
这个网络故障排查神器,运维用了都说好!
原文连接:cloud.tencent.com/developer/article/1491610
↓推荐关注↓
常用的 ping,tracert,nslookup 一般用来判断主机的网络连通性,其实 Linux 下有一个更好用的网络联通性判断工具,它可以结合ping nslookup tracert 来判断网络的相关特性,这个命令就是 mtr。
mtr 全称 my traceroute,是一个把 ping 和 traceroute 合并到一个程序的网络诊断工具。
traceroute 默认使用 UDP 数据包探测,而 mtr 默认使用 ICMP 报文探测,ICMP 在某些路由节点的优先级要比其他数据包低,所以测试得到的数据可能低于实际情况。
安装方法
https://cdn.ipip.net/17mon/besttrace.exe 下载 BestTrace 工具并安装。也可以在 https://github.com/oott123/WinMTR/releases GitHub上下载 MTR专用工具,该工具为免安装,下载后可以直接使用。
# Debian/Ubuntu 系统sudo apt install mtr# RedHat/CentOS 系统sudo yum install mtr
3. Apple 客户端可以在 App store 搜索 Best NetTools 下载安装
使用
MTR 使用非常简单,查看本机到 qq.com 的路由以及连接情况直接运行如下命令:
mtr qq.com
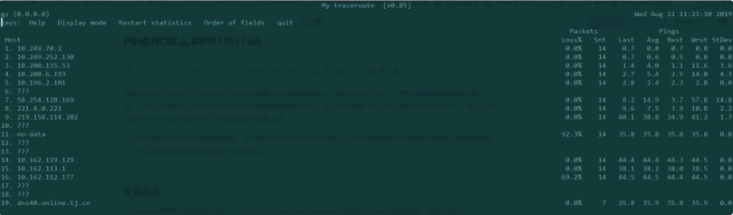
MTR qq.com 测试界面
具体输出的参数含义为:
第一列是IP地址 丢包率:Loss 已发送的包数:Snt 最后一个包的延时:Last 平均延时:Avg 最低延时:Best 最差延时:Wrst 方差(稳定性):StDev
参数说明
-r or —report
-c 参数-s or —packetsize
-s 来指定ping数据包的大小mtr -s 100 qq.com
-c
指定发送数量
mtr -c 100 qq.com
-n
-n 选项来让 mtr 只输出 IP,而不对主机 host name 进行解释mtr -n qq.com
MTR 结果分析
当我们分析 MTR 报告时候,最好找出每一跳的任何问题。除了可以查看两个服务器之间的路径之外,MTR 在它的七列数据中提供了很多有价值的数据统计报告。Loss% 列展示了数据包在每一跳的丢失率。Snt 列记录的多少个数据包被送出。使用 –report 参数默认会送出10个数据包。如果使用 –report-cycles=[number-of-packets] 选项,MTR 就会按照 [number-of-packets] 指定的数量发出 ICMP 数据包。
网络丢包
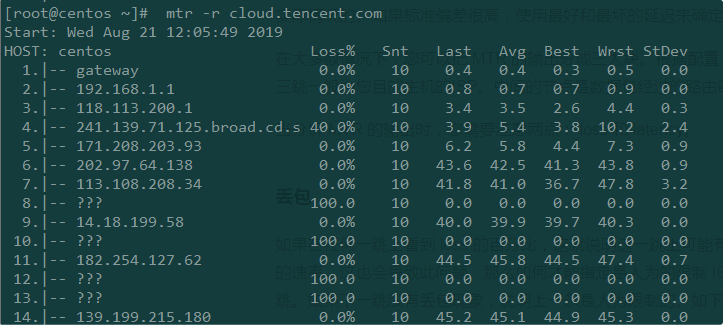
人为限制MTR丢包
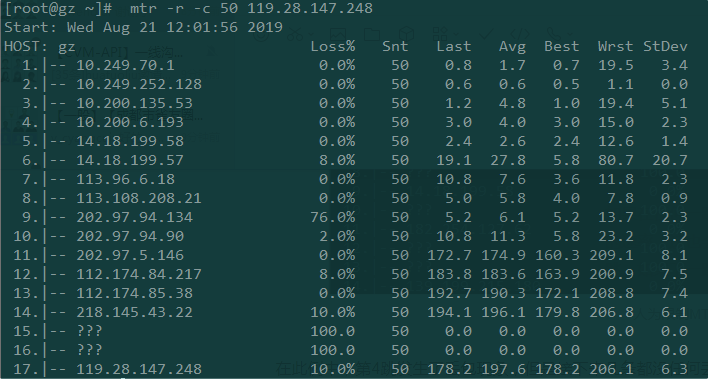
网络延迟
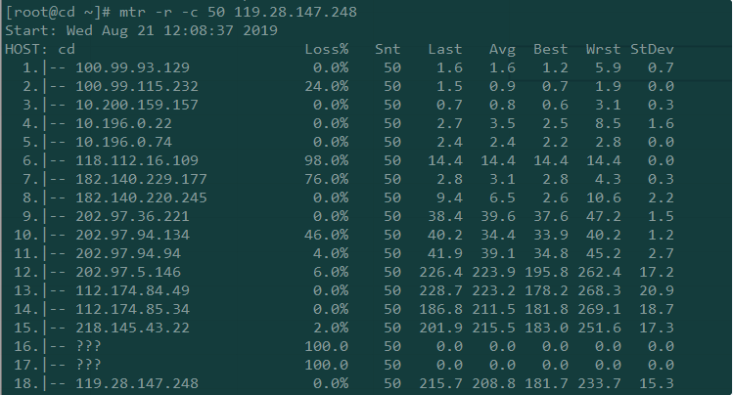
MTR查看网络延迟
从上面的MTR报告截图中,我们可以看到从第11跳到12跳的延迟猛增,直接导致了后面的延迟也很大,一般有可能是11跳到12跳属于不通地域,物理距离导致时延猛增,也有可能是第12条的路由器配置不当,或者是线路拥塞。需要具体问题进行具体的分析。
然而,高延迟并不一定意味着当前路由器有问题。延迟很大的原因也有可能是在返回过程中引发的。从这份报告的截图看不到返回的路径,返回的路径可能是完全不同的线路,所以一般需要进行双向MTR测试。
注:ICMP 速率限制也可能会增加延迟,但是一般可以查看最后一条的时间延迟来判断是否是上述情况。
根据MTR结果解决网络问题
- END -
推荐阅读 《K8s 运维架构师实战》集训营【本周开课】 这些 K8S 日常故障处理集锦,运维请收藏~ 猪八戒网 CI/CD 最佳实践之路 Jenkins Pipeline 流水线部署 Kubernetes 应用 快、狠、准!系统有效的排查运维类故障 GitLab 14.0发布,一个全新的 DevOps 平台 Nginx 常用配置清单 最强整理!常用正则表达式速查手册 七年老运维实战中的 Shell 开发经验总结 快速入门 Ansible 自动化运维工具 | 16张图 12年资深运维老司机的成长感悟 搭建一套完整的企业级 K8s 集群(v1.20,二进制方式)
点亮,服务器三年不宕机

