链接。
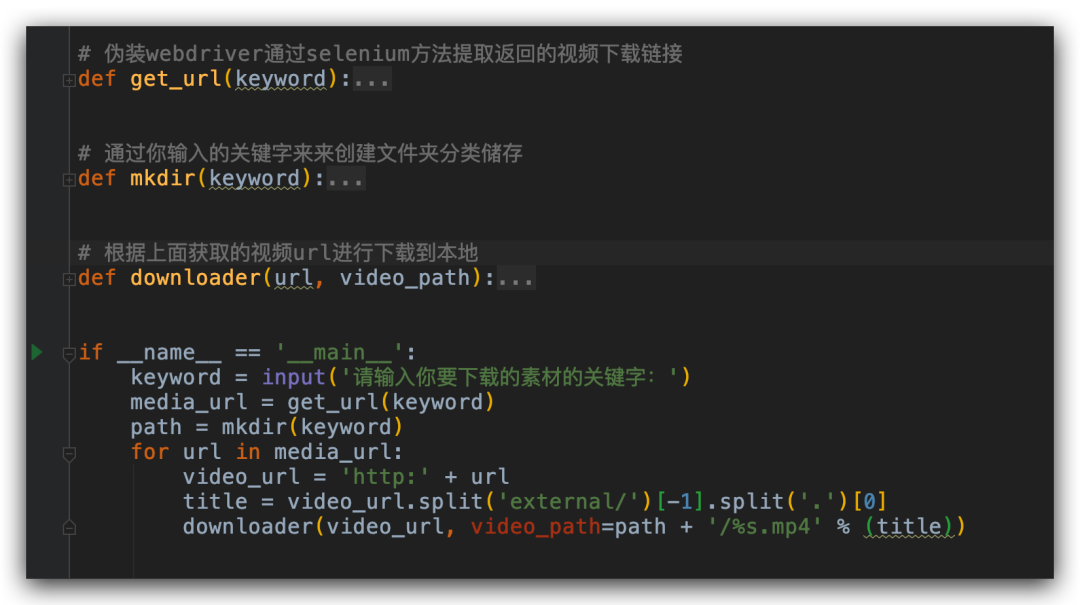
上面是对一个页面进行爬虫提取多个视频的链接,接下来就简单了,我们只需要对页面的页码做个循环,再写一个能自动根据我输入的搜索关键字来创建的文件夹存储不同主题的图片,再写一个根据视频 url 进行下载的方法,批量下载就搞定了。
总结
总结下,以上爬取视频的难点就在于网站做了反爬措施,他们对返回的信息进行了处理。用无头浏览器爬取也是被做了反爬,所以我们需要隐藏 webdriver 的一些特性。隐藏后再请求的话系统就认为我们是真实的人为请求,这样就能获取到我们想要的信息了。
好啦,以上这些素材搞定之后,我们选定主题。就可以高高兴兴的做视频发到b站了,成为一名小小的up主。如果你也有视频找素材的困扰,这篇文章你应该会有点收获。最后,祝大家早日成为 b 站的百大up。到时候别忘了回来请PK哥吃饭啊。
代码获取方法
文件提到的隐藏 webdriver 属性的 js 文件在本公众号「Python知识圈」回复「js」获取,本文的爬取视频的代码也放在里面,大家只要把 js 的路径改成你本地的路径就可以直接完成批量下载。
觉得本文不错,对你有帮助的话,点赞、在看、转发都是对 pk哥的支持,感谢。
大家也可以去我的 B 站看看我发的视频:https://space.bilibili.com/316065114,你也可以直接点击下方的阅读原文直达我的B站页面。
往期推荐 01 02 03
↓点击阅读原文查看pk哥原创视频
我就知道你“在看”
