
异常检测算法应用与实践_CMU赵越

作者信息
知乎微调:https://www.zhihu.com/people/breaknever

内容概括
1.什么是异常检测?
2.异常检测有什么具体应用?
3.异常检测的工具概览?如何用10行Python代码进行异常检测?
4.异常检测算法概览与主流模型介绍
5.面对各种各样的模型,如何选择和调参?
6.未来的异常检测研究方向
7.异常检测相关的资源汇总(书籍、讲座、代码、数据等)
异常检测
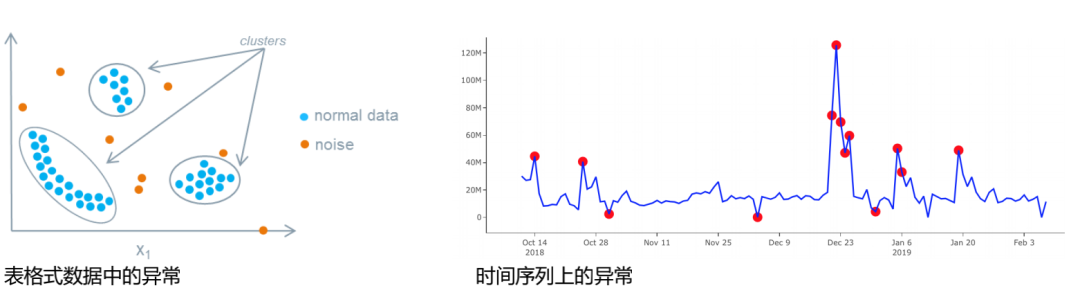
什么是异常值、离群点(anomaly)?
异常一般指的是与标准值(或期待值)有偏离的样本,也就是说跟绝大部分数据“长的不一样”。
异常检测的一些特点:
1.异常不一定代表是“坏”的事情,但往往是“有价值”的事情,我们对异常的成因感兴趣
2.异常检测往往是在无监督的模式下完成的—历史数据中没有标签,我们不知道哪些数据是异常。因此无法用监督学习去检测。
异常检测的应用:
1.金融行业的反欺诈、信用卡诈骗检测:把欺诈或者金融风险当做异常
2.罕见病检测:把罕见病当做异常,比如检测早发的阿兹海默症
3.入侵检测:把网络流量中的入侵当做异常
4.机器故障检测:实时监测发现或预测机械故障
5.图结构、群体检测:比如检测疫情的爆发点等
异常检测的应用
IntelControlFlag:
“基于10亿条包含各种错误的未标记生产质量代码的机器学习培训,ControlFlag得以通过“异常检测”技术,对传统编程模式展开筛查。无论使用的是哪种编程语言,它都能够有效地识别代码中可能导致任何错误的潜在异常。”
AmazonAWSCloudWatch:
“今天,我们将通过一项新功能增强CloudWatch,它将帮助您更有效地使用CloudWatch警报。…我们的用户可以构建自定义的控制面板,设置警报并依靠CloudWatch来提醒自己影响其应用程序性能或可靠性的问题。”
Google:
“GoogleAnalytics(分析)会选择一段时期的历史数据来训练其预测模型。要检测每天的异常情况,训练期为90天。要检测每周的异常情况,训练期为32周。”
异常检测的挑战
1.大部分情况下是无监督学习,没有标签信息可以使用
2.数据是极端不平衡的(异常点仅占总体数据的一小部分),建模难度大
3.检测方法往往涉及到密度估计,需要进行大量的距离/相似度计算,运算开销大
4.在实际场景中往往需要实时检测,这比离线检测的技术难度更高
5.在实际场景中,我们常常需要同时处理很多案例,运算开销大
6.解释性比较差,我们很难给出异常检测的原因,尤其是在高维数据上。但业务方需要了解异常成因
7.在实际场景中,我们往往有一些检测的历史规则,如何与学习模型进行整合
异常检测工具
Python:
1.PyOD:超过30种算法,从经典模型到深度学习模型一应俱全,和sklearn的用法一致
2.Scikit-Learn:包含了4种常见的算法,简单易用
3.TODS:与PyOD类似,包含多种时间序列上的异常检测算法
Java:
1.ELKI:EnvironmentforDevelopingKDD-ApplicationsSupportedbyIndex-Structures
2.RapidMiner异常检测扩展
R:
1.outlierspackage
2.AnomalyDetection
用10行Python代实行异常检测:

详细介绍:https://zhuanlan.zhihu.com/p/58313521
异常检测算法
异常检测算法可以大致被分为:
1.线性模型(LinearModel):PCA
2.基于相似度的度量的算法(Proximity-basedModel):kNN,LOF,HBOS
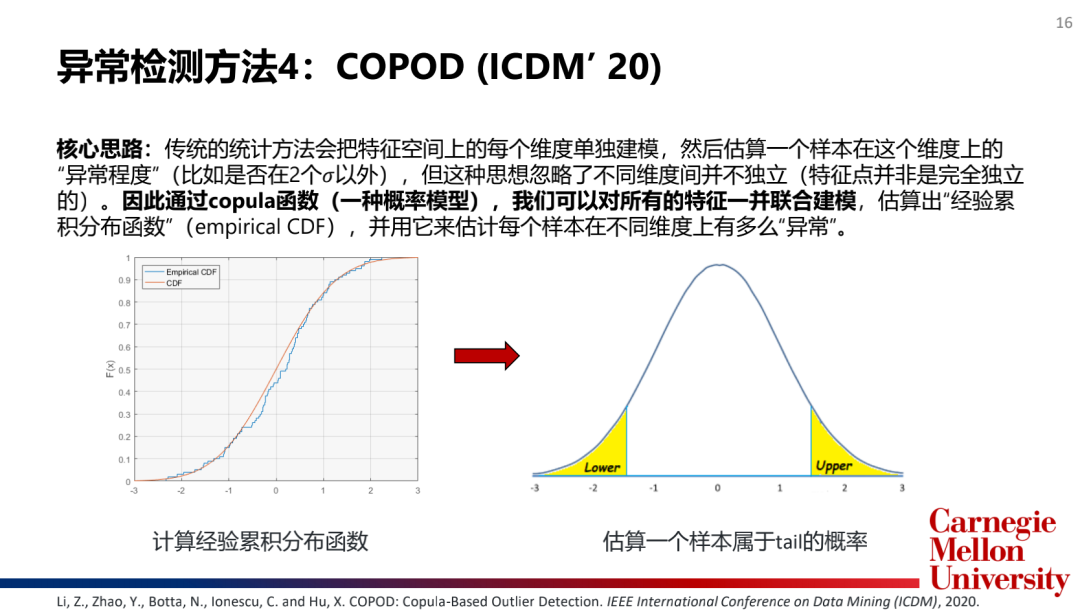
3.基于概率的算法(ProbabilisticModel):COPOD
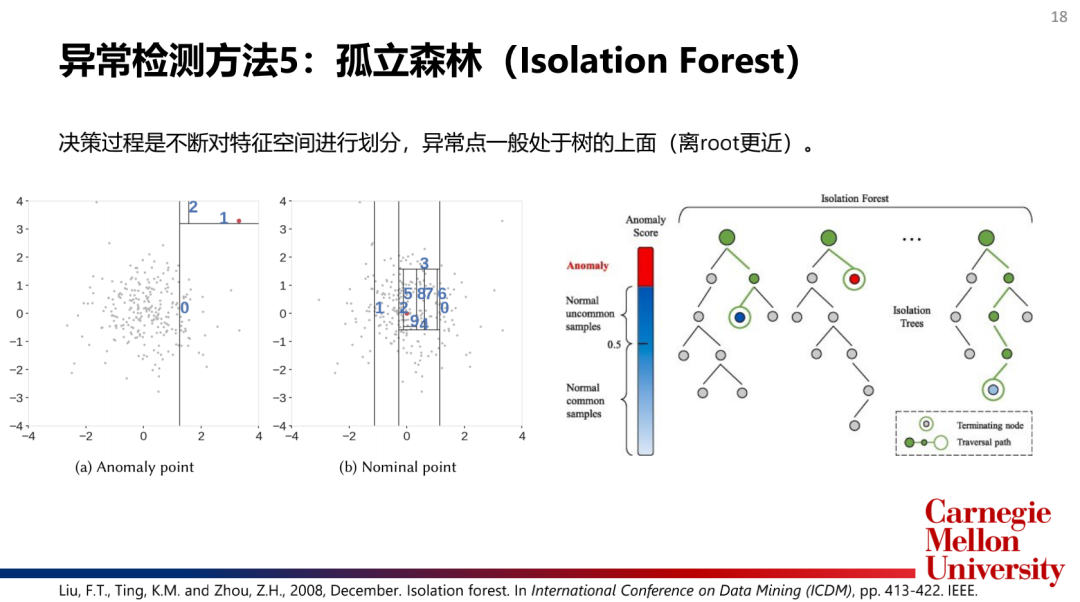
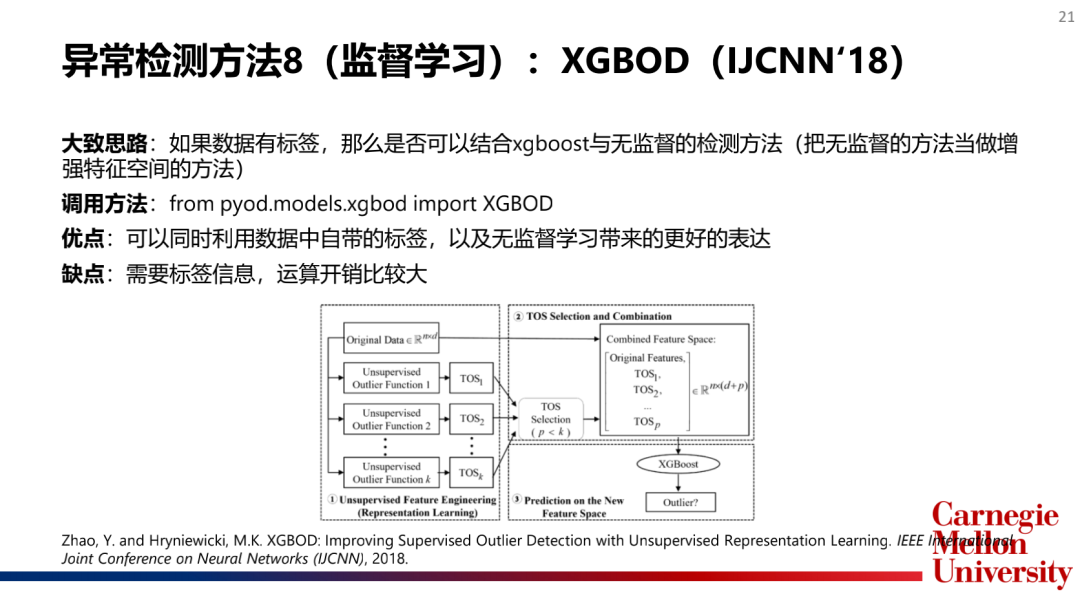
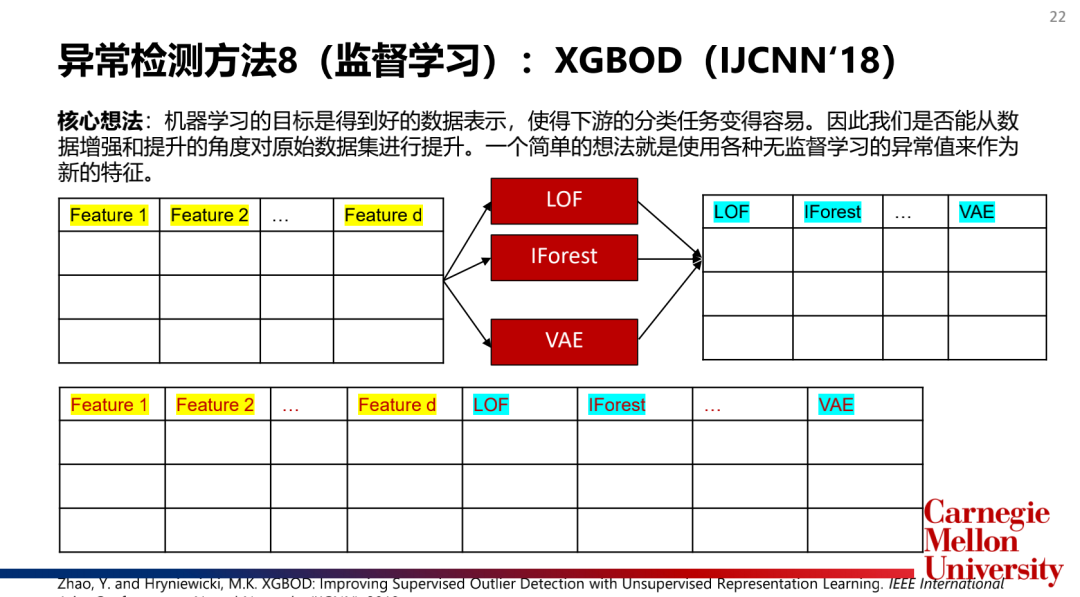
4.集成检测算法(EnsembleModel):孤立森林(IsolationForest),XGBOD
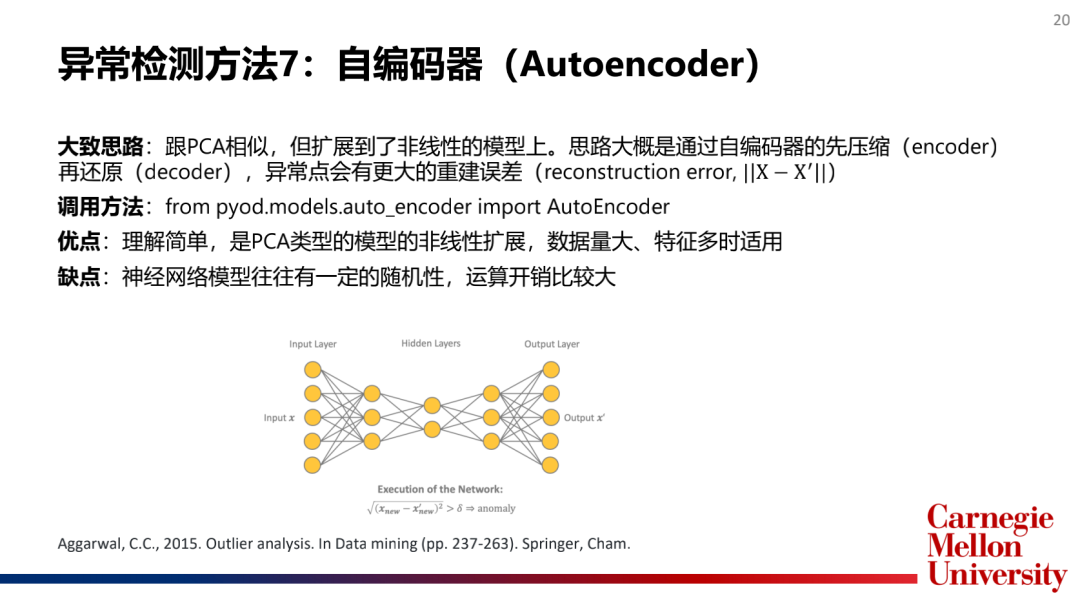
5.神经网络算法(NeuralNetworks):自编码器(AutoEncoder)
评估方法也不能简单用准确度(accuracy),因为数据的极端不平衡
1.ROC-AUC曲线
2.Precision@Rankk:topk的精准
3.AveragePrecision:平均精准度
主流模型介绍:

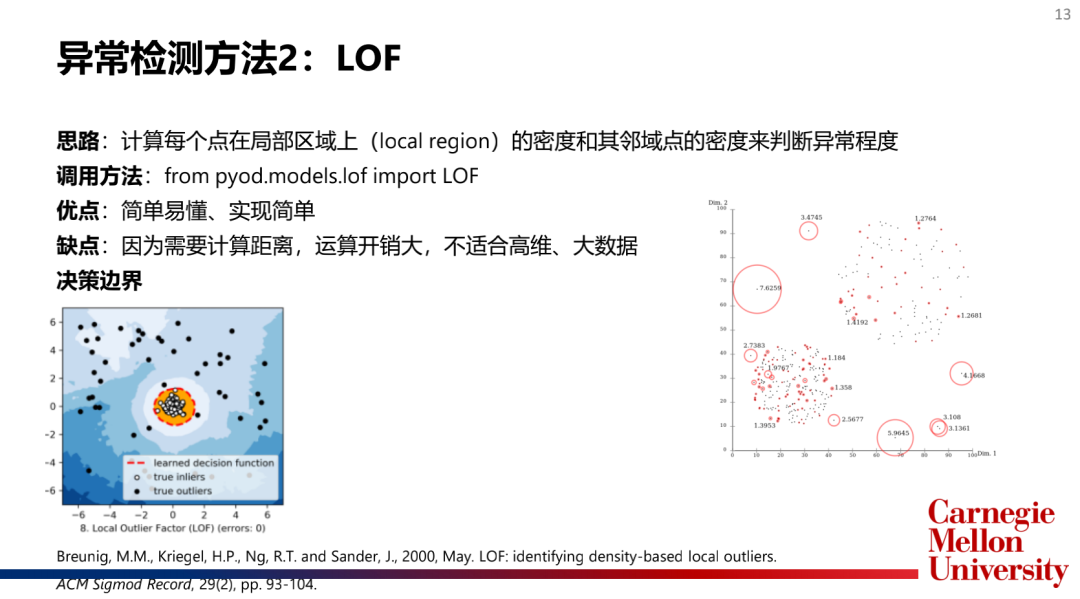
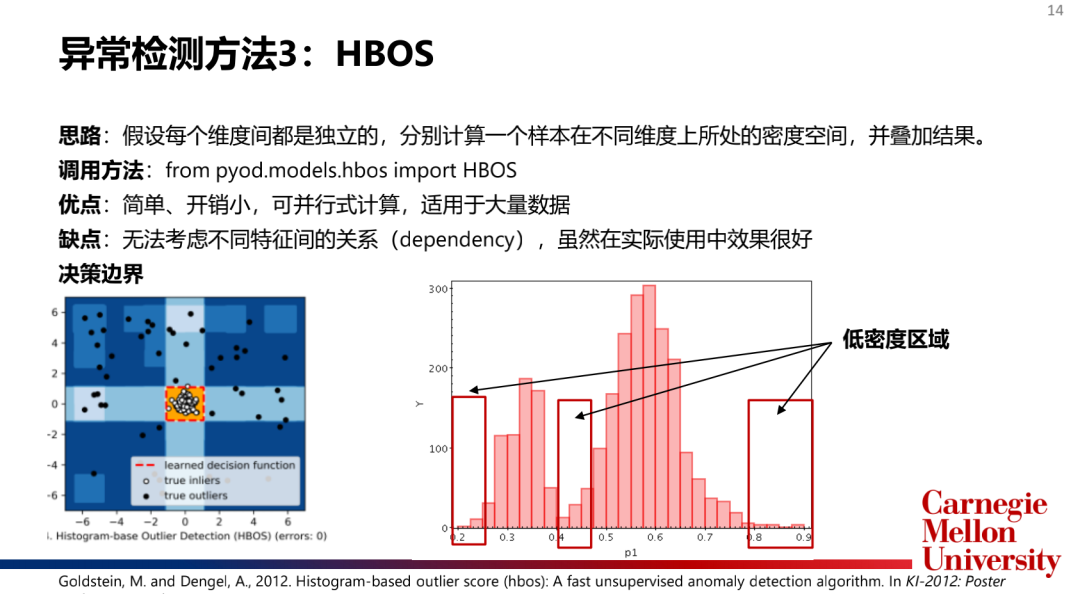
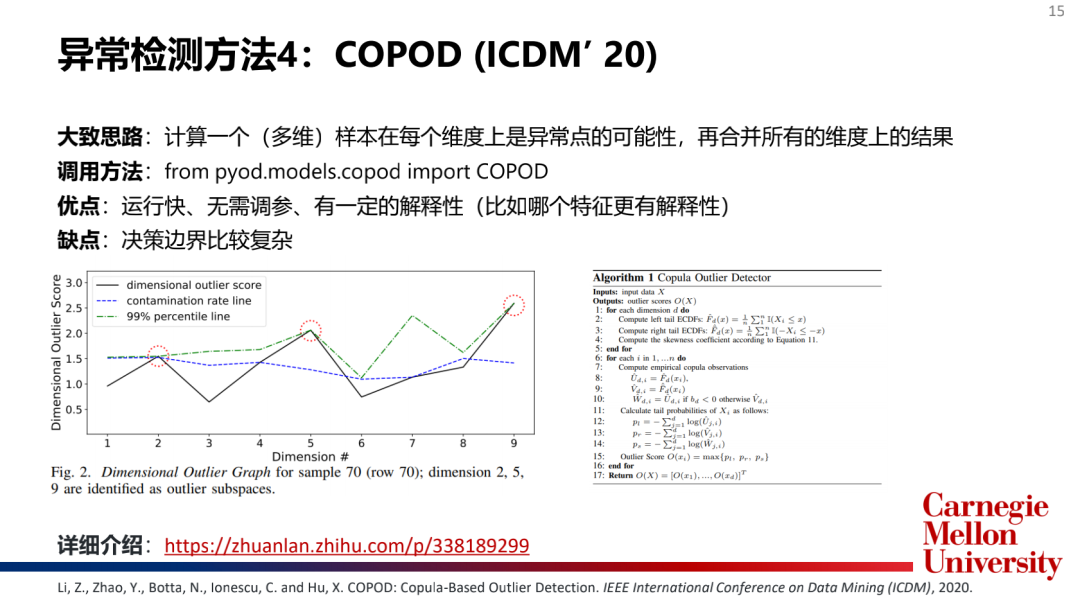


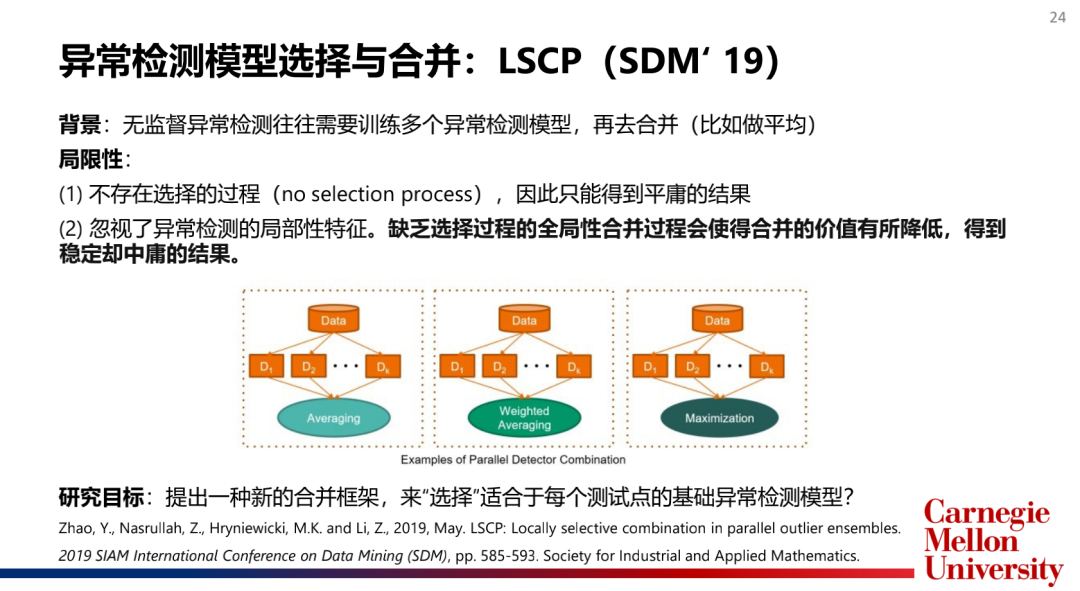
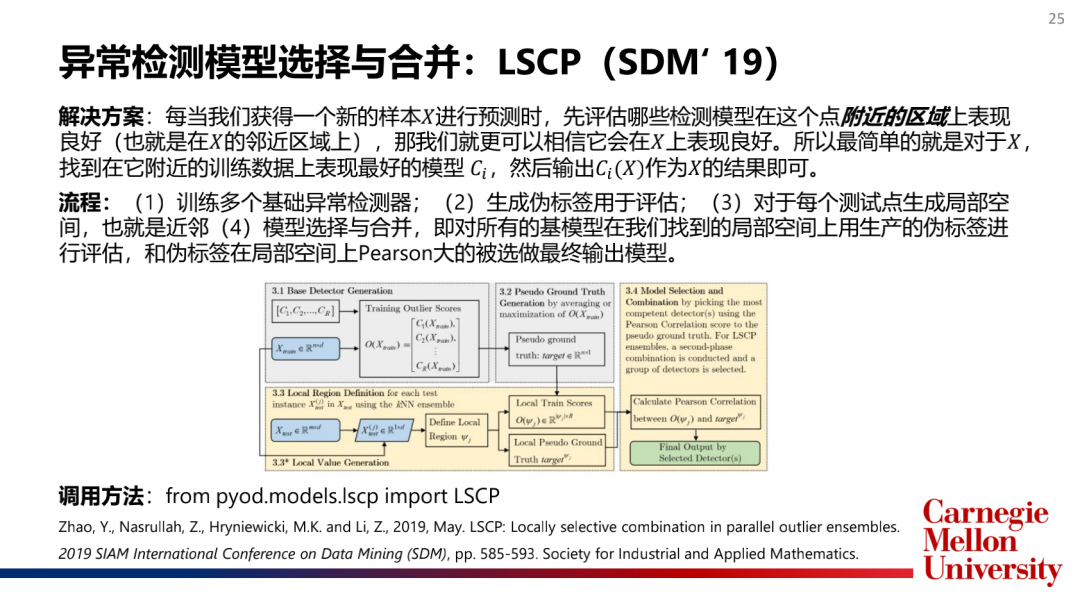
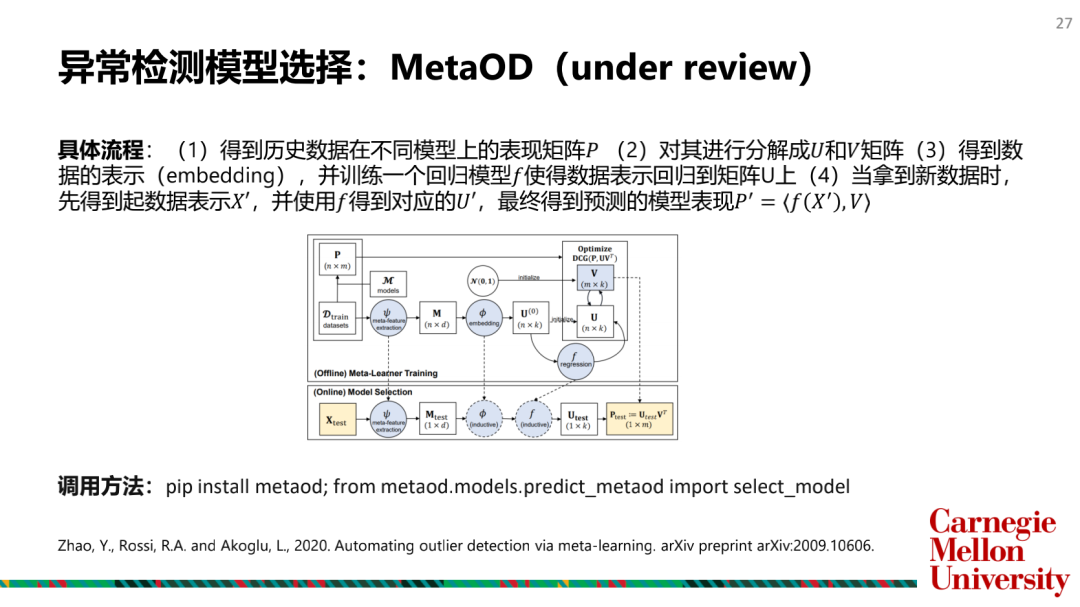
如何选择和合并模型


异常检测实践中的技巧

异常检测落地中的考量
1.不要尝试一步到位用机器学习模型来代替传统模型
2.在理想情况下,应该尝试合并机器学习模型和基于规则的模型
3.可以尝试用已有的规则模型去解释异常检测模型
异常检测研究方向
- 推荐阅读-
深度学习系列
后台回复【课程】,即可免费领取Python|机器学习|AI 精品课程大全
 机器学习算法交流群,邀您加入!!!
机器学习算法交流群,邀您加入!!!入群可以:提问求助、认识行业内同学、交流进步、共享资源...
扫描👇下方二维码,备注“加群”
