
嘘,差点被警察带走
大家好,我是 Jack。
时间又来到了假期的最后一晚,今天继续跟大家闲聊两句,再讲个新技术。
我最近一直在调整生活习惯,吃了一周的蔬菜,外加多多锻炼,开启了养生模式。
按照往常的假期,我基本是宅在家里,要么工作,要么学习,要么创作,很少公园散步。
昨天去了趟奥森,放松遛达了一番,风景确实不错。

大家在忙于学习和工作之余,一定注意锻炼身体和健康饮食,别像我,生了病再调整。
难受啊,哈哈。
闲聊结束,进入我们今天的正题。
CogView2
我发现,最近新出的很多论文,都是多模态方向的研究。
比如根据文本生成图像的Imagen,再比如根据文本生成视频的CogVideo,我在之前的文章中讲过:
CogVideo还一直没有开源,不过它依赖的文本生成图像的CogView2算法这两天开源了。
本来我想自己训练个模型试试,试一试一些奇思妙想。
但看到说明文档,我就放弃了:
Hardware: Linux servers with Nvidia A100s are recommended, but it is also okay to run the pretrained models with smaller --max-inference-batch-size or training smaller models on less powerful GPUs.
官方推荐使用A100显卡训练,这东西什么级别呢?也别对比GFLOPS了,看着抽象,直接看价钱吧:

没有相应的设备,就别想训练了,不过跑一跑pretrained models倒是可以。
项目地址:
https://github.com/thudm/cogview2
想要运行,需要部署下开发环境,不过官方也提供了网页版,直接体验。
体验地址(需要工具):
https://replicate.com/thudm/cogview2
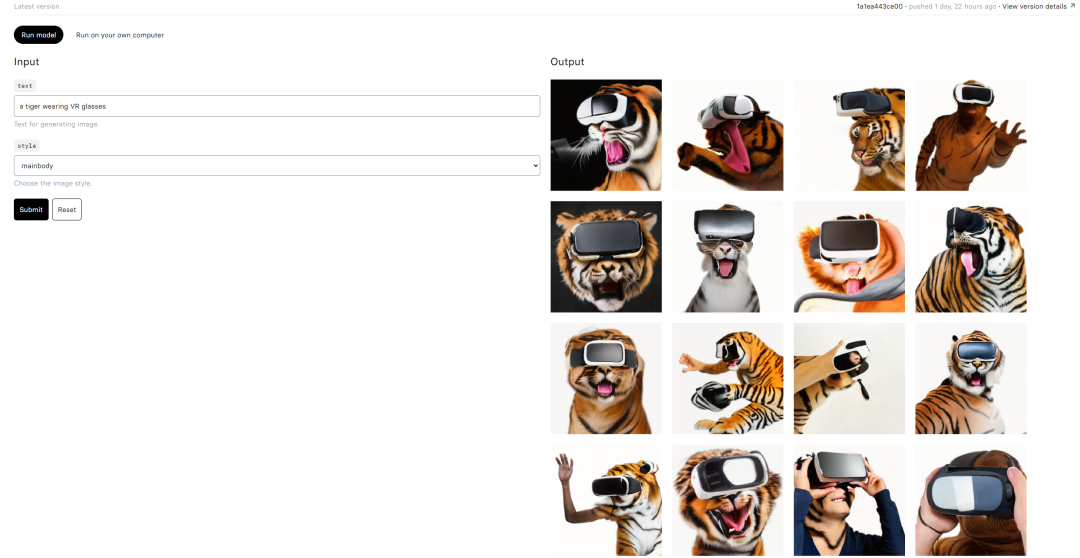
支持英文输入,比如:
A tiger wearing VR glasses
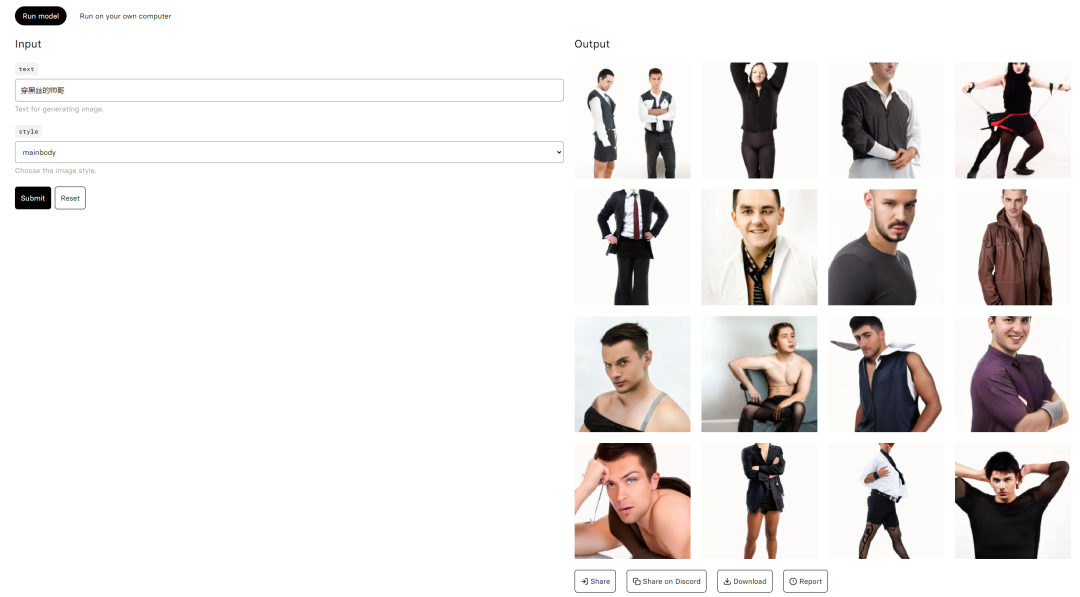
中文输入,比如:
穿黑丝的帅哥
打住,不能再乱试了,怕被 FBI 请去喝茶。

算法的理解能力还是有点东西的,看下更多的效果吧:

CogView2 算法基于Transformers,思想是将文本和图像 tokens 进行大规模生成联合预训练。
同时引入Attention Mask,只对 mask 区域计算 loss,使生成效果更稳定。
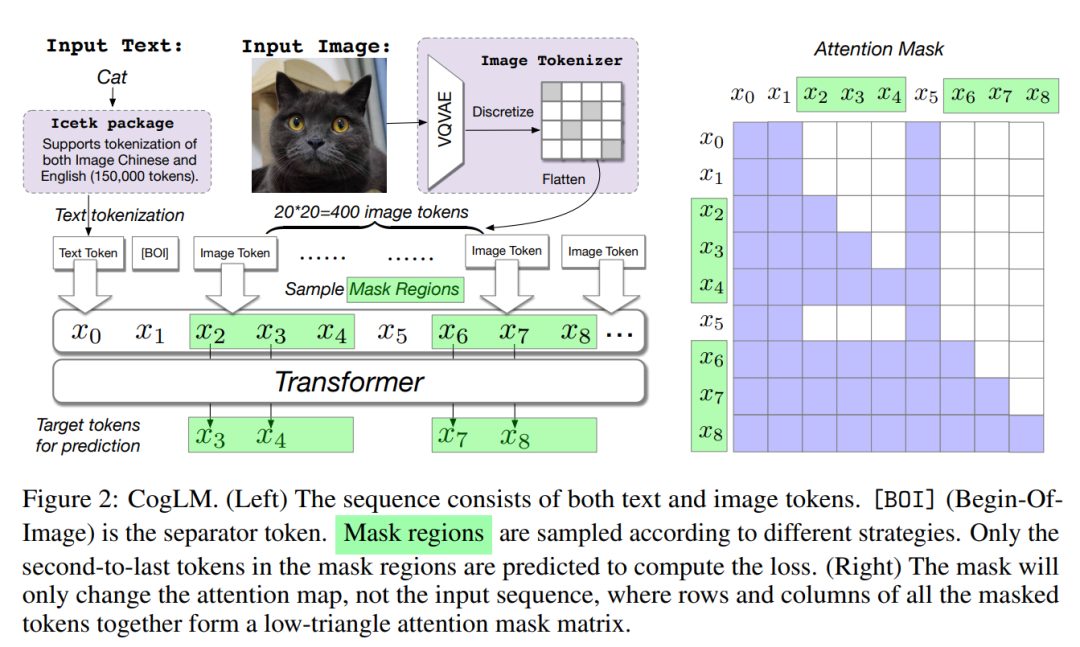
CogView2 提出一种基于层次 Transformer 和局部平行自回归生成的解决方案,采用了一个简单而灵活的自监督任务,跨模态通用语言模型(CogLM),来预训练一个 6B 参数的 Transformer。
对原理感兴趣的小伙伴,可以看看论文:
https://arxiv.org/pdf/2204.14217.pdf
好了,今天就聊这么多。
最近时间不多,没有写一些硬核的技术文,后面慢慢给大家补了~
我是 Jack,我们下期见~
