
基于深度学习的畸变校正
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达 
编者荐语
透镜由于制造精度以及组装工艺的偏差会引入畸变,导致原始图像的失真。镜头的畸变分为径向畸变和切向畸变两类。以往的文章一般是通过传统方式进行推导,本次我们尝试使用深度学习来完成这一步骤。
在手机中的计算摄影4-超广角畸变校正中,我为你描述了广角镜头的镜头畸变校正和透视畸变校正,尤其是花了很多篇幅讲述施易昌等人的论文如何校正因为透视畸变导致的人脸拉伸现象。
然而,正如我文章中所讲,这个方法依然有它的不足之处:
没有准确的人脸Mask就无法进行校正
校正只针对人脸,会出现头小身大的现象
某些情况下无法保证直线不弯曲,有些时候还无法很好的校正人脸
速度慢,单张图像需要接近1秒钟完成
那么如何解决这些问题呢?今天要介绍的方法,就是尝试对上述缺陷进行改进。
一. 第一个基于深度学习的畸变校正算法
我们先来想想为什么施易昌等人的方法存在一定缺陷
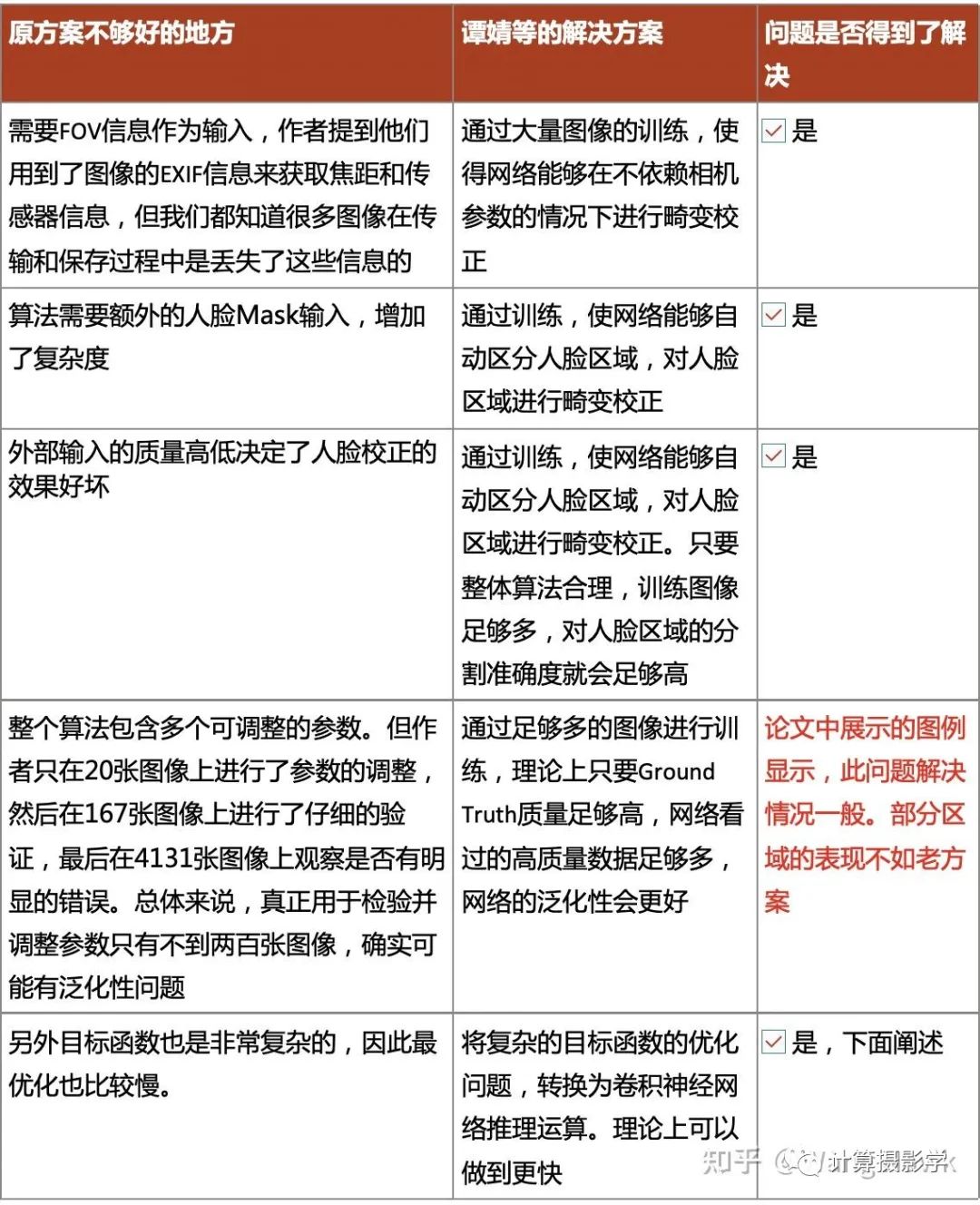
需要FOV信息作为输入,作者提到他们用到了图像的EXIF信息来获取焦距和传感器信息,但我们都知道很多图像在传输和保存过程中是丢失了这些信息的
因为他们的算法只针对人脸区域采用球极投影进行校正,因此一定需要输入人脸的Mask,而这个Mask是通过专门训练的人脸分割网络计算出来的。很显然,这里带来了两个问题:
算法需要额外的外部输入,增加了复杂度
外部输入的质量高低决定了人脸校正的效果好坏
3. 整个算法包含多个可调整的参数。但作者只在20张图像上进行了参数的调整,然后在167张图像上进行了仔细的验证,最后在4131张图像上观察是否有明显的错误。总体来说,真正用于检验并调整参数只有不到两百张图像,确实可能有泛化性问题。
4. 另外目标函数也是非常复杂的,因此最优化也比较慢。
针对这几个问题,潜在的解决方案有:
完全不用相机内参数输入,将背景的镜头畸变校正也整合到流程中,用一些图像上的特征来约束镜头畸变校正
将人脸校正所需的Mask的计算整合到整个流程中,不需要外部输入
使用大量的图像来验证算法的泛化性和有效性
旷视研究院的谭婧、赵姗等人在2021年CVPR发表的文章,就很好的把这几个方案整合到了一起:

这篇文章展示了第一个用深度学习来完成的自动去畸变算法,其中用两个子网络分别完成镜头畸变的校正和透视畸变的校正,而且它不需要相机的畸变参数,效果据作者描述比施易昌等人的方法更好。
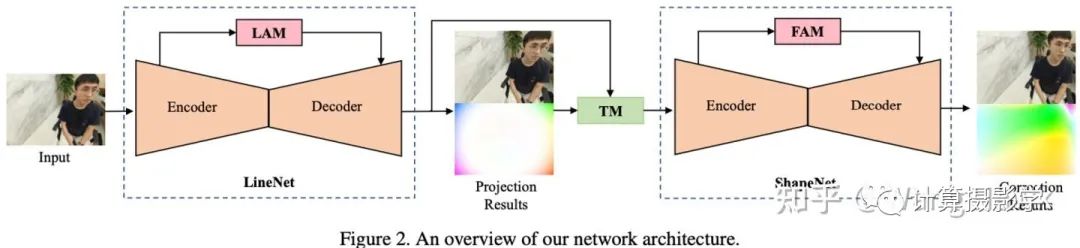
这里,LineNet用于进行镜头畸变校正,经过LineNet后直线被校直。而ShapeNet则用于进行人脸的球极畸变校正。通过两个注意力模块LAM(Line Attention Module)和FAM(Face Attention Module),图像中的直线和人脸被特意强调。由于训练数据有人脸和直线的标注信息,因此训练出的网络不需要外部的相机参数及人脸Mask也能够进行很好的校正,最后得到了和施易昌等方法相当,甚至某些情况下更好的结果。
接下来我从训练和验证数据、损失函数、评价指标、网络结构等几个方面概略的介绍一下。
1.1 训练和验证数据
谭婧等的方法总体上来说是一种监督型的训练方法,因此需要一个带有Ground Truth信息的数据集。然而以前从来没有广角畸变校正的标准数据集,因此作者用5个超广角的拍照手机,在各种场景下进行采集,制作了一个超过5000张图像的数据集,每张图像的人像分布在1到6人之间。由于有这几个相机的畸变参数,因此可以很容易的获得镜头畸变校正的map,作为LineNet训练时的Ground Truth。
接下来,为了获得每张图像对应的透视畸变校正后的图像,作者们基于施易昌等的方法开发了一个自动化的校正工具,其中刻意在原方法的目标函数的基础上添加了一个人脸附近的直线约束,使得能够更好的保持人脸附近的直线。
作者们还开发了一个微调工具,可以基于Mesh来对图像的局部进行微调。通过联合使用校正工具+微调工具,她们得到了一个效果很好的数据集,下图d是最终手动优化后的效果,可以看到它确实比施易昌等的方法结果好(图b),例如这里人脸附近的大楼阳台保持了直线。

下面展示了数据集中需要包括的内容
输入的图像(完全未经畸变校正)
经过镜头畸变校正后的图像(此时直线被校直)
经过透视畸变校正后的图像(此时背景直线校直,且人脸畸变被消除)
人脸Mask
直线标注信息
镜头畸变校正Map
透视畸变校正Map

1.2 评价方法和指标
为了评价算法的效果,作者引入了两个评价指标: LineAcc(评价直线的保直度),以及ShapeAcc(评价人脸校正的准确度)。简单说来,LineAcc计算的是已标注的线段在校正后图像上的像素点的平均夹角,夹角越小,直线越直。而ShapeAcc则是计算校正前后人脸上每个关键点与中心点形成的线段的夹角,夹角越小,人脸效果越接近Ground Truth。
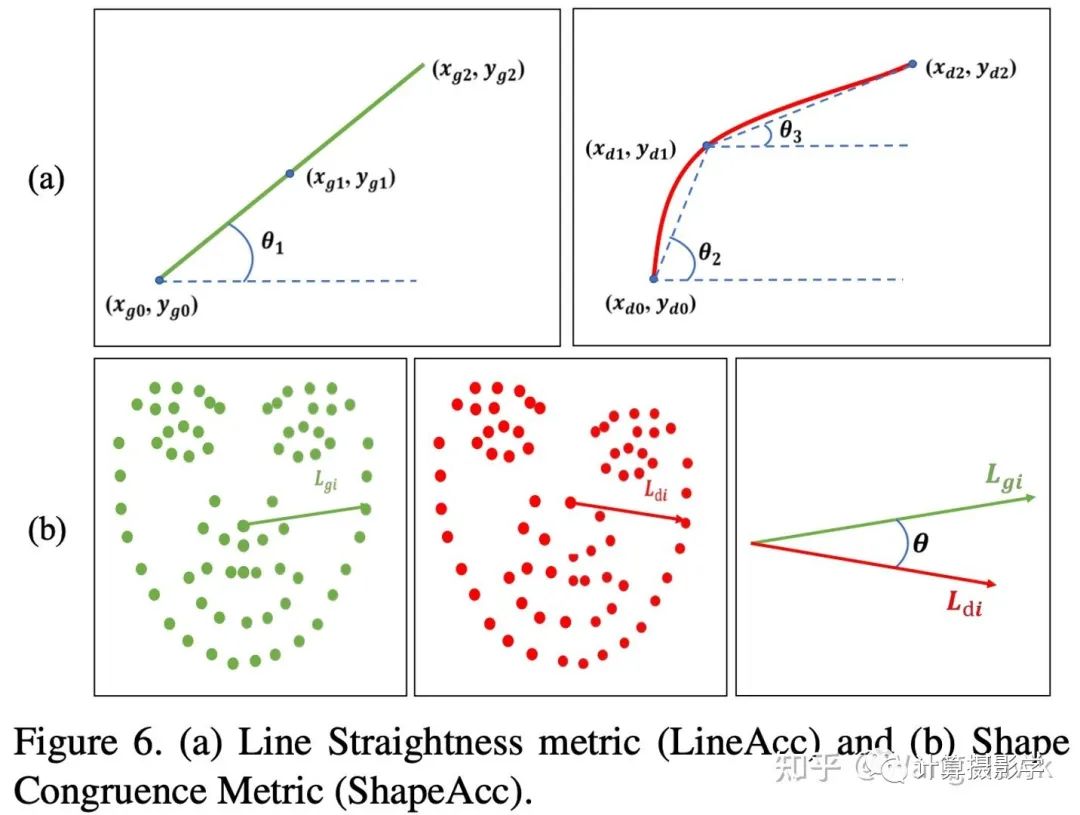
下图说明作者的最终输出在LineAcc和ShapeAcc两方面均超过了输入,且达到了较好的平衡。

1.3 网络结构
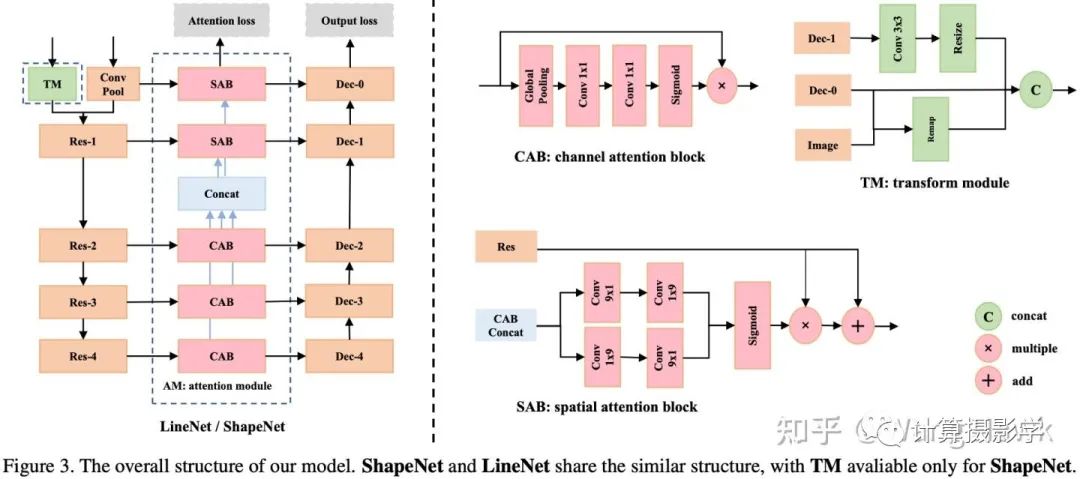
如前所述,作者的网络结构如下图所示,其中
LineNet用于进行镜头畸变校正,经过LineNet后直线被校直
ShapeNet则用于进行人脸的球极畸变校正。
通过两个注意力模块LAM(Line Attention Module)和FAM(Face Attention Module),图像中的直线和人脸被特意强调
TM用于保持LineNet和ShapeNet在背景区域的一致性
1.4 损失函数
下面是LineNet和ShapeNet的损失函数,其中下标flow代表在计算map表的一致性,而下标proj和下标out则用于表示计算image的一致性。而2,s2则表示分别计算原始的L2 Loss,以及先对图像或map做Sobel计算,然后再计算L2 Loss。
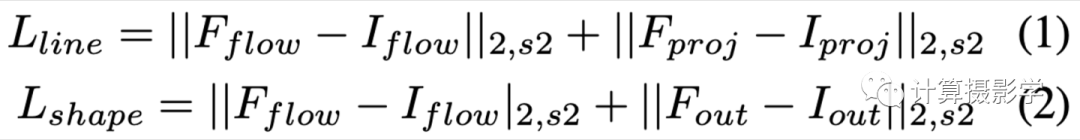
类似的,两个注意力模块LAM和FAM也有自己的损失函数:
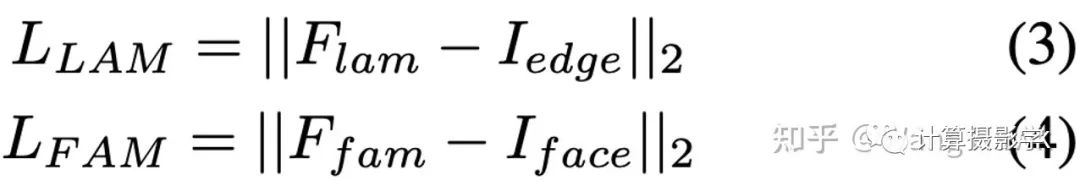
这几个损失函数之和构成了最终的损失函数,用于约束整个网络的训练
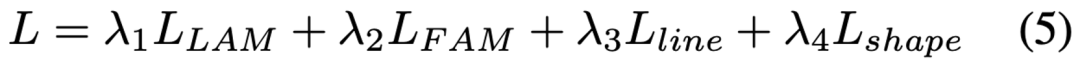
1.5 结果展示
我们先来看看作者展示的效果,这里图(a)是利用相机参数进行镜头畸变校正后的结果,图(b)是在此基础上进行球极投影校正的结果,图(c)是施易昌等人的方法,图(d)则是谭婧等的方法。

我们用动图比较下两个方法,可以看到对于某些图片,谭婧等的方法明显更好

不过仔细看别的图,会发现和施易昌的方法一样,谭婧等的方法也会有一些缺陷,施易昌等的方法过于强调人脸,使得背景可能弯曲,而谭婧等的方法则强调了背景的直线,但人脸表现不够完美:


1.6 小结,及实际项目中的好处
公平的说,这种基于深度学习的方案依然有这样那样的效果问题。但我得承认,它确实从整体方法上前进了一大步。让我们回顾施易昌等人的方案在哪些地方做的不够好,再看看新方案是否解决了这些问题:
为什么我说用深度学习的方案,理论上可以做到更快呢?因为现在各种计算框架,以及硬件芯片本身,对卷积神经网络的运算已经做到了很好的优化了,而许多传统优化算法由于计算方法的复杂和非统一性,很难做到大幅的性能提升。在实际项目中,我们对谭婧等的网络架构做了裁剪优化,经过良好的配置,在模型算力要求高达1.8GFlops的情况下,在高通8250平台只需要不到40ms即可完成推理运算,这相比起施易昌等需要接近1s才能完成运算来说,是巨大的性能提升——这就是目前很多计算机视觉、计算摄影学的算法由传统算法改为统一的深度学习算法的一大收益!
二. 改进方案,以及第一个半监督学习的畸变校正算法
然而,为什么基于深度学习的方法在实测效果上并未比施易昌等的方法好多少呢?我认为主要有两个原因:
深度学习方法需要大量数据来训练,而数据非常昂贵
谭婧等所用的评判结果好坏的标准和人类的主观感受还无法完全一致
我们先来看看评价方法和标准的缺陷,如下图所示,作者们用的评价方法是采样图像上的特定的线段,希望这些线段与Ground Truth之间的夹角越小越好。那么这里就可能存在这些采样的线段不足以描述人类的主观感受这样的问题了,比如是不是当发生畸变时,有更多的无法简单用线段的偏转来描述的特征?这是一个非常本质和深入的问题,可以留待将来进行更深入的研究。
更现实的问题是,不管是用于训练,还是用于验证和评价,数据都非常宝贵。高质量的数据非常难于得到。几乎对每一张样本图像,都需要手工进行调整,以得到它去掉畸变后的完美图像——这实际上是一个非常主观的事情。昂贵的数据采集手段,使得谭婧等最终得到的是大概5000张图像的数据集。实际上,这些数据集很可能因为时间和精力原因,存在一定的瑕疵,影响最终的效果。
那么,有没有可能降低对数据采集的需求呢?半监督学习是一个可能的方向,下面这篇旷视研究院的预印版文章(arxiv.org/abs/2109.0802)可供参考:


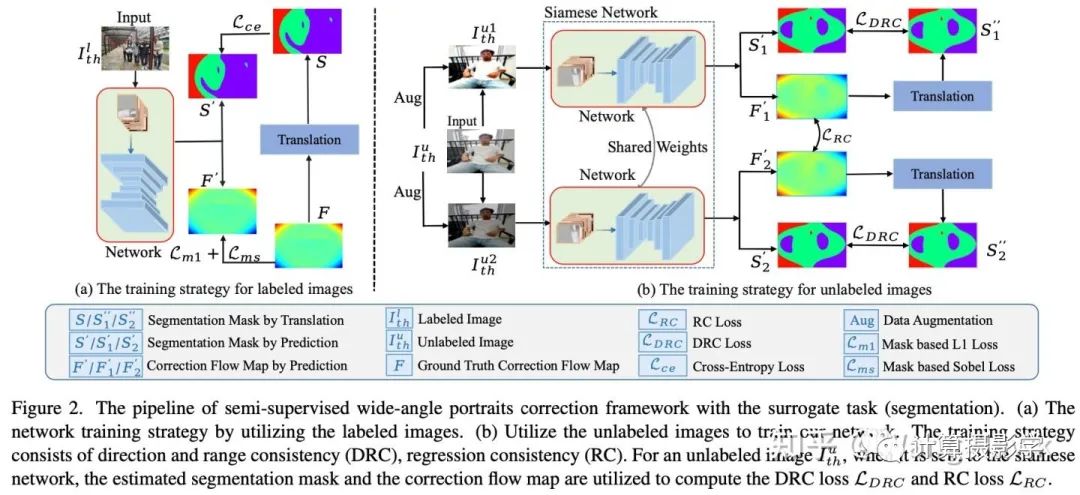
作者们的想法也很简单,他们在网络训练过程中加入了一个分割的任务,使得分割任务去分割校正map中的各个部分(不同方向的大位移以及小位移)。那么分割结果和校正map之间就建立起了某种关系,另外分割结果、校正map与各自的Ground Truth之间也有约束关系。现在加入没有标注过的数据,这些数据经过网络推理后也会得到分割图和校正map。作者认为这两者之间的关系应该和有标注的数据对应的信息有相同的约束关系——就用这个约束去迭代优化网络。
听起来,跟模型蒸馏颇有异曲同工之妙,文章中也展示了挺不错的效果,例如下图中的效果,确实相比谭婧和施易昌等人的方法有了提升。

三. 总结
到此为止,我已经介绍了第1个基于优化算法的自动畸变校正算法(手机中的计算摄影4-超广角畸变校正),第1个基于深度学习的畸变校正算法,以及第1个基于半监督学习思想的畸变校正算法。从工程上讲,利用这些技术,已经能够开发出比较符合当前手机客户需求的产品了。事实上正如我文章里所讲,我们开发的基于深度学习的畸变校正算法已经能够在不到100ms时间内完成全流程的计算和图像变换了。
然而,不管是哪种方法,目前都还有前进的空间,有一些图像上表现依然还不够好。除了人脸之外,人的身体、脚等区域与人脸的一致性还需要加强。但过于强调这些区域之间的一致性,又会使得网络学习起来比较困难。
与此同时,尽管算法运行已经足够快了,但要真正流畅的用在视频拍摄方面,还需要解决视频帧之间的时域相关性,否则会产生抖动,同时速度还需要加快,才能适用于当前大分辨率的视频录制上。
所以你现在在用的手机,基本上还没有解决好”超广角畸变校正“这个问题,比如下面的图示就能看出iPhone12和小米11都没有把这个问题解决好,其实最新的iPhone13 Pro也在这个问题上没有提升。希望之后,能在更多的手机产品上看到这个问题更好的解决方案吧!

四. 参考资料
YiChang Shih, Wei-Sheng Lai, Chia-Kai Liang, and Chia Kai Liang. Distortion-free wide-angle portraits on camera phones. ACM Trans. Graphics, 38(4):1–12, 2019
Jing Tan, Shan Zhao, Pengfei Xiong, Jiangyu Liu, Haoqiang Fan, and Shuaicheng Liu. Practical wide-angle portraits correction with deep structured models. In Proc. CVPR, pages 3498–3506, 2021.
https://arxiv.org/abs/2109.08024
—THE END—
一个专注于计算机视觉与机器学习的公众号,努力将分享变成一种习惯!
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~