抖音前端团队的自动发包方案是如何做到的?
作者简介: zoomdong,目前在抖音前端技术团队参与 Monorepo 相关的工程化基建工作,热爱编程,热爱开源,是
pnpm、Ant Design等多个知名开源项目的贡献者。

Changesets 是一个用于 Monorepo 项目下版本以及 Changelog 文件管理的工具。目前一些比较火的 Monorepo 仓库都在使用该工具进行项目的发包例如 pnpm、mobx 等。github 仓库为: https://github.com/atlassian/changesets,在 github 上有大约 2k 的 star。
目前笔者组自研的 Monorepo 发包方案基于该方案进行二次开发,替代 lerna 成为工程化团队内部统一的发包方案,并在其它团队也取得了不错的落地效果,其中包括之前关于 pnpm 的个人文章中提到的 Tiktok FE 团队,另外也包括目前字节开源出来的 modern.js 仓库:
在这篇文章中,将会介绍 changesets 工具是如何来完成 Monorepo 仓库中项目包版本的管理、一些基本的命令使用以及原理、同时还会介绍一些缺陷以及目前可以优化的一些点。
Lerna 发包方案缺陷
在之前的文章中,有介绍过基于 lerna 发包方案的源码解析。同时笔者组自研的 Monorepo 工具中,早期版本中也是采用了 lerna 这一套的发包方案,但随着在用户中的推广以及使用,这套方案随之带来了不少问题:
ignoreChanges不能做到文件的完全忽略,存在优先级问题lerna version根据 commit 以及 tag 更新出来的包版本不符合预期生成的 CHANGELOG 文件信息不完整 lifecycle scripts经常命中一些用户自定义的 script(例如publish等)CI 中自动化发包场景需要很高的定制成本 lerna 本身不支持 workspace 协议,导致基于 pnpm 开发的一些仓库无法使用
基于以上这些缺点,包括 lerna 本身的使用成本以及冗余的代码设计,加上目前 lerna 本身停止维护,因此在调研之后,我们将自研 Monorepo 工具中发包方案逐步替换为了 changesets。
Changesets 工作流介绍
在前面我们讲过了 changesets 的作用,changesets 主要关心 monorepo 项目下子项目版本的更新、changelog 文件生成、包的发布。一个 changeset 是个包含了在某个分支或者 commit 上改动信息的 md 文件,它会包含这样一些信息:
需要发布的包 包版本的更新层级(遵循 semver 规范) CHANGELOG 信息
Changesets 工作流会将开发者分为两类角色,一类是项目的维护者,还有一类为项目的开发者,两者的职责可以通过如下流程图很简洁的表示出来:
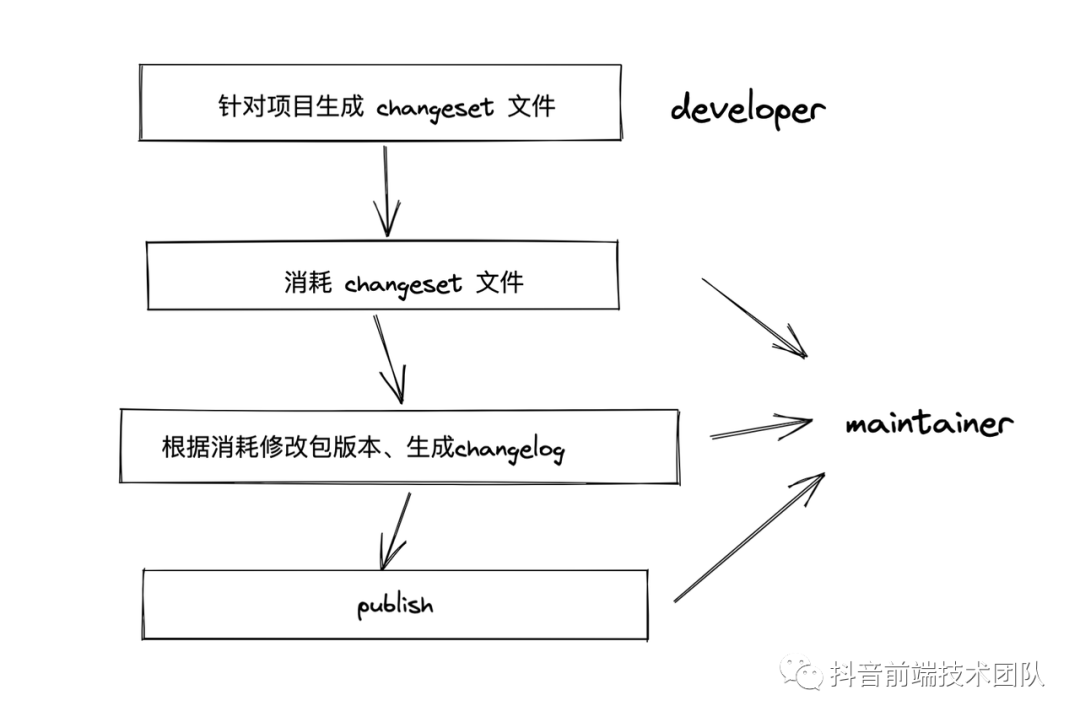
根据上图, changesets 的工作流程是这样:开发者在 Monorepo 项目下进行开发,开发完成后,给对应的子项目添加一个 changesets 文件。项目的维护者后面会通过 changesets 来消耗掉这些文件并自动修改掉对应包的版本以及生成 CHANGELOG 文件,最后将对应的包发布出去。
以上就是一个简单的 changesets 工作流,当然这些工作流会对应到具体的 cli 命令以及 config 配置中去,下面我会基于此工作流介绍一些关于 changesets 最常用的几个子命令以及使用原理。
子命令及工作原理
如果要使用 changesets,需要先安装其 CLI 工具,通过 pnpm install @changeset/cli 安装就行。安装之后,就可以按照下面的一些命令开始使用了。
init
该命令为初始化命令,通过执行 changeset init,可以在项目根目录下生成一个 .changeset 目录,里面会生成一个 changeset 的 config 文件,可以参考 pnpm 目前项目的根目录:
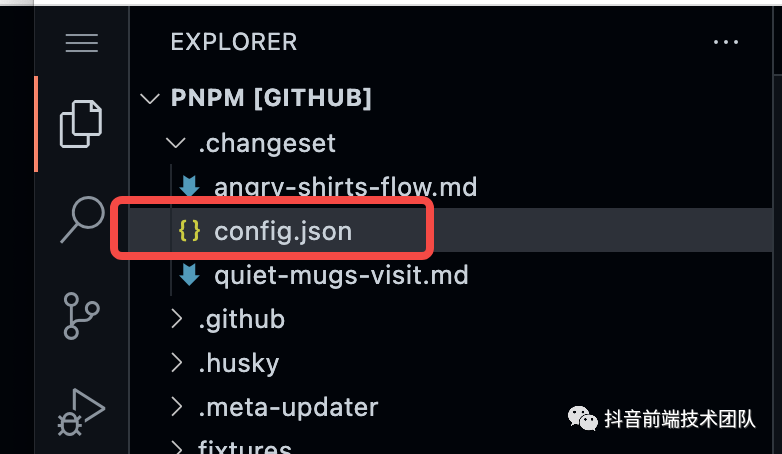
该命令原理相对简单,执行的时候通过 fs 将对应配置文件写到目录下就行,关于 config 中的具体配置描述可以参考官方文档。init 初始化出来的为默认配置,一般不需要用户去做过多的修改。
add
add 在 changesets 中算得上比较关键的命令之一了,它会根据 monorepo 下的项目来生成一个 changeset 文件,里面会包含前面提到的 changeset 文件信息(更新包名称、版本层级、CHANGELOG 信息)。
还是以 pnpm 该项目作为例子,例如在 pnpm 仓库下执行 changeset add 会出现一系列 Prompt 问题:

会让我们选择本次 changeset 需要发布的包,这些包名都是 Monorepo 项目下的子包,changesets 内部通过 getPackages() 这一方法得到 Monorepo 项目下子项目信息,该方法的具体实验可以参考 changesets 下面一个叫做 @manypkg/get-packages 的包。方法本质上是通过读 Monorepo 下所有子项目的 package.json 然后构建出一个依赖图出来,changesets 可以根据该结果得到需要进行发包流程的项目,可以说整个 changesets 项目本身都会基于底层这个方法来进行构建,有点类似于一般 Monorepo 工具中的 graph 构建。
这里同时会通过封装的 git diff 命令检查出本次 commit 修改了的包名称,不过即使是没有修改的包,用户其实也是可以进行选择的,这里不同于其他 Monorepo 发包工具的区别在于更多的修改权限在用户的手里。
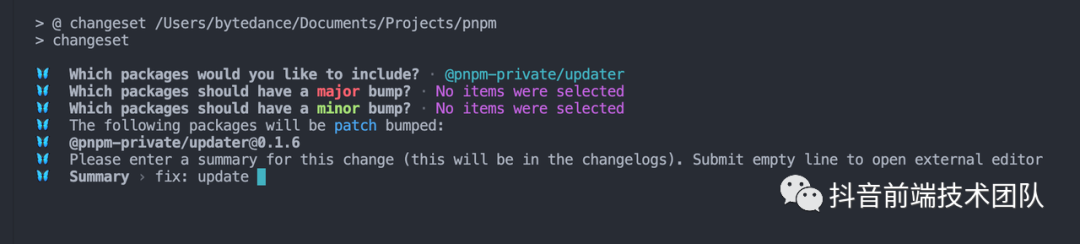
之后选择了想要发布的包之后,后面会选择到想要更新包的版本层级,例如这里我选择了 patch 级别,按照 semver 的规范,这里选择的包为 @pnpm-private,在填完 summay 之后,后面会生成一个文件名称随机的 changeset 文件,如图所示:
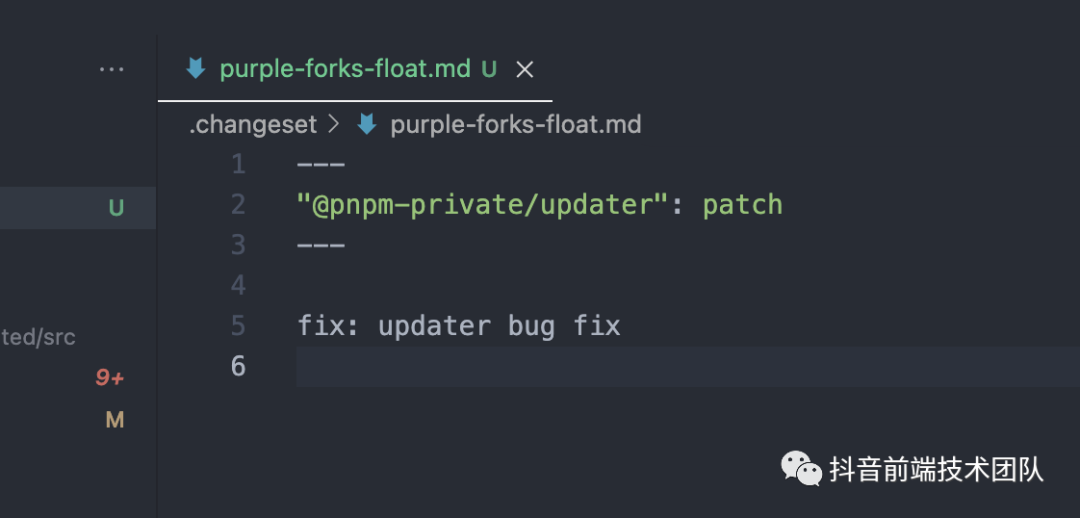
这里文件的名称是通过一个叫做 human-id 的库生成的,具体可以在 npm 上查看,但实际上这里用户也是可以自行修改文件名称的,这里并没有太大的关系,也可以修改文件里面的 CHANGELOG 的信息。
这个文件本质上是做个信息的预存储,在该文件被消耗之前,用于是可以自定义修改的。随着不同开发者的迭代积累,changeset 文件是可以在一个周期之内进行累积的。例如 pnpm 现在下面就积累了一些 changeset 文件:
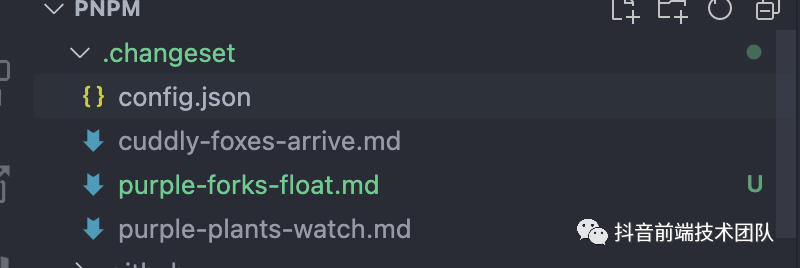
如果有信息相同,只是 CHANGELOG 描述不同的 changeset 文件,在消耗这些文件的时候是会被合并处理的,即对应包的 version 并不会被升级多次。
version
version 这个命令这里可以当作 bump version 来理解,这里本质上做的工作是消耗 changeset 文件并且修改对应包版本以及依赖该包的包版本,同时会根据之前 changeset 文件里面的信息来生成对应的 CHANGELOG 信息。version 的源码流程具体为:
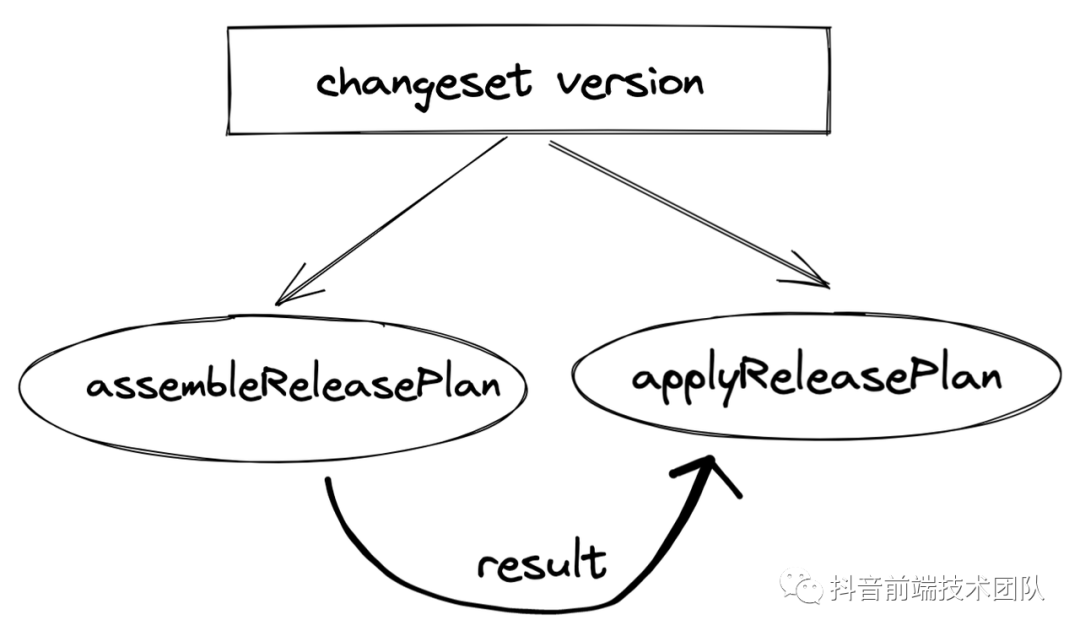
这一步的核心步骤主要在依赖于 changesets 本身项目下的两个库,分别为 @changesets/assemble-release-plan 和 @changesets/apply-release-plan ,其中 assembleReleasePlan 主要是通过读生成的 changesets 文件然后分析出需要更新的包版本以及其依赖关系,然后将读出来的待更新结果给到 applyReleasePlan 中去,在 applyReleasePlan 中则会根据相应的信息修改掉包版本、消耗掉 changeset 文件、同时更新掉 CHANGELOG 文件(如果没有就新生成一个)。
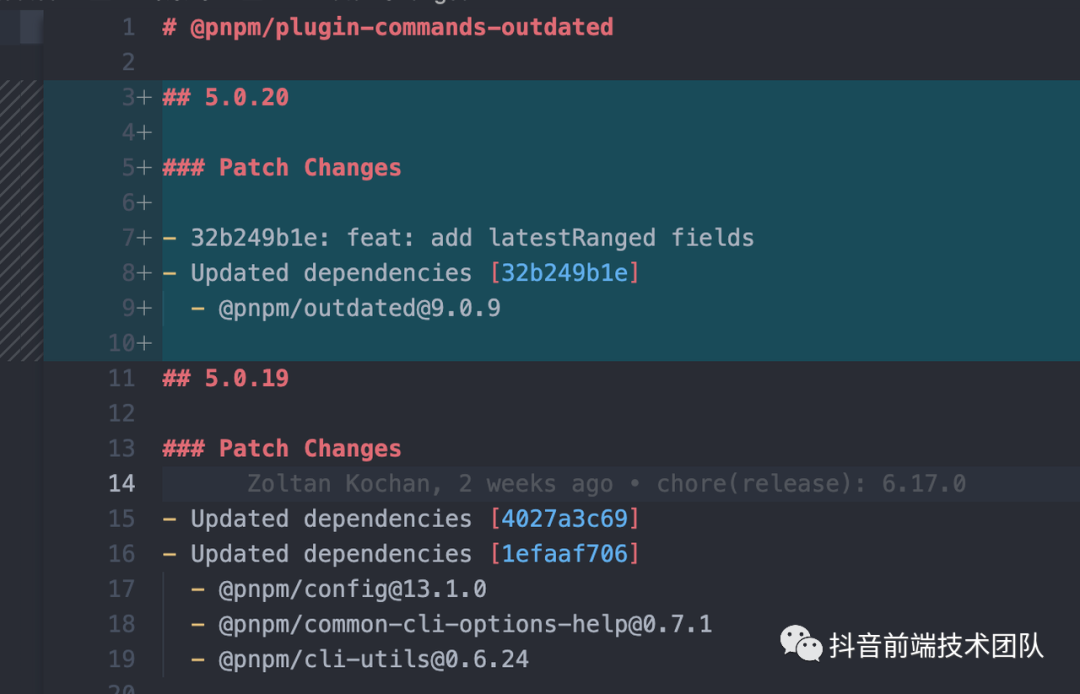
例如现在在 pnpm 仓库的根目录下执行一次 changeset version,那么就会根据上面的流程得到这样的结果:
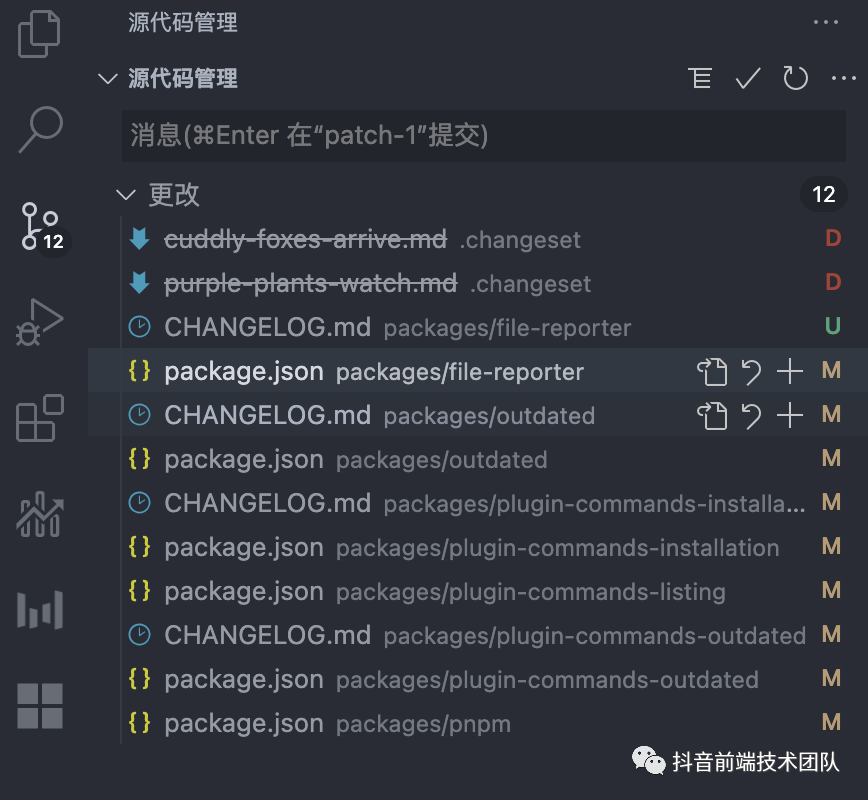
对应的 changeset 文件被消耗,然后对应子项目的 CHANGELOG 以及版本发生变更,当然改完后不满意用户还可以手动对 changelog 进行修改。自动修改的 changelog 信息如下:
其它命令
changesets 还提供了一些其他的命令,这里我就不再一一对其介绍,这些命令其实相对比较好理解并且实现上没有特别让人难以理解的地方。例如用户如果要发一个 prelease 的包版本(例如 beta、alpha 版本),那么就可以使用 changeset pre 命令,然后再结合 version 命令去进行版本的 bump。
如果用户想查看当前的 changesets 文件消耗状态,那么可以使用 changeset status 命令。
发包的 changeset publish 本质上就是对 npm publish 做了一次封装,同时会检查对应的 registry 上有没有对应包的版本,如果已经存在了,就不会再发包了,如果不存在会对对应的包版本执行一次 npm publish。
changesets 目前缺陷
笔者在前面其实有提到过目前团队开发 Monorepo 工具时,并没有直接接入 changesets 这套方案,而是通过直接 fork 该仓库进行修改,主要在于这套方案目前在一些使用场景下确实存在许多问题。
changeset 文件名随机
在前面有提到 add 这一命令生成出来的 changeset 文件名称是随机的(通过 human-id 这个库生成),那么在一个快速迭代的 Monorepo 开发场景下。例如笔者组 Monorepo 项目,每周会大概产生 20+ 的 changeset 文件,而这些文件名称又是随机的,非常不便于用户去进行管理和辨别。
因此笔者在 fork 该项目之后,通过修改了 @changesets/write 这一部分代码,使得生成的 changeset 文件能够按照分支名+用户名+id 的形式显示出来,便于不同的开发者对自己的 changeset 文件进行筛选。
命令均不支持项目筛选
例如 add 命令无法指定特定的包,而只能通过前面 getPackages() 方法得到所有的子项目名来进行选择,如果一个项目下存在好几十个子项目的话,找具体的项目就是一件很费成本的事情。
不过 add 命令至少会通过 git diff 来筛出修改的子包名称,这样在一定程度上减少了用户去找项目的成本,但是 version 命令因为没有提供对应的筛选功能,导致在一些场景下,用户只想消耗特定的 changeset 文件去更新特定包是无法完成的。
因此笔者在 fork 该项目之后,通过其与 pnpm 的 filter 机制(参考文档: https://pnpm.io/filtering)结合,使得整个工作流能够被用户进行自定义筛选。
Prelease 包发布过程繁琐
使用 changesets 如果想发一些测试版本的包,需要反复执行 changeset pre enter 、changeset pre exit 以及 changeset version 等命令,整个流程上是很繁琐的。实际上在自行维护的过程中,这些琐碎的流程可以集合到一个命令中来完成的,并不用消费如此大的成本。
项目缺少维护
这一点其实也算是支撑笔者自己 fork 源码重新搞一套的一个重要理由,目前该项目处于长期没有 PR 合并的一个状态,近半年来合并的 pr 都是一些简单的文档修改而没有实质性的功能进展:
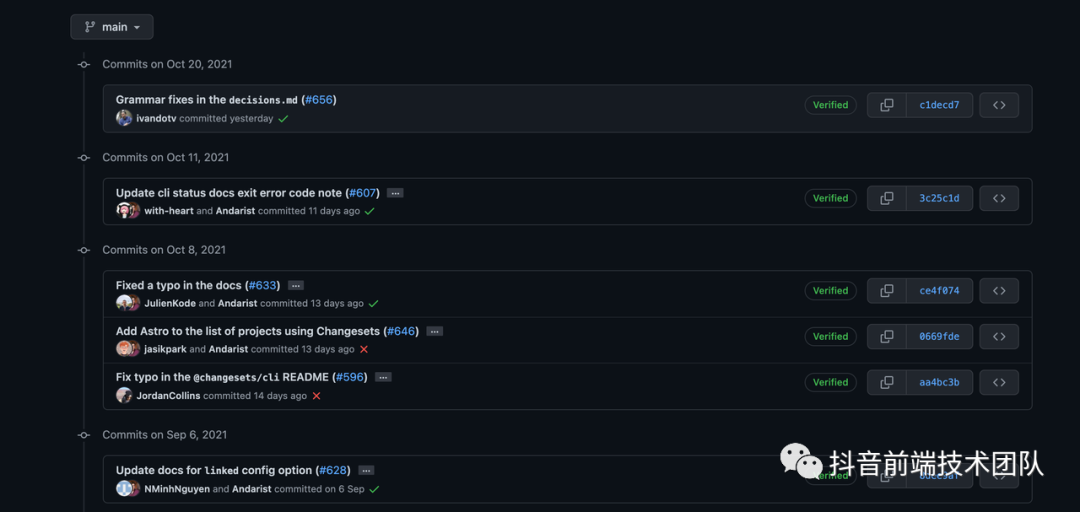
同时 changesets 本身的文档还是比较欠缺的,例如一些常见的 FAQ 文档目前还是处于 TODO 的状态。
不过好消息是最近作者已经开始活跃起来,并回复了大量的 issue ,期待能在不久之后重新将整个项目运作起来。
总结
目前的 changesets 方案整体而言在 Monorepo 项目下还是挺适用的,而且整体架构上而言并没有特别大的技术难点,主要难点在于 version bump 这一部分。
笔者认为该方案最大的优点在于提供了很大的自主权在用户手中,在复杂的业务场景下能够做出一些合适的调整,例如用户可以自行修改 changeset 文件、changelog 文件、甚至是 bump version 后不满意的版本。
相比较于 lerna 提供的比较理想化的方案而言,changeset 本身是一套泛用性很强的方案,而且比较适合当下 Monorepo 工作流场景下的一些运作方式,虽然本身还存在着不少的缺点。
期待作为目前不少 Monorepo 项目正在使用的发包方案,未来 changesets 能越来越流行~