
一个架构师的缓存修炼之路

本文作者:张勇,现任科大讯飞高级架构师。11年后端经验,曾就职于同程艺龙、神州优车等公司。乐于分享、热衷通过自己的实践经验平铺对技术的理解。
“Nginx+业务逻辑层+数据库+缓存层+消息队列,这种模型几乎能适配绝大部分的业务场景。
这么多年过去了,这句话或深或浅地影响了我的技术选择,以至于后来我花了很多时间去重点学习缓存相关的技术。
我在10年前开始使用缓存,从本地缓存、到分布式缓存、再到多级缓存,踩过很多坑。下面我结合自己使用缓存的历程,谈谈我对缓存的认识。
01 本地缓存
1. 页面级缓存
"foobar" some jsp content
2. 对象缓存
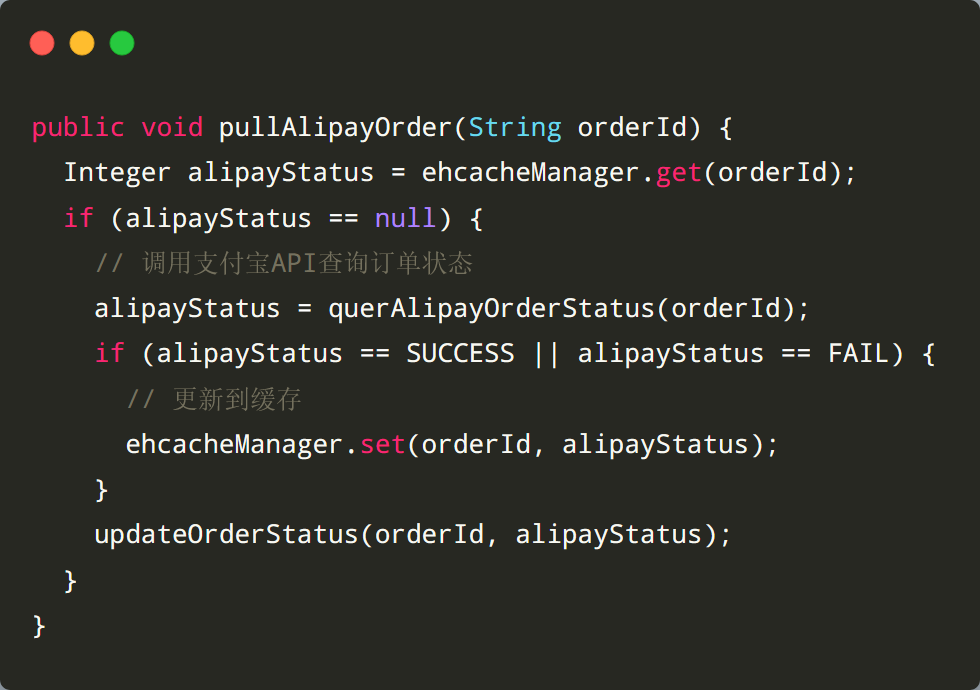
3. 刷新策略
2018年,我和我的小伙伴自研了配置中心,为了让客户端以最快的速度读取配置, 本地缓存使用了 Guava,整体架构如下图所示:
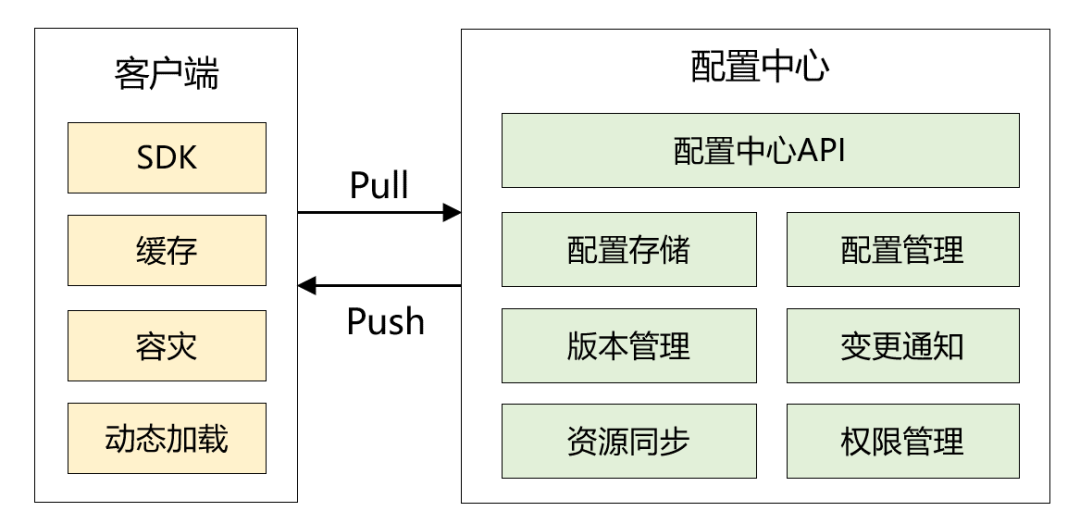
那本地缓存是如何更新的呢?有两种机制:
客户端启动定时任务,从配置中心拉取数据。 当配置中心有数据变化时,主动推送给客户端。这里我并没有使用websocket,而是使用了 RocketMQ Remoting 通讯框架。
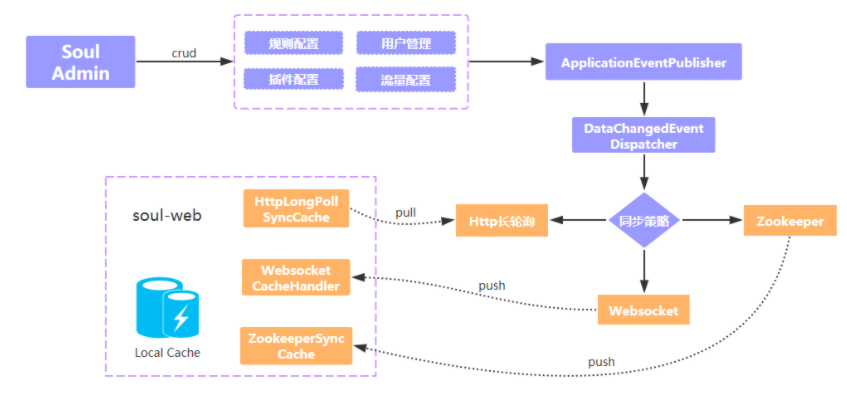
▍zookeeper watch机制
▍websocket 机制
websocket 和 zookeeper 机制有点类似,当网关与 admin 首次建立好 websocket 连接时,admin 会推送一次全量数据,后续如果配置数据发生变更,则将增量数据通过 websocket 主动推送给 soul-web。
http请求到达服务端后,并不是马上响应,而是利用 Servlet 3.0 的异步机制响应数据。当配置发生变化时,服务端会挨个移除队列中的长轮询请求,告知是哪个 Group 的数据发生了变更,网关收到响应后,再次请求该 Group 的配置数据。
pull 模式必不可少 增量推送大同小异
02 分布式缓存
1. 合理控制对象大小及读取策略
1、数据格式非常精简,只返回给前端必要的数据,部分数据通过数组的方式返回
2、使用 websocket,进入页面后推送全量数据,数据发生变化推送增量数据
再回到我的问题上,最终是用什么方案解决的呢?当时,我们的比分直播模块缓存格式是 JSON 数组,每个数组元素包含 20 多个键值对, 下面的 JSON 示例我仅仅列了其中 4 个属性。
[{"playId":"2399","guestTeamName":"小牛","hostTeamName":"湖人","europe":"123"}]
这种数据结构,一般情况下没有什么问题。但是当字段数多达 20 多个,而且每天的比赛场次非常多时,在高并发的请求下其实很容易引发问题。
基于工期以及风险考虑,最终我们采用了比较保守的优化方案:
[["2399","小牛","湖人","123"]]修改完成之后, 缓存的大小从平均 300k 左右降为 80k 左右,YGC 频率下降很明显,同时页面响应也变快了很多。
但过了一会,cpu load 会在瞬间波动得比较高。可见,虽然我们减少了缓存大小,但是读取大对象依然对系统资源是极大的损耗,导致 Full GC 的频率也不低。
3)为了彻底解决这个问题,我们使用了更精细化的缓存读取策略。
我们把缓存拆成两个部分,第一部分是全量数据,第二部分是增量数据(数据量很小)。页面第一次请求拉取全量数据,当比分有变化的时候,通过 websocket 推送增量数据。
第 3 步完成后,页面的访问速度极快,服务器的资源使用也很少,优化的效果非常优异。
2. 分页列表查询
select id from blogs limit 0,10 select id from blogs where id in (noHitId1, noHitId2)本地缓存:性能极高,for 循环即可 memcached:使用 mget 命令 Redis:若缓存对象结构简单,使用 mget 、hmget命令;若结构复杂,可以考虑使用 pipleline,lua脚本模式
03 多级缓存
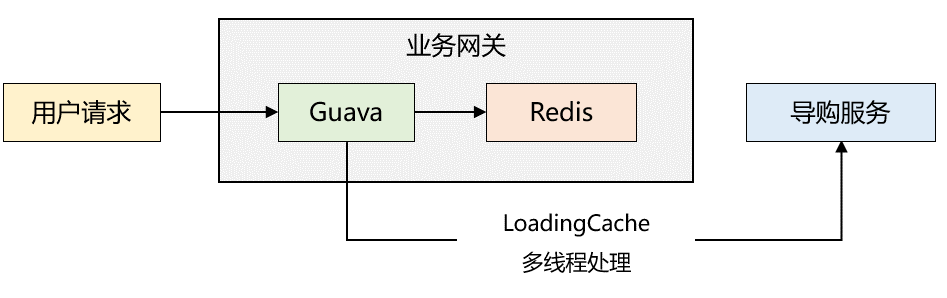
缓存读取流程如下:
1、业务网关刚启动时,本地缓存没有数据,读取 Redis 缓存,如果 Redis 缓存也没数据,则通过 RPC 调用导购服务读取数据,然后再将数据写入本地缓存和 Redis 中;若 Redis 缓存不为空,则将缓存数据写入本地缓存中。
2、由于步骤1已经对本地缓存预热,后续请求直接读取本地缓存,返回给用户端。
3、Guava 配置了 refresh 机制,每隔一段时间会调用自定义 LoadingCache 线程池(5个最大线程,5个核心线程)去导购服务同步数据到本地缓存和 Redis 中。
优化后,性能表现很好,平均耗时在 5ms 左右。最开始我以为出现问题的几率很小,可是有一天晚上,突然发现 app 端首页显示的数据时而相同,时而不同。
1、惰性加载仍然可能造成多台机器的数据不一致
2、 LoadingCache 线程池数量配置的不太合理, 导致了线程堆积
缓存是非常重要的一个技术手段。如果能从原理到实践,不断深入地去掌握它,这应该是技术人员最享受的事情。
这篇文章属于缓存系列的开篇,更多是把我 10 多年工作中遇到的典型问题娓娓道来,并没有非常深入地去探讨原理性的知识。
我想我更应该和朋友交流的是:如何体系化的学习一门新技术。
选择该技术的经典书籍,理解基础概念 建立该技术的知识脉络 知行合一,在生产环境中实践或者自己造轮子 不断复盘,思考是否有更优的方案
后续我会连载一些缓存相关的内容:包括缓存的高可用机制、codis 的原理等,欢迎大家继续关注。
关于缓存,如果你有自己的心得体会或者想深入了解的内容,欢迎评论区留言。
END
有热门推荐?
1. 心惊肉跳,新来的妹纸 rm -rf 把公司整个数据库删没了!!!
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)
