
网易云课堂 VS 慕课网 哪家网课评分高?
共 4110字,需浏览 9分钟
·
2021-01-09 17:00
作者 | 丁毅
来源 | 简说Python
「本文目录」
1 数据抓取
2 数据清洗
2.1 数据格式统一
2.2 空值处理
2.3 数据去重
2.4 评论清洗
3 数据分析及可视化
3.1 课程评分分析
3.2 用户昵称格式
3.3 各平台评论的平均长度
3.4 各平台评论高频词
3.5 评论数与课程评分之间的关系
参考资料
本文通过爬取的数据,对中国大学MOOC(icourse)、慕课网(imooc)、腾讯课堂(keqq)、网易云课堂(study163)四大网课平台的课程信息及评论进行简要分析(包含5k+课程数据和34w+课程评论信息)。同时,对数据分析的整体流程做一个总结。内容如有纰漏,敬请指出。
本文相关源码和部分数据可以在文末获取。
1 数据抓取
数据的获取是我们进行数据分析的第一步。现在获取数据的主要途径一般为:现成数据;自己写爬虫去爬取数据;使用现有的爬虫工具爬取所需内容,保存到数据库,或以文件的形式保存到本地。
如果是想通过自己写爬虫来爬取数据,那么整体思路大致分为:
确定爬取的内容 对主页面解析 子页面的获取 子页面的解析 数据的保存
现在的网站或多或少都有一些基本的反爬措施,那么,我们在写爬虫时就应针对该网站制定相应的反反爬策略,如请求头、IP代理、cookie限制、验证码限制等,这些常见的反爬机制要能够应用在你写的爬虫当中。
如果爬虫大致能够爬取我们所需的内容,下一步,我认为就是提高爬取速度,增加稳定性了。
我们知道当requests模块对页面发起请求时,整个程序是处于阻塞状态,在请求的这段时间,后面的代码是无法运行的,所以说当我们需要对很多个页面发起请求时,我们可以通过使用异步协程的方式,使我们能够利用阻塞的这段时间去执行其他任务。由于requests模块是不支持异步协程的,我们需要使用aiohttp模块来对页面发起请求,再搭配asyncio来实现异步爬虫。
提高稳定性,就需要一些稳定的ip代理,防止爬虫运行期间ip被封,推荐自己爬取一些免费的ip代理的网站,通过代码测试一下,将能用的保存到数据库中,使用时直接通过类来使用即可。如果你对爬虫中的ip代理的使用还是很了解,不妨看下这篇文章(异步爬虫)requests和aiohttp中代理IP的使用。
因为我没用过爬虫工具,所以就不介绍了。
2 数据清洗
数据得到手,我们就需要对我们爬取的数据进行清洗工作,为之后的数据分析做铺垫,如果清洗的不到位势必会对之后的数据分析造成影响。
下文将从数据格式统一、空值处理、数据去重、评论清洗等方面来介绍。
2.1 数据格式统一
对于四个平台的数据,由于各个平台爬取的内容有所不同,数据类型也有差别,我们根据后期分析的需要,提取我们需要的内容,数据类型与格式统一后再将课程及评论信息合并。
如课程评分中,imooc的评分格式为‘9分’,而数据分析时,只需要9来作为分数即可。各个平台的评分要求不同,这里统一5分制。
# 正则提取数字
df['评论分数'] = df['评论分数'].str.extract(r'(\d+)', expand=True)
# 类型转换,并改为五分制
df['评论分数'] = df['评论分数'].values.astype(float)/2
重新对列名进行命名
df.rename(columns=({'课程名':'course_name', '学习人数':'total_stu'}), inplace=True)
2.2 空值处理
对于数据中的空值(Nan),如果该行中的数据对后面数据分析影响不大。那么,直接删除改行即可。
# 直接删除course_id列中值为空的行(不包含空字符串)
df = df.dropna(subset=['comment'])
如果要对空字符串进行删除,直接使用上述方法并不能实现。可以先将字符串转为np.nan类型,再使用dropna来删除。
# 将空字符串转为'np.nan',用于下一步删除
df['course_id'].replace(to_replace=r'^\s*$', value=np.nan, regex=True, inplace=True)
# 删除course_id中的空值,并重置索引
df = df.dropna(subset=['course_id'])
df.reset_index(drop=True, inplace=True)
2.3 数据去重
用于爬取时的误差,部分数据有部分重复,这时就需要删除这些重复的数据,只保留一条即可。
# 根据course_id列的唯一性,可以把它作为作为参照,如存在多行course_id相同,那么只保留最开始出现的。
df.drop_duplicates(subset=['course_id'], keep='first', inplace=True)
# 重置索引
df.reset_index(drop=True, inplace=True)
2.4 评论清洗
对单一用户的重复评论去重。对于同一用户在不同时间对同一课程进行的评论如果内容相同,可以认为该用户在评论时并未认真思考,因此应只保留第一次,以保证后期分析数据的有效性。
df.drop_duplicates(subset=['user_id', 'comment'], keep='first', inplace=True)
df.reset_index(drop=True, inplace=True)
去除评论中的换行符(\n)和回车(\r)。
df['comment'] = df['comment'].str.replace('\r|\n', '')
去除评论开头和结尾的空格。
df['comment'] = df['comment'].str.strip()
对于纯数字评论(如‘111’,‘123456’,‘666’),无实际意义,并不能说明对某一事物的评价,应删除。先通过正则将其替换成空字符串,后面统一删除。
df['comment'] = df['comment'].str.replace('^[0-9]*$', '')
对于单一重复字符评论(如‘aaaa’,‘!!!’),无实际意义。
df['comment'] = df['comment'].str.replace(r'^(.)\1*$', '')
部分评论包含时间(如‘2020/11/20 20:00:00打卡’),通过正则匹配将时间日期转为空字符串,防止影响之后对评论的分词。
df['comment'] = df['comment'].str.replace(r'\d+/\d+/\d+ \d+:\d+:\d+', '')
「机械压缩去词」
(1)机械压缩去词思想由于评论信息中评论质量参差不齐,没有实际意义的评论有很多,只通过简单的文本去重,很难将那些没有意义的评论大量删除,因此经过简单的文本去重后,还要使用机械压缩进行再次去重。如‘非常好非常好’,‘好呀好呀’等。
这类连续重复的评论,在之前的清洗中很难删除,但放任不管,当之后情感分析时,经过分词,积极词汇量与实际词汇量相差较多,对后期统计会产生较大影响。
(2)机械压缩去词的结构从一般的评论来讲,人们一般只会在开头和结尾添加无意义的重复语料,如‘为什么为什么课程这么贵’,‘真的非常好好好’。而中间出现连续词时,大多是成语及名词修饰等,如‘老师讲课真的滔滔不绝,如同江河!’等。如果对这样的词进行压缩,可能会改变语句原意。因此,只对开头和结尾出现重复词时进行压缩去词。
(3)机械压缩处理过程及规则制定连续累赘重复的判断可以通过建立两个存放字符的列表来完成,一个一个的读取字符,并按照不同的情况,将字符放入第一个或第二个列表或触发压缩判断,若触发判断得出的结果是重复(即列表1和列表2有意义的字符部分完全相同)则进行去除,这里根据python数据分析与挖掘实战书中的规则参考,指定七条规则。
「规则1」:如果读入的字符与列表1的第一个字符相同,而列表2中没有放入任何字符,则将这个字符放入列表2中。
「规则2」:如果读入的字符与列表1中的第一个字符相同时,而列表2也有字符,那么触发压缩判断,若结果是重复,则进行去除,并清空列表2。
「规则3」:如果读入的字符与列表1的第一个字符相同,而列表2也有字符,触发压缩判断,若不重复,则清空两个列表,并把读入的这个字符放入列表1的第一个位置。
「规则4」:如果读入的字符与列表1的第一个字符不相同,触发压缩判断,若重复,且两个列表中字符数目大于2,则去除,并清空两个列表,将该字符存入列表1。
「规则5」:如果读入的字符与列表1的第一个字符不相同,触发压缩判断,若不重复,且列表2中没有字符,则继续在列表1中放入字符。
「规则6」:如果读入的字符与列表1的第一个字符不相同,触发压缩判断,若不重复,且列表2中有字符,则继续在列表2中放入字符。
「规则7」:读完所有字符后,触发压缩判断,对列表1与列表2进行比较,若重复则删除。
(4)机械压缩效果展示
3 数据分析及可视化
3.1 课程评分分析
首先对各个平台课程的评分进行分析,并可视化。
由于平台数据中只有两个平台包含课程评分,所以只对这两个平台的课程评分进行分析。
从合并好的课程信息csv中选择两平台的500门课程评分进行分析,统计各个评分区间的课程数量。
df = pd.read_csv(r'merge_course.csv', usecols=['platform', 'rating'])
df = df.loc[df['platform'] == 'imooc'].head(500)
print(len(df[df['rating'] >= 4.75]))
print(len(df[(df['rating'] < 4.75) & (df['rating'] >=4.5)]))
print(len(df[(df['rating'] < 4.5)]))
再数据通过matplotlib库进行可视化。得到下图。
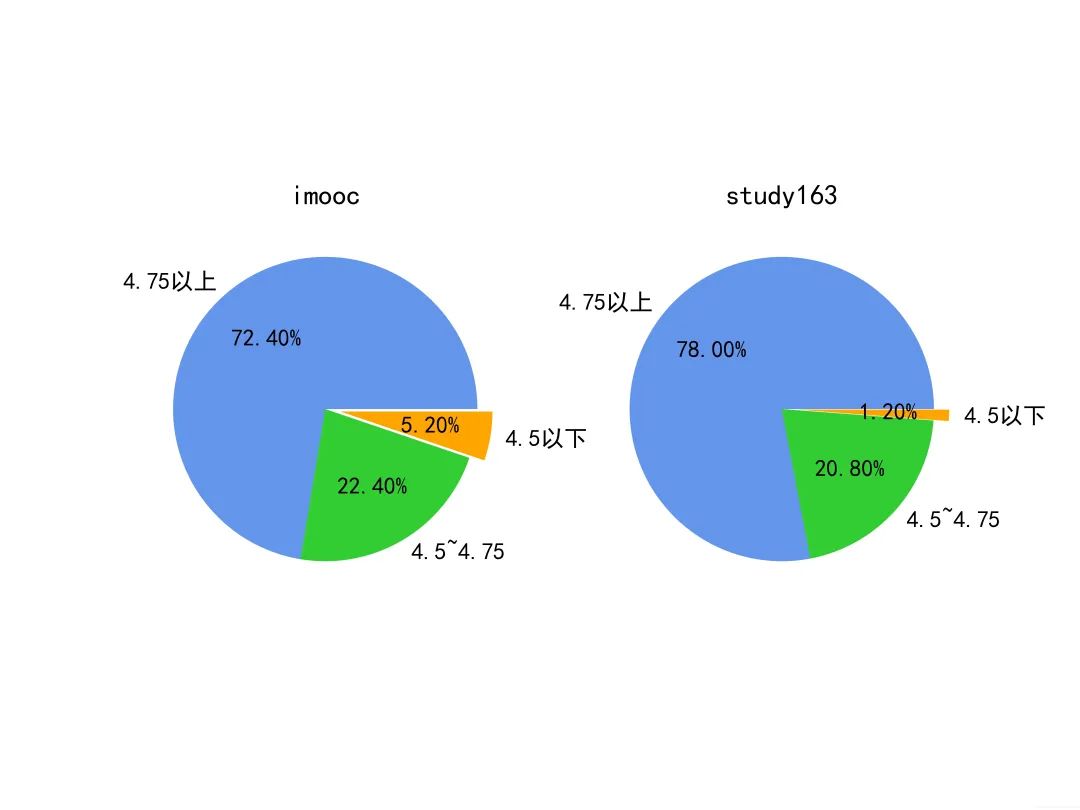
❝通过图可以很清晰的看出,两个平台的评分区间分布,总的来说study163平台的课程整体评分要比imooc平台高一些,4.5分以下的课程只占1.2%。imooc中网课的评分4.5分以上的占94.8%,study163中网课的评分4.5分以上的占98.8%,都超过了90%+,从整体来看学习者对网课的内容和质量还是很认可的,但少部分低于4.5分的用户评分来看,说明网课可以改进的地方还是有的。
❞
3.2 用户昵称格式
用户名从评论信息中获取,通过去重,来保证用户名的唯一性,由于keqq平台用户名是隐藏的,所以不进行统计。
df = pd.read_csv(r'/new_merge_comment.csv',
low_memory=False, usecols=['platform', 'user_name'])
df = df.loc[df['platform']=='mooc163', :]
df.dropna(inplace=True)
df.drop_duplicates(keep='first', inplace=True)
df.reset_index(drop=True, inplace=True)
df = df.head(30000)
chinese_name = []
for name in df['user_name'].values:
if re.findall(r'[\u4e00-\u9fff]', name):
chinese_name.append(name)
pure_chinese_name = []
for name in chinese_name:
if name == ''.join(re.findall(r'[\u4e00-\u9fff]', name)):
pure_chinese_name.append(name)
print(30000-len(chinese_name)) # 字符
print(len(pure_chinese_name)) # 中文
得到各个平台的用户名格式,就可以进行可视化了。结果如下图。
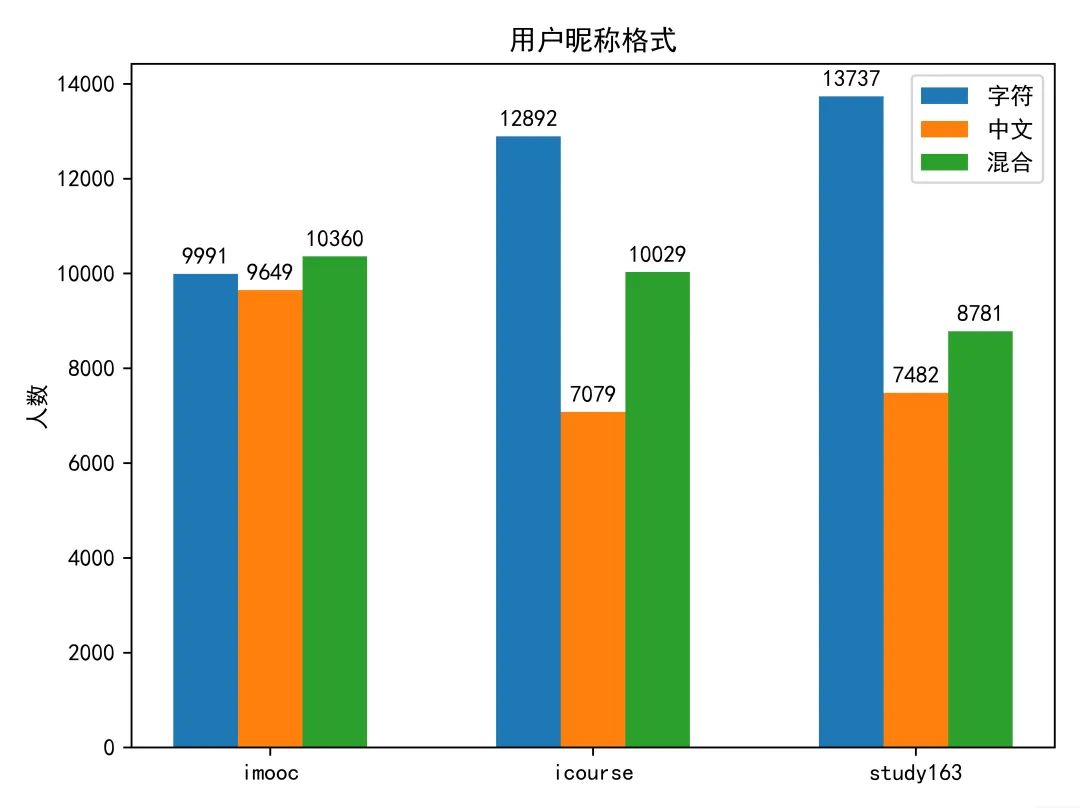
❝根据图中信息可知,在imooc平台,三种格式的用户名使用人数大致持平,而在icourse和study163平台上使用纯字符来做为昵称的人数要明显多于纯中文的昵称,数字和英文昵称一定程度上更加洁简,同时也可以避免被熟人认出,其中应该个体学习者居多,而学校安排的网课,更多要求考核学生,一般会要求学生使用真实姓名作为昵称,从昵称角度分析用户可以参考这篇文章xxx。
❞
3.3 各平台评论的平均长度
之前已经统计了各个平台课程评论的平均长度,现在只需要取它们的平均值即可。
df = pd.read_csv(r'Chinese_comment.csv', low_memory=False,
usecols=['platform', 'average_length'])
print(df.groupby('platform').describe().reset_index(drop=None))

可视化结果如下。
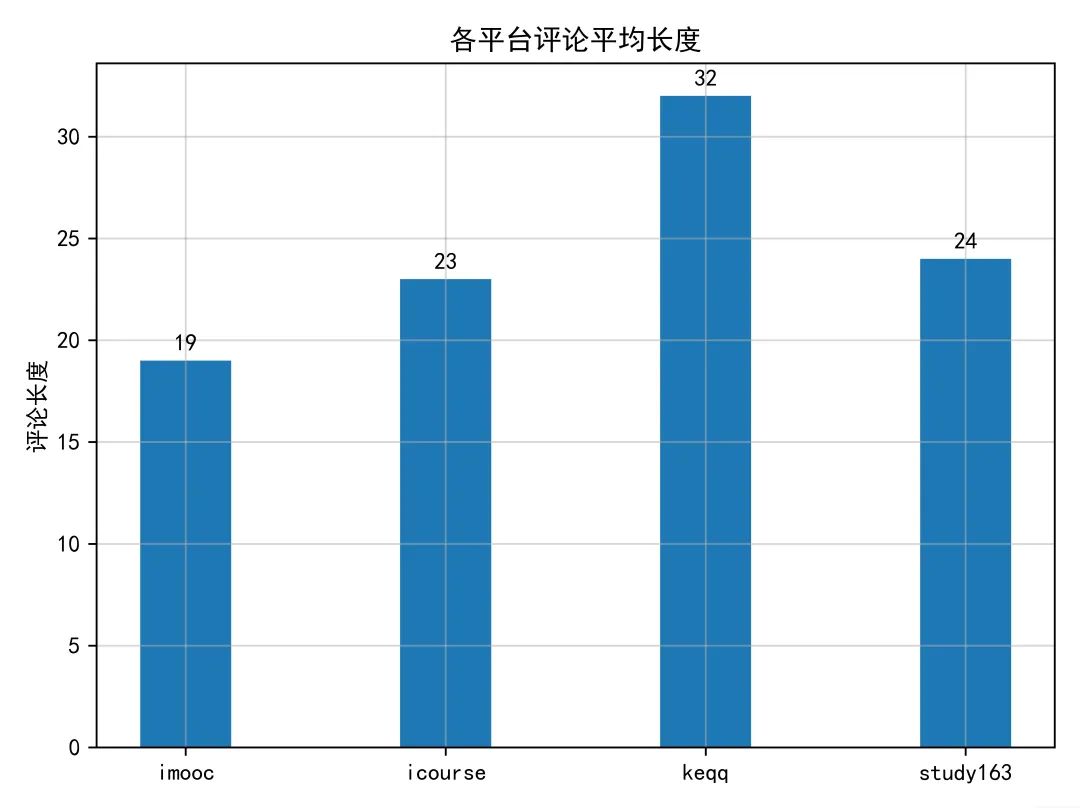
❝四个平台的评论平均长度以腾讯课堂(keqq)最高,中国大学MOOC(icourse)与网易云课堂(study163)相近,慕课网(imooc)最低。用户评论从两个方面考虑,正向(好评)和反向(差评),但不论哪个方面,用户评论越长,一定程度说明用户更加喜欢这平台,对这个平台有更多的期待。
❞
3.4 各平台评论高频词
提取各个平台的积极消极高频词。
使用dataframe保存读取csv文件中的内容,再从dataframe中读取每一条评论,使用groupby()函数按课程名进行分组,同时将该课程评论合并到同一列。
course_comment = df.groupby(['course_id'])['comment'].apply(sum)
将dataframe中的数据保存到字典中,创建一个新的dataframe对象new_df来保存课程名和提取的正面/负面高频词,循环字典中的键‘comemnt’的每一个评论,使用jieba分词精准模式对其进行分词,对比导入的中文停用词表将词汇列表中无用的字符汉字进行剔除。之后导入positive.txt,negative.txt分别作为正面情感词典,负面情感词典。循环每个分词后得到的课程正面/负面词汇列表,使用Courter函数获取正面/负面词汇列表出现次数最多的五组词。
up_list = Counter(positive_list).most_common(5)
down_list = Counter(negative_list).most_common(5)
之后将得到的高频词和课程名保存到new_df中,循环直至所有的课程评论都已保存。 到这里已经获取了各平台每一课程中所有评论的高频词。接下来只需要整合每个平台课程的高频词,将其以词汇图的形式来展现即可。这里以慕课网(imooc)平台的积极消极高频词作为展示。可视化结果如下图
到这里已经获取了各平台每一课程中所有评论的高频词。接下来只需要整合每个平台课程的高频词,将其以词汇图的形式来展现即可。这里以慕课网(imooc)平台的积极消极高频词作为展示。可视化结果如下图
课程评论积极高频词

课程评论消极高频词

❝从这两个词云图中的高频词,不难看出,用户对课程的难易度、教师的讲课水平、课程的整体结构、课后习题的安排有较高的要求,如积极词汇中出现较多的“易懂”、“详细”、“基础”、“清晰”等,消极词汇中出现较多的“复杂”、“辛苦”、“废话”等。
❞
3.5 评论数与课程评分之间的关系
这里我们随机选取慕课网(imooc)和网易云课堂(study163)200门课程,分别统计它们的课程评分和评论数。
df = pd.read_csv('merge_course.csv', low_memory=False,
usecols=['platform', 'course_name', 'course_id', 'rating'])
df = df.loc[df['platform'] == 'imooc'].reset_index(drop=None).head(200)
df_comment = pd.read_csv('merge_comment.csv', low_memory=False,
usecols=['platform', 'course_id', 'comment'])
df_comment = df_comment.loc[df_comment['platform'] == 'mooc163']
series = df_comment.groupby('course_id')['comment'].count()
df_comment = pd.DataFrame()
df_comment['course_id'] = series.index
df_comment['count'] = series.values
df_comment['course_id'] = df_comment['course_id'].str.extract('^(\d+)', expand=True)
new_df = pd.merge(df, df_comment, on='course_id')
rating_list = new_df['rating'].values.tolist() # 课程评分
count_list = new_df['count'].values.tolist() # 课程评论
得到rating_list、count_list后通过散点图可视化。结果如下图。
慕课网(imooc)
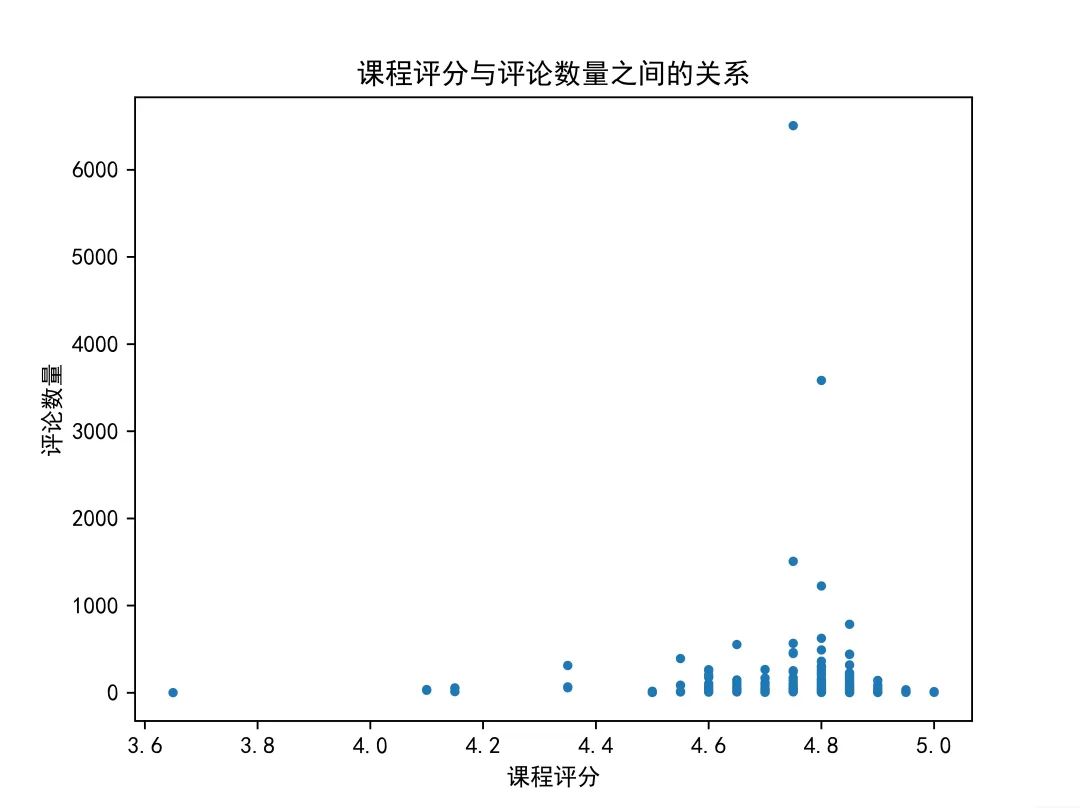
网易云课堂(study163)
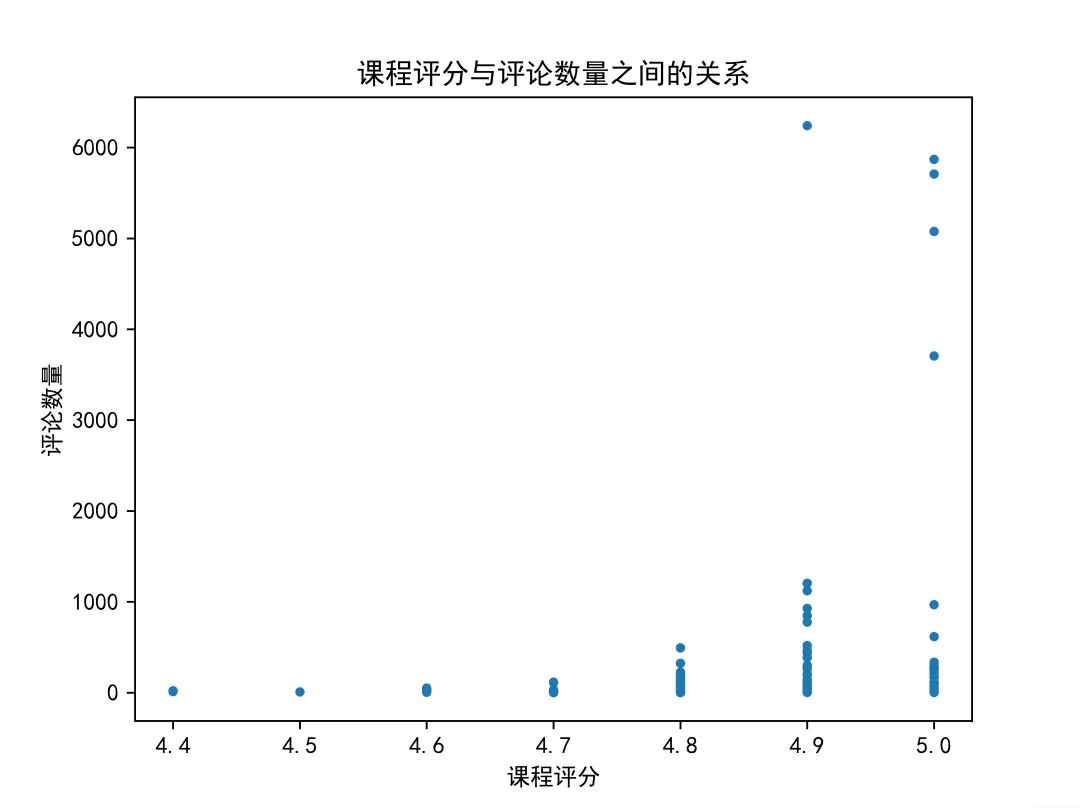
❝通过两个平台的对比不难看出,当评论数量较多时,慕课网的课程评分基本稳定在4.8--5.0之间,网易云课堂课程评分基本稳定在4.9--5.0之间。两平台评论数量最多的课程评分分别为4.8,4.9分。可见评论人数越多,越不容易达到满分。同时两个平台中评分较低的课程普遍评论量不高,可见当评论人数较少时,个别用户的低分就会对课程评分产生较大影响;说明评论人数作为课程火热度的一个指标对课程评分是有直接影响的。
❞
以上便是本文全部内容,部分代码并不完整,只提供思 路,matplotlib可视化可以参考官方文档,所以在文中就没放可视化相关代码。
数据和完整源码链接:https://pan.baidu.com/s/16Xyv0Ln2oVbu3oyyQdwg5g 提取码:h9n8
你在哪些平台学习过呢?
参考资料
「python数据分析与挖掘实战」https://book.douban.com/subject/26677686/
「pandas官方文档」https://pandas.pydata.org/docs/user_guide/index.html
「matplotlib官方文档」https://matplotlib.org/