# 打开Excel表格 data = xlrd.open_workbook("site_information.xlsx") # print(data) # <xlrd.book.Book object at 0x000001F1111C38D0> 在内存中 # 获取特定Sheet 索引为0 也就是第一个表 table = data.sheets()[0] # 从零开始 # 每条线路对应有哪些站点 字典推导式 site_dic = {k: [] for k in line_list} site_list = [] for i in range(1, table.nrows): # 每一行的数据 返回的是一个列表 x = table.row_values(i) if x[1] == "0": # 上行 站点数据 每条线路对应有哪些站点 添加进列表 site_dic[x[0]].append(x[3]) site_list.append(x[3]) else: continue # print(len(site_dic)) # 618条线路 # print(len(site_list)) # 15248条站点数据 print(f"公交网络共有 {len(line_list)} 条线路") # 618条线路
# 先初始化一个统计每个节点的度的列表 与线路名称列表里的索引一一对应 node_count = [m * 0for m in range(len(line_list))] # 以每条线路为一个节点 线路名称为键 值为一个列表 里面包含每条路线上行经过的所有站点 sites = [site for site in site_dic.values()] # print(sites) for j in range(len(sites)): # 类似冒泡法排序 比较多少趟 for k in range(j, len(sites) - 1): # 每趟比较后 往后推一个 直到比较完 和防止越界 if len(sites[j]) > len(sites[k + 1]): for x in sites[j]: if x in sites[j] and x in sites[k + 1]: # 只要这两条线路有公共站点 节点度数加1 node_count[j], node_count[k + 1] = node_count[j] + 1, node_count[k + 1] + 1 break# 两条线路对应在列表索引的值加1 这两条线的比较结束 else: for x in sites[k + 1]: if x in sites[j] and x in sites[k + 1]: # 只要这两条线路有公共站点 节点度数加1 node_count[j], node_count[k + 1] = node_count[j] + 1, node_count[k + 1] + 1 break# 两条线路对应在列表索引的值加1 这两条线的比较结束 # print(node_count) # 节点编号 与 节点的度数索引对应 node_number = [y for y in range(len(node_count))] # 线性网络度的最大值 175 print(f"线路网络的度的最大值为:{max(node_count)}") print(f"线路网络的度的最小值为:{min(node_count)}") print(f"线路网络的度的平均值为:{sum(node_count) / len(node_count)}") # 设置大小 图的像素 # 设置字体 matplotlib 不支持显示中文 自己本地设置 plt.figure(figsize=(10, 6), dpi=150) mpl.rcParams['font.family'] = 'SimHei'
# 打开Excel表格 data = xlrd.open_workbook("site_information.xlsx") # print(data) # <xlrd.book.Book object at 0x000001F1111C38D0> 在内存中 # 获取特定Sheet 索引为0 也就是第一个表 table = data.sheets()[0] # 从零开始 # 每条线路对应有哪些站点 字典推导式 site_dic = {k: [] for k in line_list} site_list = [] for i in range(1, table.nrows): # 每一行的数据 返回的是一个列表 x = table.row_values(i) if x[1] == "0": # 上行 站点数据 每条线路对应有哪些站点 添加进列表 site_dic[x[0]].append(x[3]) site_list.append(x[3]) else: continue # print(len(site_dic)) # 618条线路 # print(len(site_list)) # 15248条站点数据 # 先初始化一个统计每个节点的度的列表 与线路名称列表里的索引一一对应 node_count = [m * 0for m in range(len(line_list))] # 以每条线路为一个节点 线路名称为键 值为一个列表 里面包含每条路线上行经过的所有站点 sites = [site for site in site_dic.values()] # print(sites) for j in range(len(sites)): # 类似冒泡法排序 比较多少趟 for k in range(j, len(sites) - 1): # 每趟比较后 往后推一个 直到比较完 和防止越界 if len(sites[j]) > len(sites[k + 1]): for x in sites[j]: if x in sites[j] and x in sites[k + 1]: # 只要这两条线路有公共站点 节点度数加1 node_count[j], node_count[k + 1] = node_count[j] + 1, node_count[k + 1] + 1 break# 两条线路对应在列表索引的值加1 这两条线的比较结束 else: for x in sites[k + 1]: if x in sites[j] and x in sites[k + 1]: # 只要这两条线路有公共站点 节点度数加1 node_count[j], node_count[k + 1] = node_count[j] + 1, node_count[k + 1] + 1 break# 两条线路对应在列表索引的值加1 这两条线的比较结束 # print(node_count) # 节点编号 与 节点的度数索引对应 node_number = [y for y in range(len(node_count))] # 线性网络度的最大值 175 # print(max(node_count))
# 打开Excel表格 data = xlrd.open_workbook("site_information.xlsx") # print(data) # <xlrd.book.Book object at 0x000001F1111C38D0> 在内存中 # 获取特定Sheet 索引为0 也就是第一个表 table = data.sheets()[0] # 从零开始 # 每条线路对应有哪些站点 字典推导式 site_dic = {k: [] for k in line_list} site_list = [] for i in range(1, table.nrows): # 每一行的数据 返回的是一个列表 x = table.row_values(i) if x[1] == "0": # 只取上行站点数据 每条线路对应有哪些站点 添加进列表 site_dic[x[0]].append(x[3]) site_list.append(x[3]) else: continue # print(len(site_dic)) # 618条线路 # print(len(site_list)) # 15248条站点数据 # 先初始化一个统计每个节点的度的列表 与线路名称列表里的索引一一对应 node_count = [m * 0for m in range(len(line_list))] # 以每条线路为一个节点 线路名称为键 值为一个列表 里面包含每条路线上行经过的所有站点 sites = [site for site in site_dic.values()] # print(sites) # 统计各节点的度 for j in range(len(sites) - 1): # 类似冒泡法排序 比较多少趟 for k in range(j, len(sites) - 1): # 每趟比较后 往后推一个 直到比较完 和防止越界 if len(sites[j]) > len(sites[k + 1]): for x in sites[j]: if x in sites[j] and x in sites[k + 1]: # 只要这两条线路有公共站点 节点度数加1 node_count[j], node_count[k + 1] = node_count[j] + 1, node_count[k + 1] + 1 break# 两条线路对应在列表索引的值加1 这两条线的比较结束 else: for x in sites[k + 1]: if x in sites[j] and x in sites[k + 1]: # 只要这两条线路有公共站点 节点度数加1 node_count[j], node_count[k + 1] = node_count[j] + 1, node_count[k + 1] + 1 break# 两条线路对应在列表索引的值加1 这两条线的比较结束
# 找到该节点的邻居节点 邻居节点间实际的边数 Ei = [] # 对每条线路进行找邻接节点 并统计其邻接节点点实际的边数 for a in range(len(sites)): neighbor = [] if node_count[a] == 0: Ei.append(0) continue if node_count[a] == 1: Ei.append(0) continue for b in range(len(sites)): if a == b: # 自身 不比 continue if len(sites[a]) > len(sites[b]): # 从站点多的线路里选取站点 看是否有公共站点 for x in sites[a]: if x in sites[a] and x in sites[b]: # 找到邻居节点 neighbor.append(sites[b]) break else: for x in sites[b]: if x in sites[a] and x in sites[b]: # 找到邻居节点 neighbor.append(sites[b]) break # 在邻居节点中判断这些节点的实际边数 又类似前面的方法 判断两两是否相连 count = 0 for c in range(len(neighbor) - 1): for d in range(c, len(neighbor) - 1): # 每趟比较后 往后推一个 直到比较完 和防止越界 try: if len(sites[c]) > len(sites[d + 1]): for y in sites[c]: if y in sites[c] and y in sites[d + 1]: # 邻居节点这两个也相连 count += 1 break else: continue else: for y in sites[d + 1]: if y in sites[c] and y in sites[d + 1]: # 邻居节点这两个也相连 count += 1 break else: continue except IndexError: break Ei.append(count)
# 每个节点的邻居节点间实际相连的边数 # print(Ei) # 节点编号 与 节点的度数索引对应 node_number = [y for y in range(len(node_count))]
# 设置字体 matplotlib 不支持显示中文 自己本地设置 mpl.rcParams['font.family'] = 'SimHei' # 设置大小 图的像素 plt.figure(figsize=(10, 6), dpi=150) # 公交线路网络的聚类系数分布图像 相邻节点的连通程度 Ci = [] for m in range(len(node_number)): if node_count[m] == 0: Ci.append(0) elif node_count[m] == 1: Ci.append(0)

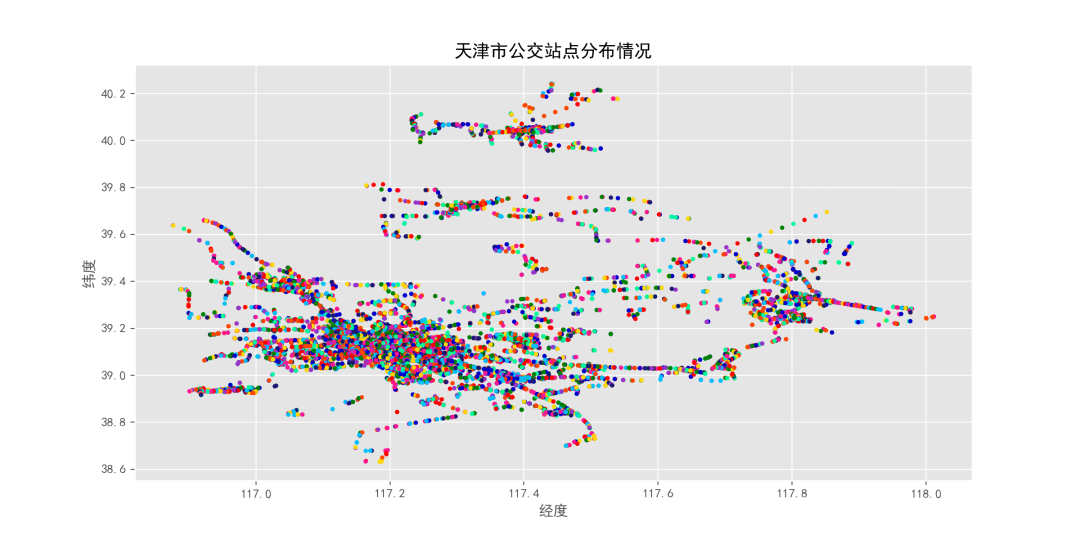 一、数据查看和预处理
一、数据查看和预处理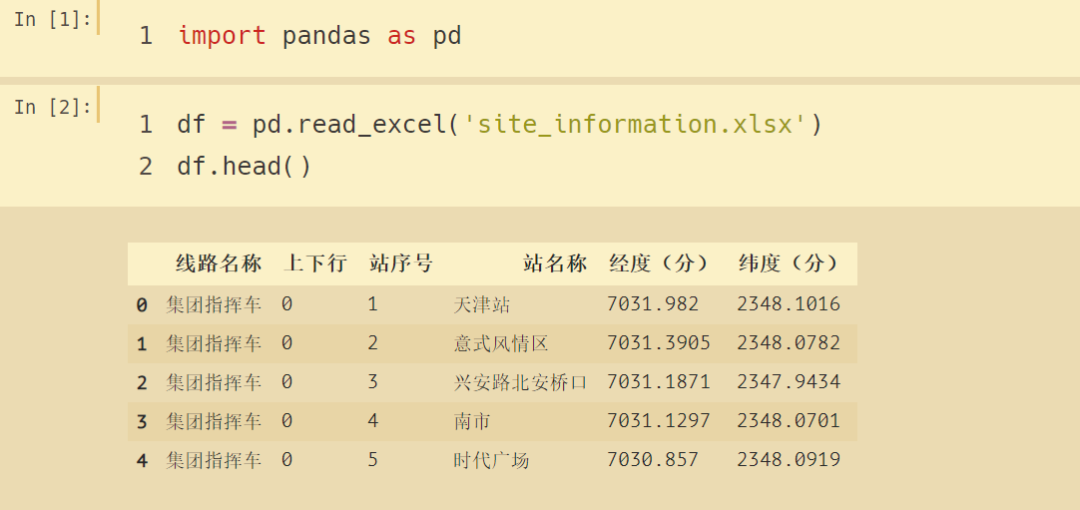
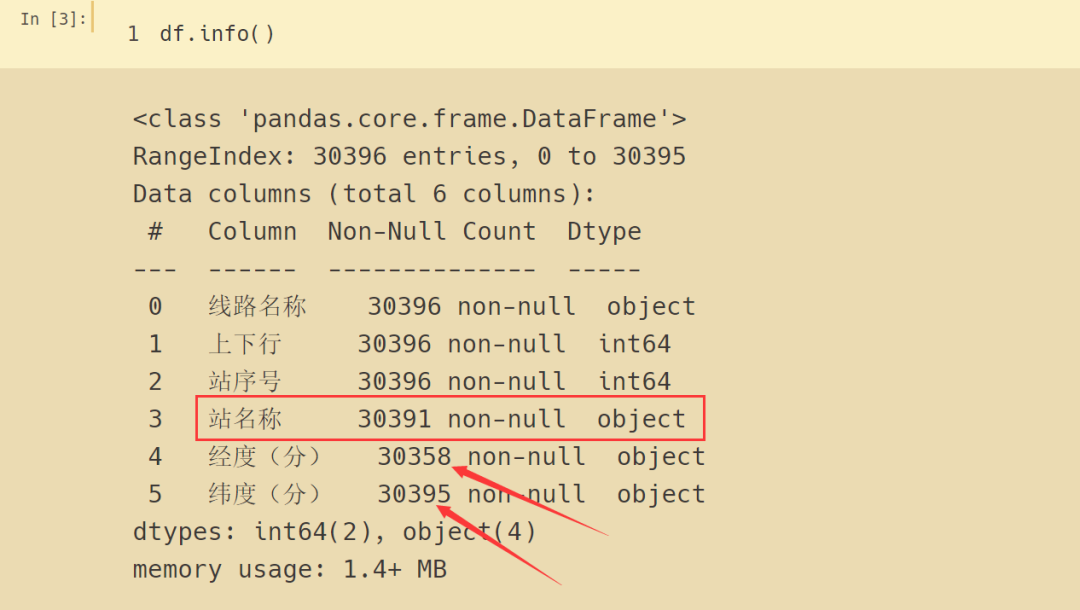 总的数据有 30396 条,站名称缺失了 5 条,纬度(分)缺失了 1 条,经度(分)缺失了 38 条,为了处理方便,直接把有缺失值的行删除。
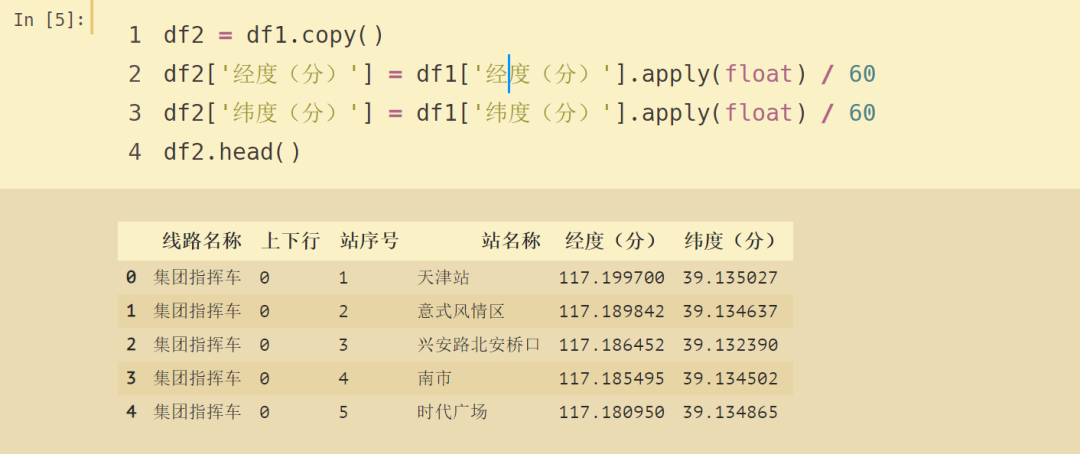
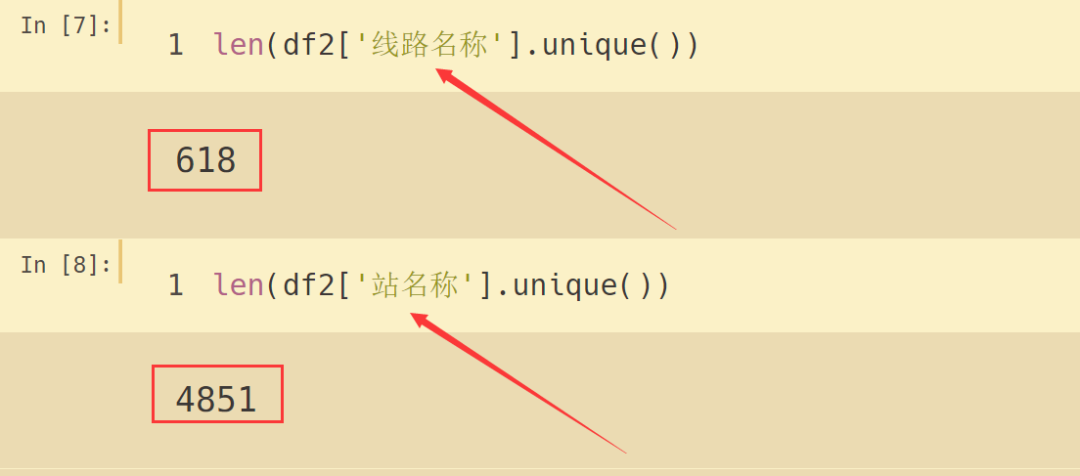
总的数据有 30396 条,站名称缺失了 5 条,纬度(分)缺失了 1 条,经度(分)缺失了 38 条,为了处理方便,直接把有缺失值的行删除。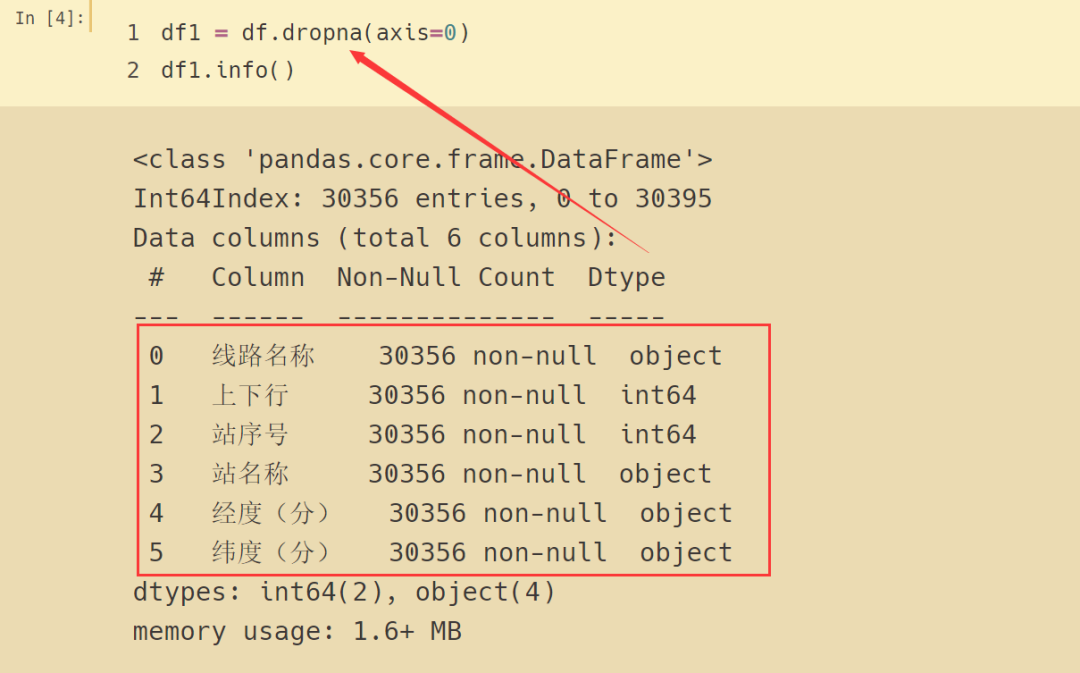
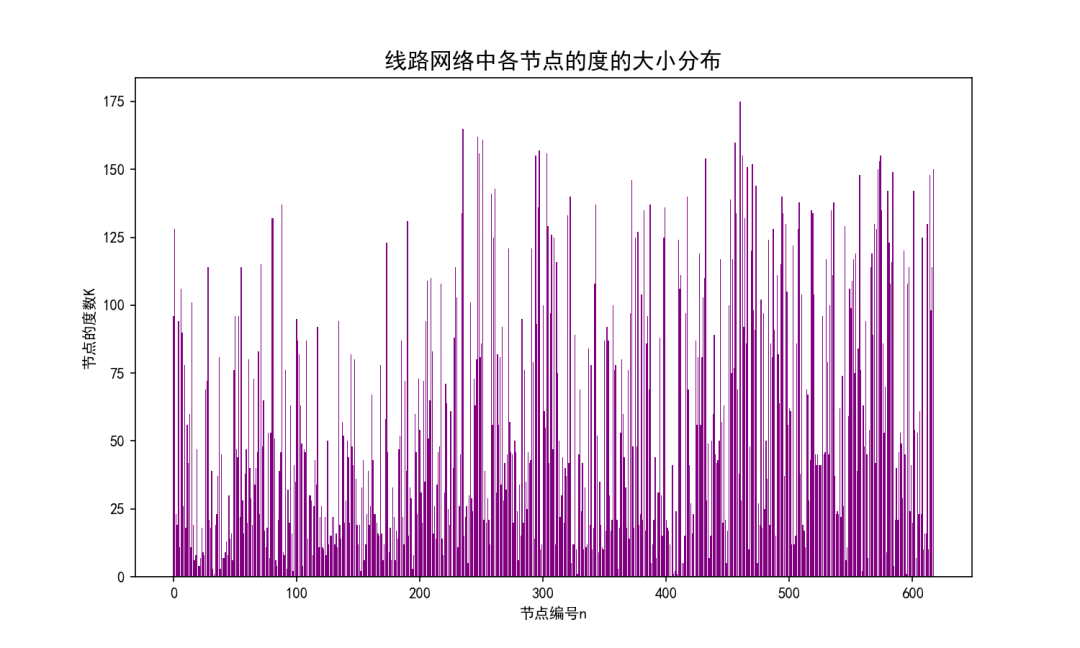
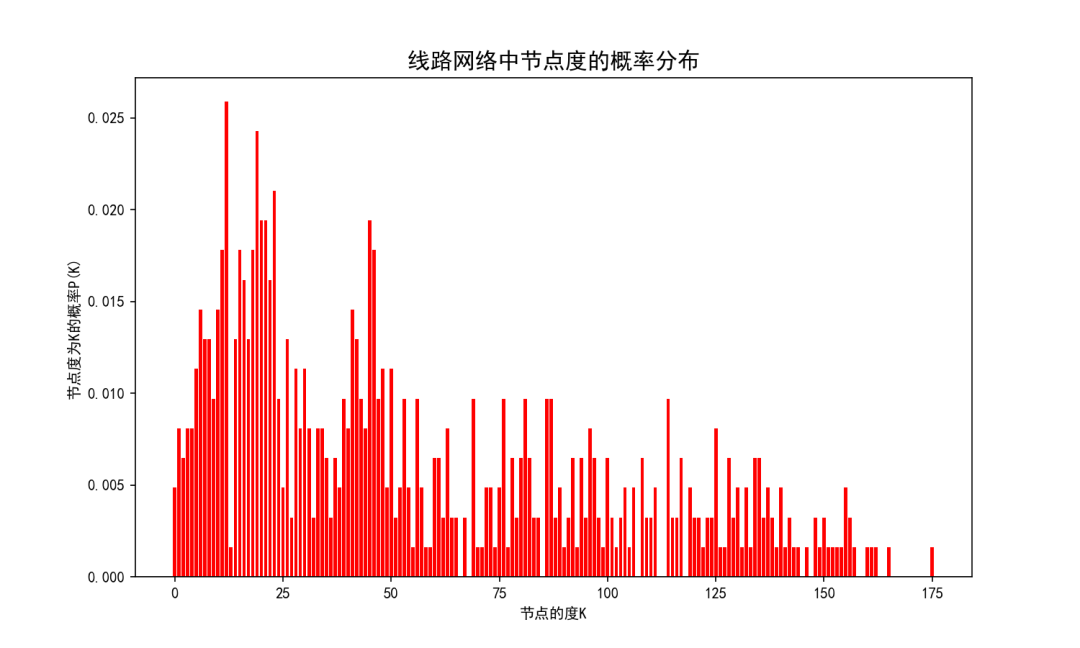 天津市公交线路网络的度分布如上图所示,本文收集的天津市线路网络共有 618 条线路组成,线路网络的度的最大值为175。概率分布中概率最大的度值为16,度平均值为55.41,表明天津市公交网络提供的换乘机会较多,使得可达性较高。其中概率较大的度值大多集中在 7~26 之间,使得节点强度分布相对来说不够均匀,造成天津市很多路段公交线路较少,少数路段经过线路过于密集,造成资源的浪费。
天津市公交线路网络的度分布如上图所示,本文收集的天津市线路网络共有 618 条线路组成,线路网络的度的最大值为175。概率分布中概率最大的度值为16,度平均值为55.41,表明天津市公交网络提供的换乘机会较多,使得可达性较高。其中概率较大的度值大多集中在 7~26 之间,使得节点强度分布相对来说不够均匀,造成天津市很多路段公交线路较少,少数路段经过线路过于密集,造成资源的浪费。
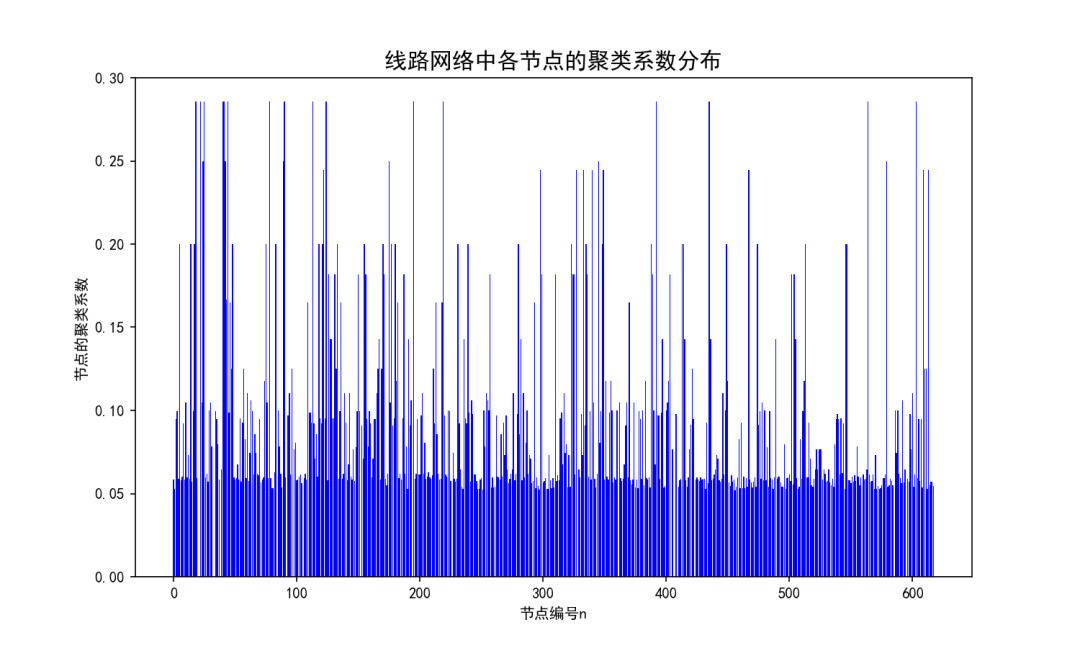
 聚类系数是研究节点邻居之间的连接紧密程度,因此不必考虑边的方向。对于有向图,将其当成无向图来处理。网络聚类系数大,表明网络中节点与其附近节点之间的连接紧密度程度高,即与实际站点之间的公交线路连接密集。计算得到天津公交复杂网络的聚类系数为0.091,相对其他城市较低。
聚类系数是研究节点邻居之间的连接紧密程度,因此不必考虑边的方向。对于有向图,将其当成无向图来处理。网络聚类系数大,表明网络中节点与其附近节点之间的连接紧密度程度高,即与实际站点之间的公交线路连接密集。计算得到天津公交复杂网络的聚类系数为0.091,相对其他城市较低。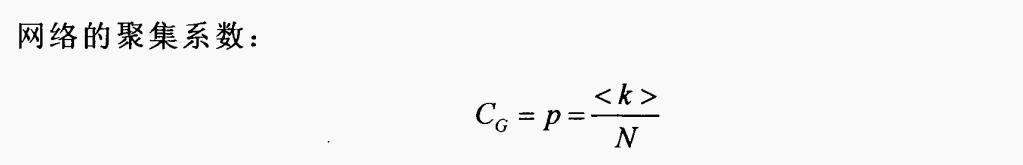 同规模的随机网络聚集系数约为0.00044,进一步体现了网络的小世界特性。
同规模的随机网络聚集系数约为0.00044,进一步体现了网络的小世界特性。