
让玛丽莲梦露表演迪士尼动画角色,CVPR论文一阶运动模型效果Redd...

新智元原创
编辑:元子、小智
【新智元导读】一个只有13秒的人脸视频在Reddit火了,发布一天就已超4k赞。我们分析了背后的技术原理,发现该项目使用的一阶运动模型来源于一篇NeurIPS论文(该论文目前也入选了CVPR 2020),并通过视频来对模型结果做了呈现。作者称,他们的框架在各种基准和各种对象类别上得分最高。「新智元急聘主笔、高级主任编辑,添加HR微信(Dr-wly)或扫描文末二维码了解详情。」
视频左上角是个真人,一个非常可爱的TikTok(抖音海外版)网红小姐姐,当时正在表演迪士尼动漫中,女性角色的经典表情动作,后面我们会给出小姐姐的完整视频。
但在此之前,我们需要先让大家了解一下,让这个视频如此火爆背后的技术。
背后的技术驱动:一阶运动模型,效果逼真感人
该项目使用的一阶运动模型来源于下面这篇NeurIPS论文。
这个模型可以根据驱动视频的运动,对源图像中的对象进行动画处理,以生成视频序列,而无需使用任何注释或有关特定对象的先验信息。
模型采用自监督的方法将外观和运动信息分离,使用了视频中对象的关键点及其局部仿射变换进行特征表示。
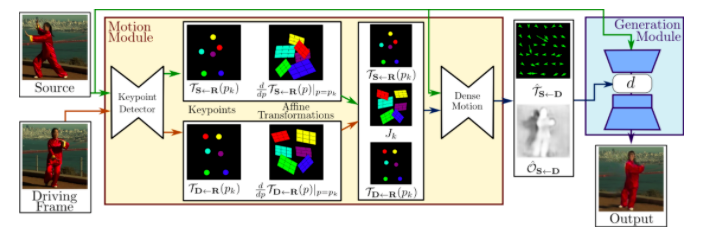 可以看出模型由两个主要模块组成:运动估计模块和图像生成模块。
可以看出模型由两个主要模块组成:运动估计模块和图像生成模块。模型假设存在一个抽象的参考框架,然后独立地估计了两种转换:从参考到源以及从参考到驱动,这样的设计使模型能够独立处理源帧和驱动帧。
第一步,模型通过自监督方式学习的关键点获得稀疏轨迹集来近似两种转换,然后使用局部仿射变换对每个关键点附近的运动进行建模。与仅使用关键点位移相比,局部仿射可以关注更多的细节变换。在第二步中,密集运动网络会组合局部近似来获得最终的密集运动场。

除了密集的运动场之外,该网络还会输出一个掩模,该掩模可以指导生成网络应该重构哪些部分,以及修复哪些部分(从上下文中推断)。最终使用一个生成器网络根据密集运动场扭曲源图像,并修复源图像中被遮挡的部分。
我们可以使用这个模型轻松地将特朗普的讲话迁移到权游中的人物,也可以让形态相似的静态马奔跑起来,还能一键完成模特的换装,对需要制作大量换装图片的美工来说简直是神器!
来,让LeCun模仿下Hinton。

用论文做成的视频效果让我们大吃亿惊!6GB GTX 1070跑起来都不如视频中顺畅
网友StevenAU说:我看着这个网红小姐姐,就像她一辈子都在研究迪士尼的公主一样,看得我停不下来。
Zenith_N:这个小姐姐简直就是动漫本漫!
a_white_american_guy:想看小姐姐,想看完整版视频!
我知道你们也想看,满足你们!
网友Faketuxedo说,他用自己的老显卡GTX 1070试了一下,觉得还是在可以接受的范围,虽然不如视频中那么的流畅。
因为GitHub上Jupyter Notebook的体验不是太好,想尝试的小伙伴可以去下面的NBVIEWER链接查看:
https://nbviewer.jupyter.org/url/github.com/AliaksandrSiarohin/first-order-model/blob/master/demo.ipynb
当然,如果你想在线跑跑代码,网友还贴心的给了一个binder链接,可以启动你自己的Jupyter服务器尝试一下!
https://mybinder.org/v2/gh/AliaksandrSiarohin/first-order-model/master?filepath=demo.ipynb
参考链接:
http://papers.NeurIPS.cc/paper/8935-first-order-motion-model-for-image-animation
https://aliaksandrsiarohin.github.io/first-order-model-website/
https://github.com/alievk/avatarify
https://arxiv.org/abs/2003.00196v2
评论