
七月论文审稿GPT第2.5和第3版:分别微调GPT3.5、Llama2 13B以扩...
 文末 《 大模型项目开发线上营 》开抢↓↓↓
文末 《 大模型项目开发线上营 》开抢↓↓↓
前言
自去年7月份我带队成立大模型项目团队以来,我司至今已有5个项目组:
-
第一个项目组的AIGC模特生成系统已经上线在七月官网
-
第二项目组的论文审稿GPT则将在今年3 4月份对外上线发布
-
第三项目组的RAG知识库问答第1版则在春节之前已就绪
-
第四、第五项目组的大模型机器人、Agent则正在迭代中
所有项目均为会对外上线发布的商用项目,而论文审稿GPT至今在过去的半年已经迭代两个版本,其中第二版的效果甚至超过了GPT4(详见《七月论文审稿GPT第2版:用一万多条paper-review数据集微调LLaMA2最终反超GPT4》,且本文所用的模型评估方法均用的该文第六部分所述的评估 ),为了持续累积与原始GPT4的优势,我们如今正在迭代第2.5版本:包括对GPT3.5 turbo 16K的微调以及llama2 13B的微调,本文也因此而成
第一部分
第2.5版之微调GPT3.5 Tubor 16K
我们微调第一版的时候,曾经考虑过微调ChatGPT,不过其开放的微调接口的上下文长度不够大部分论文的长度(截止到23年10月底暂只有4K),故当时没来得及,好在23年11.6日,OpenAI在其举办的首届开发者大会上,宣布开放GPT3.5 16K的微调接口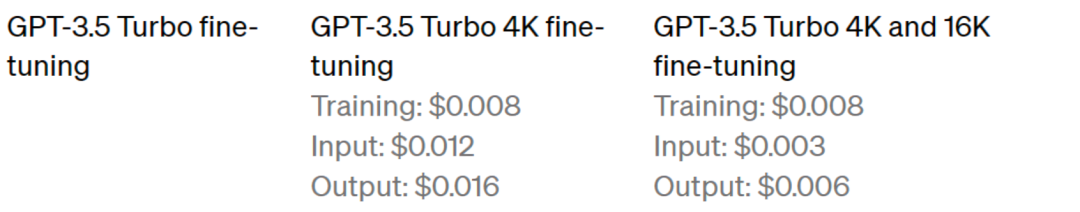
因此,我们在第2.5版便可以微调ChatGPT了,即我司正在尝试用我们自己爬取一万多条的paper-review数据集去微调GPT3.5 16k,最终让它们大乱斗,看哪个是最强王者
不过,考虑到可能存在的数据泄露给OpenAI的风险,故我们打算先用一小部分的数据 微调试下,看能否把这条路径走通,以及看下胜率对比
-
如果能超过咱们微调的开源模型,那ChatGPT确实强
-
如果没超过,则再上全量
1.1 模型训练:GPT3.5 Tubor 16K的微调
1.1.1 微调GPT3.5的前期调研:费用、微调流程、格式转换等
首先,计算一下微调GPT所需的费用 由于我司爬取的15566条paper-review数据集的token数量为:118689950 根据OpenAI微调gpt3.5 turbo的定价策略(Pricing)

-
可知,全量样本Traning阶段预计要花费的费用为(按2个epoch):118689950个token × 2个epoch × 0.008 × 汇率7.18 = 13635元
2. 其次,这是微调的页面:https://platform.openai.com/finetune 此外,这是OpenAI官网上关于微调的教程:https://platform.openai.com/docs/guides/fine-tuning/fine-tuning-examples
3. 接着,根据OpenAI微调教程给的提示 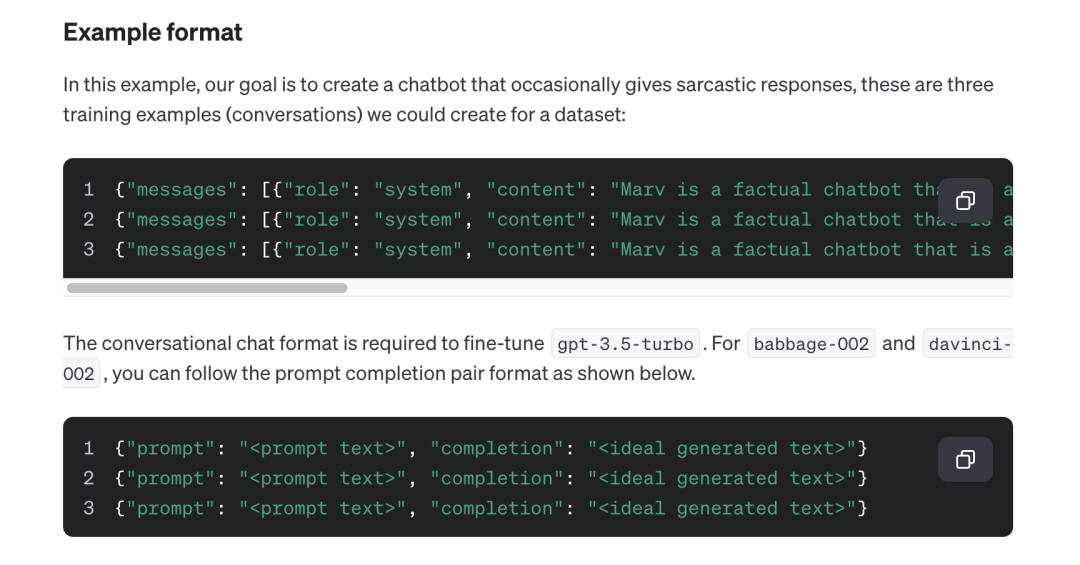
把我们自己爬的数据

转成做成chatml的格式,即 {"messages": [{"role": "system", "content": "xxx"}, {"role": "user", "content": "xxx"}, {"role": "assistant", "content": "zzz"}]}
从而变成如下适应「gpt3.5 16k微调之用」的paper-review数据集

为了方便大家一目了然,我再把转换前后的样式贴出来 对比下 
4. 在微调页面上传自己的数据 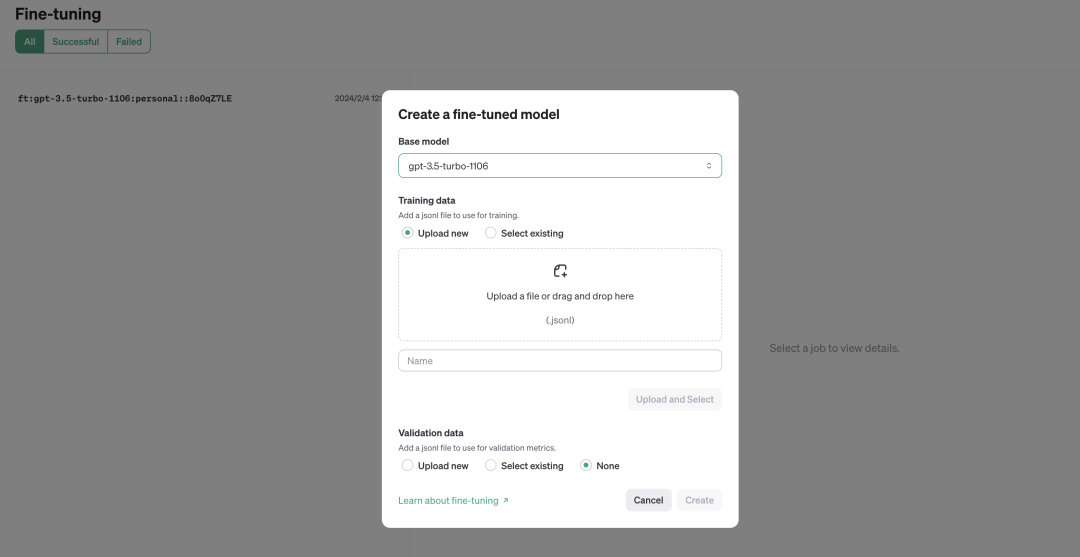
1.1.2 先后用150多条、1500多条、15000多条数据微调GPT3.5 Tubor 16K
为了先验证一下微调这个模式,故我们先用了156条paper-review数据集去微调gpt3.5 16k,然后跑完之后,我还和项目组的同事打趣说,搞不好我们是国内第一批微调gpt3.5 16k的呢,毕竟高质量的长文本数据非常稀缺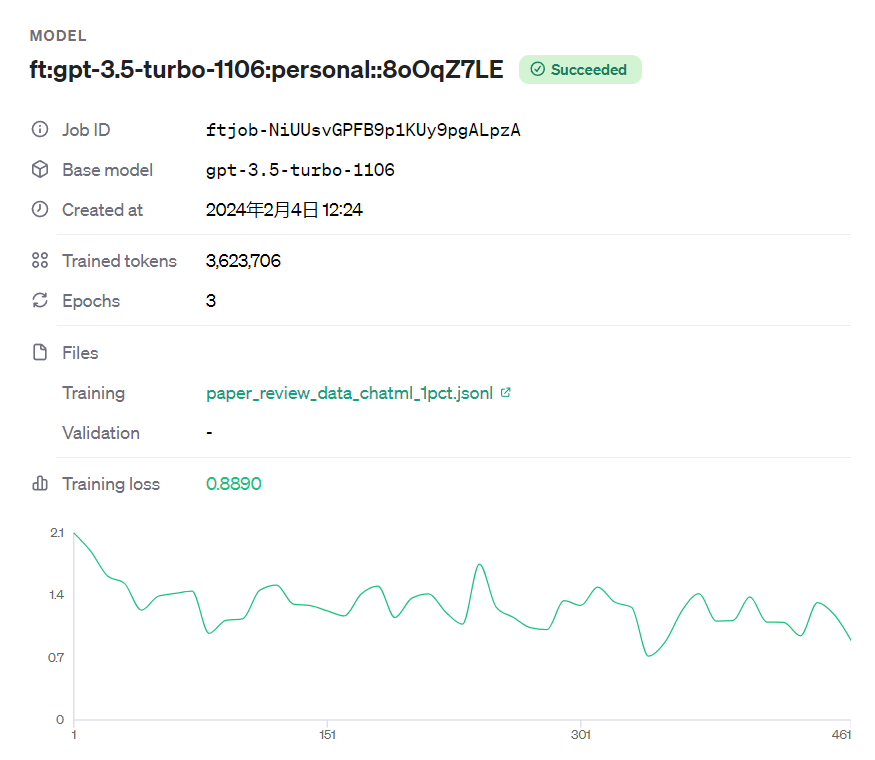 效果如何呢,我们先随机试一篇训练集之外的论文,做个验证,至于专业全面的评估下节详述
效果如何呢,我们先随机试一篇训练集之外的论文,做个验证,至于专业全面的评估下节详述
第二项目组的文弱同学用传「七月大模型线上营」群里的10pct那个数据集的倒数第二行的input(因为上面用于微调的156条数据只用了群里10%的数据,所以后面的这个input数据可以做验证集),分别让gpt3.5、微调过的gpt3.5对该input进行审稿意见的输出,且对比原始的人工审稿意见
这三个输出按顺序如下从左至右展示
1.2 模型评估:对通过156条数据微调后的gpt3.5 16K的效果评估
1.2.1 ft后的gpt3.5效果超过不微调的gpt3.5和GPT4
如下图左侧所示,仅才156条数据微调之后的gpt3.5的效果远远超过不微调的gpt3.5,且如果下图右侧所示,也超过了GPT4(对GPT4的胜率达到61.4%)
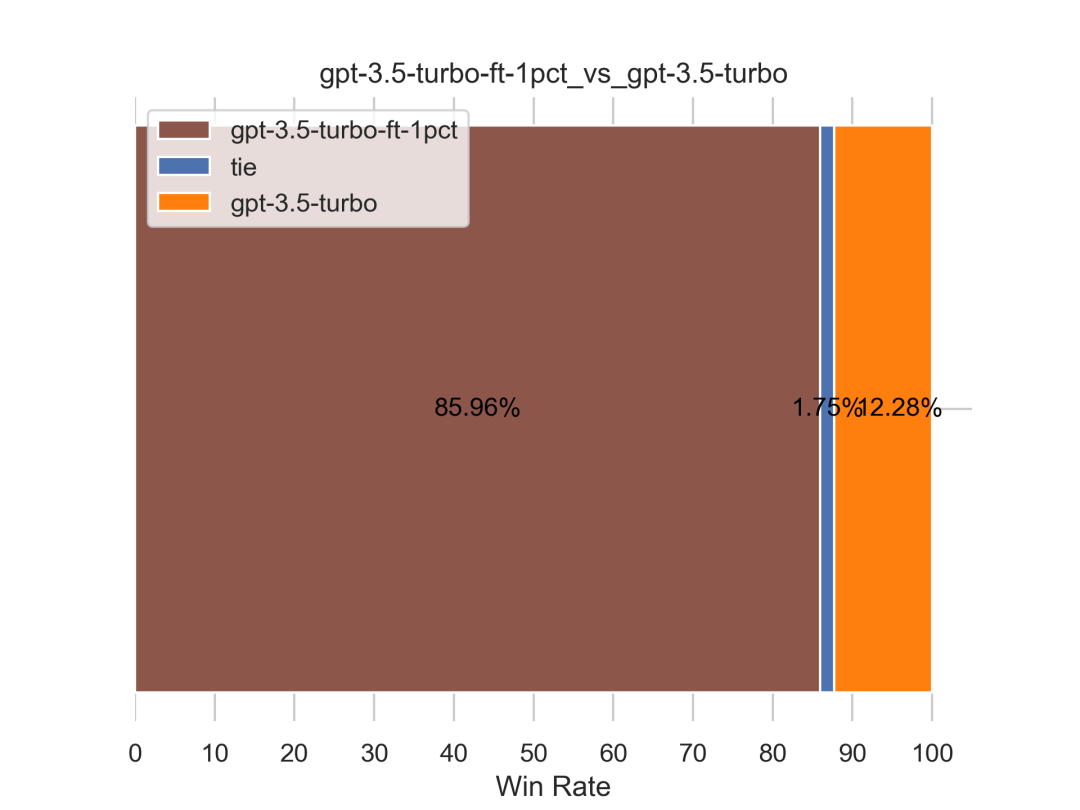
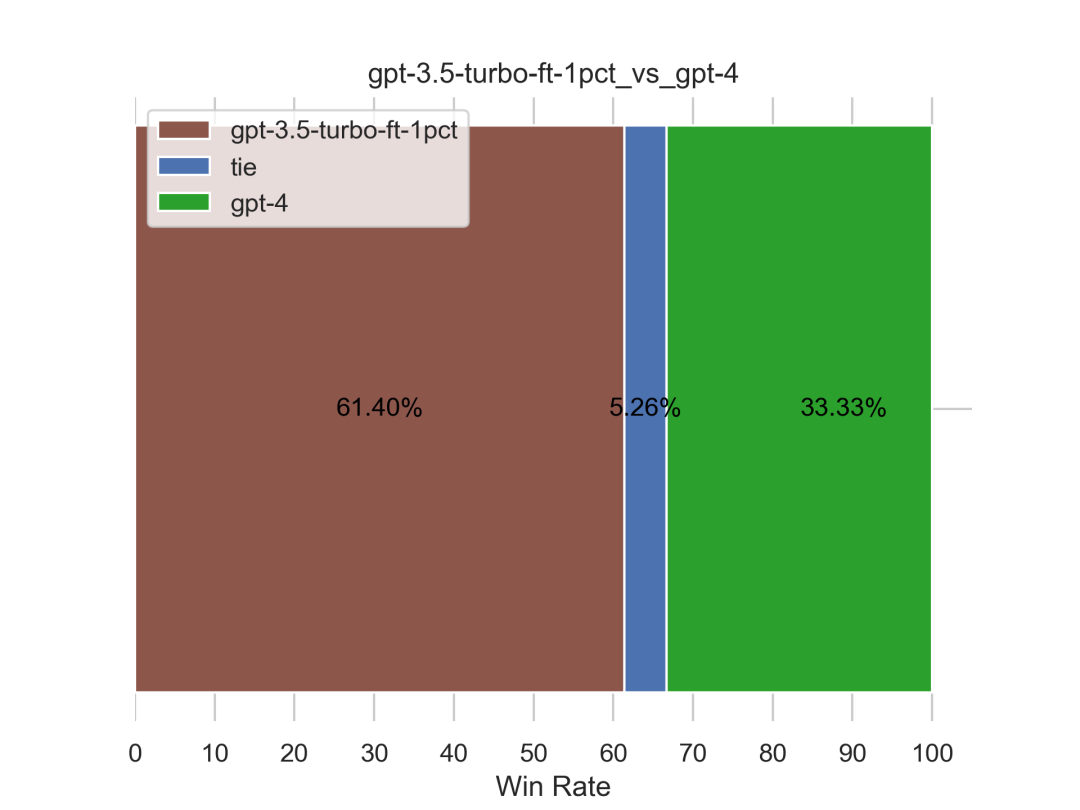
当然,上述的表现表面上是证明了微调的威力,其实是证明了我司爬取的这份超高质量paper-review数据的威力
1.2.2 ft后的gpt3.5依然不敌我司通过longqlora微调后的llama2
如下图所示,ft后的gpt3.5虽然变强了(通过我司爬取的极高质量的paper-review数据集微调后接连超过不微调的gpt3.5和gpt4),但仍不敌我司通过longqlora微调后的llama2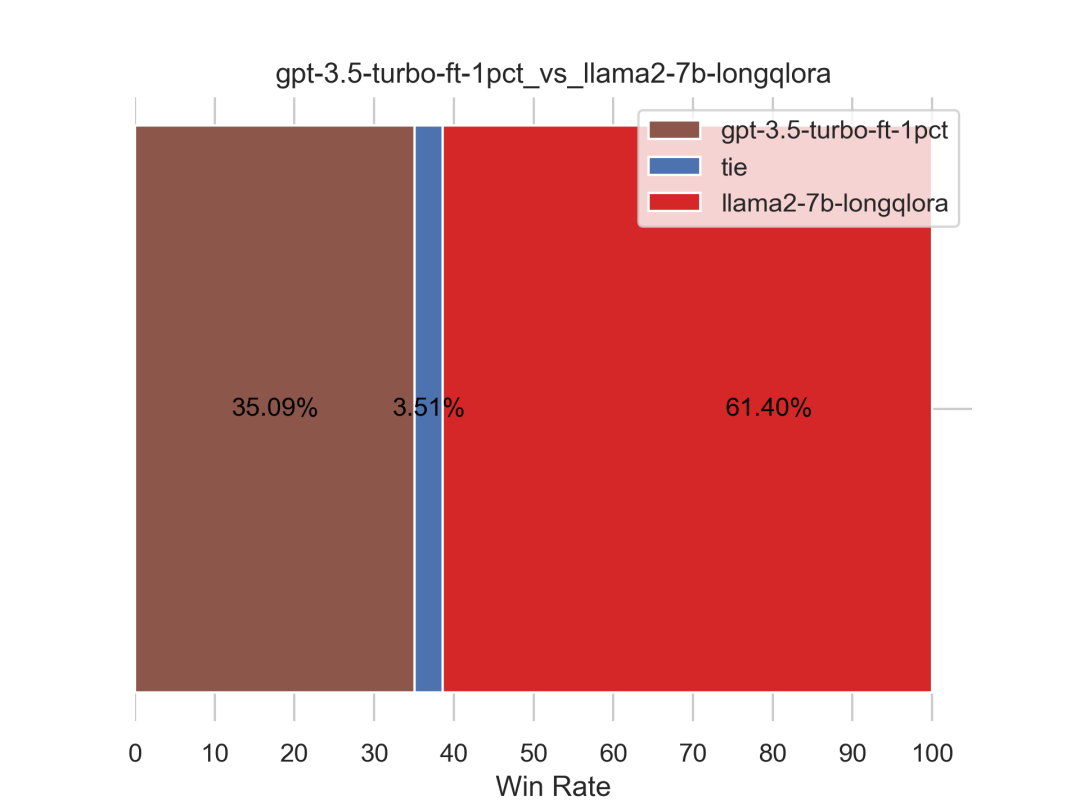
你可能会说,那为何不用全部的一万多条数据微调gpt3.5 16K呢?原因在于
-
一方面 如上文所说,尚不确定有无数据泄露给OpenAI的风险(毕竟这一万多条的paper-review数据集是目前该审稿项目中最大的资产,不敢轻易上传云端)
- 另一方面 毕竟也是一万多块,故之后再尝试
第二部分
第3版之微调Llama2 13b chat
在我司这个论文审稿场景下,对于13B模型的微调,首选还是微调llama 13B(模型地址: Llama-2-13b-chat-hf)
其对卡的要求:双48g的卡或者单卡80g,即13b的话双A40用longqlora差不多,所以本次微调方法继续用之前微调过llama2 7B的longqlora(当然,longlora也行,不过 考虑到尽可能节省资源,故还是longqlora了)
2.1 模型训练:LongQLora微调Llama2 13b chat
2.1.1 资源依赖与环境配置
以下是所需的资源需求
-
Linux系统
-
支持cuda11.7
-
2张A40(即显存48G+的Ampere架构显卡)
-
可访问HuggingFace/Python官方源(操作前确认已开启)
-
至少120GB的空余硬盘空间
接下来,如下配置环境
# 训练代码基于LongQLoRA论文的源码进行修改,完整代码见七月在线的课程cd /path/to/LongQLoRA
# 创建虚拟环境conda create -n longqlora python=3.9 pip
# 配置虚拟环境## 单独安装pytorchpip install torch==1.13.0+cu117 torchvision==0.14.0+cu117 torchaudio==0.13.0 --extra-index-url https://download.pytorch.org/whl/cu117 -i https://pypi.org/simple## 单独安装flash attentionpip install flash_attn -i https://pypi.org/simple## 安装requirementspip install -r requirements.txt -i https://pypi.org/simple

-
安装flash attention的最后阶段会需要进行联网编译,如果无法有效访问相关网络可能会导致编译失败
requirements中包含对deepspeed的安装,使用非python官方源安装的deepspeed可能会出现必要文件丢失或加载不到相关驱动的问题,导致无法正常进行多卡训练(时点为2024年2月初)
accelerate==0.21.0transformers==4.31.0peft==0.4.0bitsandbytes==0.39.0logurunumpypandastqdmdeepspeed==0.9.5tensorboardsentencepiecetransformers_stream_generatortiktokeneinops# torch==1.13.0openpyxlhttpx# flash_attn==2.3.3joblib==1.2.0scikit_learn==0.24.2
2.1.2 前期准备: 数据集与模型文件下载
-
创建输出目录
2. 放置数据集 
3. 下载模型文件 安装git-lfs
# 安装git-lfscurl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bashsudo apt-get install git-lfs
# 激活git-lfsgit lfs install
获取Llama-2-13b-chat-hf模型文件
# 进入用于存储模型文件的目录cd /path/to/models_dir
# 获取Llama-2-13b-chat-hfgit lfs clone https://huggingface.co/NousResearch/Llama-2-13b-chat-hf
2.1.3 定义传参
-
修改yaml文件
路径位于“/path/to/LongQLoRA/train_args/llama2-13b-chat-sft-bf16.yaml”,完整配置见七月在线的课程
| 相关主要参数说明 |
|
| 参数 |
释义 |
| output_dir |
训练输出(日志、权重文件等)目录,即创建的输出目录外加自定义的文件名 |
| model_name_or_path |
用于训练的模型文件目录,即获取的模型文件路径 |
| train_file |
训练所用数据路径,即放置数据集的路径。 |
| deepspeed |
deepspeed参数路径,即LongQLoRA目录下的“train_args/deepspeed/deepspeed_config_s2_bf16.json” |
| sft |
是否是SFT训练模式 |
| use_flash_attn |
是否使用flash attention、attention |
| num_train_epochs |
训练轮次 |
| per_device_train_batch_size |
每个设备的batch_size |
| gradient_accumulation_steps |
梯度累计数 |
| max_seq_length |
数据截断长度 |
| model_max_length |
模型所支持的最大长度,即本次训练所要扩展的目标长度 |
| learning_rate |
学习率 |
| logging_steps |
打印频率,每logging_steps步打印1次 |
| save_steps |
权重存储频率,每save_steps步保存1次 |
| save_total_limit |
权重存储数量上限,超出该上限时自动删除早期存储的权重 |
| lr_scheduler_type |
学习率调度策略 |
| warmup_steps |
warmup步数 |
| lora_rank |
lora秩的大小 |
| lora_alpha |
lora的缩放尺度 |
| lora_dropout |
lora的dropout概率 |
| gradient_checkpointing |
是否开启gradient_checkpointing |
| optim |
所选用的优化器 |
| bf16 |
是否开启bf16训练 |
| report_to |
输出的日志形式 |
| dataloader_num_workers |
读取数据所用线程数,0为不开启多线程 |
| save_strategy |
保存策略,steps为按步数进行保存、epochs为按轮次进行保存 |
| weight_decay |
权重衰减值 |
| max_grad_norm |
梯度裁剪阈值 |
| remove_unused_columns |
是否删除数据集中的无关列 |
-
修改bash文件
注意,这里和用修改后的longqlora代码微调llama2 7B不一样,由于本次咱们是用的双卡微调llama2 13B( 算是通过DS并行训练 ),所以我们需要加个命令: 要 --num_gpus=2
最终,路径位于“/path/to/LongQLoRA/ run_train_sft_13b_bf16 .sh”,该文件如下所示
export CUDA_LAUNCH_BLOCKING=1deepspeed --num_gpus=2 train.py --train_args_file /root/autodl-tmp/LongQLoRA/train_args/llama2-13b-chat-sft-bf16.yaml
- 其中--train_args_file,即指训练所用yaml文件的路径你可以对比下之前微调llama2 7B的配置
-
export CUDA_LAUNCH_BLOCKING=1
-
deepspeed train.py --train_args_file /path/to/LongQLoRA/train_args/llama2-7b-chat-sft-bf16.yaml
2.1.4 运行训练
# 进入LongQLoRA源码目录cd /path/to/LongQLoRA
# 启动bash文件进行训练bash run_train_sft_bf16.sh
2.2 模型评估:llama2 13B longqlora再次接连超过GPT3.5和GPT4
为了全面评估我司审稿模型第3版13B,对GPT4在论文审稿方面的胜率,和文弱做了一系列实验
-
13B PK GPT4-0125,1106 0125依次裁判
-
13B PK GPT4-1106,1106 0125依次裁判
2.2.1 不同裁判下,llama2 13B longqlora与GPT4-0125的PK
还是用的和第二版一样的评估方法,只考察命中数,接连超过GPT3.5、GPT4
不过有一点要强调下,考虑到如此篇文章《七月论文审稿GPT第2版:用一万多条paper-review数据集微调LLaMA2 7B最终反超GPT4》的6.3节开头所说
“在同在一个季度的工作 才互相PK,且首选当季度最强的裁判去评判”

故,接下来,GPT3.5之外,面对GPT4时,PK的均是GPT4-0125的生成结果
-
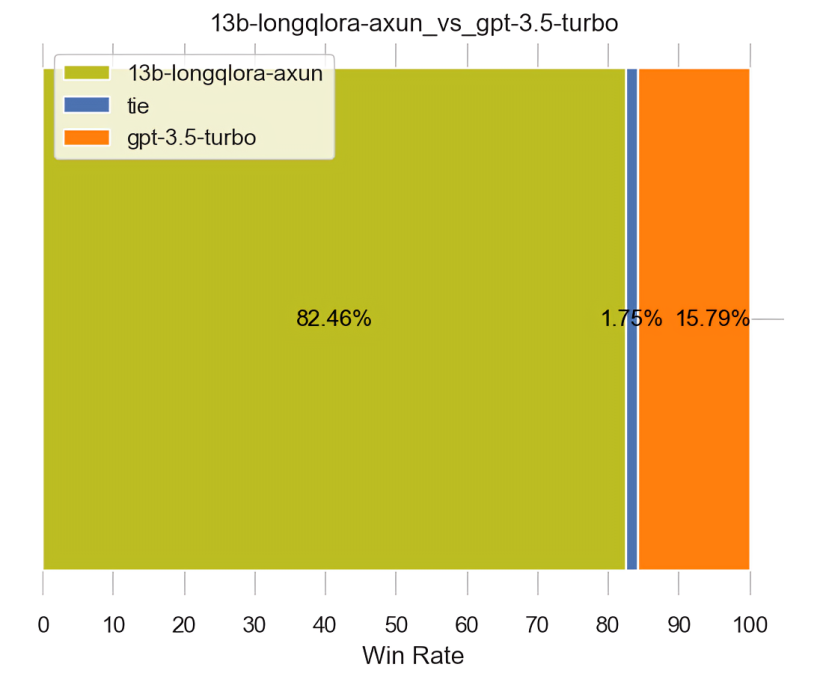
下图无论是左侧还是右侧,都是用的GPT4-1106做的裁判
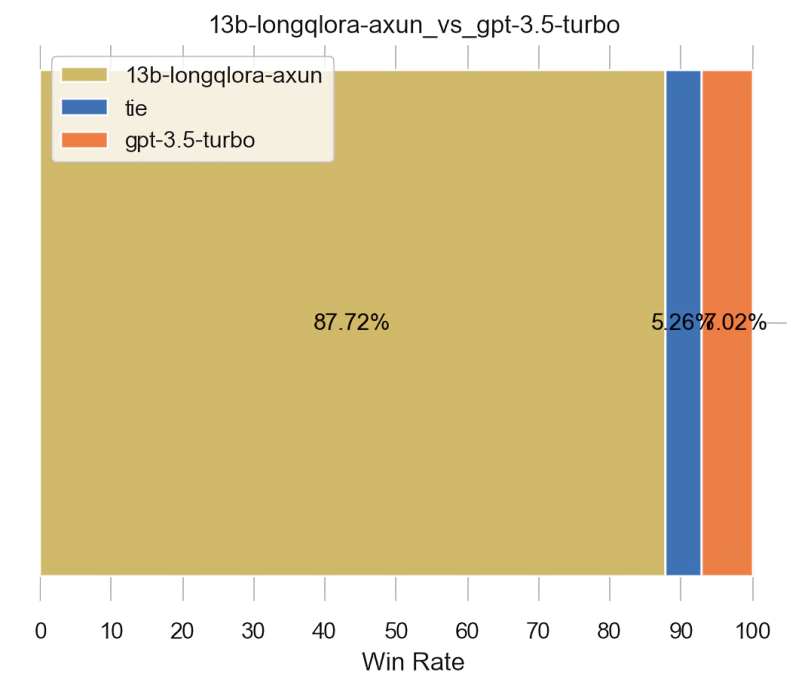
-
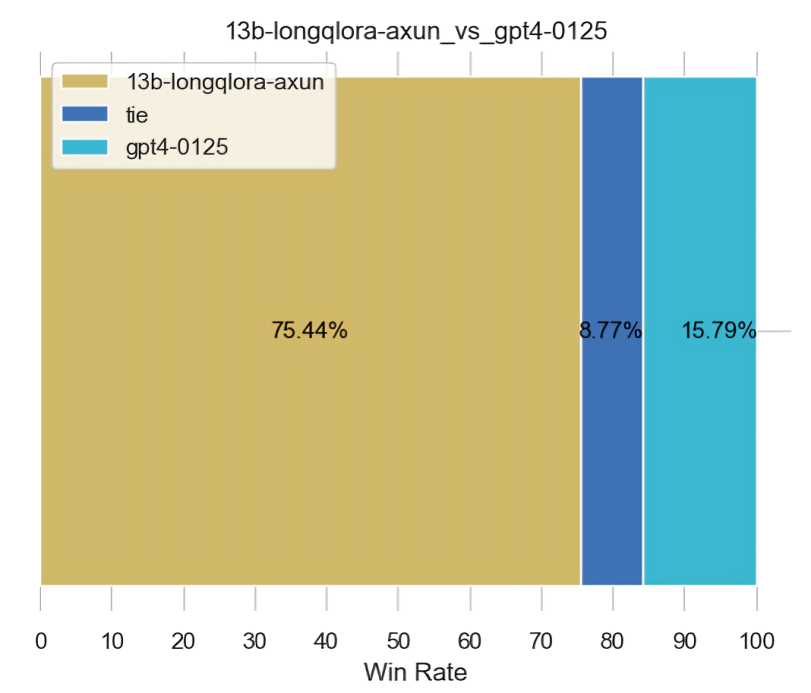
而下图无论是左侧还是右侧,都是用的GPT4-0125做的裁判
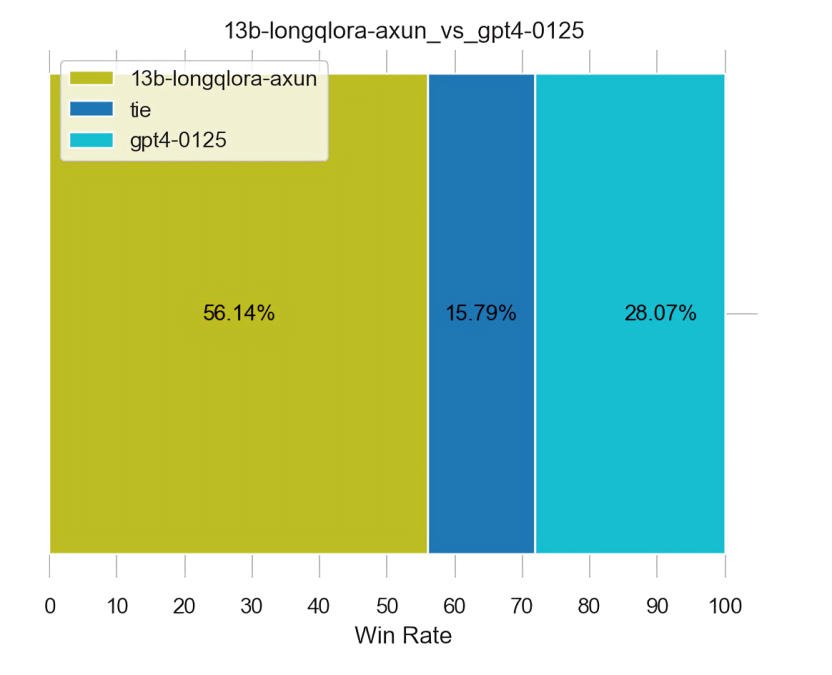
上面有个问题是,为何仅仅只是裁判不同,但差距那么大呢?原因在于GPT4-0125做裁判时,会对GPT4-0125生成的结果有偏心
举个例子,对于同一篇文章的同一个review,如下图所示

蓝框:0125判阿荀的时候,把A7-B4的相似度判定不足为7,所以蓝框内没有A7-B4
绿框:0125判0125的时候,把A4-B4的相似度判断为7,但实际上 这两项的相似性如果按照1106的标准的话,不足为7
啥意思呢,就是0125当裁判的时候,对阿荀的生成结果判定的较严,对0125自己的生成结果判定的较松
2.2.2 llama2 13B与GPT4-1106、llama2 7B longqlora的对比
为了验证,GPT4-0125做裁判时,是不是更倾向GPT4本身生成的结果,故我们再次做了一个实验 下图无论左侧还是右侧,都是13B对比GPT4-1106的生成结果,但下图左侧是GPT4-1106做裁判,下图右侧是GPT4-0125做裁判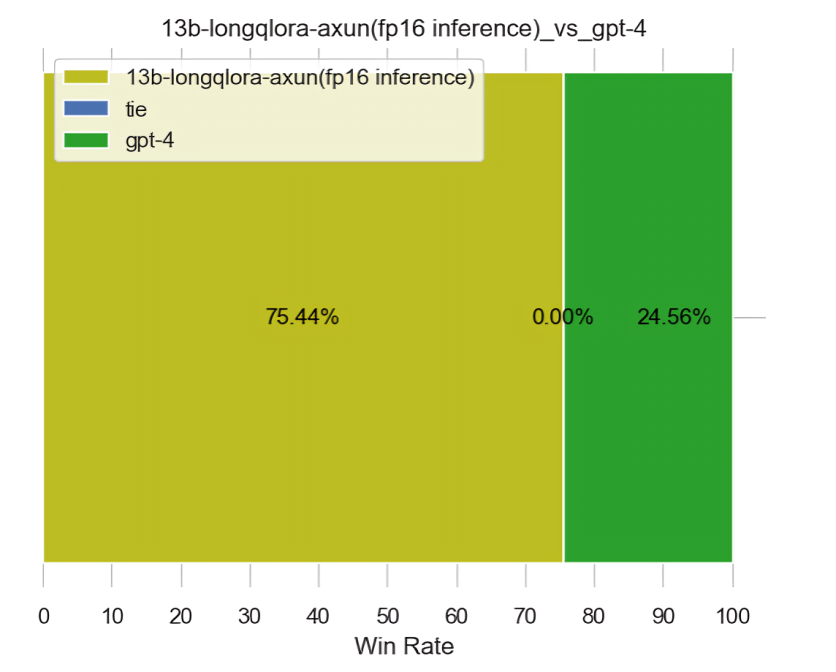
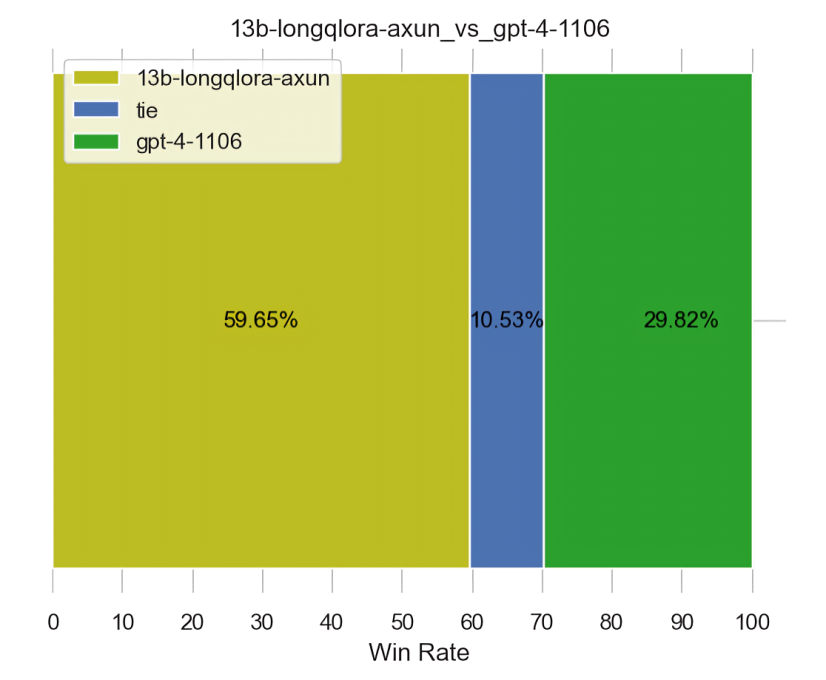
对于上述这个结果,我再引用下第二版《 七月论文审稿GPT第2版:用一万多条paper-review数据集微调LLaMA2 7B最终反超GPT4 》的这个结果:llama2 7B longqlora PK GPT4-1106(且GPT4-1106做裁判)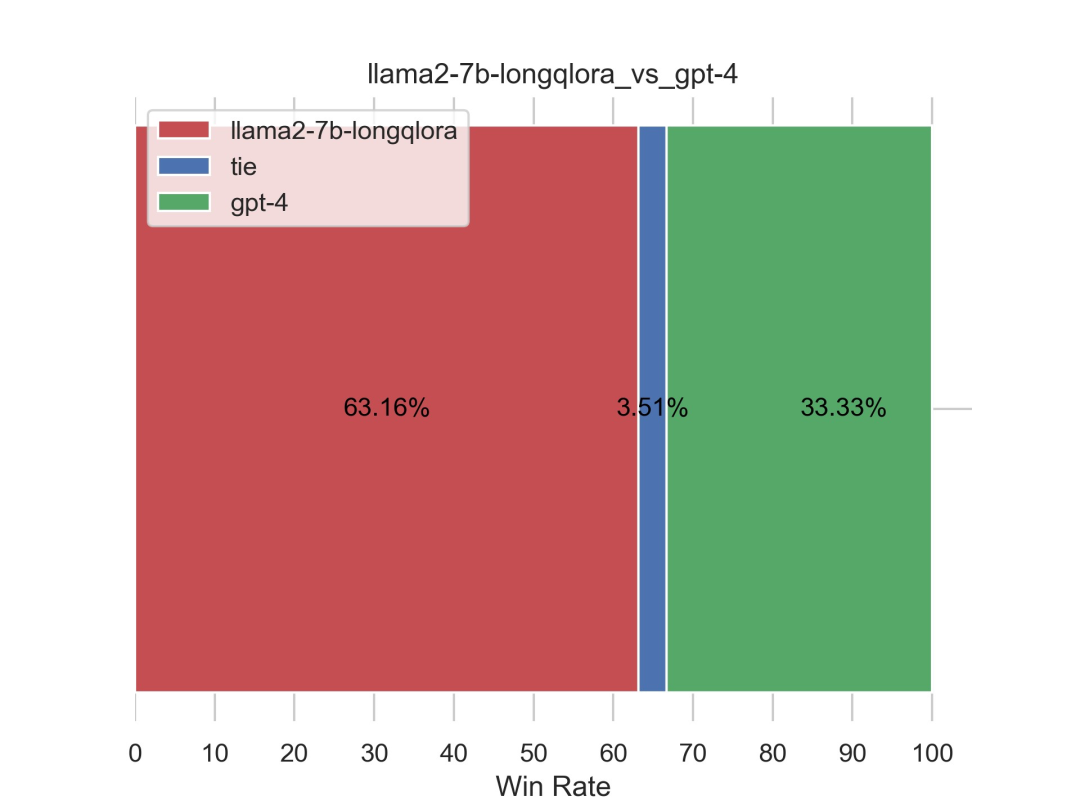
你能看出什么端倪不(你是不想说,GPT4-0125不太适合做裁判?)创作、修订、完善记录
- 第一阶段 第2.5版之微调GPT3.5 Tubor 16K 2.3日,新增一节的内容,即 1.1.1 微调GPT3.5的前期调研:费用、微调流程等
- 2.4日,新增一节,即 1.1.2 先后用150多条、1500多条、15000多条数据微调GPT3.5 Tubor 16K
- 2.5日,新增一节,即 1.2 对通过156条数据微调后的gpt3.5 16K的效果评估
- 第二阶段 第3版之微调Llama2 13b chat 2.7日,新增此节,即 “2.1 模型训练:LongQLora微调Llama2 13b chat”
- 2.15,新增一节,即 2.2 模型评估:llama2 13B longqlora再次接连超过GPT3.5和GPT4
- 2.17,更新此节的内容 2.2 模型评估:llama2 13B longqlora再次接连超过GPT3.5和GPT4
- 2.21,补充关于13B的下一步训练计划
- 2.28,补充关于“得克萨斯SelfExtended、微软LongRoPE等长度扩展方法”的初步调研结果
① 一年GPU,封装了诸如ChatGLM3等各大主流大模型
② 一个VIP年卡 ↓↓↓扫码抢购↓↓↓ 课程咨询可找苏苏老师VX: julyedukefu008 或七月在线其他老师 点击“ 阅读原文 ”了解 课程详情 ~