
爬虫必备工具,掌握它就解决了一半的问题
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
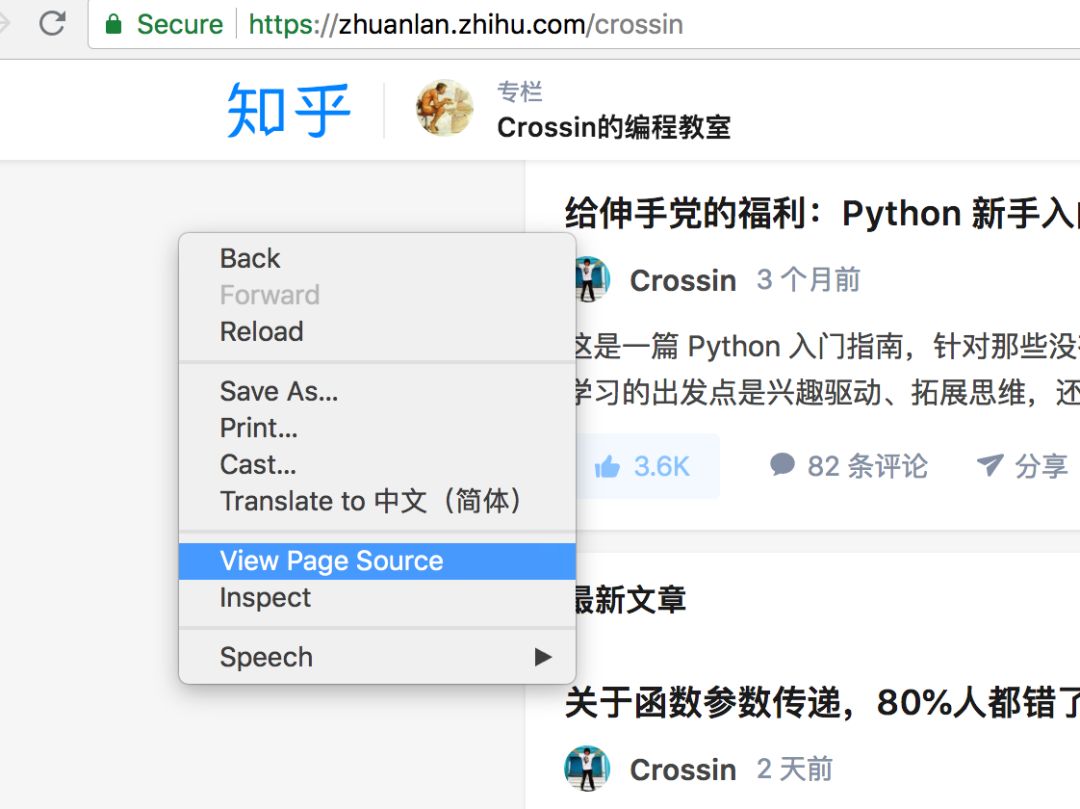
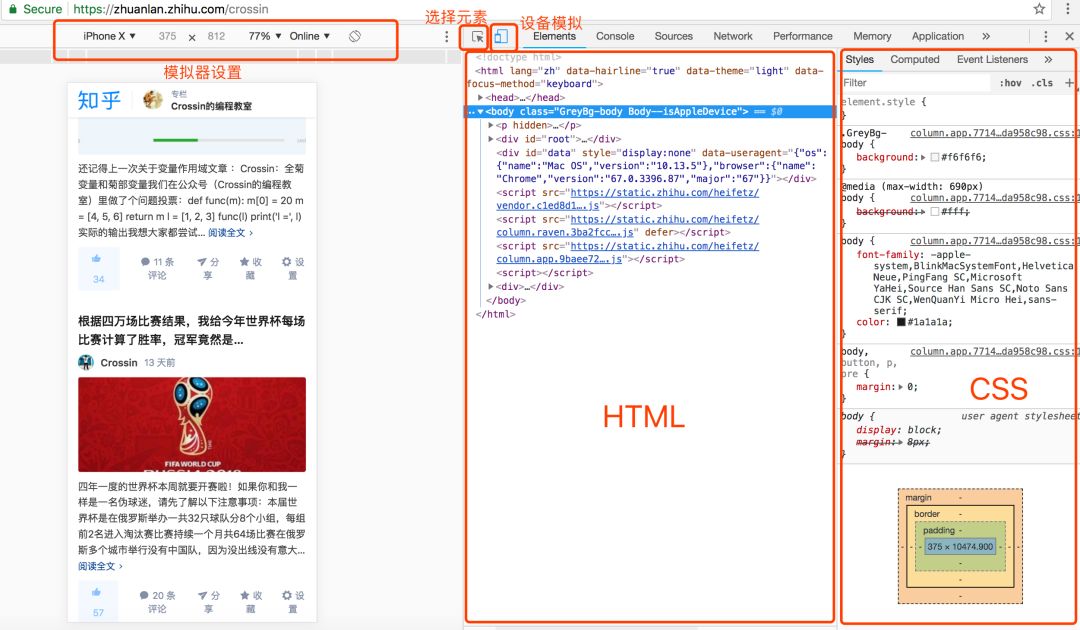
选择元素:通过鼠标去选择页面上某个元素,并定位其在代码中的位置。 模拟器:模拟不同设备的显示效果,且可以模拟带宽。 代码区:显示页面代码,以及选中元素对应的路径 样式区:显示选中元素所受的 CSS 样式影响
抓什么 怎么抓
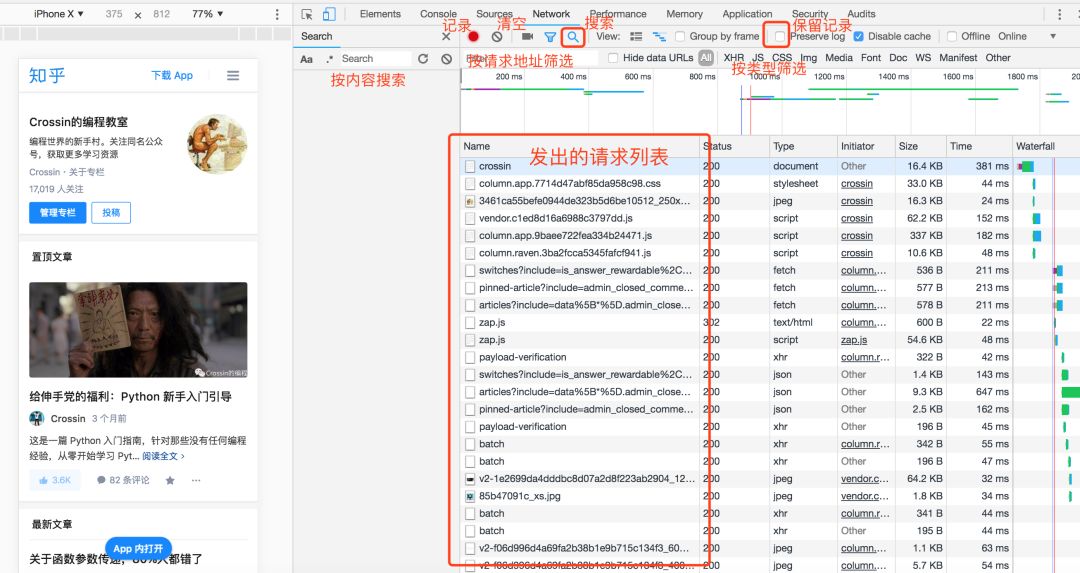
点击“搜索”功能,直接对内容进行查找。 选中 Preseve log,这样页面刷新和跳转之后,列表不会清空。 Filter 栏可以按类型和关键字筛选请求。
请求方法,是 GET 还是 POST。 请求附带的参数数据。GET 和 POST 传递参数的方法不一样。 Headers 信息。常用的包括 user-agent、host、referer、cookie 等。其中 cookie 是用来识别请求者身份的关键信息,对于需要登录的网站,这个值少不了。而另外几项,也经常会被网站用来识别请求的合法性。同样的请求,浏览器里可以,程序里不行,多半就是 Headers 信息不正确。你可以从 Chrome 上把这些信息照搬到程序里,以此绕过对方的限制。
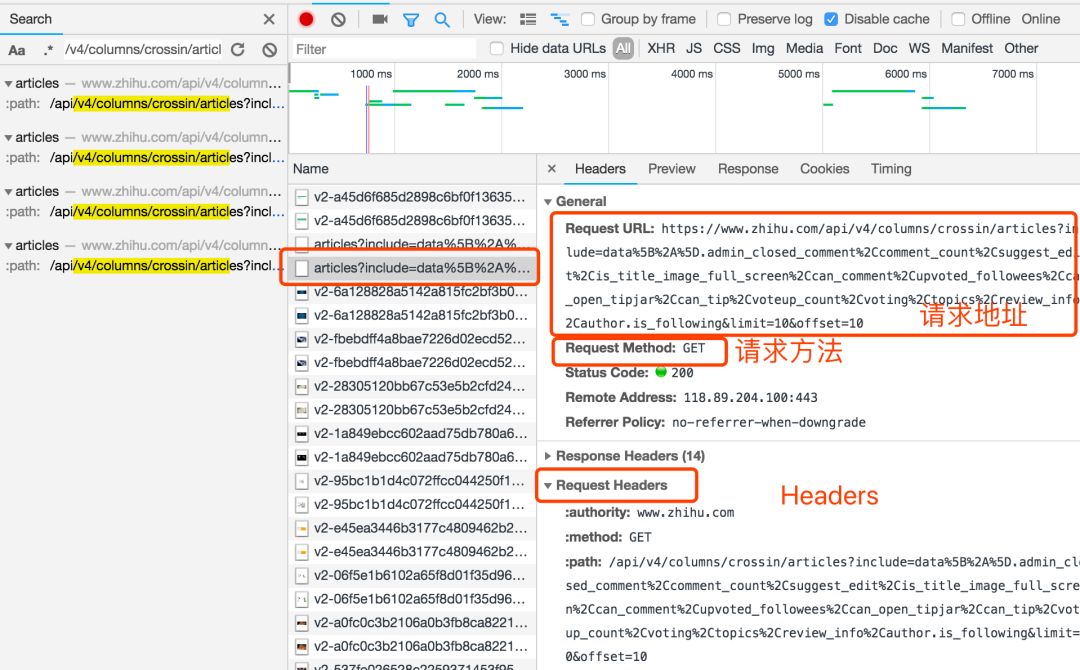
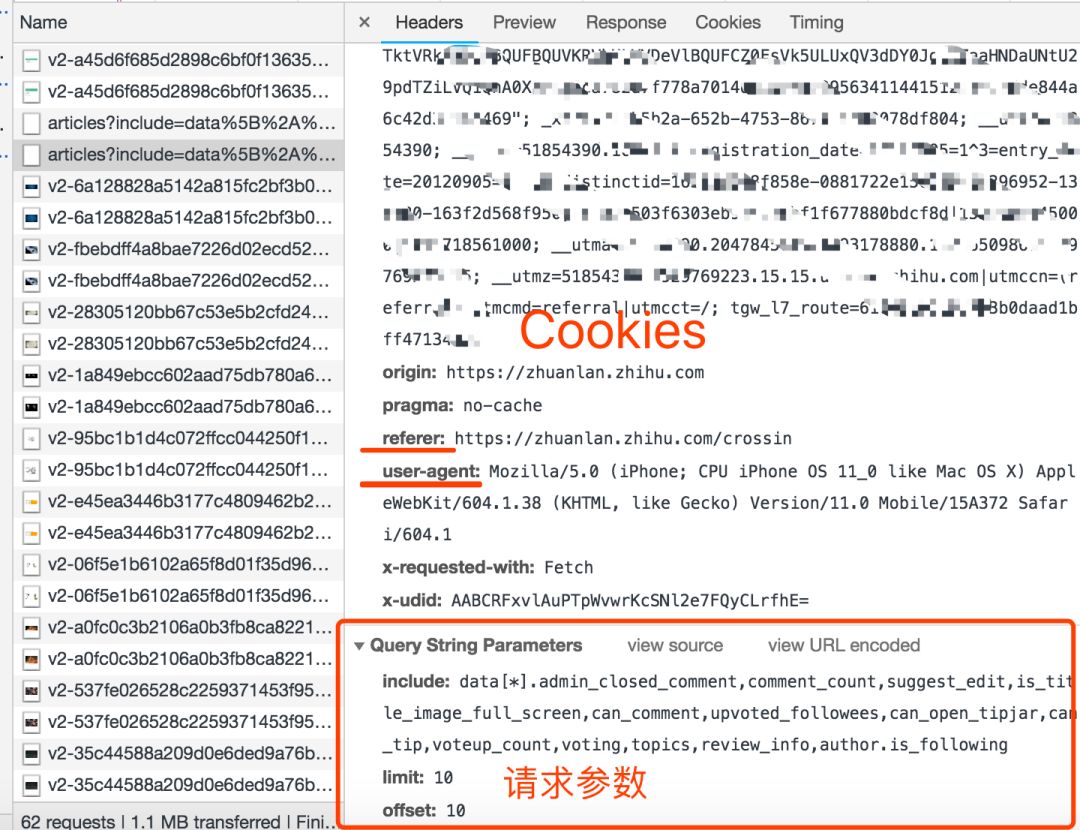
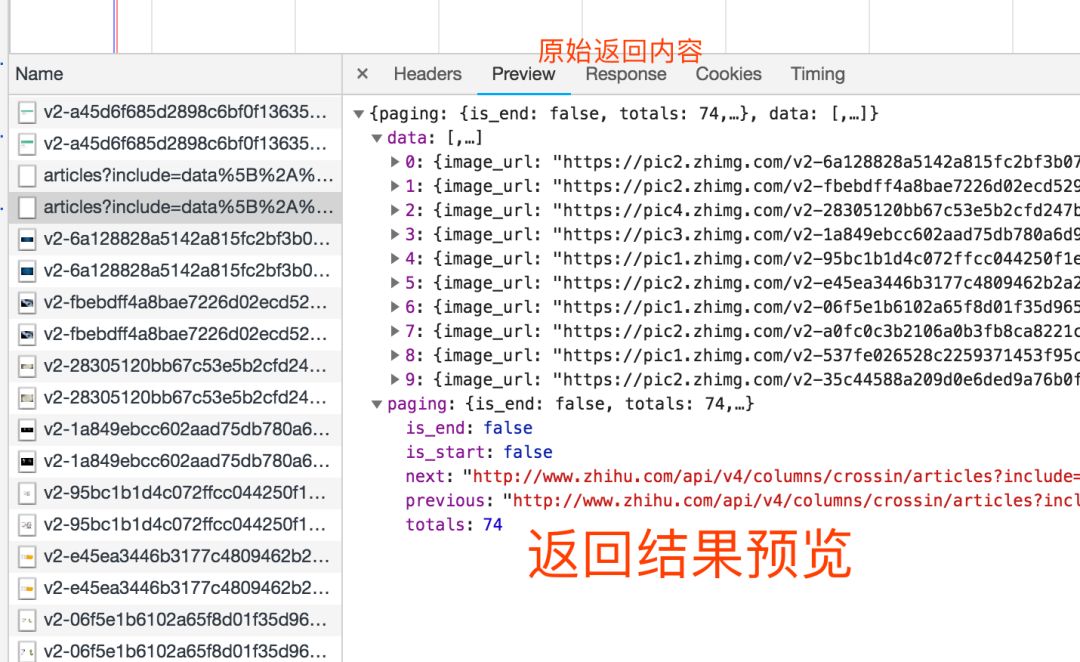
“查看源代码”里能看到的数据,可以直接通过程序请求当前 URL 获取。 Elements 里的 HTML 代码不等于请求返回值,只能作为辅助。 在 Network 里用内容关键字搜索,或保存成 HAR 文件后搜索,找到包含数据的实际请求 查看请求的具体信息,包括方法、headers、参数,复制到程序里使用。


评论