
如何化解 Kubernetes 网络的复杂性?

本文将以带有两个 Linux 节点的标准 Google Kubernetes Engine(GKE)集群为例,通过跟踪 HTTP 请求被传送到集群服务的整个过程,深度拆解 Kubernetes 网络的复杂性。
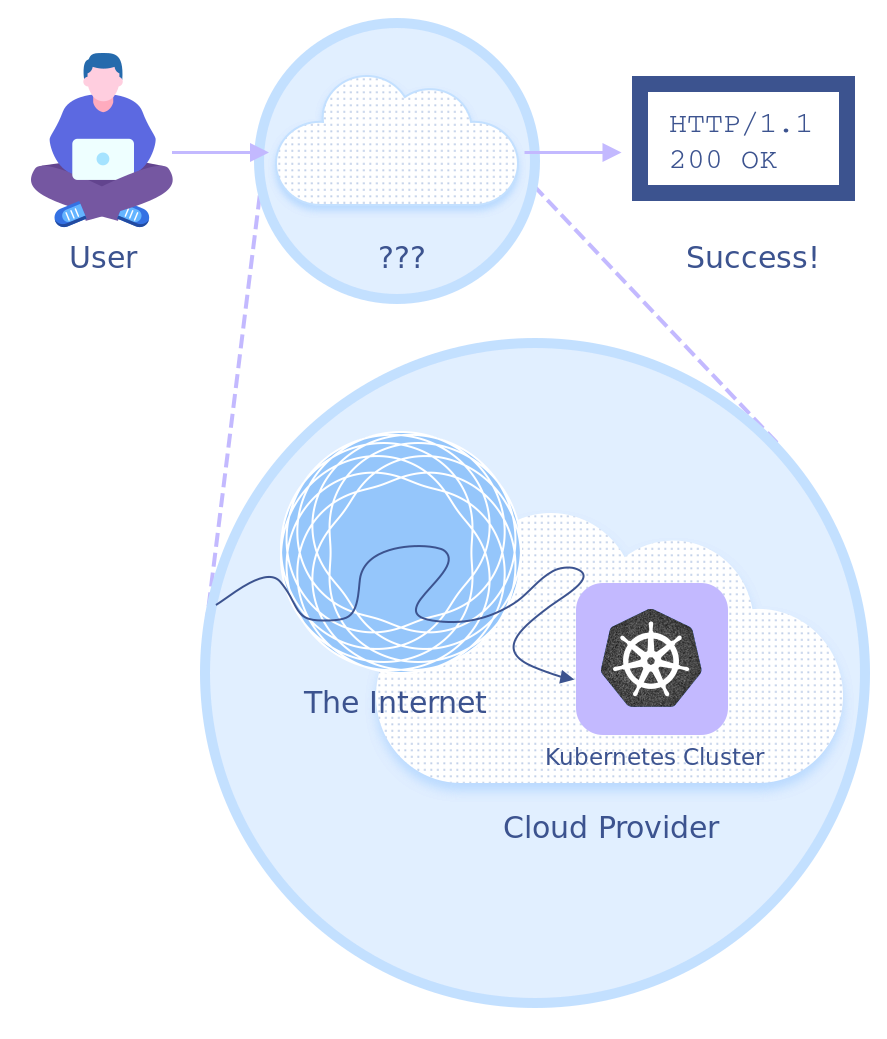
请求的旅程
当一个人在浏览网页时,他首先单击一个链接,发生了一些事,之后目标页面就被加载出来。这让人不免好奇,从单击链接到页面加载,中间到底发生了什么?

Service 资源(svc)发送请求,然后将请求路由到 Kubernetes ReplicaSet(rs)中的 Pod。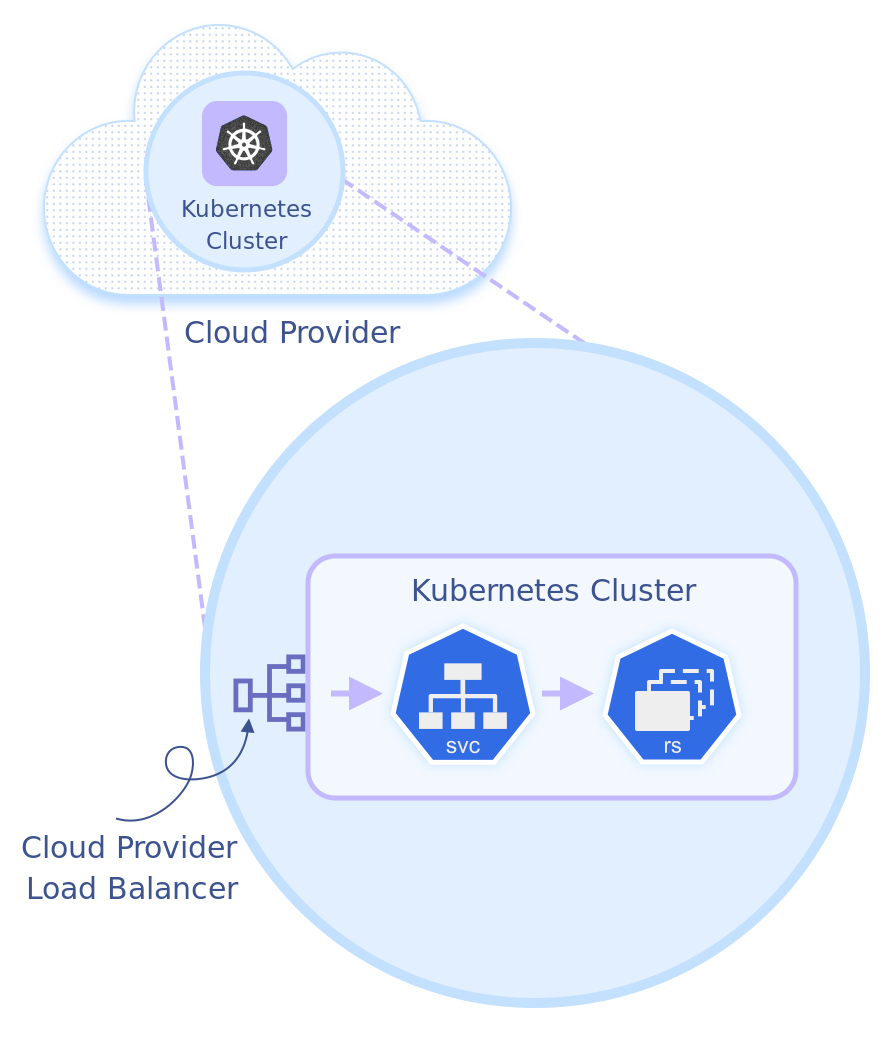
apiVersion: apps/v1kind: ReplicaSetmetadata:name: hello-worldlabels:app: hello-worldspec:selector:matchLabels:app: hello-worldreplicas: 2template:metadata:labels:app: hello-worldspec:containers:- name: hello-worldimage: gcr.io/google-samples/node-hello:1.0imagePullPolicy: Alwaysports:- containerPort: 8080protocol: TCP---apiVersion: v1kind: Servicemetadata:name: hello-worldspec:selector:app: hello-worldports:- port: 80targetPort: 8080protocol: TCPtype: LoadBalancerexternalTrafficPolicy: Cluster
hello-world ReplicaSet 下创建了两个 Pod,还创建了一个带有负载均衡器的服务资源 hello-world(如果云提供商和集群网络支持),以及一个在 host:port 中有两个条目的 Kubernetes Endpoint 资源,每个 Pod 对应一个,以 Pod IP 作为主机值和端口 8080。kubectl 一下会返回以下内容: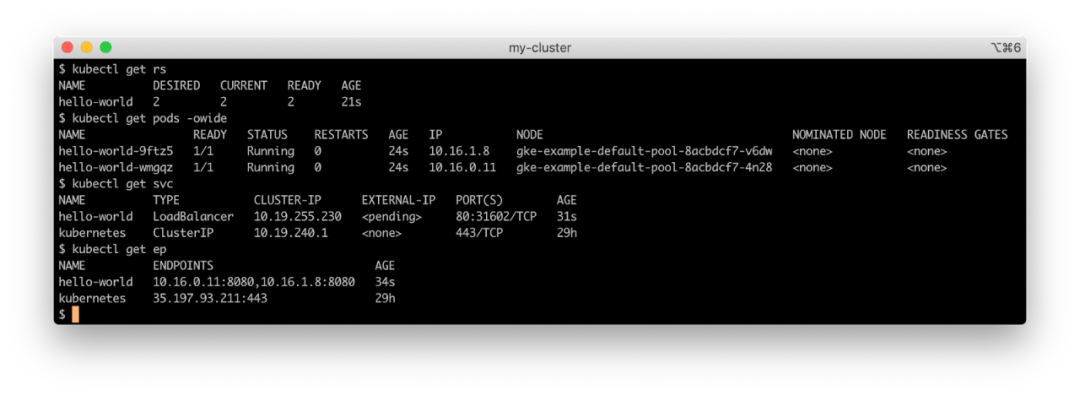
Node - 10.138.15.0/24 Cluster - 10.16.0.0/14 Service - 10.19.240.0/20
已知服务在集群 CIDR 中的虚拟 IP 地址(VIP)是 10.19.240.1。现在,我们可以从负载均衡器开始,深入跟踪请求进入 Kubernetes 集群的整个“旅程”。
负载均衡器
Kubernetes 通过本地控制器和 Ingress 控制器提供了很多公开服务的方法,但这里我们还是使用 LoadBalancer 类型的标准 Service 资源。
hello-world 服务需要 GCP 网络负载均衡器。每个 GKE 集群都有一个云控制器,它在集群和 API 端点之间进行接口,以自动创建集群资源所需的 GCP 服务,包括我们的负载均衡器(不同云提供商的负载均衡器在类型、特性上都有不同)。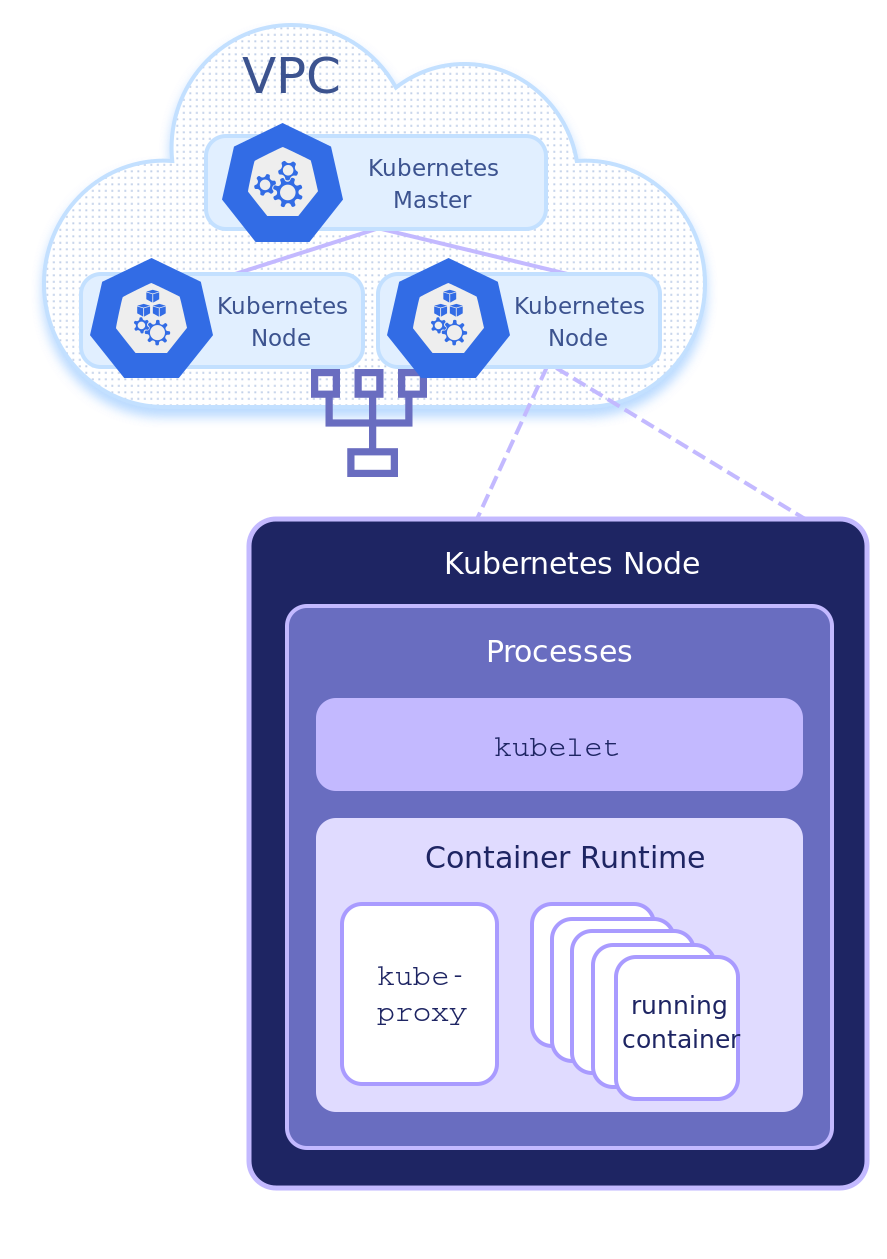
kube-proxy
每个节点都有一个 kube-proxy 容器进程(在 Kubernetes 参考框架中,kube-proxy 容器位于 kube-system 命名空间的 Pod 中),它负责把寻址到集群 Kubernetes 服务对象虚拟 IP 地址的流量转发到相应后端 Pod。kube-proxy 当前支持三种不同的实现方式:
User space:即用户空间,服务路由是在用户进程空间的 kube-proxy 中进行的,而不是内核网络堆栈。这是 kube-proxy的最初版本,较为稳定,但是效率不太高;iptables:这种方式采用 Linux 内核级 Netfilter 规则为 Kubernetes Services 配置所有路由,是大多数平台实现 kube-proxy的默认模式。当对多个后端 Pod 进行负载均衡时,它使用未加权的循环调度;IPVS:IPVS 基于 Netfilter 框架构建,在 Linux 内核中实现了 L4 负载均衡,支持多种负载均衡算法,连接最少,预期延迟最短。它从 Kubernetes v1.11 中开始普遍可用,但需要 Linux 内核加载 IPVS 模块。它也不像 iptables 那样拥有各种 Kubernetes 网络项目的广泛支持。
kube-proxy 以 iptables 模式运行,所以我们后续主要研究该模式的工作方式。hello-world 服务,我们可以发现它已经被分配了一个节点端口 30510。节点网络上动态分配的端口允许其中托管的多个 Kubernetes 服务在其端点中使用相同的面向 Internet 的端口。hello-world pods 绝对没有在节点的端口 80 上监听。所以如果在节点上运行 netstat,我们可以看到没有进程正在监听该端口。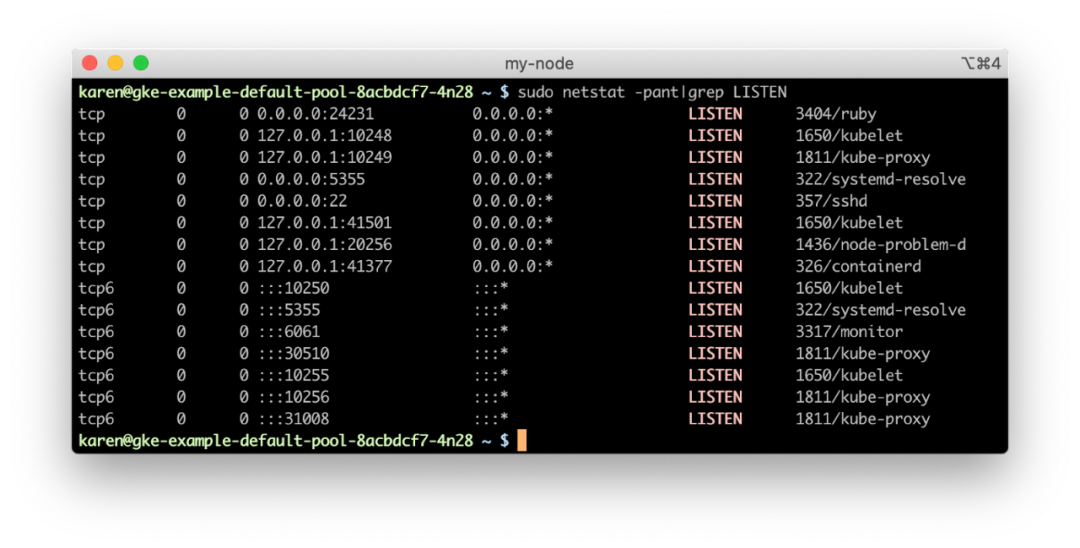
那么,通过负载均衡器的请求是如何成功建立连接的呢?如果 kube-proxy 在用户空间模式下运行,它实际上是将连接代理到后端 Pod。但是,在 iptables 模式下,kube-proxy 配置了 Netfilter 链,因此该连接被节点的内核直接路由到了后端容器的端点。
iptables
在我们的 GKE 集群中,如果登录到其中一个节点并运行 iptables,我们可以看到这些规则。
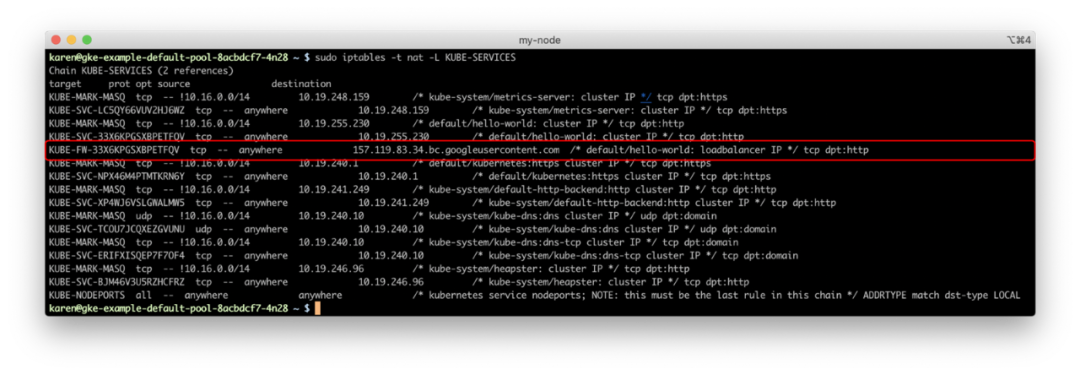
hello-world 服务的传入连接相匹配的过滤器链的名称,并遵循该链的规则(在没有规则注释的情况下,我们仍然可以将规则的源 IP 地址与服务的负载均衡器进行匹配)。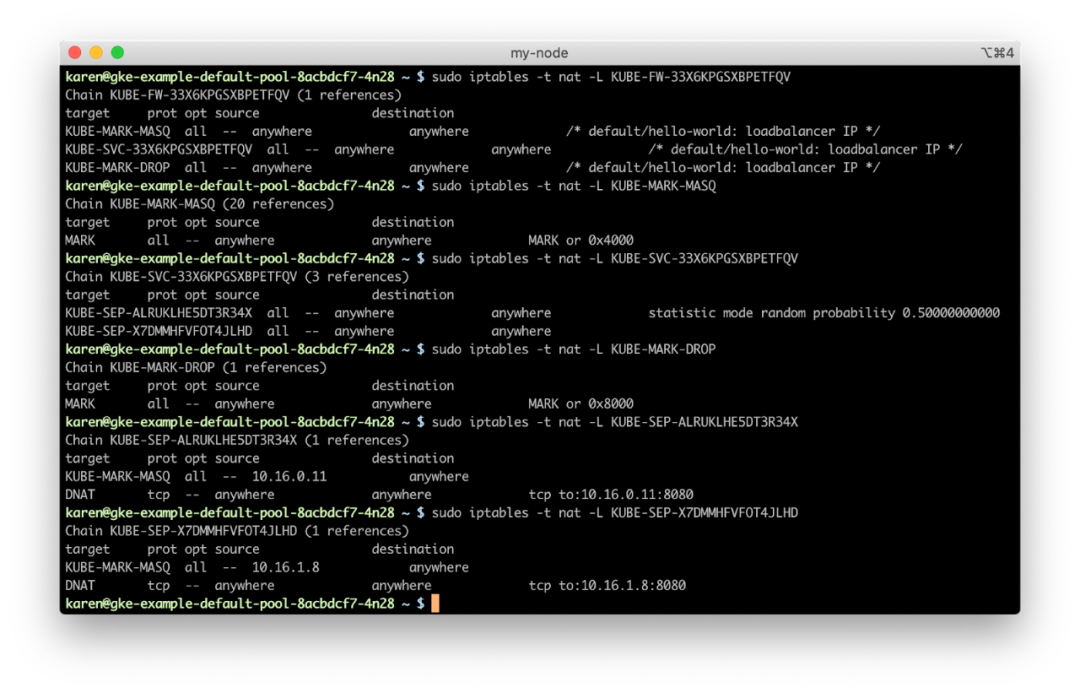
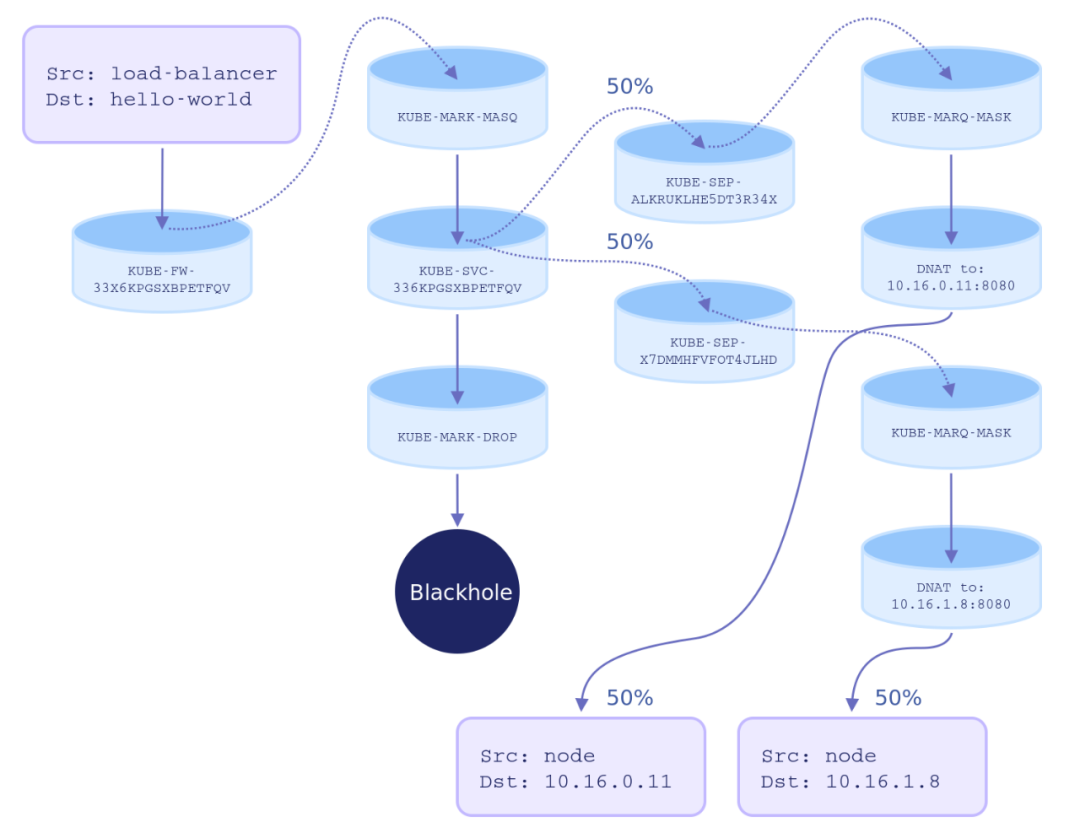
KUBE-FW-33X6KPGSXBPETFQV 链有三个规则,每个规则都添加了另一个链来处理数据包。KUBE-MARK-MASQ向发送到hello-world服务的包(来自集群网络外部)添加一个 Netfilter 标记。带有此标记的数据包将按照POSTROUTING规则进行更改,以使用源网络地址转换(SNAT),并将节点 IP 地址作为其源 IP 地址;KUBE-SVC-33X6KPGSXBPETFQV链适用于所有与hello-world服务相关的流量(与源无关),并且对每个服务端点(在本例中为两个 Pod)提供规则。使用哪个端点链是完全随机确定的:KUBE-SEP-ALRUKLHE5DT3R34X:如果需要,KUBE-MARK-MASQ会再次向数据包中添加一个 Netfilter 标记用以 SNAT;DNAT规则使用 10.16.0.11:8080 端点作为目标来设置目标 NATKUBE-SEP-X7DMMHFVFOT4JLHD:如果需要,KUBE-MARK-MASQ会再次为数据包添加一个 Netfilter 标记用以 SNAT;DNAT规则使用 10.16.1.8:8080 端点作为目标来设置目标 NATKUBE-MARK-DROP向此时尚未启用目标 NAT 的数据包添加 Netfilter 标记。这些数据包将在KUBE-FIREWALL链中被丢弃。
hello-world Pod,但这种路由方法并不存在优先级。如果我们将服务规范中的 externalTrafficPolicy 更改为 Local,那么情况就会改变。假设此时存在请求,这个请求不仅会转到接收请求的节点上的 Pod,还会导致没有服务 Pod 的节点拒绝连接。因此,Local 策略通常需要与 Kubernetes daemon sets 一起使用,后者会在集群中的每个节点上调度一个 Pod。虽然前者能明显降低请求的平均网络延迟,但它也可能导致服务 Pods 之间的负载不均衡。
Pod 网络
请求
以下是是我们获取 HTTP 200 响应代码的方式:
容器网络接口(CNI)插件:每个云提供商默认使用与其 VM 网络模型兼容的 CNI 实现。本文以默认设置的 GKE 集群为例,但如果是 Amazon EKS,那会很不一样,因为 AWS VPC CNI 把容器直接放在节点的 VPC 网络上;
Kubernetes Network Policy:Calico 是实施网络策略最受欢迎的 CNI 插件之一,它在节点上为每个 Pod 创建一个虚拟网络接口,并使用 Netfilter 规则来实施其防火墙规则;
尽管大多数情况下仍然使用 Netfilter,但
kube-proxyIPVS 路由模式通常会把服务路由和 NAT 移出 Netfilter 规则;外部负载均衡器或其他可以将流量直接发送到服务节点端口的源将匹配 iptables 中的不同链(
KUBE-NODEPORTS);Kubernetes Ingress 控制器可以通过多种方式更改边缘服务路由;
诸如 Istio 之类的服务网格可能会绕过 kube-proxy,直接连接服务容器之间的内部路由。
保护服务
Kubernetes 网络需要大量可移动部件,它非常复杂,但如果开发者对集群中发生的事有基本了解,这会有助于开发者更有效地监控、保护它。
loadBalancerSourceRanges 字段,这个字段允许开发者提供可以连接到负载均衡器的 IP CIDR 块白名单。如果云提供商不支持此字段,它就会被忽略,因此开发者需要验证外部负载均衡器的网络配置。loadBalancerSourceRanges 字段的云提供商,除非已经在云提供商级别采取措施锁定了负载均衡器和运行它们的云网络,开发者还是应该假定负载均衡器上的服务端点是对全世界开放的。由于各种因素,云提供商负载均衡器产品的默认防火墙设置千差万别,一些云提供商可能还支持对 Service 对象的注释,以配置负载均衡器的安全性。NetworkPolicy API 的 CNI,并创建限制 Pod 流量的策略。HostNetwork 属性创建的 Pod 将共享节点的网络空间。虽然存在一些这样做的例子,但通常情况下,大多数 Pod 不需要在主机网络上,尤其是对于有 root 特权的 Pod,这可能会导致受攻击的容器可以查看网络流量。如果开发者需要在节点网络上公开容器端口,而使用 Kubernetes Service 节点端口无法满足需求,一个稳妥的选择是可以在 PodSpec 中为容器指定 hostPort。NET_ADMIN 功能运行,这将使它们能够读取和修改节点的防火墙规则。K8S 进阶训练营

 点击屏末 | 阅读原文 | 即刻学习
点击屏末 | 阅读原文 | 即刻学习

扫描二维码获取
更多云原生知识
k8s 技术圈