
视觉分类任务中处理不平衡问题的loss比较

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
在计算机视觉(CV)任务里常常会碰到类别不平衡的问题, 例如:
1. 图片分类任务,有的类别图片多,有的类别图片少
2. 检测任务。现在的检测方法如SSD和RCNN系列,都使用anchor机制。训练时正负anchor的比例很悬殊.
3. 分割任务, 背景像素数量通常远大于前景像素。
从实质上来讲, 它们可以归类成分类问题中的类别不平衡问题:对图片/anchor/像素的分类。
再者,除了类不平衡问题, 还有easy sample overwhelming的问题。easy sample如果太多,可能会将有效梯度稀释掉。
这两个问题通常都会一起出现。如果不处理, 可能会对模型性能造成很大伤害。用Focal Loss里的话说,就是训练不给力, 且会造成模型退化:
(1) training is inefficient as most locations are easy negatives…
(2) the easy negatives can overwhelming training and lead to degenerate models.
如果要处理,那么该怎么处理呢?在CV领域里, 若不考虑修改模型本身, 通常会在loss上做文章, 确切地说,是在样本选择或loss weight上做文章。
常见的解决办法介绍
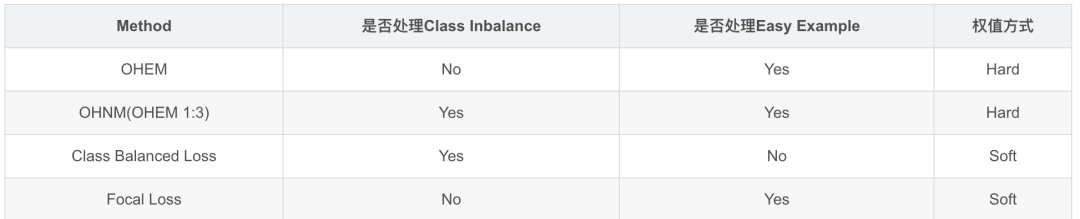
常见的方法有online的, 也有非online的;有只处理类间不平衡的,有只处理easy example的, 也有同时处理两者的。
Hard Negative Mining, 非online的mining/boosting方法, 以‘古老’的RCNN(2014)为代表, 但在CV里现在应该没有人使用了(吧?)。若感兴趣,推荐去看看OHEM论文里的related work部分。
Mini-batch Sampling,以Fast R-CNN(2015)和Faster R-CNN(2016)为代表。Fast RCNN在训练分类器, Faster R-CNN在训练RPN时,都会从N = 1或2张图片上随机选取mini_batch_size/2个RoI或anchor, 使用正负样本的比例为1:1。若正样本数量不足就用负样本填充。使用这种方法的人应该也很少了。从这个方法开始, 包括后面列出的都是online的方法。
Online Hard Example Mining, OHEM(2016)。将所有sample根据当前loss排序,选出loss最大的N个,其余的抛弃。这个方法就只处理了easy sample的问题。
Oline Hard Negative Mining, OHNM, SSD(2016)里使用的一个OHEM变种, 在Focal Loss里代号为OHEM 1:3。在计算loss时, 使用所有的positive anchor, 使用OHEM选择3倍于positive anchor的negative anchor。同时考虑了类间平衡与easy sample。
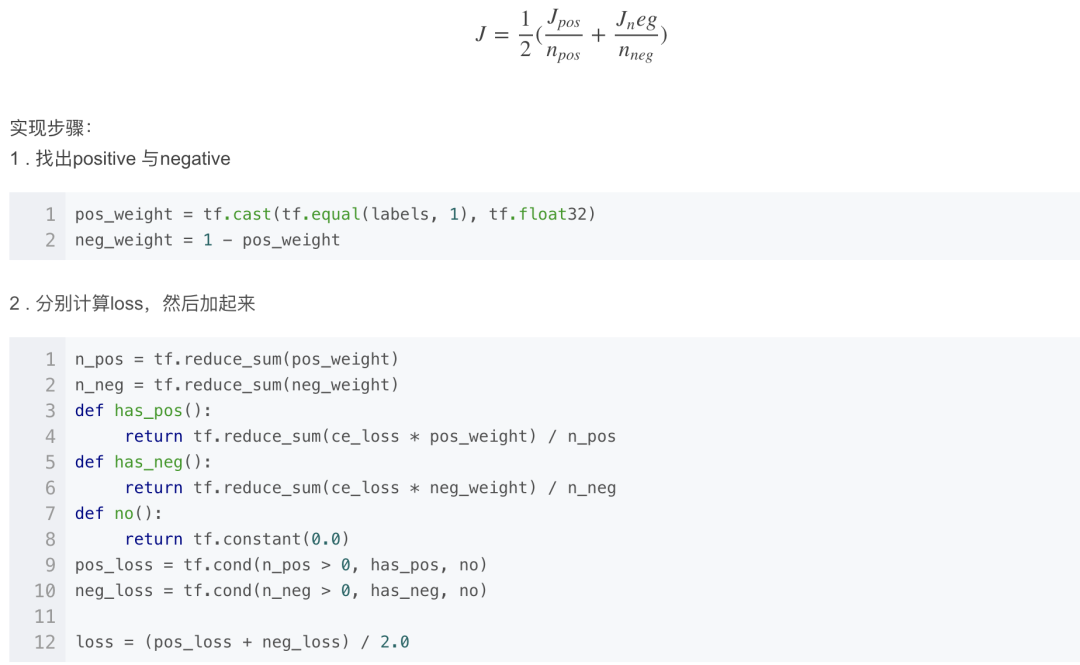
Class Balanced Loss。计算loss时,正负样本上的loss分别计算, 然后通过权重来平衡两者。暂时没找到是在哪提出来的,反正就这么被用起来了。它只考虑了类间平衡。
Focal Loss(2017), 最近提出来的。不会像OHEM那样抛弃一部分样本, 而是和Class Balance一样考虑了每个样本, 不同的是难易样本上的loss权重是根据样本难度计算出来的。
从更广义的角度来看,这些方法都是在计算loss时通过给样本加权重来解决不平衡与easy example的问题。不同的是,OHEM使用了hard weight(只有0或1),而Focal Loss使用了soft weight(0到1之间).
现在依然常用的方法特性比较如下:
接下来, 通过修改过的Cifar数据集来比较这几种方法在分类任务上的表现,当然, 主要还是期待Focal Loss的表现。
实验数据
实验数据集
Cifar-10, Cifar-100。使用Cifar的原因没有别的, 就因为穷,毕竟要像Focal Loss论文里那样跑那么多的大实验对大部分学校和企业来说是不现实的。
处理数据得到类间不平衡
将多分类任务转换成二分类:
new_label = label == 1
原始Cifar-10和100里有很多类别,每类图片的数量基本一样。按照这种方式转变后,多分类变成了二分类, 且正负样本比例相差悬殊:9倍和99倍。
实验模型
一个5层的CNN,完成一个不平衡的二分类任务。使用Cross Entropy Loss,按照不同的方法使用不同的权值方案。以不加任何权重的CE Loss作为baseline。
衡量方式
在这种不平衡的二分类问题里, 准确率已经不适合用来衡量模型的好与坏了。此处使用F-Score作标准.
实现细节
CE(Cross Entroy Loss)

OHEM

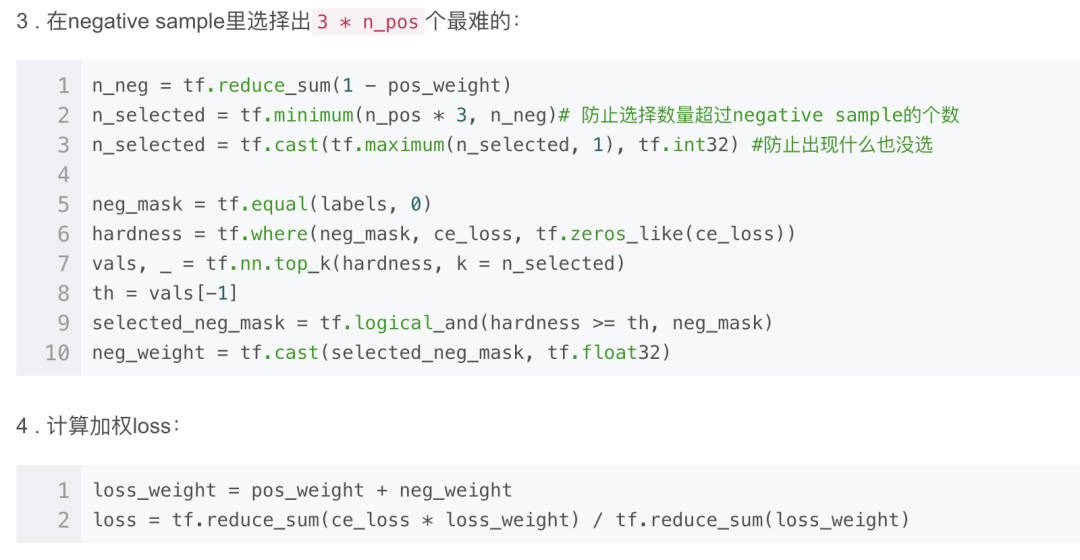
Class Balance CE


优化方法
实验结果
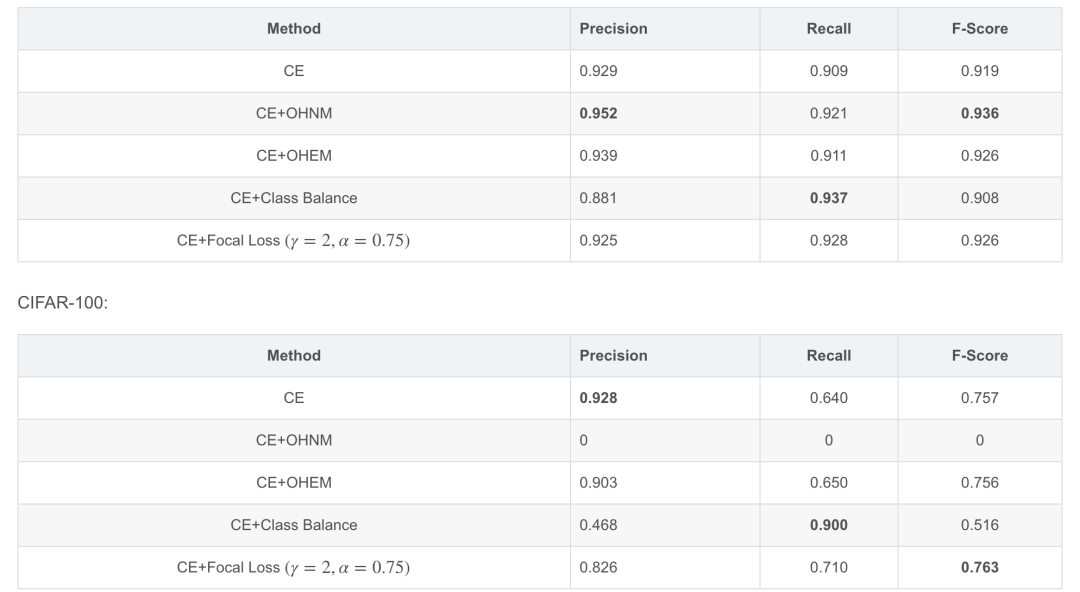

Focal Loss的一个补丁
对于CIFAR-100,batch_size=128时, 一个batch内可能会一个positive sample都没有, 即n_pos == 0, 这时,paper里用n_pos来normalize loss 的方式就不可行了。测试过两种简单的选择:一是用所有weight之和来normalize, 二是直接不normalize。前者很难训练甚至训练不出来, 后者可用。所以上面的Focal loss计算代码应该补充为:

经验总结

Code Available On Github
https://github.com/dengdan/test_tf_models
Branch:focal_loss
References
Focal Loss for Dense Object Detection, https://arxiv.org/pdf/1708.02002.pdf
RCNN, https://arxiv.org/abs/1311.2524
Fast RCNN, http://arxiv.org/abs/1504.08083
Faster-RCNN, http://arxiv.org/abs/1506.01497
Training Region-based Object Detectors with Online Hard Example Mining, https://arxiv.org/abs/1604.03540
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx