
一文概览深度学习中的激活函数

来源:深度学习爱好者 本文约3300字,建议阅读10+分钟
本文为你介绍不同类型的激活函数以及非线性激活函数的使用。
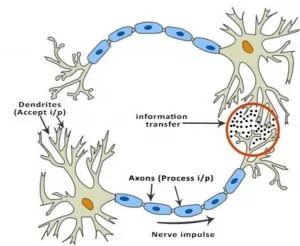
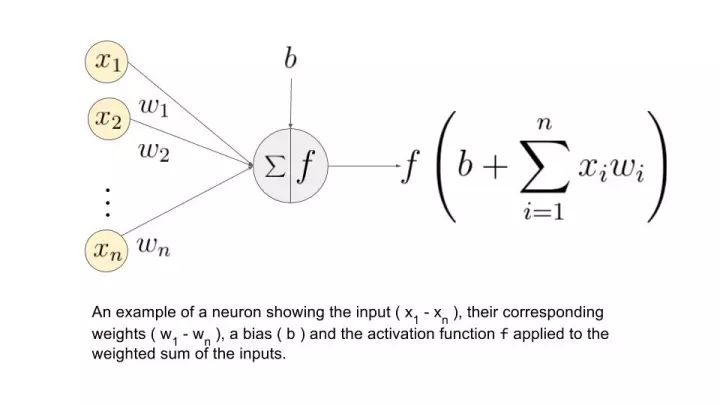
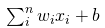 的输出值可以非常大。该输出在未经修改的情况下馈送至下一层神经元时,可以被转换成更大的值,这样过程就需要极大算力。激活函数的一个任务就是将神经元的输出映射到有界的区域(如,0 到 1 之间)。
的输出值可以非常大。该输出在未经修改的情况下馈送至下一层神经元时,可以被转换成更大的值,这样过程就需要极大算力。激活函数的一个任务就是将神经元的输出映射到有界的区域(如,0 到 1 之间)。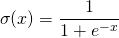



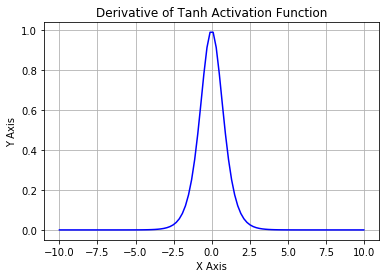

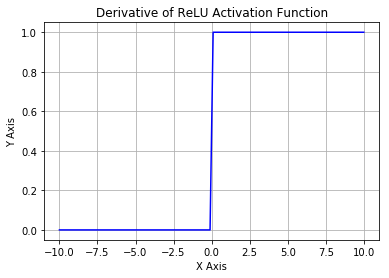
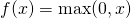
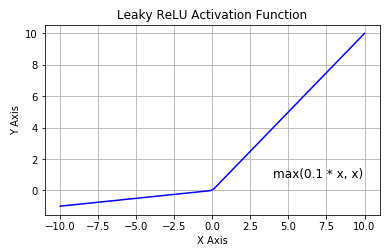
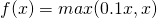
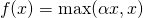
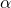 是超参数。这里引入了一个随机的超参数,它可以被学习,因为你可以对它进行反向传播。这使神经元能够选择负区域最好的梯度,有了这种能力,它们可以变成 ReLU 或 Leaky ReLU。
是超参数。这里引入了一个随机的超参数,它可以被学习,因为你可以对它进行反向传播。这使神经元能够选择负区域最好的梯度,有了这种能力,它们可以变成 ReLU 或 Leaky ReLU。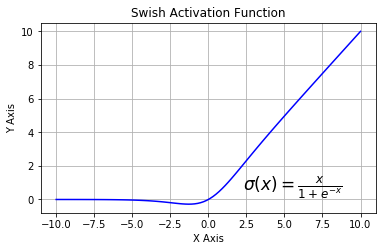
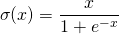
评论