
使用 Go 每分钟处理百万请求
介绍
偶然间看到一篇写于15年的文章,说实话,标题确实吸引了我。
关于这篇文章,我就不直接翻译了,原文地址我放在文章最后了。
项目的需求就是很简单,客户端发送请求,服务端接收请求处理数据(原文是把资源上传至 Amazon S3 资源中)。本质上就是这样,
我稍微改动了原文的业务代码,但是并不影响核心模块。在第一版中,每收到一个 Request,开启一个 G 进行处理,很常规的操作。
初版
package mainimport ("fmt""log""net/http""time")type Payload struct {// 传啥不重要}func (p *Payload) UpdateToS3() error {//存储逻辑,模拟操作耗时time.Sleep(500 * time.Millisecond)fmt.Println("上传成功")return nil}func payloadHandler(w http.ResponseWriter, r *http.Request) {// 业务过滤// 请求body解析......var p Payloadgo p.UpdateToS3()w.Write([]byte("操作成功"))}func main() {http.HandleFunc("/payload", payloadHandler)log.Fatal(http.ListenAndServe(":8099", nil))}
这样操作存在什么问题呢?一般情况下,没什么问题。但是如果是高并发的场景下,不对 G 进行控制,你的 CPU 使用率暴涨,内存占用暴涨......,直至程序奔溃。
如果此操作落地至数据库,例如mysql。相应的,你数据库服务器的磁盘IO、网络带宽 、CPU负载、内存消耗都会达到非常高的情况,一并奔溃。所以,一旦程序中出现不可控的事物,往往是危险的信号。
中版
package mainimport ("fmt""log""net/http""time")const MaxQueue = 400var Queue chan Payloadfunc init() {Queue = make(chan Payload, MaxQueue)}type Payload struct {// 传啥不重要}func (p *Payload) UpdateToS3() error {//存储逻辑,模拟操作耗时time.Sleep(500 * time.Millisecond)fmt.Println("上传成功")return nil}func payloadHandler(w http.ResponseWriter, r *http.Request) {// 业务过滤// 请求body解析......var p Payload//go p.UpdateToS3()Queue <- pw.Write([]byte("操作成功"))}// 处理任务func StartProcessor() {for {select {case payload := <-Queue:payload.UpdateToS3()}}}func main() {http.HandleFunc("/payload", payloadHandler)//单独开一个g接收与处理任务go StartProcessor()log.Fatal(http.ListenAndServe(":8099", nil))}
这一版借助带 buffered 的 channel 来完成这个功能,这样控制住了无限制的G,但是依然没有解决问题。
原因是处理请求是一个同步的操作,每次只会处理一个任务,然而高并发下请求进来的速度会远远超过处理的速度。这种情况,一旦 channel 满了之后, 后续的请求将会被阻塞等待。然后你会发现,响应的时间会大幅度的开始增加, 甚至不再有任何的响应。
终版
package mainimport ("fmt""log""net/http""time")const (MaxWorker = 100 //随便设置值MaxQueue = 200 // 随便设置值)// 一个可以发送工作请求的缓冲 channelvar JobQueue chan Jobfunc init() {JobQueue = make(chan Job, MaxQueue)}type Payload struct{}type Job struct {PayLoad Payload}type Worker struct {WorkerPool chan chan JobJobChannel chan Jobquit chan bool}func NewWorker(workerPool chan chan Job) Worker {return Worker{WorkerPool: workerPool,JobChannel: make(chan Job),quit: make(chan bool),}}// Start 方法开启一个 worker 循环,监听退出 channel,可按需停止这个循环func (w Worker) Start() {go func() {for {// 将当前的 worker 注册到 worker 队列中w.WorkerPool <- w.JobChannelselect {case job := <-w.JobChannel:// 真正业务的地方// 模拟操作耗时time.Sleep(500 * time.Millisecond)fmt.Printf("上传成功:%v\n", job)case <-w.quit:return}}}()}func (w Worker) stop() {go func() {w.quit <- true}()}// 初始化操作type Dispatcher struct {// 注册到 dispatcher 的 worker channel 池WorkerPool chan chan Job}func NewDispatcher(maxWorkers int) *Dispatcher {pool := make(chan chan Job, maxWorkers)return &Dispatcher{WorkerPool: pool}}func (d *Dispatcher) Run() {// 开始运行 n 个 workerfor i := 0; i < MaxWorker; i++ {worker := NewWorker(d.WorkerPool)worker.Start()}go d.dispatch()}func (d *Dispatcher) dispatch() {for {select {case job := <-JobQueue:go func(job Job) {// 尝试获取一个可用的 worker job channel,阻塞直到有可用的 workerjobChannel := <-d.WorkerPool// 分发任务到 worker job channel 中jobChannel <- job}(job)}}}// 接收请求,把任务筛入JobQueue。func payloadHandler(w http.ResponseWriter, r *http.Request) {work := Job{PayLoad: Payload{}}JobQueue <- work_, _ = w.Write([]byte("操作成功"))}func main() {// 通过调度器创建worker,监听来自 JobQueue的任务d := NewDispatcher(MaxWorker)d.Run()http.HandleFunc("/payload", payloadHandler)log.Fatal(http.ListenAndServe(":8099", nil))}
最终采用的是两级 channel,一级是将用户请求数据放入到 chan Job 中,这个 channel job 相当于待处理的任务队列。
另一级用来存放可以处理任务的 work 缓存队列,类型为 chan chan Job。调度器把待处理的任务放入一个空闲的缓存队列当中,work 会一直处理它的缓存队列。通过这种方式,实现了一个 worker 池。大致画了一个图帮助理解,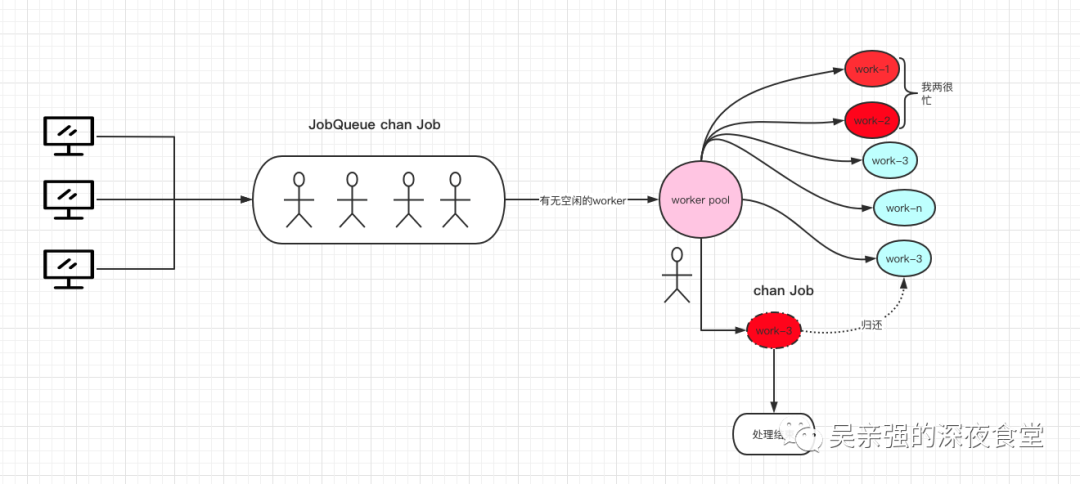
首先我们在接收到一个请求后,创建 Job 任务,把它放入到任务队列中等待 work 池处理。
func payloadHandler(w http.ResponseWriter, r *http.Request) {job := Job{PayLoad: Payload{}}JobQueue <- work_, _ = w.Write([]byte("操作成功"))}
调度器初始化work池后,在 dispatch 中,一旦我们接收到 JobQueue 的任务,就去尝试获取一个可用的 worker,分发任务给 worker 的 job channel 中。 注意这个过程不是同步的,而是每接收到一个 job,就开启一个 G 去处理。这样可以保证 JobQueue 不需要进行阻塞,对应的往 JobQueue 理论上也不需要阻塞地写入任务。
func (d *Dispatcher) Run() {// 开始运行 n 个 workerfor i := 0; i < MaxWorker; i++ {worker := NewWorker(d.WorkerPool)worker.Start()}go d.dispatch()}func (d *Dispatcher) dispatch() {for {select {case job := <-JobQueue:go func(job Job) {// 尝试获取一个可用的 worker job channel,阻塞直到有可用的 workerjobChannel := <-d.WorkerPool// 分发任务到 worker job channel 中jobChannel <- job}(job)}}}
这里"不可控"的 G 和上面还是又所不同的。仅仅极短时间内处于阻塞读 Chan 状态, 当有空闲的 worker 被唤醒,然后分发任务,整个生命周期远远短于上面的操作。
附录
推荐阅读