
(附代码)收藏 | CNN的一些可视化方法
点击左上方蓝字关注我们

链接 | https://zhuanlan.zhihu.com/p/53683453
注:本文所有资料均来自Keras之父、Google人工智能研究员Francois Chollet的大作:《Python深度学习》,建议大家直接去看原文,这里只是结合楼主的理解做点笔记。
有一些同学认为深度学习、神经网络什么的就是一个黑盒子,没办法、也不需要分析其内部的工作方式。个人认为这种说法“谬之千里”。
首先,站在自动特征提取或表示学习的角度来看,深度学习还是很好理解,即通过一个层级结构,由简单到复杂逐步提取特征,获得易于处理的高层次抽象表示。其次,现在也已经有很多方法对神经网络进行分析了,特别是一些可视化方法,可以很直观的展示深度模型的特征提取过程。
对神经网络进行可视化分析不管是在学习上还是实际应用上都有很重要的意义,基于此,本文将介绍以下3种CNN的可视化方法:
可视化中间特征图。 可视化卷积核。 可视化图像中类激活的热力图。
这种方法很简单,把网络中间某层的输出的特征图按通道作为图片进行可视化展示即可,如下述代码所示:
import matplotlib.pyplot as plt
#get feature map of layer_activation
plt.matshow(layer_activation[0, :, :, 4], cmap='viridis')把多个特征图可视化后堆叠在一起可以得到与下述类似的图片。
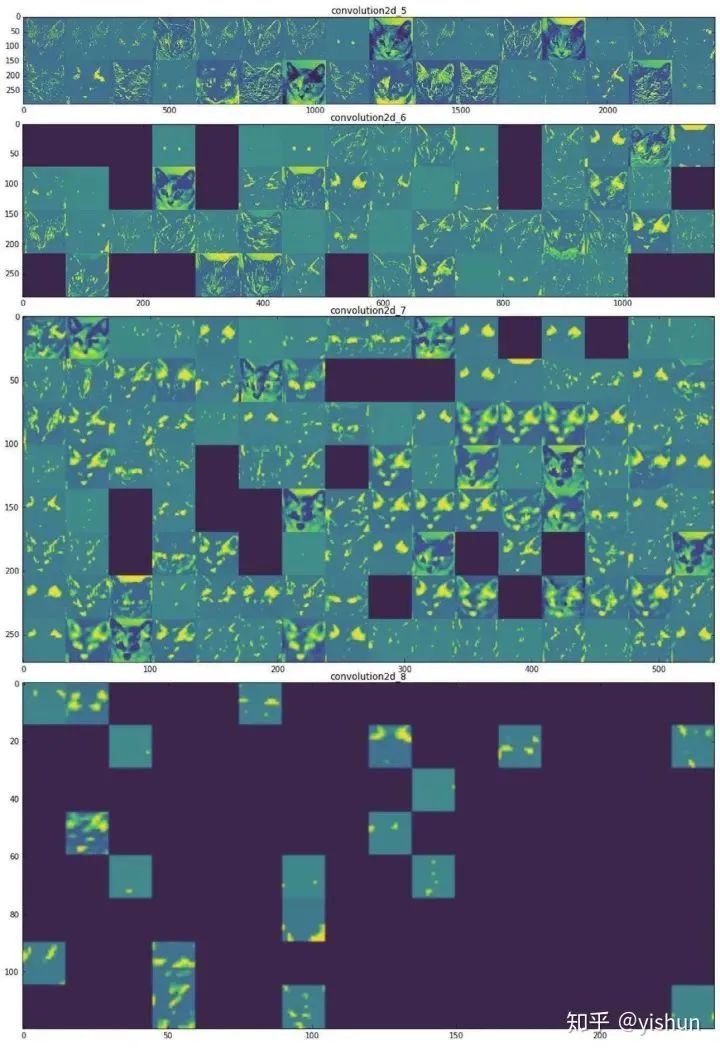
上图为某CNN 5-8 层输出的某喵星人的特征图的可视化结果(一个卷积核对应一个小图片)。可以发现越是低的层,捕捉的底层次像素信息越多,特征图中猫的轮廓也越清晰。越到高层,图像越抽象,稀疏程度也越高。这符合我们一直强调的特征提取概念。
想要观察卷积神经网络学到的过滤器,一种简单的方法是获取每个过滤器所响应的视觉模式。我们可以将其视为一个优化问题,即从空白输入图像开始,将梯度上升应用于卷积神经网络的输入图像,让某个过滤器的响应最大化,最后得到的图像是选定过滤器具有较大响应的图像。
核心代码如下所示(利用Keras框架):
def generate_pattern(layer_name, filter_index, size=150):
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:, :, :, filter_index])
grads = K.gradients(loss, model.input)[0]
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
iterate = K.function([model.input], [loss, grads])
input_img_data = np.random.random((1, size, size, 3)) * 20 + 128.
step = 1.
for i in range(40):
loss_value, grads_value = iterate([input_img_data])
input_img_data += grads_value * step
img = input_img_data[0]
return deprocess_image(img)将输入图片张量转换回图片后进行可视化,可以得到与下述类似的图片:

block1_conv1 层的过滤器模式

block2_conv1 层的过滤器模式
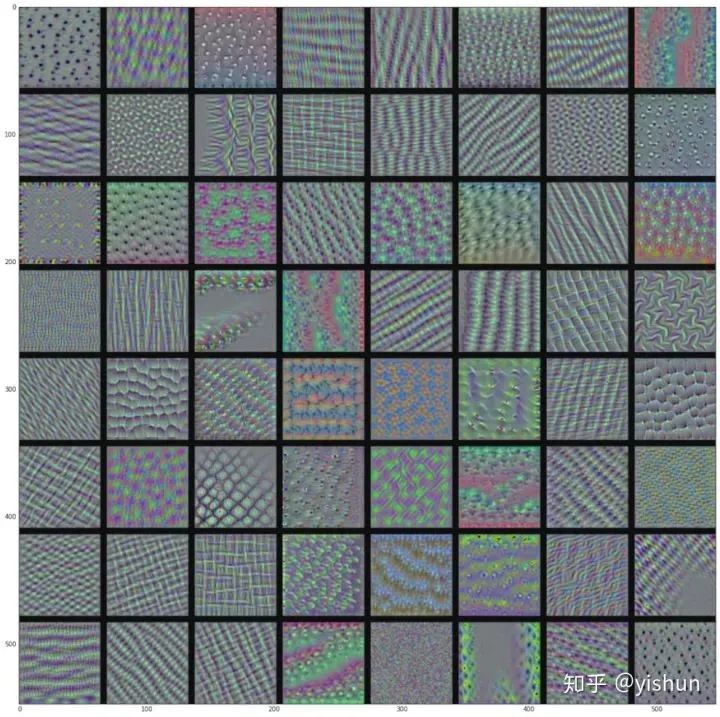
block3_conv1 层的过滤器模式

block4_conv1 层的过滤器模式
随着层数的加深,卷积神经网络中的过滤器变得越来越复杂,越来越精细。模型第一层( block1_conv1 )的过滤器对应简单的方向边缘和颜色,高层的过滤器类似于自然图像中的纹理:羽毛、眼睛、树叶等。
即显示原始图片的不同区域对某个CNN输出类别的“贡献”程度,如下面图片所示:

可以看到,大象头部对“大象”这个类别的“贡献”程度较高,而且这种方法似乎可以在一定程度上进行无监督的目标检测。
下面是书中原文,可能有点绕口。
我们将使用的具体实现方式是“Grad-CAM: visual explanations from deep networks via gradient-based localization”这篇论文中描述的方法。这种方法非常简单:给定一张输入图像,对于一个卷积层的输出特征图,用类别相对于通道的梯度对这个特征图中的每个通道进行加权。直观上来看,理解这个技巧的一种方法是,你是用“每个通道对类别的重要程度”对“输入图像对不同通道的激活强度”的空间图进行加权,从而得到了“输入图像对类别的激活强度”的空间图。
这里谈一下我的理解,给定线性函数 ,y为类别, 等等为输入。可以看到这里 对y的贡献为 ,恰好为 。当然了,深度模型中有非线性激活函数,不能简化为一个线性模型,所以这只是启发性的理解。
代码如下所示:
african_elephant_output = model.output[:, 386]
last_conv_layer = model.get_layer('block5_conv3')
grads = K.gradients(african_elephant_output, last_conv_layer.output)[0]
pooled_grads = K.mean(grads, axis=(0, 1, 2))
iterate = K.function([model.input],
[pooled_grads, last_conv_layer.output[0]])
pooled_grads_value, conv_layer_output_value = iterate([x])
for i in range(512):
conv_layer_output_value[:, :, i] *= pooled_grads_value[i]
heatmap = np.mean(conv_layer_output_value, axis=-1)
heatmap = np.maximum(heatmap, 0)
heatmap /= np.max(heatmap)
plt.matshow(heatmap)得到的热力图如下所示:
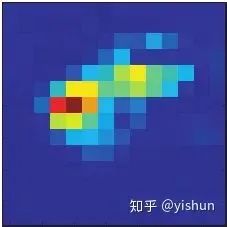
经下述代码处理后,可以得到本节开始时的图片。
import cv2
img = cv2.imread(img_path)
heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0]))
heatmap = np.uint8(255 * heatmap)
heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)
superimposed_img = heatmap * 0.4 + img
cv2.imwrite('/Users/fchollet/Downloads/elephant_cam.jpg', superimposed_img)本文到这里就结束了,这里再次推荐一下Francois Chollet大佬的书,写的很接地气,建议新手们都看看。
END