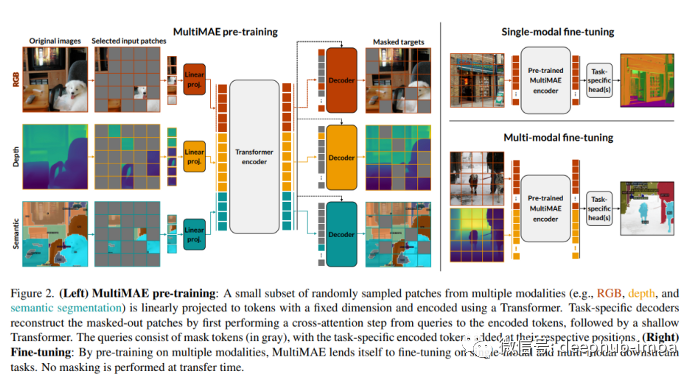
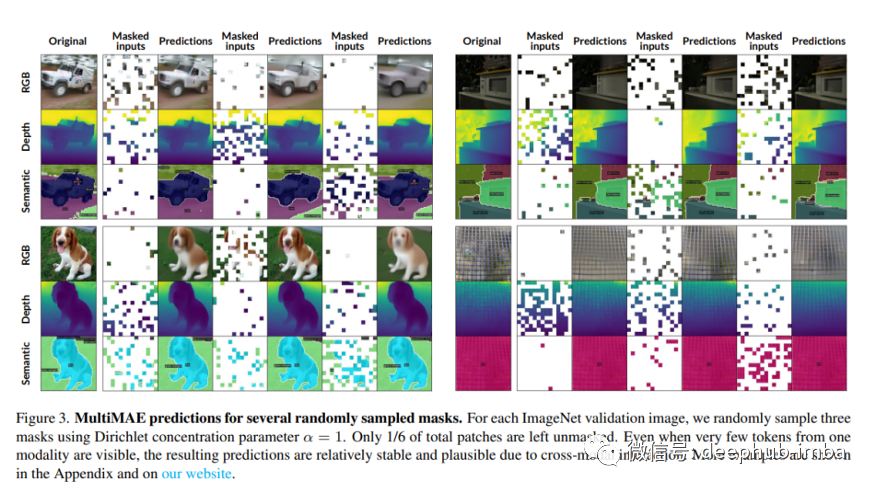
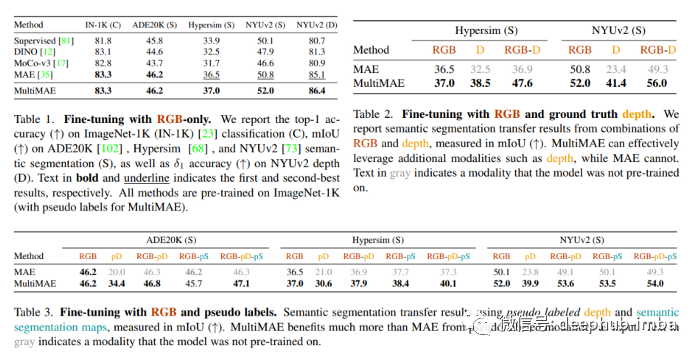
Multi-modal Multi-task Masked Autoencoder:一种简单、灵活且有效的 ViT 预训练策略数据派THU关注共 1195字,需浏览 3分钟 ·2022-05-14 17:56 来源:Deephub Imba本文约1000字,建议阅读4分钟本文介绍了一种简单、灵活且有效的Vit预训练策略。MAE是一种使用自监督预训练策略的ViT,通过遮蔽输入图像中的补丁,然后预测缺失区域进行子监督与训练。尽管该方法既简单又有效,但 MAE 预训练目标目前仅限于单一模态——RGB 图像——限制了在通常呈现多模态信息的实际场景中的应用和性能。在新论文 MultiMAE: Multi-modal Multi-task Masked Autoencoders 中,来自瑞士洛桑联邦理工学院 (EPFL) 的团队提出了 Multi-modal Multi-task Masked Autoencoders (MultiMAE),也是一种预训练策略,可以对掩码进行自动编码处理并执行多模态和多任务的训练。MultiMAE 使用伪标签进行训练,使该框架适用于任何 RGB 数据集。MultiMAE 的设计基于传统的 Masked Autoencoding,但在两个关键方面有所不同:1、除了 RGB 图像,它还可以选择接受输入中的附加模态信息(因此是“多模态”)2、其训练目标相应地包括 预测除 RGB 图像之外的多个输出(因此称为“多任务”)。从架构上看,MultiMAE 的编码器是一个 ViT,但每个额外的输入模态都有补丁的投影层和一个带有可学习的额外全局令牌嵌入,类似于 ViT 的类令牌。所以仅加载所需的输入投影并忽略所有其他投影的MultiMAE 预训练权重可以直接用于标准单模态 ViT。为了执行语义分割补丁投影,论文的作者用学习的 64 维的类嵌入替换每个类索引。并且仅对可见标记的随机子集进行编码,这样可以显著的加速计算和减少内存使用,并且使用了具有三种密集输入模态的 MultiMAE 多模态预训练。每个任务使用一个单独的解码器,因此解码器的计算随着任务的数量线性扩展,并且只增加了最小的成本。在他们的研究中,图像分类、语义分割和深度估计这三个任务上对 MultiMAE 进行了预训练,并在 ImageNet-1K 上进行伪标记,然后在 ImageNet、ADE20K、Taskonomy、Hypersim 和 NYUv2 数据集上进行微调。结果表明,当 只使用RGB 进行微调时,MultiMAE 保留了常规 MAE 的优势,并且它还可以利用深度等其他模态,例如使用伪标记深度或语义分割来提高性能。MultiMAE 预训练策略可以显著提高迁移性能。该项目的在 GitHub 上也公开了代码、预训练模型和交互式可视化。论文 MultiMAE: Multi-modal Multi-task Masked Autoencoders 公开资料汇总地址如下:https://multimae.epfl.ch/编辑:王菁校对:王欣 浏览 9点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 一种系统性能定位的简单策略喔家ArchiSelf0DeepBlur:一种简单有效的自然图像模糊方法AI算法与图像处理0预训练卷积超越预训练Transformer?机器学习算法工程师0ViT训练的全新baseline!机器学习实验室0ViT 训练的全新baseline机器学习与生成对抗网络0EasyCms简单灵活的 Java CMS简介JavaEasyCms使用最简单性能最高的框架,将cms系统简单到极致,灵活的栏目扩展,快速的构建普通网站生成的静态演示站(测试):www.j4cms.com用到的框架工具java,servletEasyCms简单灵活的 Java CMS简介Java EasyCms 使用最简单性能最高的框架,将cms系统简单到极致,灵活的栏目扩展,快速2022年,预训练何去何从?NLP从入门到放弃0GNN教程:与众不同的预训练模型!Datawhale0详解超强 ResNet 变体 NFNet(二):匹敌 ViT 性能的 JFT-4B 大规模预训练极市平台0点赞 评论 收藏 分享 手机扫一扫分享分享 举报