
抖音、腾讯、阿里、美团春招服务端开发岗位硬核面试(完结)
在上一篇 我们中,我们分享了几大互联网公司面试的题目,本文就来详细分析面试题答案以及复习参考和整理的面试资料,小民同学的私藏珍品?。
首先是面试题答案公布,在讲解时我们主要分成如下几块:语言的基础知识、中间件、操作系统、计算机网络、手写算法、开放题和项目经历。对面试题和涉及的知识点进行整理,这样更容易让各位同学理解。不会按照提问的顺序进行讲解,还请见谅。
其次是 Java 复习参考和整理的面试资料。由于内容比较多,学习有 道 非常重要,我们介绍一下其中的要点和目录,完整文件可以参见笔者提供的 pdf 资料。
本文较长,可以收藏再看!
面试题解析
jenkins 如何使用?
jenkins 涉及到 DevOps 相关的知识,主要用于自动化集成,持续、自动地构建/测试软件项目,监控一些定时任务。
持续集成(CI)已成为当前许多软件开发团队在整个软件开发生命周期内侧重于保证代码质量的常见做法。它是一种实践,旨在缓和和稳固软件的构建过程。
MVCC 在读方面有什么用途
MySQL的大多数事务型存储引擎实现的都不是简单的行级锁。基于提升并发性能的考虑,它们一般都同时实现了多版本并发控制(MVCC)。不同存储引擎的 MVCC 实现是不同的,典型的有乐观(optimistic)并发控制和悲观(pessimistic)并发控制。
MVCC 简单来讲就是对数据库的任何修改的提交都不会直接覆盖之前的数据,而是产生一个新的版本与老版本共存,使得读取时可以完全不加锁。这样读某一个数据时,事务可以根据隔离级别选择要读取哪个版本的数据。过程中完全不需要加锁。
可以认为 MVCC 是行级锁的一个变种,但是它在很多情况下避免了加锁操作,因此开销更低。大多数的 MVCC 都实现了非阻塞的读操作,写操作也只锁定必要的行。MVCC只能在可重复读和可提交读的隔离级别下生效。不可提交读不能使用它的原因是不能读取符合事务版本的行版本。它们总是读取最新的行版本。可序列化不能使用MVCC的原因是,它总是要锁定行。
MVCC 的实现,是通过保存数据在某个时间点的快照来实现的。也就是说,不管需要执行多长时间,每个事务看到的数据是一致的。根据事务开始的时间不同,每个事务对同一张表,同一时刻看到的数据可能是不一样的。
mysql orderby 如何实现
MySQL有两种方式可以实现ORDER BY:
通过索引扫描生成有序的结果
使用文件排序(filesort)
利用有序索引获取有序数据
取出满足过滤条件作为排序条件的字段,以及可以直接定位到行数据的行指针信息,在 Sort Buffer 中进行实际的排序操作,然后利用排好序的数据根据行指针信息返回表中取得客户端请求的其他字段的数据,再返回给客户端。
这种方式,在使用explain分析查询的时候,显示Using index。而文件排序显示Using filesort。
SQL语句中,WHERE子句和ORDER BY子句都可以使用索引:WHERE 子句使用索引避免全表扫描,ORDER BY 子句使用索引避免 filesort(用“避免”可能有些欠妥,某些场景下全表扫描、filesort 未必比走索引慢),以提高查询效率。
虽然索引能提高查询效率,但在一条 SQL 里,对于一张表的查询 一次只能使用一个索引(注:排除发生 index merge 的可能性),也就是说当 WHERE 子句与ORDER BY子句要使用的索引不一致时,MySQL 只能使用其中一个索引(B+树)。
也就是说,一个既有WHERE又有ORDER BY的SQL中,使用索引有三个可能的场景:
只用于WHERE子句 筛选出满足条件的数据
只用于ORDER BY子句 返回排序后的结果
既用于WHERE又用于ORDER BY,筛选出满足条件的数据并返回排序后的结果
文件排序(filesort)
filesort仅仅是排序而已,是否会放入磁盘看情况而定。filesort是否会使用磁盘取决于它操作的数据量大小。总结来说就是,filesort按排序方式来划分 分为两种:
数据量小时,在内存中快排
数据量大时,在内存中分块快排,再在磁盘上将各个块做归并
数据量大的情况下涉及到磁盘 io,所以效率会低一些。根据回表查询的次数,filesort又可以分为两种方式:
回表读取两次数据(two-pass):两次传输排序
回表读取一次数据(single-pass):单次传输排序
单次传输排序的弊端在于会将所有涉及到的列都放入排序缓冲区,排序缓冲区一次能放下的tuples更少了,进行归并排序的概率增大。列数据量越大,需要的归并路数更多,增加了额外的I/O开销。所以列数据量太大时,单次传输排序的效率可能还不如两次传输排序。
两次传输排序会进行两次回表操作:第一次回表用于在WHERE子句中筛选出满足条件的rowid以及rowid对应的ORDER BY的列值;第二次回表发生在ORDER BY子句对指定列进行排序之后,通过rowid回表查出SELECT子句需要的字段信息。
mysql 索引 orderby 之后的字段要不要加进去
对于order by字段加入索引本身这个问题,如果最终的结果集是以order by字段为条件筛选的,将order by字段加入索引,并放在索引中正确的位置,会有明显的性能提升。
eureka源码
Eureka 是 Spring Cloud 推荐的服务注册与发现组件,包括Eureka Server 和 Eureka Client:
Eureka Server提供服务注册服务,各个节点启动后,会在Eureka Server中注册,这样Server中的服务注册表中将会存储所有可用的服务节点的信息;
Eureka Client是一个Java客户端,用于简化与Eureka Server交互,客户端同时具备一个内置的、使用轮询负载均衡算法的负载均衡器;
在应用启动后,将会向Eureka Server发送心跳(默认周期30s),如果Eureka Server在多个心跳周期没有收到某个节点的心跳,Eureka Server会从服务注册表中把这个服务节点删除(默认为90s);
Eureka Server之间通过复制的方式完成数据的同步;
Eureka Client具有缓冲机制,如果Eureka Server全部宕机的情况,客户端依然可以利用缓存的信息消费其他服务API;
Eureka region可以理解为地理上的分区,没有具体大小的限制;
Eureka zone可以理解为region内具体的机房信息;
使用Jersey框架实现自身的Restful HTTP接口,peer之间同步与服务注册通过HTTP协议实现,定时任务(发送心跳、定时清理过期服务、节点同步等)通过JDK自带的Timer实现,内存缓存实现Google的guava实现;
当服务注册中心Server检测服务提供者宕机时,在服务中心将服务置为DOWN状态,并将该服务向其他订阅者发布,订阅者更新本地缓存信息;
当Eureka Server节点在短时间内丢失过多的客户端时,这个节点会进入自我保护模式,不再注销任何服务;
Hystrix源码
分布式系统环境下,服务间类似依赖非常常见,一个业务调用通常依赖多个基础服务。如下图,对于同步调用,当库存服务不可用时,商品服务请求线程被阻塞,当有大批量请求调用库存服务时,最终可能导致整个商品服务资源耗尽,无法继续对外提供服务。并且这种不可用可能沿请求调用链向上传递,这种现象被称为雪崩效应。
Hystrix 中文含义是豪猪,因其背上长满棘刺,从而拥有了自我保护的能力。
Hystrix设计目标
对来自依赖的延迟和故障进行防护和控制——这些依赖通常都是通过网络访问的
阻止故障的连锁反应
快速失败并迅速恢复
回退并优雅降级
提供近实时的监控与告警
Hystrix遵循的设计原则
防止任何单独的依赖耗尽资源(线程)
过载立即切断并快速失败,防止排队
尽可能提供回退以保护用户免受故障
使用隔离技术(例如隔板,泳道和断路器模式)来限制任何一个依赖的影响
通过近实时的指标,监控和告警,确保故障被及时发现
通过动态修改配置属性,确保故障及时恢复
防止整个依赖客户端执行失败,而不仅仅是网络通信
分布式锁实现方式?
分布式锁在微服务架构中很常用,主要有几下实现方式:
基于数据库做分布式锁
基于表主键唯一做分布式锁
思路:利用主键唯一的特性,如果有多个请求同时提交到数据库,数据库只会保证只有一个操作可以成功,那么就可以认为操作成功的线程获取到了该方法的锁。当方法执行完毕之后,通过删除该行数据就可释放锁。
单点数据库导致强依赖,可以通过多数据库主从切换
通过定时器删除超时数据避免死锁
通过自旋CAS的方式插入实现阻塞
可重入可以通过检查对应的记录是否存在实现
公平锁可以通过等待线程表的方式实现
在大并发的情况下,通过主键冲突防重容易导致锁表,尽量在程序中生产主键进行防重
基于表字段版本号做分布式锁
基于mysql的mvcc机制,只有版本号一致才能进行对应的修改,修改后版本号加1,通过CAS的方式进行修改。
基于数据库排他锁做分布锁
通过事务和 for update 语句实现,数据库会在该事务下给数据库增加排他锁。在 InnoDB 引擎加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则使用表级锁。
基于Redis做分布锁
基于Redis的SETNX()、EXPIRE()方法做分布式锁
setnx 方法的语义为 SET if Not Exists,其主要有两个参数,setnx(key, value)。该方法是原子的,如果 key 不存在,则设置当前的 key 成功,返回1;如果当前 key 已经存在,则设置当前 key 失败,返回 0。
expire 方法设置过期时间,setnx 命令不能设置 key 的超时时间,只能通过 expire() 来对 key 设置。
如果在 setnx 执行成功后,在 expire 命令执行成功,执行的线程出现宕机的现象,就可能出现死锁现象。
基于 Redis 的 SETNX()、GET()、GETSET() 方法做分布式锁
getset方法有两个参数 getset(key,newValue)。该方法是原子的,对 key 设置 newValue 这个值,并且返回 key 原来的旧值。假设 key 原来是不存在的,那么多次执行这个命令,会出现下边的效果:getset(key, “value1”) 返回 null 此时 key 的值会被设置为 value1;getset(key, “value2”) 返回 value1 此时 key 的值会被设置为 value2。
使用步骤:setnx(lockkey,当前时间+过期超时时间),如果返回 1,则获取锁成功;如果返回0则没有获取到锁,转向2。
get(lockkey) 获取值 oldExpireTime,并将这个 value 值与当前的系统时间进行比较,如果小于当前系统时间,则认为这个锁已经超时,可以允许别的请求重新获取,转向 3。
计算 newExpireTime = 当前时间 + 过期超时时间,然后 getset(lockkey, newExpireTime) 会返回当前 lockkey 的值 currentExpireTime。
判断 currentExpireTime 与 oldExpireTime 是否相等,如果相等,说明当前 getset 设置成功,获取到了锁。如果不相等,说明这个锁又被别的请求获取走了,那么当前请求可以直接返回失败,或者继续重试。
在获取到锁之后,当前线程可以开始自己的业务处理,当处理完毕后,比较自己的处理时间和对于锁设置的超时时间,如果小于锁设置的超时时间,则直接执行 delete 释放锁;如果大于锁设置的超时时间,则不需要再锁进行处理。
基于 REDLOCK 做分布式锁
Redlock 是 Redis 的作者开发的集群模式的 Redis 分布式锁,它基于 N 个完全独立的 Redis 节点.
客户端获取当前时间,以毫秒为单位。客户端尝试获取N个节点的锁(每个节点获取锁的方式和前面说的缓存锁一样),N 个节点以相同的 key 和 value 获取锁。客户端需要设置接口访问超时,接口超时时间需要远远小于锁超时时间,比如锁自动释放的时间是 10s,那么接口超时大概设置5-50ms。这样可以在有redis节点宕机后,访问该节点时能尽快超时,而减小锁的正常使用。
客户端计算在获得锁的时候花费了多少时间,方法是用当前时间减去在步骤一获取的时间,只有客户端获得了超过3个节点的锁,而且获取锁的时间小于锁的超时时间,客户端才获得了分布式锁。
客户端获取的锁的时间为设置的锁超时时间减去步骤三计算出的获取锁花费时间。
如果客户端获取锁失败了,客户端会依次删除所有的锁。
基于 REDISSON 做分布式锁
Redisson 是 redis 官方的分布式锁组件。在Redisson中,如果如果线程获取锁成功,Redisson会在后台起开一个定时任务watchdog,定时任务会定时检查调用renewExpirationAsync(threadId)对锁进行续约。定时调度的时间差为internalLockLeaseTime/3,即10秒,默认加锁时间为30s。
基于 Consul 做分布式锁
基于Consul的分布式锁主要利用Key/Value存储API中的acquire和release操作来实现。acquire和release操作是类似Check-And-Set的操作。
acquire操作只有当锁不存在持有者时才会返回true,并且set设置的Value值,同时执行操作的session会持有对该Key的锁,否则就返回false
release操作则是使用指定的session来释放某个Key的锁,如果指定的session无效,那么会返回 false,否则就会set设置 Value 值,并返回 true。
zk的原理 源码
Zookeeper 有如下的角色:
领导者(leader),负责进行投票的发起和决议,更新系统状态
学习者(learner),包括跟随者(follower)和观察者(observer),follower用于接受客户端请求并想客户端返回结果,在选主过程中参与投票
Observer可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度
客户端(client),请求发起方
Zookeeper 的核心是原子广播,这个机制保证了各个server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式和广播模式。
当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数server的完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和server具有相同的系统状态
一旦leader已经和多数的follower进行了状态同步后,他就可以开始广播消息了,即进入广播状态。这时候当一个server加入zookeeper服务中,它会在恢复模式下启动,发现leader,并和leader进行状态同步。待到同步结束,它也参与消息广播。Zookeeper服务一直维持在 Broadcast 状态,直到leader崩溃了或者leader失去了大部分的followers支持。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识 leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
高级开发工程师的面试一般都会涉及源码,为什么很多同学觉得原理、源码是造火箭,其实这个和自己的经历是有很大关系的。首先不排除,确实又一部分面试题的确是造火箭。很多同学做的项目比较简单,就拿 Java 举例,业务可能增删改查居多,长久就形成了工作并不需要看源码,甚至觉得阅读源码、熟悉原理对自己帮助并不大的错觉。看优秀的源码是一种更深入的学习。
序列化方式
首先理解序列化和反序列化。
序列化:可以将对象转化成一个字节序列,便于存储。
反序列化:将序列化的字节序列还原
优点:可以实现对象的"持久性”, 所谓持久性就是指对象的生命周期不取决于程序。
Java 中的序列化方式包括Java原生以流的方法进行的序列化、Json序列化、FastJson序列化、Protobuff序列化。Protobuff序列化支持跨语言。
Java原生序列化
Java原生序列化方法即通过Java原生流(InputStream和OutputStream之间的转化)的方式进行转化。需要注意的是JavaBean实体类必须实现Serializable接口,否则无法序列化。
Json序列化
Json序列化一般会使用jackson包,通过ObjectMapper类来进行一些操作,比如将对象转化为byte数组或者将json串转化为对象。现在的大多数公司都将json作为服务器端返回的数据格式。比如调用一个服务器接口,通常的请求为xxx.json?a=xxx&b=xxx的形式。
FastJson序列化
fastjson 是由阿里巴巴开发的一个性能很好的Java 语言实现的 Json解析器和生成器。特点:速度快,测试表明fastjson具有极快的性能,超越任其他的java json parser。功能强大,完全支持java bean、集合、Map、日期、Enum,支持范型和自省。无依赖,能够直接运行在Java SE 5.0以上版本支持Android。使用时候需引入FastJson第三方jar包。
ProtoBuff序列化
ProtocolBuffer是一种轻便高效的结构化数据存储格式,可以用于结构化数据序列化。适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
优点:跨语言;序列化后数据占用空间比JSON小,JSON有一定的格式,在数据量上还有可以压缩的空间。
缺点:它以二进制的方式存储,无法直接读取编辑,除非你有 .proto 定义,否则无法直接读出 Protobuffer的任何内容。
其与thrift的对比:两者语法类似,都支持版本向后兼容和向前兼容,thrift侧重点是构建跨语言的可伸缩的服务,支持的语言多,同时提供了全套RPC解决方案,可以很方便的直接构建服务,不需要做太多其他的工作。Protobuffer主要是一种序列化机制,在数据序列化上进行性能比较,Protobuffer相对较好。
ProtoBuff序列化对象可以很大程度上将其压缩,可以大大减少数据传输大小,提高系统性能。对于大量数据的缓存,也可以提高缓存中数据存储量。原始的ProtoBuff需要自己写.proto文件,通过编译器将其转换为java文件,显得比较繁琐。百度研发的jprotobuf框架将Google原始的protobuf进行了封装,对其进行简化,仅提供序列化和反序列化方法。其实用上也比较简洁,通过对JavaBean中的字段进行注解就行,不需要撰写.proto文件和实用编译器将其生成.java文件,百度的jprotobuf都替我们做了这些事情了。
redis 持久化
redis是一个内存数据库,数据保存在内存中,但是我们都知道内存的数据变化是很快的,也容易发生丢失。幸好 Redis 还为我们提供了持久化的机制,分别是RDB(Redis DataBase)和 AOF(Append Only File)。
RDB 机制
RDB 其实就是把数据以快照的形式保存在磁盘上。快照可以理解成把当前时刻的数据拍成一张照片保存下来。
RDB 持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。也是默认的持久化方式,这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为 dump.rdb。
RDB 机制是通过把某个时刻的所有数据生成一个快照来保存,那么就应该有一种触发机制,是实现这个过程。对于 RDB 来说,提供了三种机制:save、bgsave、自动化。我们分别来看一下:
save:该命令会阻塞当前 Redis 服务器,执行 save 命令期间,Redis 不能处理其他命令,直到 RDB 过程完成为止。
bgsave 触发方式:执行该命令时,Redis 会在后台异步进行快照操作,快照同时还可以响应客户端请求。
自动触发:自动触发是由我们的配置文件来完成的。
RDB 具有如下的优势:
RDB 文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。
生成 RDB 文件的时候,redis 主进程会 fork() 一个子进程来处理所有保存工作,主进程不需要进行任何磁盘 IO 操作。
RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
也存在不足之处,RDB 快照是一次全量备份,存储的是内存数据的二进制序列化形式,存储上非常紧凑。当进行快照持久化时,会开启一个子进程专门负责快照持久化,子进程会拥有父进程的内存数据,父进程修改内存子进程不会反应出来,所以在快照持久化期间修改的数据不会被保存,可能丢失数据。
AOF
全量备份总是耗时的,有时候我们提供一种更加高效的方式 AOF,工作机制很简单,redis 会将每一个收到的写命令都通过 write 函数追加到文件中。通俗的理解就是日志记录。
AOF 的方式也同时带来了另一个问题。持久化文件会变的越来越大。为了压缩 AOF 的持久化文件。redis 提供了 bgrewriteaof 命令。将内存中的数据以命令的方式保存到临时文件中,同时会 fork 出一条新进程来将文件重写。重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
AOF也有三种触发机制:
每修改同步always:同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
每秒同步everysec:异步操作,每秒记录 如果一秒内宕机,有数据丢失
不同no:从不同步
AOF 可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据;AOF日志文件没有任何磁盘寻址的开销,写入性能非常高,文件不容易破损;AOF 日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写;AOF 日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用 flushall 命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝 AOF 文件,将最后一条 flushall 命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据。
当然,对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大;AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高;以前AOF发生过bug,就是通过AOF记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。
redis 主从复制
和Mysql主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况。为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步。下图为级联结构。
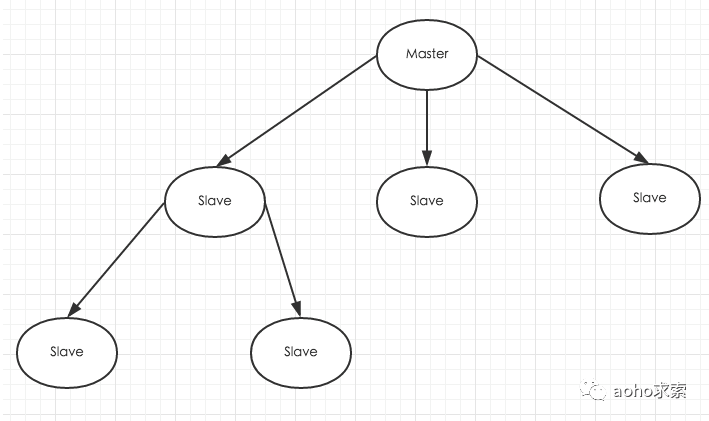
全量同步
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
从服务器连接主服务器,发送SYNC命令;
主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
增量同步
Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
Redis主从同步策略
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
Redis主从复制的配置十分简单,它可以使从服务器是主服务器的完全拷贝。需要清除Redis主从复制的几点重要内容:
Redis使用异步复制。但从Redis 2.8开始,从服务器会周期性的应答从复制流中处理的数据量。
一个主服务器可以有多个从服务器。
从服务器也可以接受其他从服务器的连接。除了多个从服务器连接到一个主服务器之外,多个从服务器也可以连接到一个从服务器上,形成一个图状结构。
Redis主从复制不阻塞主服务器端。也就是说当若干个从服务器在进行初始同步时,主服务器仍然可以处理请求。
主从复制也不阻塞从服务器端。当从服务器进行初始同步时,它使用旧版本的数据来应对查询请求,假设你在redis.conf配置文件是这么配置的。否则的话,你可以配置当复制流关闭时让从服务器给客户端返回一个错误。但是,当初始同步完成后,需要删除旧的数据集和加载新的数据集,在这个短暂的时间内,从服务器会阻塞连接进来的请求。
主从复制可以用来增强扩展性,使用多个从服务器来处理只读的请求(比如,繁重的排序操作可以放到从服务器去做),也可以简单的用来做数据冗余。
使用主从复制可以为主服务器免除把数据写入磁盘的消耗:在主服务器的redis.conf文件中配置“避免保存”(注释掉所有“保存“命令),然后连接一个配置为“进行保存”的从服务器即可。但是这个配置要确保主服务器不会自动重启
主从复制结构,一般slave服务器不能进行写操作,但是这不是死的,之所以这样是为了更容易的保证主和各个从之间数据的一致性,如果slave服务器上数据进行了修改,那么要保证所有主从服务器都能一致,可能在结构上和处理逻辑上更为负责。不过你也可以通过配置文件让从服务器支持写操作。
主从服务器之间会定期进行通话,但是如果master上设置了密码,那么如果不给slave设置密码就会导致slave不能跟master进行任何操作,所以如果你的master服务器上有密码,那么也给slave相应的设置密码。
为什么要使用 Spring Cloud
spring Cloud 通过 Spring Boot 封装了各家公司开发的一系列成熟、稳定的服务框架,去除了繁琐的配置,给开发者提供了一套简单易用、方便部署、易于维护的分布式系统开发工具包。spring Boot 是 Spring 的一套快速配置脚手架,可以基于 Spring Boot 快速开发单个微服务,Spring Boot 专注于快速、方便的集成单个个体,Spring Cloud 关注全局的服务治理框架。
Spring Boot 可以离开 Spring Cloud 独立使用开发项目,但是 Spring Cloud 离不开 Spring Boot,属于依赖关系。
微服务注册中心原理
注册中心主要涉及到三大角色:
服务提供者
服务消费者
注册中心
它们之间的关系大致如下:
各个微服务在启动时,将自己的网络地址等信息注册到注册中心,注册中心存储这些数据。
服务消费者从注册中心查询服务提供者的地址,并通过该地址调用服务提供者的接口。
各个微服务与注册中心使用一定机制(例如心跳)通信。如果注册中心与某微服务长时间无法通信,就会注销该实例。
微服务网络地址发送变化(例如实例增加或IP变动等)时,会重新注册到注册中心。这样,服务消费者就无需人工修改提供者的网络地址了。
注册服务怎么判断上线下线
服务启动之时如果端口部署成功,会调用注册中心提供的服务注册API将自身网络地址等数据提交到服务注册与发现中完成注册;
注册中心会通过一定的机制(例如心跳)与注册表中的微服务实例保持通信,如果注册中心长时间无法与该微服务实例通信,将会从注册表中剔除该服务实例信息;
微服务实例在关闭时会主动调用注册中心提供的下线接口,将自身微服务实例数据从注册表中注销。
操作系统与计算机网络
访问一个 url 发生了什么
当我们在浏览器的地址栏输入 www.google.com ,然后回车,回车这一瞬间到看到页面到底发生了什么呢?
根据属于的域名,进行DNS域名解析
Chrome 浏览器会首先搜索浏览器自身的 DNS 缓存(缓存时间比较短,且只能容纳 1000 条缓存),看自身的缓存中是否有 www.google.com 对应的条目,而且没有过期,如果有且没有过期则解析到此结束。
如果浏览器自身的缓存里面没有找到对应的条目,那么 Chrome 会搜索操作系统自身的DNS缓存,如果找到且没有过期则停止搜索解析到此结束。
如果在系统的DNS缓存也没有找到,那么尝试读取 hosts 文件,看看这里面有没有该域名对应的IP地址,如果有则解析成功。
如果在 hosts 文件中也没有找到对应的条目,浏览器就会发起一个 DNS 的系统调用,就会向本地配置的首选 DNS 服务器发起域名解析请求,运营商的 DNS 服务器首先查找自身的缓存,找到对应的条目,且没有过期,则解析成功。如果没有找到对应的条目,则有运营商的 DNS 代我们的浏览器发起迭代 DNS 解析请求。
解析到IP地址,建立TCP连接
拿到域名对应的IP地址之后,User-Agent(一般是指浏览器)会以一个随机端口(1024 < 端口 < 65535)向服务器的WEB程序(常用的有 httpd,nginx等)80 端口发起 TCP 的连接请求。这个连接请求(原始的http请求经过TCP/IP4层模型的层层封包)到达服务器端后(这中间通过各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的 TCP/IP 协议栈(用于识别该连接请求,解封包,一层一层的剥开),还有可能要经过 Netfilter 防火墙(属于内核的模块)的过滤,最终到达WEB程序(以Nginx为例),最终建立了 TCP/IP 的连接。
发送HTTP请求
TCP 3 次握手之后,浏览器发起了http的请求(看第包),使用的http的方法 GET 方法,请求的URL是 / ,协议是HTTP/1.0。
服务器处理请求,并返回响应结果
服务器端 WEB 程序接收到 http 请求以后,就开始处理该请求,处理之后就返回给浏览器 html 文件。关闭TCP连接。
浏览器解析HTML
浏览器拿到index.html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载(会使用多线程下载,每个浏览器的线程数不一样),这个时候就用上 keep-alive 特性了,建立一次 HTTP 连接,可以请求多个资源,下载资源的顺序就是按照代码里的顺序,但是由于每个资源大小不一样,而浏览器又多线程请求请求资源,所以从下图看出,这里显示的顺序并不一定是代码里面的顺序。
浏览器在请求静态资源时(在未过期的情况下),向服务器端发起一个http请求(询问自从上一次修改时间到现在有没有对资源进行修改),如果服务器端返回304状态码(告诉浏览器服务器端没有修改),那么浏览器会直接读取本地的该资源的缓存文件。
浏览器布局渲染
最后,浏览器利用自己内部的工作机制,把请求到的静态资源和html代码进行渲染,渲染之后呈现给用户。
操作系统两个进程写共享内存中一个位置 会不会出现不一致?
共享内存就是允许两个或多个进程共享一定的存储区。就如同 malloc() 函数向不同进程返回了指向同一个物理内存区域的指针。当一个进程改变了这块地址中的内容的时候,其它进程都会察觉到这个更改。因为数据不需要在客户机和服务器端之间复制,数据直接写到内存,不用若干次数据拷贝,所以这是最快的一种 IPC。
但是,当有多个程序同时向共享内存中读写数据时,问题就会出现。共享内存没有提供同步的机制,这使得我们在使用共享内存进行进程间通信时,往往要借助其他的手段来进行进程间的同步工作。
http 请求 api 超时如何实现的
网关和 rpc 负载均衡进行配置,比如在 API 网关统一配置接口的超时时间。在单个微服务中,服务之间的调用配置超时时间,如 Ribbon Timeout。
http 协议是什么
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。基于TCP的应用层协议,它不关心数据传输的细节,HTTP(超文本传输协议)是一个基于请求与响应模式的、无状态的、应用层的协议,只有遵循统一的 HTTP 请求格式,服务器才能正确解析不同客户端发的请求,同样地,服务器遵循统一的响应格式,客户端才得以正确解析不同网站发过来的响应。
HTTP 请求由请求行、请求头、空行、请求体组成
请求行:请求方式 + URL + 协议版本
常见的请求方法有 GET、POST、PUT、DELETE、HEAD
客户端要获取的资源路径(所谓的 URL)
客户端使用的 HTTP 协议版本号(使用的是 http1.1)
请求头:客户端向服务器发送请求的补充说明:
host:请求地址
User-Agent:客户端使用的操作系统和浏览器的名称和版本.
Content-Length:发送给HTTP服务器数据的长度。
Content-Type:参数的数据类型
Cookie:将cookie的值发送给HTTP 服务器
Accept-Charset:自己接收的字符集
Accept-Language:浏览器自己接收的语言
Accept:浏览器接受的媒体类型
请求体:一般携带的请求参数
application/json:{"name":"value","name1":"value2”}
application/x-www-form-urlencoded:name1=value1&name2=value2
multipart/from-data:表格形式
text/xml
content-type:octets/stream
POST 请求有哪些字段
在HTTP的请求头中,可以使用Content-type来指定不同格式的请求信息。HTTP协议规定 POST 提交的数据必须放在消息主体(entity-body)中,但协议并没有规定数据必须 使用什么编码方式 。实际上,开发者完全可以自己决定消息主体的格式,只要最后发送的 HTTP 请求满足上面的格式就可以。
数据发送出去,还要服务端解析成功才有意义。一般服务端语言如 php、python 等,以及它们的 framework,都内置了自动解析常见数据格式的功能。服务端通常是根据请求头(headers)中的 Content-Type 字段来获知请求中的消息主体是用何种方式编码,再对主体进行解析。
form表单中enctype属性可以用来控制对表单数据的发送前的如何进行编码,enctype有三种,分别为:
multipart/form-data不对字符编码,用于发送二进制的文件,其他两种类型不能用于发送文件;
text/plain用于发送纯文本内容,空格转换为 "+" 加号,不对特殊字符进行编码,一般用于email之类的;
application/x-www-form-urlencoded,在发送前会编码所有字符,即在发送到服务器之前,所有字符都会进行编码(空格转换为 "+" 加号,"+"加号转换为空格,特殊符号转换为 ASCII HEX 值)。
其中 application/x-www-form-urlencoded 为默认类型。
HTTPS 和HTTP区别是什么?HTTPS 客户端服务器怎么交互的?
HTTPS:是以安全为目标的 HTTP 通道,简单讲是 HTTP 的安全版,即 HTTP 下加入 SSL 层,HTTPS 的安全基础是 SSL,因此加密的详细内容就需要 SSL。
HTTPS 协议的主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。
HTTP 协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。简单来说,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
HTTPS和HTTP的区别主要如下:
https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
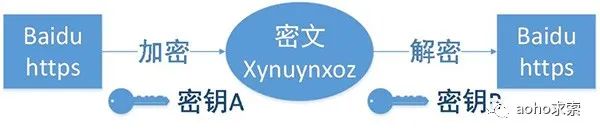
客户端在使用HTTPS方式与Web服务器通信时有以下几个步骤:
客户使用 https 的 URL 访问 Web 服务器,要求与 Web 服务器建立 SSL 连接。
Web 服务器收到客户端请求后,会将网站的证书信息(证书中包含公钥)传送一份给客户端。
客户端的浏览器与 Web 服务器开始协商SSL连接的安全等级,也就是信息加密的等级。
客户端的浏览器根据双方同意的安全等级,建立会话密钥,然后利用网站的公钥将会话密钥加密,并传送给网站。
Web服务器利用自己的私钥解密出会话密钥。
Web服务器利用会话密钥加密与客户端之间的通信。
尽管HTTPS并非绝对安全,掌握根证书的机构、掌握加密算法的组织同样可以进行中间人形式的攻击,但HTTPS仍是现行架构下最安全的解决方案。
滑动窗口 -> 客户端和服务器端分别有哪些区域(已确认 传输未确认 未传输)
大家都知道,我们从一台机器向另外一台机器发送数据的时候,数据并不是一口气也不可能一口气传输给接收方。这个并不难理解,因为网络环境特别的复杂,有些地方快有些地方慢。所以,操作系统把这些数据写成连续的数据包,并且以一定的速率发给对方。
我们要考虑到带宽缓冲区等因素,如果一下子发送所有的数据只会加大网络压力,造成丢包重试,轻则传输更慢,重则网络崩溃。因为TCP是顺序发送的,操作系统将这些数据包一批一批的发送给对方,就像一个窗口,不停地往后移动,所以,我们称之为TCP滑动窗口协议。
在TCP中,窗口的大小是在TCP三次握手后协定的,并且窗口的大小并不是固定的,而是会随着网络的情况进行调整。TCP为了更好的传输效率,就会调整窗口的大小。TCP 通过滑动窗口机制检测丢包,并在丢包发生时调整数据传输速率。
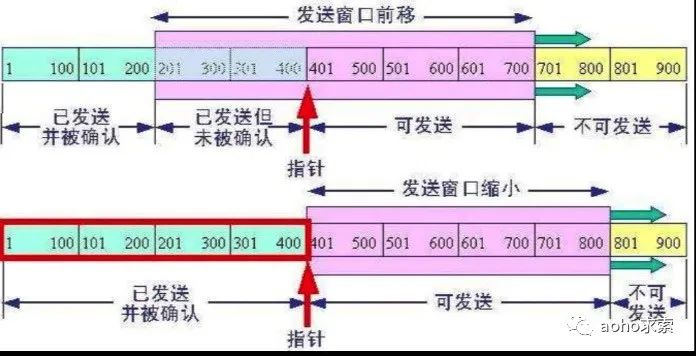
对于发送端来说,即将要发送的数据包排成一个队列,对于发送者来说,数据包总共分成四类。分别是在窗口前的,已经发送给接收方,并且收到了接收方的答复,我们称之为已发送。在窗口中的,有两种状态,一个是已经发送给接收方,但是接收方还没确认送达,我们称之为已发送未确认,另外一个是可以发送了,但是还没有发送,我们称之为允许发送未发送。最后的是在窗口外面的,我们称之为不可发送,除非窗口滑到此处,否则不会进行发送。
一旦前面的数据已经得到服务端确认了,这个窗口就会慢慢地往后滑,如下图所示,P1,P2两个数据包被确认之后,窗口就往后移动,后面新的数据包就由不可发送待发送变成了可发送状态了。
TCP的滑动窗口协议有什么意义呢?首先当然是可靠性,滑动窗口只有在队列前部的被确认之后,才会往后移动,保证数据包被接收方确认并接收。其次是传输效率,假如没有窗口,服务端是杂乱无章地进行发包,因为TCP的队首效应,如果有前面的包没有发送成功,就会不停的重试,反而造成更差的传输效率。最后是稳定性,TCP的滑动窗口大小,是整个复杂网络商榷的结果,会进行动态调整,可以尽量地避免网络拥塞,更加稳定。
dns 是什么原理
当前大部分的网络访问都是基于 TCP/IP 协议开发,而 TCP/IP 是基于 IP 寻址的。又因为大多数人记不住没有意义的 ip 地址,因此希望使用一些简单的域名代替地址,而 DNS 就充当了这样一个“翻译器”。我们输入域名,DNS帮我们查询对应的域名绑定的IP地址。
http 握手的 wait time
根据 tcp 关闭时四次握手流程,主动关闭方会在发送完最后的ACK包后进入time_wait 状态,该状态持续时间为 2MSL (MSL 是指报文的最大生存时间,超过 MSL 时间没被接受的数据包将会被丢弃,RFC793 中建议为 2 min),时间到达后将进入 close 状态,关闭本次 tcp 连接。
主动关闭方进入2MSL的 time_wait 状态的目的有二:
保证本次tcp连接中产生的所有数据包都在网络中消亡,避免本次tcp连接中产生但延迟到达的数据包影响到新建 tcp 连接的使用;
保证被动关闭方能够收到最后的 ACK。如果最后的 ACK 在网络传递中丢失了,那么被动关闭方就会重传FIN包。而主动关闭方就能在这 2MSL 时间内接受到这个 FIN 包,并重新发送 ACK 包,重新启动 2MSL 计时。
延伸一下,如果在tcp客户端出现大量的time_wait状态该如何处理?
提示一下连接复用。
算法相关
计算题:扑克牌两张王的概率
第一百次抽取可以从54张牌中抽大小王中度的一张,概率为2/54=1/27。第二次只能从53张牌中抽到那张知剩下的王,概率道为1/53。所以抽专两张是大小王的概率=(1/27)*(1/53)=1/1431。
算法稳定性的实际作用
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序中,Ai=Aj,且Ai在Aj之前,在排序后的序列中,Ai仍在Aj之前,则称这种排序算法是稳定的;否则该算法是不稳定的。
要排序的内容是一个复杂对象的多个数字属性,且其原本的初始顺序存在意义,那么我们需要在二次排序的基础上保持原有排序的意义,才需要使用到稳定性的算法,例如要排序的内容是一组原本按照价格高低排序的对象,如今需要按照销量高低排序,使用稳定性算法,可以使得想同销量的对象依旧保持着价格高低的排序展现,只有销量不同的才会重新排序。(当然,如果需求不需要保持初始的排序意义,那么使用稳定性算法依旧将毫无意义)。
如果只是简单的进行数字的排序,那么稳定性将毫无意义。
如果排序的内容仅仅是一个复杂对象的某一个数字属性,那么稳定性依旧将毫无意义(正如上面说的,会增大一定的开销,但并不起决定性因素,算法本身的开销才是关键——比如换种算法)
如果要排序的内容是一个复杂对象的多个数字属性,但是其原本的初始顺序毫无意义,那么稳定性依旧将毫无意义。
算法:第 K 大的元素
在长度为 N 的乱序数组中寻找第k(n>=k)大的元素。
有好几种方法:
方法一:排序法,先把无序数组从大到小进行排序,排序后的第k个元素自然就是数组中的第k大元素。但是这种方法的时间复杂度是O(nlogn),性能有些差。
方法二:插入法,维护一个长度为k的数组A的有序数组,用于存储已知的K个较大的元素。然后遍历无序数组,每遍历到一个元素,和数组A中的最小元素进行比较,如果小于等于数组A中的最小元素,继续遍历;如果大于数组A中的最小元素,则插入到数组A中,并把曾经的最小元素"挤出去"。时间复杂度为O(N*k),适用于k相对于N很小的情况。
方法三:小顶堆法,维护一个容量为K的小顶堆,堆中的K个节点代表着当前最大的K个元素,而堆顶显然是这K个元素中的最小值。遍历原数组,每遍历一个元素,就和堆顶比较,如果当前元素小于等于堆顶,则继续遍历;如果元素大于堆顶,则把当前元素放在堆顶位置,并调整二叉堆(下沉操作)。遍历结束后,堆顶就是数组的最大K个元素中的最小值,也就是第K大元素。当k远小于n的情况下,也可以近似地认为时间复杂度是O(nlogk)。
方法四:分治法,快速排序利用分治法,每一次把数组分成较大和较小元素两部分。我们在寻找第K大元素的时候,也可以利用这个思路,以某个元素A为基准,把大于A的元素都交换到数组左边,小于A的元素交换到数组右边。
下面我们基于方法三进行实现算法:
public static int findNumberK(int[] array, int k) {
//1.用前k个元素构建小顶堆
buildHeap(array, k);
//2.继续遍历数组,和堆顶比较
for (int i = k; i < array.length; i++) {
if(array[i] > array[0]) {
array[0] = array[i];
downAdjust(array, 0, k);
}
}
//3.返回堆顶元素
return array[0];
}
private static void buildHeap(int[] array, int length) {
//从最后一个非叶子节点开始,依次下沉调整
for (int i = (length - 2) / 2; i >= 0; i--) {
downAdjust(array, i, length);
}
}
/**
* 下沉调整
* @param array 待调整的堆
* @param index 要下沉的节点
* @param length 堆的有效大小
*/
private static void downAdjust(int[] array, int index, int length) {
//temp保存父节点的值,用于最后的赋值
int temp = array[index];
int childIndex = 2 * index + 1;
while (childIndex < length) {
//如果有右孩子,且右孩子小于左孩子的值,则定位到右孩子
if (childIndex + 1 < length && array[childIndex + 1] < array[childIndex]) {
childIndex++;
}
//如果父节点小于任何一个孩子的值,直接跳出
if (temp <= array[childIndex])
break;
//无需真正交换,单项赋值即可
array[index] = array[childIndex];
index = childIndex;
childIndex = 2 * childIndex + 1;
}
array[index] = temp;
}
public static void main(String[] args) {
int[] array = new int[] {7, 5, 15, 3, 17, 2, 20, 24, 1, 9, 12, 8};
System.out.println(findNumberK(array, 5));
}
具体操作步骤如下:
把数组的前K个元素构建成堆。
继续遍历数组,和堆顶比较,如果小于等于堆顶,则继续遍历;如果大于堆顶,则取代堆顶元素并调整堆。
此时的堆顶,就是堆中的最小元素,也就是数组中的第 K 大元素。
算法:第一个从n个数字的数组中等概率的取出m个数字
这个模型类似抽奖的模型,有 n 张彩票,n 个人每人一张,怎样选出 m 个人出来中奖。即我们仅仅须要模拟一个公正的抽奖过程便能得到等概率的 m 个人。
我们都知道,抽奖不分先后。每一个人中奖的机率都一样。因此。最简单的做法是将 n 个人随机化排成一列,再取前 m 个人中奖就可以。
这个问题本身不难理解,但是关键的地方是等概率,还有一个隐性的条件,那就是不能重复取。
面临当前元素时。使用一个概率(这个概率可能是动态变化的。或者不变的)决定去留,若留,则与某个已选择的元素置换。以下再给出一种方法。
设 A 为源数组。B 为辅助数组(装入已选择的元素)。A 长度为 n。B 长度为 m。须要从 A 中取 m 个数字放入 B。使它们等概率。
遍历 A,在面临第 i 个元素 x 时,记 p 为还须要从 A 中选出的元素个数。q 为从 x 向后数,将 A 数完的个数。包含 x。决定 x 被选中的概率设置为 p/q。这也能够达到等概率。
1:第 0 个元素被选中的概率为 :m/n
2:第 1 个元素被选中的概率为 :m/n(m-1)/(n-1) + (1-m/n)m/(n-1) = m/n
3:第 2 个元素被选中的概率为:… = m/n
….
依此类推,不管哪个元素被选中的概率都为 m/n。以下,我们证明随意一个元素被选中的概率都为 m/n。
假设按上面的思路去证明将非常复杂。可是有一个非常巧妙的证明方法。
我们看这个问题的模型,实际上,它就是一个抽奖模型,如今有一个箱子里面装着 n 张奖券,写着“中”。或“不中”,当中。写着“中”的有 m 张,如今问。第 k 次抽奖,中奖的概率为多少?这显然为 m/n!
还记得 "抽奖与顺序无关” 吗?于是。我们独立写出第 k 次中奖的概率的表达式:
C(m,1)*A(n-1,m-1) / A(n,m) = m/n。
故,上面的操作方法,随意一个元素被选中的概率都为 m/n。
算法:找一个字符串的最长重复的子串
选用后缀,后缀字符串的前缀包含了字符串S的部分子串,只要求出字符串S的所有后缀就可间接的表示了S所有的子串。具体步骤如下:
保存S字符串的所有后缀
对所有后缀进行排序(自然排序)
比较排序后的相邻的后缀的最长公共子串(两个后缀从第一个字符开始的就相等得到公共子串),求出最长的公共子串
public class Main{
//保存最长公共子串
static String result = "";
public static void main(String [] args) throws InterruptedException {
Scanner sc = new Scanner(System.in);
String s = sc.nextLine();
ArrayList<String> list = new ArrayList<String>();
//得到字符串的所有后缀
for(int i = s.length()-1;i>=0;i--) {
list.add(s.substring(i));
}
Collections.sort(list);
int maxLen = 0;
for(int i = 0;i-1;i++) {
int len = getComlen(list.get(i),list.get(i+1));
maxLen = Math.max(maxLen, len);
}
System.out.println(result+":"+maxLen);
}
//得到两个字符串最长公共长度
public static int getComlen(String str1,String str2) {
int i;
for(i =0;i if(str1.charAt(i)!=str2.charAt(i)) {
break;
}
}
String temp = str1.substring(0,i);
if(temp.length()>result.length()) result = temp;
return i;
}
}
算法:反转每组K个节点
单链表每k个节点为一组进行反转(最后不满k个时不反转)
leetcode 原题,提供其中的一种解法如下:
public class LinkReverse {
public static Node mhead=null;
public static Node mtail=null;
public static Node newLink(int n){
Node head = new Node();
head.setData(1);
head.setNext(null);
Node tmp = head;
for(int i=2;i<=n;i++){
Node newNode = new Node();
newNode.setData(i);
newNode.setNext(null);
tmp.setNext(newNode);
tmp = newNode;
}
return head;
}
public static void main(String[] args) {
Node node = newLink(10);
pritNode(node);
// Node node1 = reverseKLink(node,3);
// Node node1 = reverse(node,2);
Node node1 = reverseLink3(node,4);
pritNode(node1);
}
public static void pritNode(Node head){
Node temp = head;
while(temp !=null){
System.out.print(temp.getData()+"->");
temp = temp.getNext();
}
System.out.println();
}
/*public static Node reverseLink(Node head){
Node pre=null,cur=head,next=null;
while(cur!=null){
next=cur.getNext();
cur.setNext(pre);
pre=cur;
cur=next;
}
return pre;
}*/
/*public static Node reverseKLink(Node head,int k){
Node pre=null,cur=head,next=null;
Node pnext=null,global_head=null;
int i=0;
Node tmp=null;
while(cur!=null){
next = cur.getNext();
if(tmp==null) tmp=cur; //tmp记录当前组反转完最后一个节点
if(pnext!=null) pnext.setNext(cur); //pnext是上一组反转完最后一个节点
cur.setNext(pre);
pre=cur;
cur = next;
i++;
if(i>=k){ //当前组反转完成的时候
if(global_head==null){
global_head=pre;
}
if(pnext!=null){ //将上一组反转完的最后一个节点指向 当前组反转完后的第一个节点
pnext.setNext(pre);
}
pnext=tmp; //迭代
i=0; //新的一组反转时 关键数据初始化
tmp=null;
pre=null;
}
}
return global_head;
}*/
//反转每组
public static void inreverse(Node left,Node right){
Node pre=null,cur=left,next=null;
while(pre!=right){
next = cur.getNext();
cur.setNext(pre);
pre=cur;
cur=next;
}
if(mtail!=null) mtail.setNext(right);
mhead=right;
mtail=left;
}
//每k个节点为一组反转
public static Node reverseLink3(Node head,int k){
Node cur=head,global_head=head;
int i=1;
Node left=null,right=null;
while(cur!=null){
if(i%k==1)
left=cur;
right=cur;
cur=cur.getNext();
if(i%k==0){
inreverse(left,right);
if(mtail!=null){
mtail.setNext(cur);
}
if(global_head==head){
global_head = mhead;
}
}
i++;
}
return global_head;
}
}
算法题:判断一个IP是否在国内
输入:
数据库中有几十万的国内 IP 段 (start_ip, end_ip)
一个待验证的 IP
输出:
YES or NO
首先,整理 IP 段配置。为了方便 IP 进行比较,这里将 IP 转换为 long 格式。
把数据load进来,取第一第二行,ip2long 处理
第一行保存在left,第二行保存在 right 中
然后根据left进行排序
得到类似如下的结果:
('16842752','16843007'),('16843264','16859135')
接下来使用二分法查找即可,较为简单。
手写代码:合并N个链表 -> 优化为 log(n) -> null 判断 -> 不允许修改数据结构怎么实现
出自LeetCode第二十三题-合并n个有序链表
最简单粗暴的方法是建立一个集合,遍历所有链表,将其元素添加到集合中,将集合通过数组的方式升序排序,将其添加到一个新的链表中并返回。
这种方法的时间复杂度:o(n2)外层遍历一遍数组内层遍历链表的元素,即双层遍历,还有一个单层遍历,所以结果近似于o(n2);空间复杂度:o(n)定义了数组长度多的变量listNode,定义了集合长度的链表长度即o(n)。
考虑优化如上的方法,用分治的方法进行合并。

public ListNode mergeKLists(List lists) {
// write your code here
if (lists == null || lists.size() == 0) {
return null;
}
ListNode dummy = new ListNode(0);
ListNode p = dummy;
Queue queue = new PriorityQueue(lists.size(), new Comparator()
{
@Override
public int compare(ListNode o1, ListNode o2) {
return o1.val - o2.val;
}
});
for (ListNode node : lists) {
if (node != null) {
queue.offer(node);
}
}
while (!queue.isEmpty()) {
ListNode node = queue.poll();
p.next = node;
if (node.next != null) {
queue.offer(node.next);
}
p = p.next;
}
return dummy.next;
}
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
ListNode dummy = new ListNode(-1);
ListNode p = dummy;
ListNode p1 = l1;
ListNode p2 = l2;
while (p1 != null && p2 != null) {
if (p1.val < p2.val) {
p.next = p1;
p1 = p1.next;
} else {
p.next = p2;
p2 = p2.next;
}
p = p.next;
}
if (p1 != null) {
p.next = p1;
}
if (p2 != null) {
p.next = p2;
}
return dummy.next;
}
开放题和项目经历
开放题和项目经历,需要根据自己的实际经验进行事先整理。
如果一个服务版本升级了 其他服务没升级怎么办
兼容处理,在接口层级进行兼容,加一层适配器。这个需要谨慎处理,如果项目规模大,维护特别麻烦。
Spring cloud/jdk设计模式 项目中的设计模式
这个要看平时的习惯,要有刨根问底的探索精神。多看些优秀的源码。
observer,发布和订阅模式,用了java里面的一个类,java.util.observable作为发布者,java.util.observer为订阅者。
Adapter:把一个接口或是类变成另外一种。如 java.util.Arrays#asList()
Decorator: 为一个对象动态的加上一系列的动作,而不需要因为这些动作的不同而产生大量的继承类。这个模式在JDK中几乎无处不在,所以,下面的列表只是一些典型的。如 java.io.BufferedInputStream(InputStream)
常用的语言?python 和 java 比较
Java和Python两门语言都是目前非常热门的语言,主要有如下的区别:
难易度而言。python远远简单于java。
开发速度。Python远优于java
运行速度。java远优于标准python,pypy和cython可以追赶java,但是两者都没有成熟到可以做项目的程度。
可用资源。java一抓一大把,python很少很少,尤其是中文资源。
稳定程度。python3和2不兼容,造成了一定程度上的混乱以及大批类库失效。java由于有企业在背后支持所以稳定的多。
是否开源。python从开始就是完全开源的。Java由sun开发,但现在有GUN的Openjdk可用,所以不用担心。
编译还是解释,两者都是解释型。
看了看我大三的面试记录?问了一下当时面试挂掉的原因?我说算法当时不行,顺便问了下我今年的笔试情况
总结之间失败的经验。
未来职业规划?
紧扣工作和学习两个维度回答:
第一点:介绍自己认真思考过这个问题,自己的规划是基于目前的实际情况来设计的,不是凭空想的。
第二点:工作方面,突出自己打算通过积极完成工作任务,积累各方面的经验,让自己成为这个领域的专业人士,也希望有机会能够带领团队,成为优秀的管理者,为单位做出更大贡献,获得双赢。
第三点:在学习方面,打算在专业领域做进一步学习和研究,将实践经验与专业知识相结合,为自己的职业成长做好铺垫,打好基础。
这不仅是应付面试官,更是对自己人生的思考,很重要。
有没有博客?开源项目?
博客和开源项目都是加分项,有最好了,平时注意积累。
实习的工作?有什么感觉有难度的地方?和团队其他人怎么协调的?
考察团队协作和问题解决的能力。
实习之后有哪些成长?业务可以改进的点?
同上,注意总结之前的经验。
项目:介绍 难点 实现细节 和二面差不多
挑熟悉且大型的项目说,比较容易应对。
最近在看什么书?平时怎么学习
HR是想通过这个问题来考察你获取知识和经验的路径与方法。通过平时的阅读习惯来了解求职者的知识结构和求知习惯。
学习的方法可以根据自己的实际进行解答,比如说重复练习,强化记忆,科学的方法应用等等。学习的能力很重要,自己需要凸显这一点。
面试的锦囊
上述所列出的面试题只能是帮助各位同学理解大部分的问题,并不会面面俱到,这里推荐一些师弟的面试复习资料,仅供参考。
师弟拿下阿里、抖音、腾讯、美团的offer,目前入职阿里。首先给大家提供他自己准备的一份复习资料。
私家珍藏
福利,后台回复“面试”,即可获取 PDF 文件。下面是参考的一些复习资料,内容质量很高,面试头条这样的一线大厂,算法也是必不可少,所以也给大家提供了经典算法的链接。
计算机基础和 Java 基础
https://cyc2018.github.io/CS-Notes/#/README
https://github.com/AobingJava/JavaFamily
https://github.com/Snailclimb/JavaGuide
算法
Longest Increasing Subsequence variants:
https://leetcode.com/problems/longest-increasing-subsequence/
https://leetcode.com/problems/largest-divisible-subset/ https://leetcode.com/problems/russian-doll-envelopes/ https://leetcode.com/problems/maximum-length-of-pair-chain/ https://leetcode.com/problems/number-of-longest-increasing-subsequence/ https://leetcode.com/problems/delete-and-earn/ https://leetcode.com/problems/longest-string-chain/Partition Subset:
https://leetcode.com/problems/partition-equal-subset-sum/BitMasking:
https://leetcode.com/problems/partition-to-k-equal-sum-subsets/Longest Common Subsequence Variant:
https://leetcode.com/problems/longest-common-subsequence/ https://leetcode.com/problems/edit-distance/ https://leetcode.com/problems/distinct-subsequences/ https://leetcode.com/problems/minimum-ascii-delete-sum-for-two-strings/Palindrome:
https://leetcode.com/problems/palindrome-partitioning-ii/ https://leetcode.com/problems/palindromic-substrings/Coin Change variant:
https://leetcode.com/problems/coin-change/ https://leetcode.com/problems/coin-change-2/ https://leetcode.com/problems/combination-sum-iv/ https://leetcode.com/problems/perfect-squares/ https://leetcode.com/problems/minimum-cost-for-tickets/ https://leetcode.com/problems/last-stone-weight-ii/Matrix multiplication variant:
https://leetcode.com/problems/minimum-score-triangulation-of-polygon/ https://leetcode.com/problems/minimum-cost-tree-from-leaf-values/ https://leetcode.com/problems/burst-balloons/Matrix/2D Array:
https://leetcode.com/problems/matrix-block-sum/ https://leetcode.com/problems/range-sum-query-2d-immutable/ https://leetcode.com/problems/dungeon-game/ https://leetcode.com/problems/triangle/ https://leetcode.com/problems/maximal-square/ https://leetcode.com/problems/minimum-falling-path-sum/Hash + DP:
https://leetcode.com/problems/target-sum/ https://leetcode.com/problems/longest-arithmetic-sequence/ https://leetcode.com/problems/longest-arithmetic-subsequence-of-given-difference/ https://leetcode.com/problems/maximum-product-of-splitted-binary-tree/State machine:
https://leetcode.com/problems/best-time-to-buy-and-sell-stock/ https://leetcode.com/problems/best-time-to-buy-and-sell-stock-ii/ https://leetcode.com/problems/best-time-to-buy-and-sell-stock-iii/ https://leetcode.com/problems/best-time-to-buy-and-sell-stock-iv/ https://leetcode.com/problems/best-time-to-buy-and-sell-stock-with-cooldown/ https://leetcode.com/problems/best-time-to-buy-and-sell-stock-with-transaction-fee/Depth First Search + DP:
https://leetcode.com/problems/out-of-boundary-paths/ https://leetcode.com/problems/knight-probability-in-chessboard/Minimax DP:
https://leetcode.com/problems/predict-the-winner/ https://leetcode.com/problems/stone-game/Misc:
https://leetcode.com/problems/greatest-sum-divisible-by-three/ https://leetcode.com/problems/decode-ways/ https://leetcode.com/problems/perfect-squares/ https://leetcode.com/problems/count-numbers-with-unique-digits/ https://leetcode.com/problems/longest-turbulent-subarray/ https://leetcode.com/problems/number-of-dice-rolls-with-target-sum/
面经
关于面经,大家多看看牛客网,里面很全面。
福利,整理的一份
写在最后
基础知识的掌握是一个积累过程,面试虽然有很多的技巧,可以去恶补。但是如果我们在平时就能够保持良好的学习习惯,以及最重要的求知欲,会使得我们准备面试时能够事半功倍。
最后给大家留一道思考题,检验下自己学习之后的效果?,欢迎在留言区写出你的想法,或者私信我交流。如有实在做不出来,笔者最后会提供思路和答案。
算法题:用户在线波峰计算
输入:用户日志(time, user_id, login | logout)
输出:同时在线人数的峰值, 峰段(峰值的90%) (如 19:50到22:10, 峰值3亿,最低2.7亿)
-关注我
推荐阅读
AbstractQueuedSynchronizer超详细原理解析