
Vert.x 操作数据库
 哈喽,大家好,欢迎阅读闲话Java的Vert.x部分,本篇是闲话Vert.x的第四期,《Vert.x操作数据库》。本期由闲话哥带您了解,如何通过Vert.x来连接数据库。
哈喽,大家好,欢迎阅读闲话Java的Vert.x部分,本篇是闲话Vert.x的第四期,《Vert.x操作数据库》。本期由闲话哥带您了解,如何通过Vert.x来连接数据库。
后续所使用的代码均开源在:https://github.com/happy-fly/wxcode
为什么不用Mybatis或者Hibernate
Vert.x提供异步访问数据库的API,可能这里有朋友会有疑惑,直接使用我们之前的熟悉的Mybatis或者Hibernate不行吗,可行,但数据库操作是一个耗时操作,使用传统的同步模型,容易阻塞线程,导致整体性能下降,因此我们对于数据库操作,需要使用Vert.x提供的异步API。
Vert.x提供的API层级非常低,可以说是仅仅在原生JDBC基础上封装了一层异步接口。所有的对数据库操作都需要通过编写SQL来完成,参数的封装和结果的获取都需要手动的来实现,对于习惯使用ORM框架的开发者可能会非常的不习惯。
下面就来一个具体的例子来对数据库进行个crud。
增删改查
Vert.x的数据库操作还是比较简单的,类似于Apache的DbUtils或者是Spring的JDBCTemplate。基本上就是写了SQL,然后填上参数,再读取结果。
我个人认为,在Vert.x中是不提倡使用PO等对象的,数据封装用JsonObject,那么对于数据的序列化、反序列化包括数据的传输,异构平台的数据交互就都满足了。所以在我参与的系统中,都没有涉及到类似于User,Dept之类的对象,数据就存储到JsonObject中。
在开发中,你需要转变思想,不能总想着封装对象。比如在下面的例子中,查询数据库的结果,官方的API就帮助我们把结果封装到JsonObject中了,对于多行多列的结果,就会封装为List<JsonObject>。
废话不多说,我们实现一个基于User信息的增删改查。
准备工作
引入依赖包,这里需要引入vertx-jdbc和mysql驱动包
<dependency><groupId>io.vertx</groupId><artifactId>vertx-jdbc-client</artifactId><version>${vertx.version}</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.13</version></dependency>
主方法
创建一个Verticle,在Verticle的start方法中写我们的测试代码,最终如下。
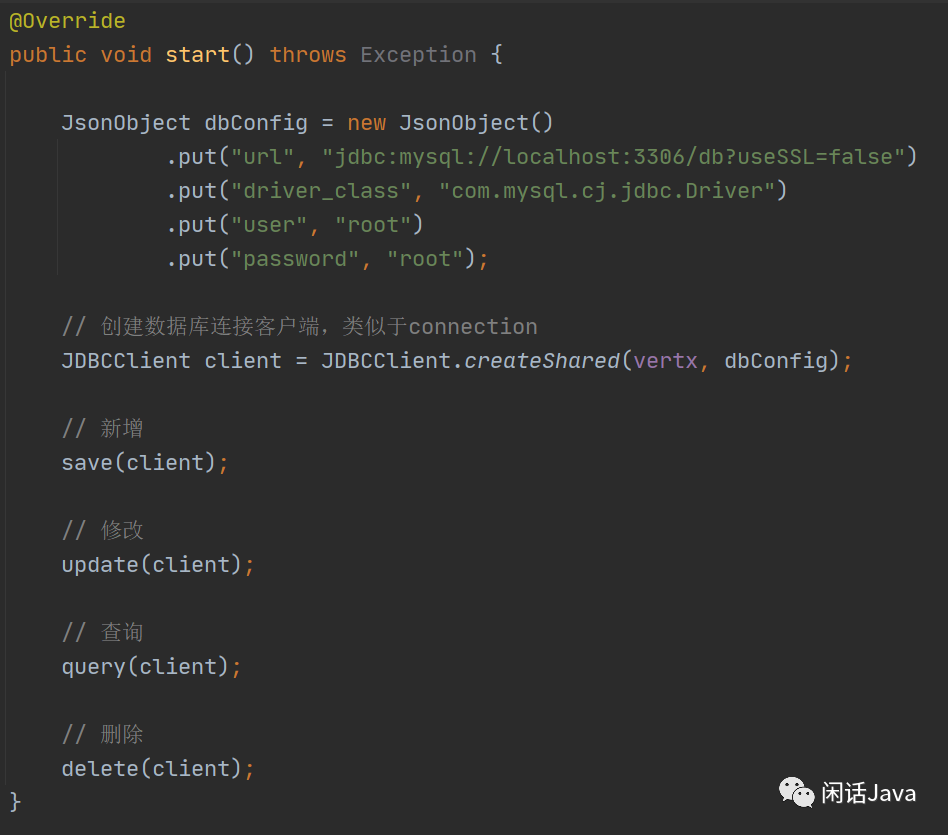
运行结果会按新增、修改、查询、删除的顺序执行吗?
不会的!这四个方法会同时执行,谁先抢到CPU的时间片,谁就先执行。因为这四个方法都是异步的。
新增(基础)
update方法接收两个参数,第一个参数是我们要执行的SQL。第二个参数是Handler。Handler<AsyncResult<UpdateResult>> handler。这种参数我们不是第一次遇见了,后续我会带大家分析下Handler的实现机制。Handler中有一个泛型参数AsyncResult,标识的是异步结果,也有一个泛型参数UpdateResult,这个参数就是异步方法执行完毕后响应的数据。
update方法进行了重载,可以在SQL和Handler中间传入一个JsonArray。对于SQL中带有参数的情景,在SQL中用“?”进行替代,然后将参数的值放到JsonArray中,传入到update方法中即可。参考后续修改操作的代码!
private void save(JDBCClient client) {String sql = "insert into user(name) values ('zhangsan')";client.update(sql, r -> {if (r.succeeded()) {System.out.println("保存成功");}});}
修改(SQL中带参数)
代码结构和上面的新增是完全相同的,这里演示了SQL中带参数是情景,这种情景在开发中会用的更多。
private void update(JDBCClient client) {String sql = "update user set name = ? where id = ?";// 带参数JsonArray params = new JsonArray().add("lisi").add(1);client.updateWithParams(sql, params, r -> {if (r.succeeded()) {System.out.println("删除成功");}});}
删除
这里只是换了SQL,其他的都不变。
private void delete(JDBCClient client) {String sql = "delete from user";client.update(sql, r -> {if (r.succeeded()) {System.out.println("删除成功");}});}
查询
查询主要关注点是结果的封装。
多行多列 :queryWithParams List<JsonObject>
单行多列:querySingleWithParams JsonArray
多行单列:同多行多列
单行单列:同单行多列
我习惯性都用queryWithParams,然后对结果进行处理后拿到想要的数据,下面是一个单行多列的例子。
private void query(JDBCClient client) {String sql = "select * from sys_user where id = ?";JsonArray params = new JsonArray().add(1);client.queryWithParams(sql, params, r -> {if (r.succeeded()) {List<JsonObject> rows = r.result().getRows();System.out.println(rows.get(0));} else {System.out.println(r.cause());}});}
CRUD小结
通过上面的代码,可以很轻松的看到,基本的增删改查还是比较简单的。贴近于原生的写法。
对于刚开始接触Vert.x的朋友,一定感觉非常不适应,首先是这么原始的吗,我们之前都jpa了,这是哪个年代的框架。第二个就是“对象”呢?为啥用JsonObject啊,我怎么知道JsonObject里面到底有哪些属性呢?
对于这两个问题我现在没法给到具体的答案,毕竟用过DbUtils的朋友可能也不多,灵活和性能也未必体会的到。对于数据封装到JsonObject中,这个真是利弊都有,祸兮福所倚,福兮祸所伏。福祸相依,有无相生,难易相成,长短相形,高下相倾,音声相和,前后相随。
到这里数据库操作就结束了吗?没有,还有两个很难解决的问题。
循环执行多条SQL该怎么处理呢?
如何执行事务操作?
这两个问题都不好解决,而且写起来都非常的恶心,我们挨个的看下吧。
循环执行SQL
循环执行有几种表现形式
循环相同的SQL,参数不同,且参数提前可以确定
循环相同的SQL,次数在可控范围之内
循环相同的SQL,参数不同,参数依赖上一个SQL的结果
对于前两种形式,都很好处理,第一种可以使用updateBatch提供的批量操作。第二种既然是次数可控,那就用Vert.x提供的fluent编程风格,一个接一个的处理,虽然low,但也能解决问题。最麻烦的是第三种形式。
批量执行相同SQL
批量执行相同SQL,可以通过batchWithParams方法,这个方法中就接收了执行的SQL和SQL所依赖的参数。这个参数的形式是List<JsonArray>。那么这样我们就能很轻松的解决批量的问题。
按照面向对象的思维方式,我们期望直接通过client.batchWithParams,当你这么写的时候,你会发现找不到这个方法。其实,这个方法是在SQLConnection对象中的,因此,我们要先来获得连接对象。
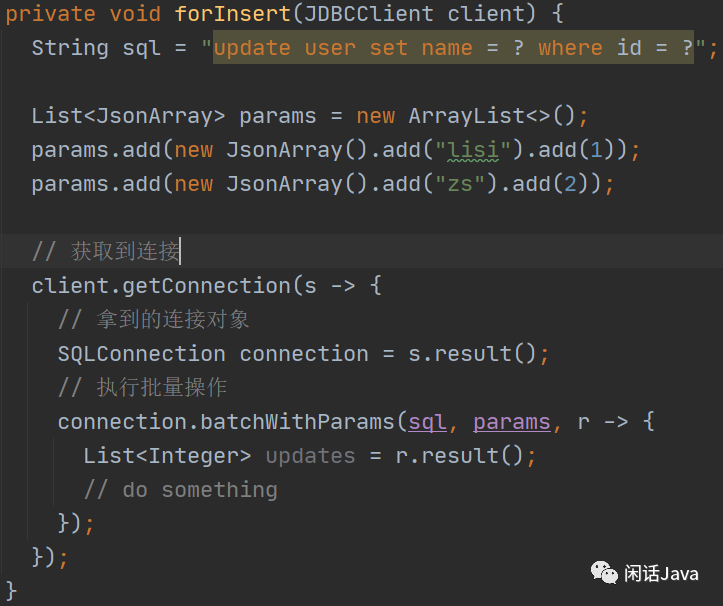
上面的例子中,会执行两次SQL,参数是List集合里的两个JsonArray元素。
批量执行的SQL,执行次数在可控范围
Vert.x提供了Fluent编程风格的API,就是说update方法后还可以继续update方法,直到最后一个操作执行完毕。如果有5个操作,那们就是5个update就可以了。这种方式虽然显得low,但也能解决问题。
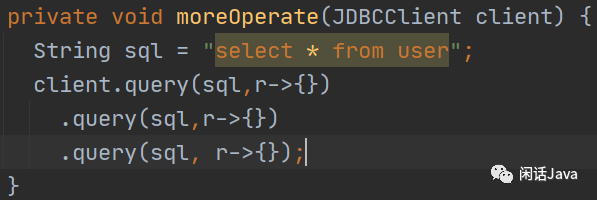
这种操作方式无法实现下一个操的条件是上一个操作的结果。所有的操作必须是没有依赖的,谁先执行都可以。
批量的SQL,下一个SQL依赖上一个SQL的结果
这是异步带来的问题,就是循环,且依赖的问题。因为异步响应结果是在回调里面的,不是同步的响应,因此简单的批量,你并不能通过一个for来解决。按照思路,就是在结果中再去封装结果,因为你不知道有多少层嵌套,所有这样是显然不可行的,那改如何解决呢?
可以通过rxjava,这里简单提供一种实现的思路,非常复杂。
1、引入rxjava的依赖
<dependency><groupId>io.vertx</groupId><artifactId>vertx-rx-java</artifactId><version>${vertx.version}</version></dependency>
2、核心执行程序
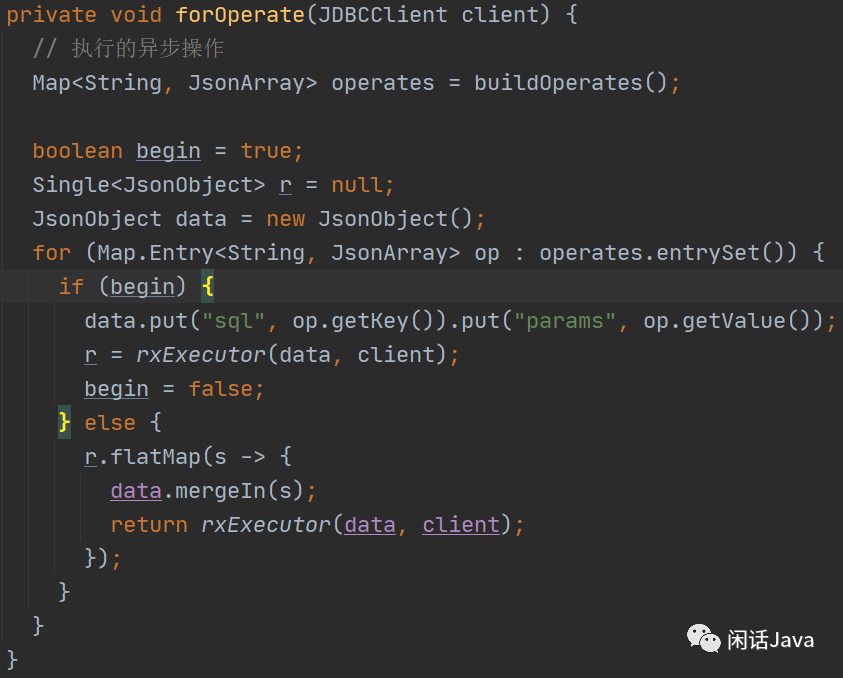
3、rxExecuter方法实现
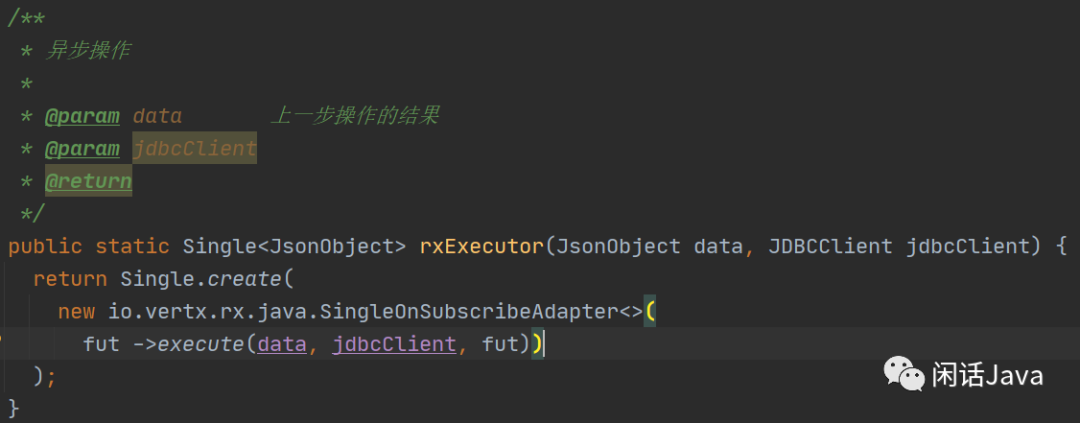
4、execute方法实现
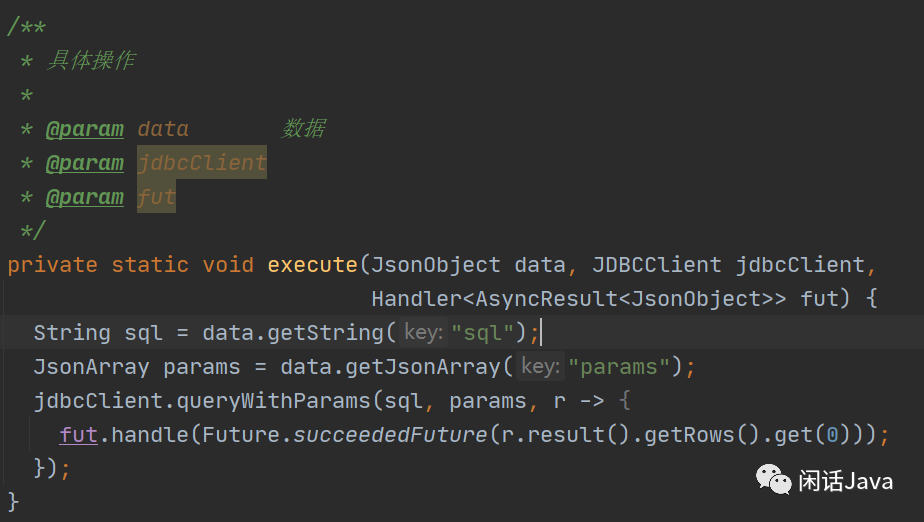
到这里,最为强大的循环就完事了,是不是比你想象的要复杂很多。没办法,想要循环异步的操作就要这么实现。
事务
数据库操作,事务是不可避免的,先来回顾下jdbc如何开启事务?
获取连接
设置不自动提交事务(setAutoCommit = false)
执行SQL操作
提交或者回滚事务
关闭资源
那么我们分析下上面的这几个步骤,在同步的编程模型下,每个步骤都很简单,几乎一行代码就搞定了。可是到了异步模型下,我们首先应该考虑的就是这个操作是不是一个耗时操作(这里简单认为通过网络连接的,就是耗时操作),如果是耗时操作,我们就需要对其进行异步的封装。
那么上面的5个步骤中,都需要和数据库通信,也就需要走网络,网络相比较CPU的处理速度那真是太慢了,因此肯定都是耗时操作。那也就意味着,这些都是异步的。
/*** 事务* <p>* 获取连接* 设置不自动提交事务(setAutoCommit = false)* 执行SQL操作* 提交或者回滚事务* 关闭资源** @param client*/private void tx(JDBCClient client) {client.getConnection(c->{if(c.succeeded()) {SQLConnection connection = c.result();// 关闭事务自动提交connection.setAutoCommit(false, a->{if(a.succeeded()) {// 执行SQLconnection.update("sql1", r1->{if(r1.succeeded()) {connection.update("sql2",r2->{if(r2.succeeded()) {// 提交事务connection.commit(o->{});} else {// 操作2执行失败,事务回滚connection.rollback(r->{});}});}else {// 操作1执行失败connection.rollback(b->{if(b.succeeded()) {// 回滚成功}});}});} else {// 开始事务失败}});} else {// 获取连接失败}});}
没有办法,这里就是这样,开启事务也就只能这么实现,着实非常麻烦。这里同样可以使用rx来降低开发难度。
总结
到这里,相信你对数据库的操作就已经很熟悉了。习惯了Mybatis或者JPA的你,是不是一时还不能接受。你是不是还在想着我该先创建个对象,然后将结果封装到对象里。
上面的想法是完全可以实现的,但是,用了很久的jdbc之后,我会感觉到,纯的jdbc未必不是个好的写法。我在一些公司的小的项目架构中,也会采用Spring+DbUtils的形式,在简单、灵活以及性能的方面也是提高了不少。
所以抛开技术实现不谈,还是要贴合业务需求。存在的即合理的。
The End
下期预告
我们系统中操作比较频繁的除了数据库,就属于Redis了,几乎所有的项目都离不开高性能的缓存服务器Redis。下一篇我来带大家看看Vert.x是如何和Redis进行交互的。