
以某乎为实战案例,教你用Python爬取手机App数据
1
前言
最近爬取的数据都是网页端,今天来教大家如何爬取手机端app数据(本文以ios苹果手机为例,其实安卓跟ios差不多)!
本文将以『某乎』为实战案例,手把手教你从配置到代码一步一步的爬取App数据!
2
配置抓包工具
1.安装软件
本文选择的抓包工具:Fiddler
具体的下载安装这里不详细赘述!(网上搜Fiddler安装,一大堆教程),本文以实战为例,就不再这里浪费时间了!
2.配置Fiddler
安装好之后,接下来就开始配置Fiddler工具(这里是关键,仔细阅读!)
配置Connections
打开Fiddler后,点击Tools->Options
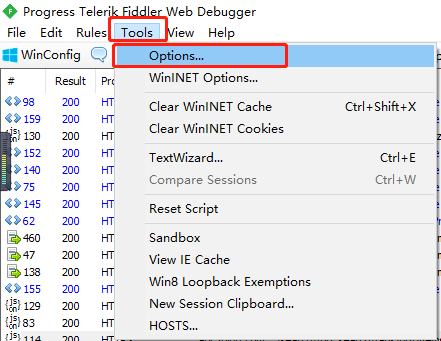
点击Connections

勾选上对应的选项
配置HTTPS
由于目前大部分APP都是https加密,包括本文实战『某乎』案例也是https加密,因此配置HTTPS,来抓取https数据包!

勾选上对应的选项
最后抓包工具Fiddler就配置好了
记得重启Fiddler!重启Fiddler!重启Fiddler!不然可能不生效
3
配置手机代理
1.设置代理
准备工作
首先看一下安装Fiddler主机ip(电脑和手机必须处于同一局域网)
查看ip命令
window:ipconfigmac或linux:ifconfig

开始配置
目标代理主机信息
ip:192.168.31.195
端口:8888
在wifi无线网处进去,点击配置代理
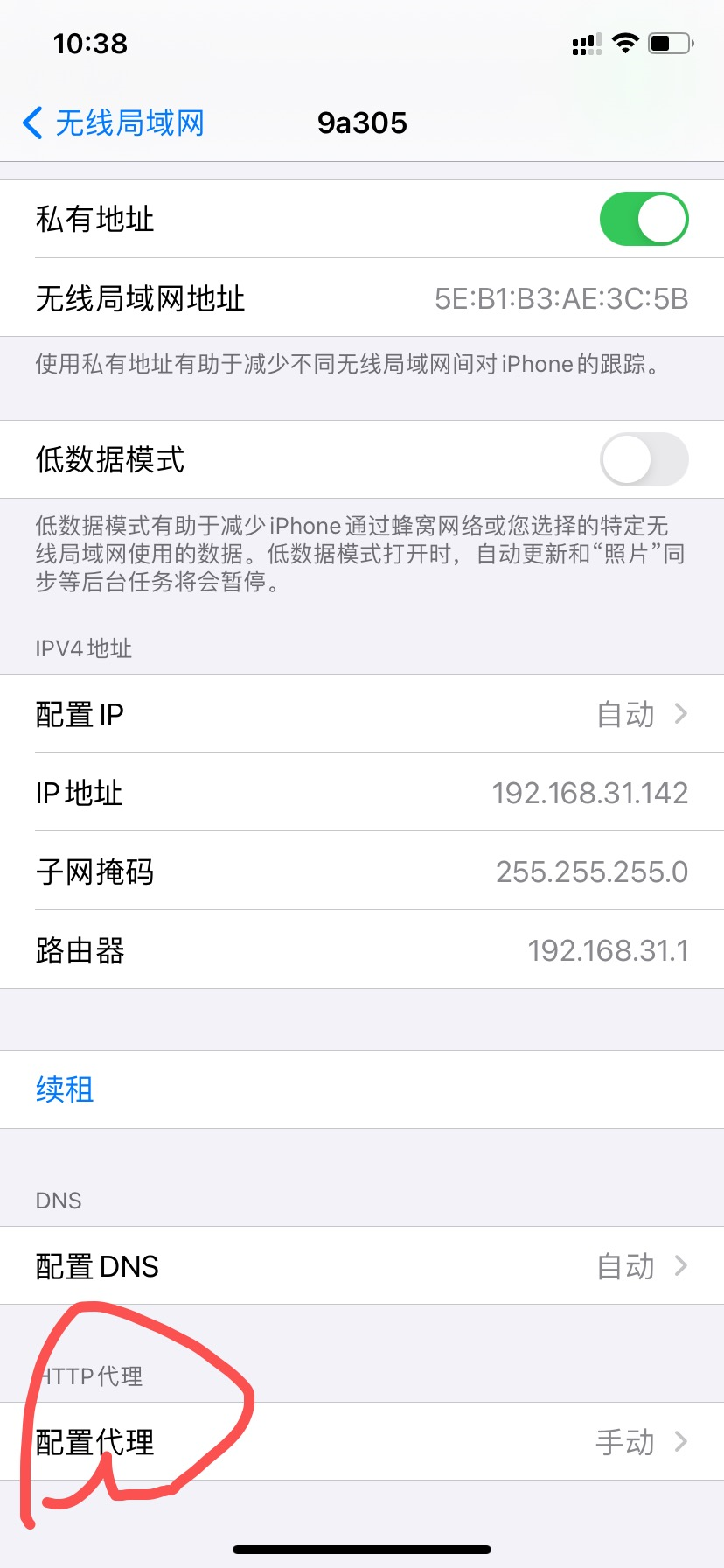
填写好相关代理信息
2.安装证书
在浏览器输入:
http://192.168.31.195:8888点击下载证书后,下面就开始安装(看图操作)
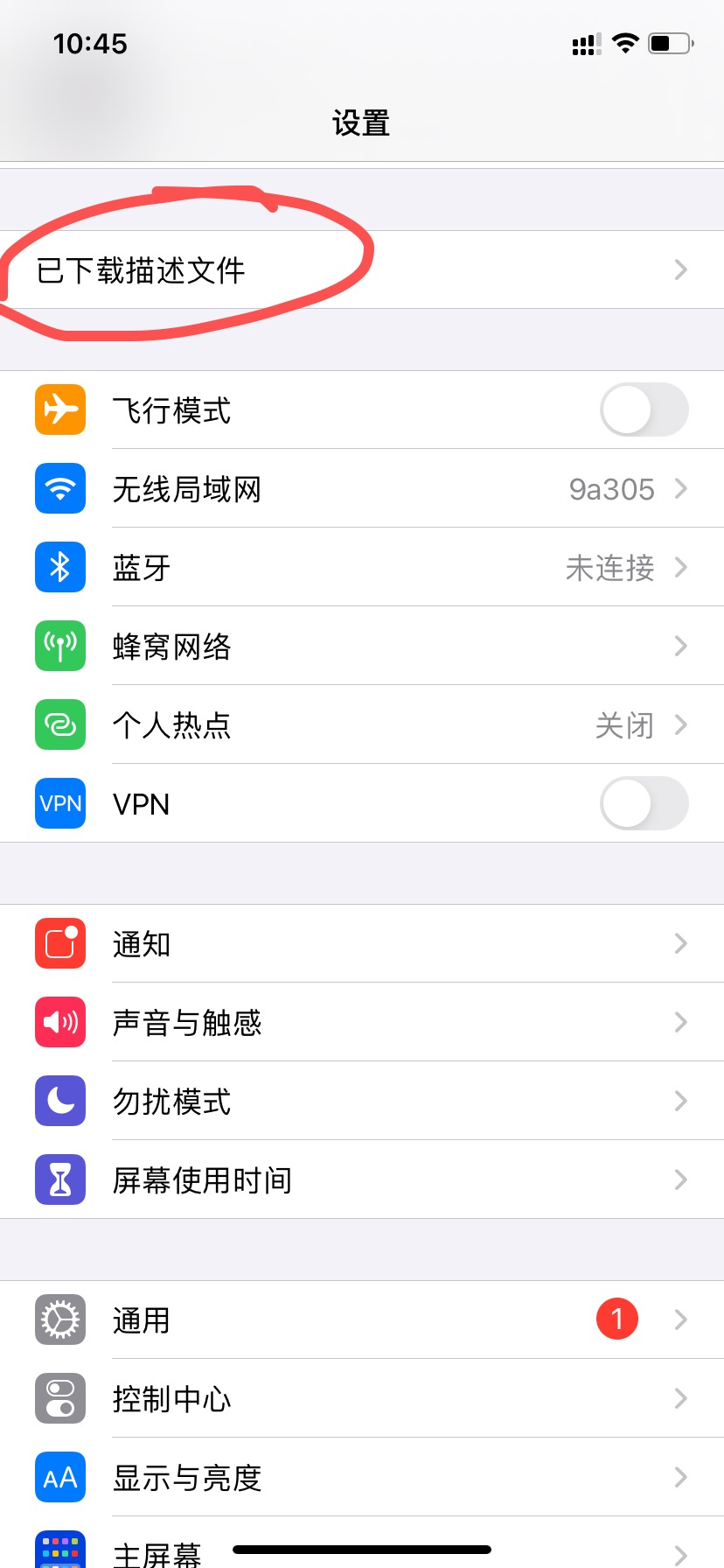
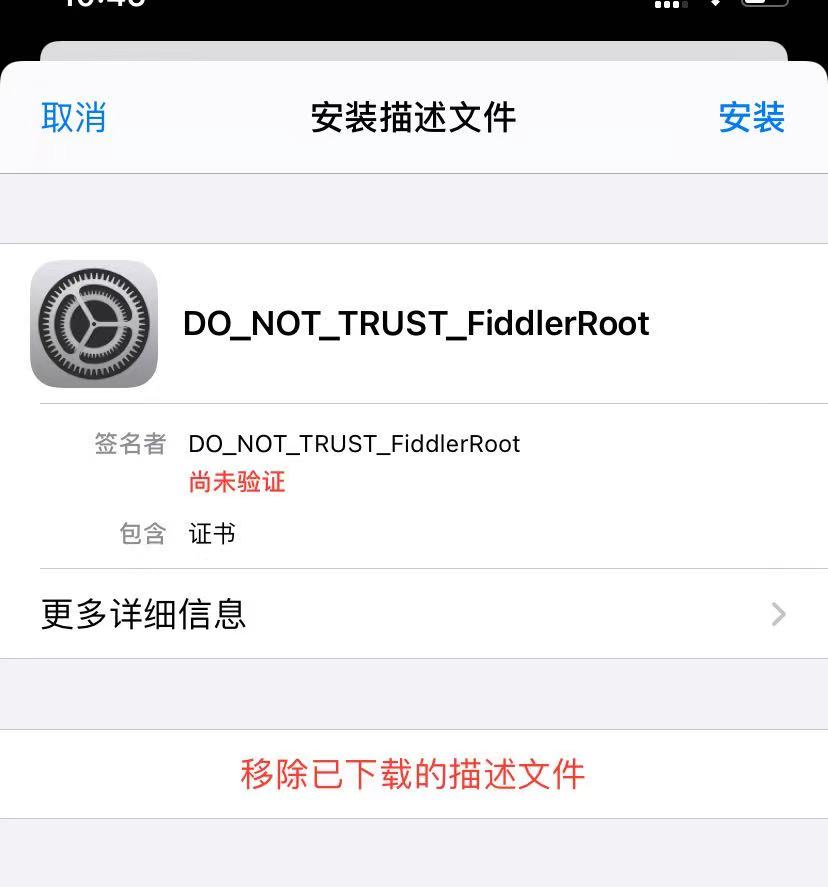
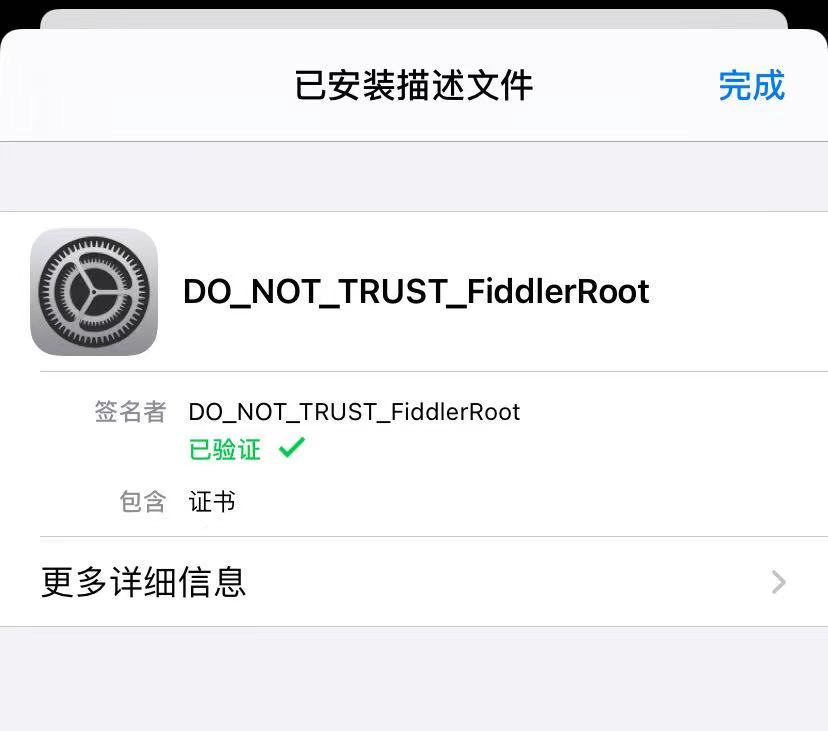
ok,这样手机端就配置完成,下面开始抓取数据!!!
4
抓取数据
1.打开某乎app

2.查看数据包列表
打开app之后,Fiddler就已经抓取到数据了

这里可以看到app发送和接收了哪些数据包
为了更加精准定位到某乎(只看目标的数据包),添加一个过滤条件
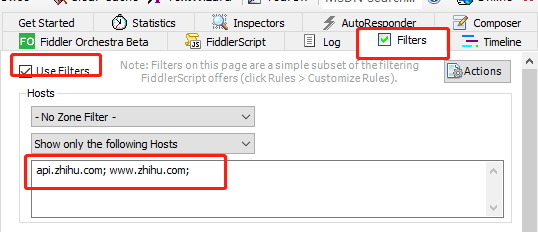
这样我们获取的数据包列表就都是过滤条件内的目标网址

3.查找数据包
比如点击热榜
对应的https加密数据包如下:
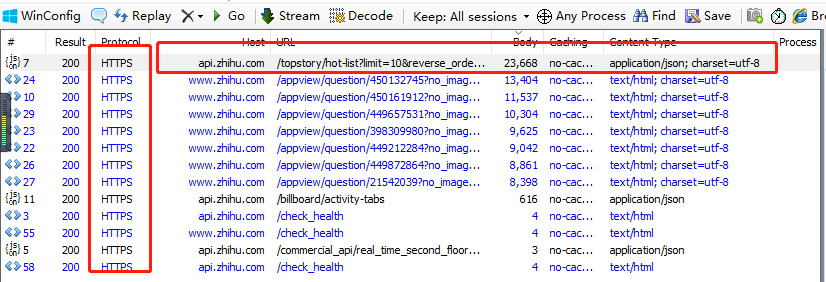
数据包中的数据如下:
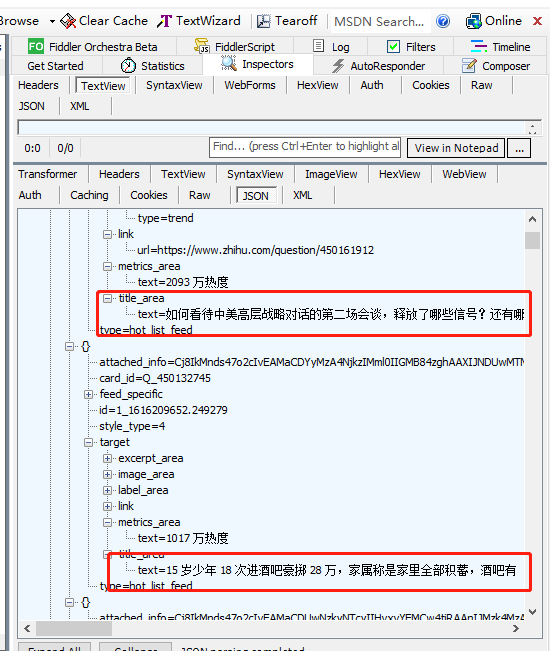
提取出url链接
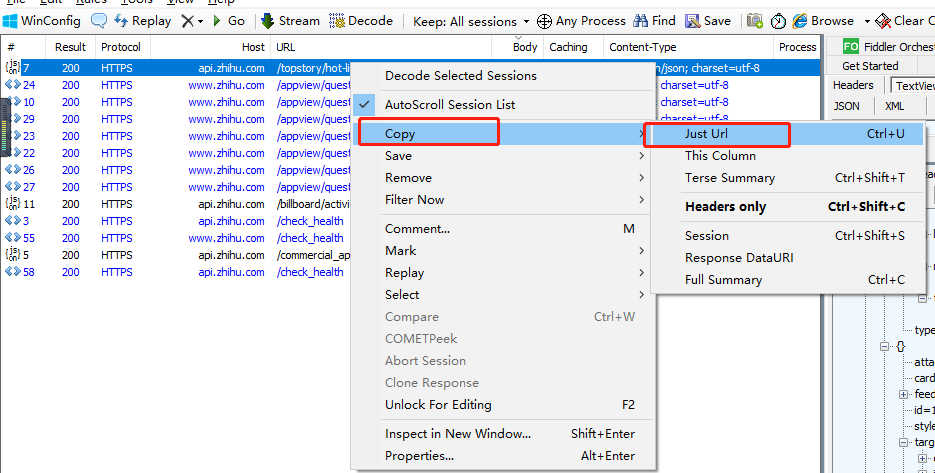
https://api.zhihu.com/topstory/hot-list?limit=10&reverse_order=0拿到url之后,接着开始编程爬取保存数据。
4.编写爬虫程序
# -*- coding: utf-8 -*-## 李运辰 2021-3-20import requestsimport jsonheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0',}url = "https://api.zhihu.com/topstory/hot-list?limit=10&reverse_order=0"res = requests.get(url, headers=headers)res.encoding = 'utf-8's = json.loads(res.text)list = s['data']for i in list:title = i['target']['title']print(title)

ok这样就可以将数据获取下来!
5
总结
1.配置抓包工具Fiddler(重点)。
2.ios苹果手机配置证书和设置代理(安卓手机也类似)。
3.简单使用Fiddler(过滤数据包、查看数据包等)。
4.本文以某户为实战,实现了python爬取手机app数据(详细教程,推荐收藏)。
近期热门文章