
算法工程师应具备的落地能力!
导读
作者从自身经验出发,从三个方面:软实力、技术和业务讲述了算法工程师落地的能力具体指向,为想要成为算法工程师或者已经工作中的小伙伴们提供一点小小的建议。
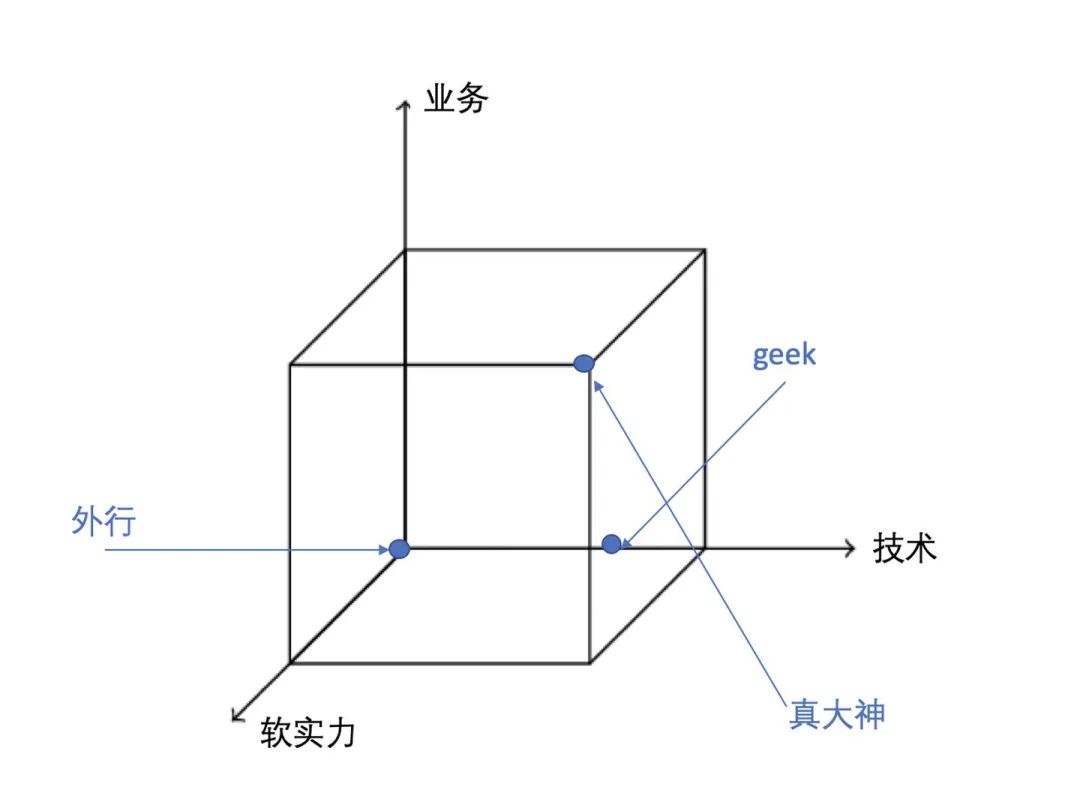
1.技术层面
 图源《如何创造可信的AI》
图源《如何创造可信的AI》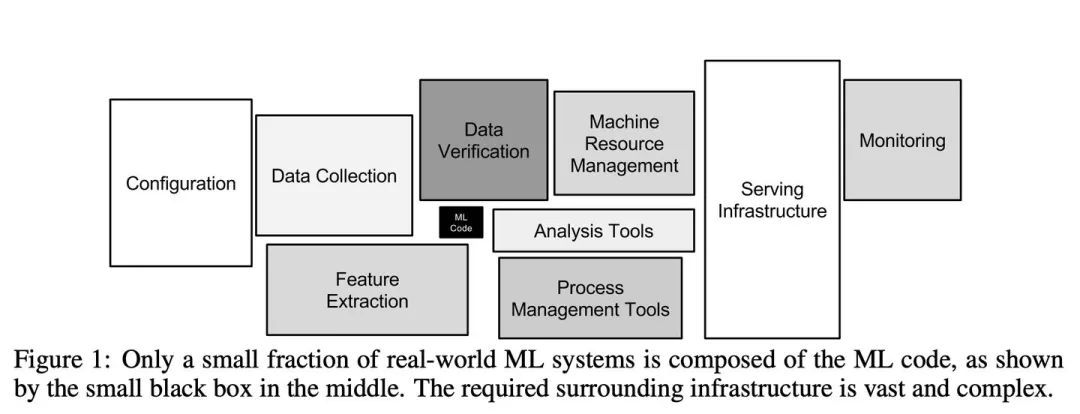
学会数据获取。原始数据需要经过ETL才能被算法利用。ETL(Extract, Transform, Load)是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。也许你们公司有专职的数据工程师来做ETL,但你如果能稍微参与到ETL的过程中,不仅让你在大数据技术方面得到提升,而且对你理解上游业务非常有帮助。ETL工具的典型代表有:Informatica、Datastage、OWB、微软DTS等。
构建特征。如果没有机会参加到ETL里,也没关系,我也没,毕竟客户不想给让我们接触原始数据。这时候,你也可以处理ETL之后的数据,从中构建特征。其实特征构建的过程能帮助你理解业务,例如给银行预测信用卡逾期风险,你了解到,债务负担率和用户风险有着一定关联,于是你会考虑把用户所有信用卡的欠款加起来除以这个用户的收入,得到一个新的特征。关于相关技术,我知道很多人肯定马上想到pandas,但老实讲句,我做了几年数据工作,能用到pandas的机会真的不多。产品都要落地了,几百万条的数据马上进来了,还在玩pandas?spark, hadoop, flink等分布式计算平台赶紧给我研究起来。
可视化数据。我相信问出来这个问题的人都知道哪些python库可以做可视化,例如matplot, seaborn等等。当然,除了python库,excel里的可视化也要做好,这与算法无关,但在你做汇报时能帮助你把一个结果解释清楚。
会用服务器。一般数据产品部署,得上云或者私有服务器吧,那么如果你还不熟悉linux,那就赶紧练练吧。你把系统部署到服务器时,是不太可能用鼠标拖拽个exe就完事的。如果你还能熟练使用aws等云服务,那就更好了。
至于UI层面,例如构建网页等等,开发app这种,这就不再推荐算法工程师学了,毕竟人的精力有限。
2.业务层面
你的产品所服务的对象所在的行业都有什么「痛点」。sorry,句子有点长,而且说法也有点「老土」,但了解客户痛点永远都是必须的。例如我做金融风控,客户的痛点是「旧的专家系统规则更新慢」,而我们提供「基于机器学习的方案」,数据来了就自动更新规则,就能解决他们痛点。
他们这项业务目前的工作流程如何。例如我做反洗钱,那么我得了解洗钱的三个步骤,反洗钱的警报产生,警报调查等等。这些流程在不同客户之间都是一样的,我了解清楚了这些,我才能知道,我的产品是在哪个环节发挥价值。如果你做的项目是对内的,例如为自己公司电商搞推荐算法,那你必须清楚用户在你们APP上的路径,例如首页到搜索页再到详情页。以及在每条路径上,怎么做推荐商品,例如有的商品是推荐搭配,有的商品是推荐近似替代品。
开发时间。即使项目刚开始,你还不知道要花多久,你也得计划开发时间出来,你计划不出来,领导也会给你设定期限。毕竟做产品不同于做研究,做产品大家都喜欢确定的投入和可预估的汇报。 计算资源。因为机器学习系统使用是需要成本的,你得知道用户能承受怎么样的成本或者自己服务器能承受怎样的成本。 算法性能。算法落地不同于打kaggle比赛,并没有时间能把性能压榨到极致。只要比预期好些,基本就「先用着再说」了
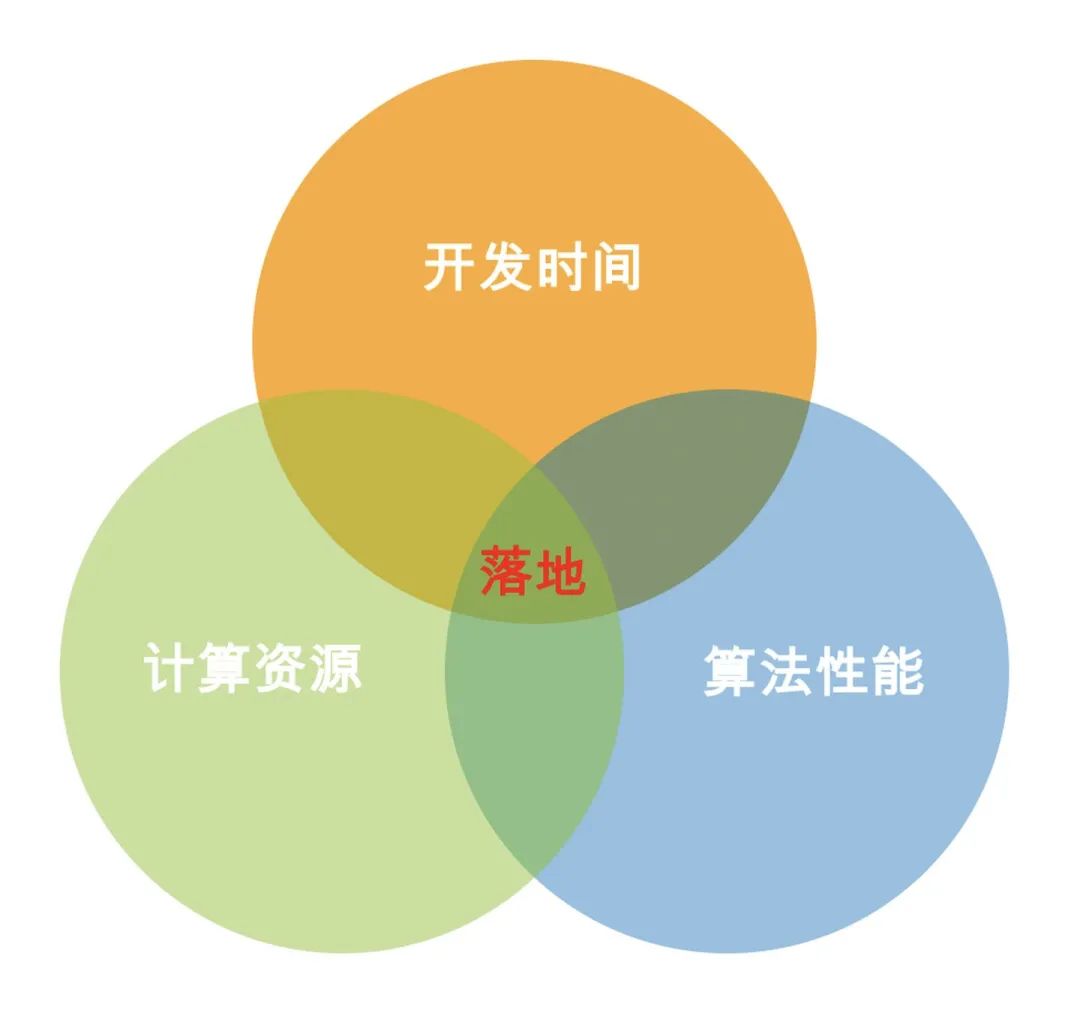
检查下自己是否能快速复现方案? 如果能快速复现方案,是否能估算每个阶段大致需要多少人多少时间? 面对不同的数据量,能否估算一个大概的服务器性能需求?
3.软实力层面
和客户沟通的能力。听你讲的客户并不一定是算法工程师或者数据科学家,你是否能把自己的方案原理讲清楚?设计到技术的概念,是否能让非技术的听众也能大致理解? 思考能力。例如结构化思维和批判性思维。其实有一定套路,只要多加练习就能掌握。推荐书籍有《金字塔原理》、《批判性思维工具》等。 推动团队的能力。和个人魅力息息相关。