
Swin-Transformer再次助力夺冠 | Kaggle第1名方案解读

极市导读
本文详细介绍了Kaggle冠军方案中的two-step “detect-then-match”的视频实例分割方法。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

在报告中介绍了two-step “detect-then-match”的视频实例分割方法。第1步对每一帧进行实例分割得到大量的instance mask proposals。第2步是利用光流进行帧间instance mask matching。用high quality mask proposals证明了一个简单的匹配机制可以促使得到更好的跟踪。本文的方法在2021年UVO比赛中取得了第1名的成绩。
1 实例分割
这里作者采用了先检测后进行语义分割的Pipeline的方法。
首先,训练一个目标检测器为视频的每一帧生成边界框。 然后,取前100个bounding box proposals,裁剪带有这些bounding box的图像,并将调整大小后的图像块输入前景/背景分割网络,以获得Instance Mask。
1、检测网络
作者采用Cascade Region Proposal Network作为Baseline,采用Focal loss和GIoU loss进行分类和边界框回归。 在训练过程中,作者使用2个独立的SimOTA采样器进行正/负样本采样,其中一个用于分类,另一个用于边界框回归。与此同时作者也放宽了边界框回归采样器的选择标准,以获得更多的正样本。 与分类头和边界框回归头并行增加一个IoU分支,用于预测预测边界框与ground truth之间的IoU。 为了解决目标检测中分类任务和回归任务之间的冲突问题,作者采用了decoupled head算法。 为了节省内存,所有金字塔的头部都有相同的权重。 将decoupled head的第1卷积层替换为DCN。 作者在FPN中添加了CARAFE块,并使用Swin-Transformer作为Backbone。
2、语义分割
前面使用检测网络预测的边界框来裁剪图像,并将它们的大小调整为512×512。裁剪后的图像路径被输入到分割网络以获得Instance Mask。作者采用了Upernet架构和Swin-Transformer作为Backbone。该分割网络是一种二值分割网络,如果像素属于目标,则被预测为前景,否则被预测为背景。
2 帧间Mask匹配
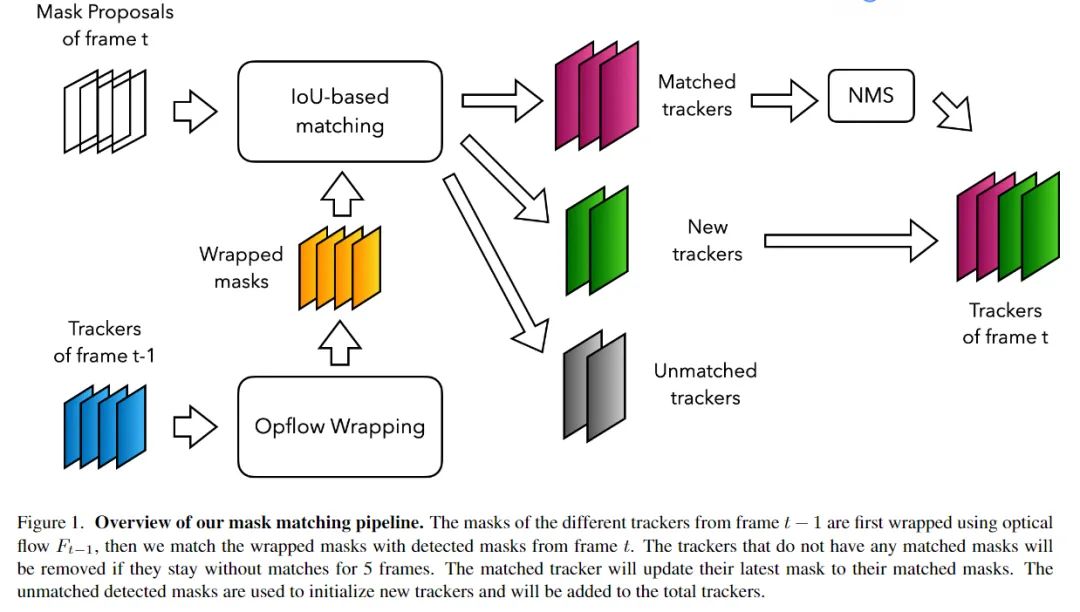
图1显示了本文方法的概述。作者的想法类似于IoU-tracker。利用预测的光流将前一帧的跟踪器wrapped 到当前帧,然后通过计算被wrapped Mask与detected Mask之间的IoU将跟踪器与当前帧的detected Mask匹配。用M表示所有帧的 mask proposals,表示帧t的mask proposal。t表示视频长度,F表示光流,其中表示帧t与帧t+1之间的光流。
首先,用第1帧中的mask proposal初始化跟踪器。 然后,使用光流将跟踪器的warpped mask到第2帧。 然后,通过计算它们之间的IoU,将warpped mask与detected Mask 匹配。
作者认为只有当IoU大于固定阈值时匹配才会成功。如果跟踪器与detected Mask匹配,则用匹配的Mask替换跟踪器的最新Mask。如果跟踪器和中的Mask之间没有匹配,则使用warpped mask更新其最新的Mask。如果跟踪器没有连续匹配5帧,从跟踪器列表中删除这个跟踪器。对于中没有匹配跟踪器的Mask,作者用这些Mask初始化新的跟踪器,并将这些跟踪器添加到跟踪器列表中使用非最大抑制(NMS)来去除最新Mask IoU大于0.7的跟踪器。给每个跟踪器分配一个分数,这个分数是被跟踪的帧数和检测分数之和的乘积。
3 复现细节
1、检测模型
作者使用MMDetection来训练检测器。对于Backbone网络,作者通过ImageNet 22k预训练了Swin-Transformer。这里所有的检测器都经过了Detectron ‘1x’ setting的训练。2个SimOTA采样的中心比设置为0.25,分类头的top-K数设置为10,回归头的top-K数设置为20,以获得更多的正样本。分类分支和回归分支使用4个的卷积层,IoU分支和回归分支共享相同的卷积层。为了训练以Swin-Transformer为Backbone的检测器,作者采用AdamW作为优化器,初始学习率设置为1e-4。批量大小设置为16。在COCO上进行训练后,结合6个epoch的UVO-Sparse和UVO-Dense数据集对检测器进行微调。所有的检测器都是以 class-agnostic的方式训练的。在推理过程中增加测试时间,进一步提高网络性能。
2、语义分割
作者使用MMSegmentation来训练分割网络。这里使用与检测网络相同的Backbone。在训练过程中,给定一幅图像和一个Instance Mask,首先生成一个bounding box,bounding box包含Instance Mask,然后在bounding box的各个方向上添加20像素的边界。作者使用生成的边界框来裁剪图像,并调整图像补丁的大小为。随机翻转、随机光度失真和随机bounding box抖动被用作数据增强。作者还采用多元学习率策略,初始学习率设置为6e-5。批大小被设置为32,AdamW被用作优化器。
首先,在OpenImage, PASCALVOC和COCO数据集的组合上训练网络为300k iter, 然后,在UVO-Density和UVO-Sparse数据集的组合上优化网络为100k迭代,初始学习率设置为6e-6。
所有的分割网络都是用class-agnostic的方式训练的,因此,分割裁剪路径中的目标成为一个前景/后景分割问题。推理过程中仅使用翻转试验增强。
3、光流估计
作者在FlyingTh-ings上训练的模型。FlyingThings是一个用于光流估计的大规模合成数据集。数据集是通过随机化从ShapeNet数据集中收集的相机的运动和合成对象生成的。先在FlyingThings上对光流估计模型进行预训练,每次迭代10万次,BS为12;然后在FlyingThings3D上进行10万次迭代,BS为6。
指标与可视化结果

在图2中,作者展示了一些视频实例分割结果。本文的方法可以适用于不同形状的物体。
潜在的改进点
本文简单的“检测然后匹配”框架可以作为视频实例分割的Baseline。它严重依赖于每帧mask proposals的质量。该方法的性能可能受到严重遮挡、物体出现/消失/重新出现等因素的影响。通过在Mask匹配过程中考虑目标层理,可以很好地解决这些问题。
参考
[1].1st Place Solution for the UVO Challenge on Video-based Open-World Segmentation 2021
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
