
腾讯文档收集表后台重构:改造一个巨石单体!


👉目录
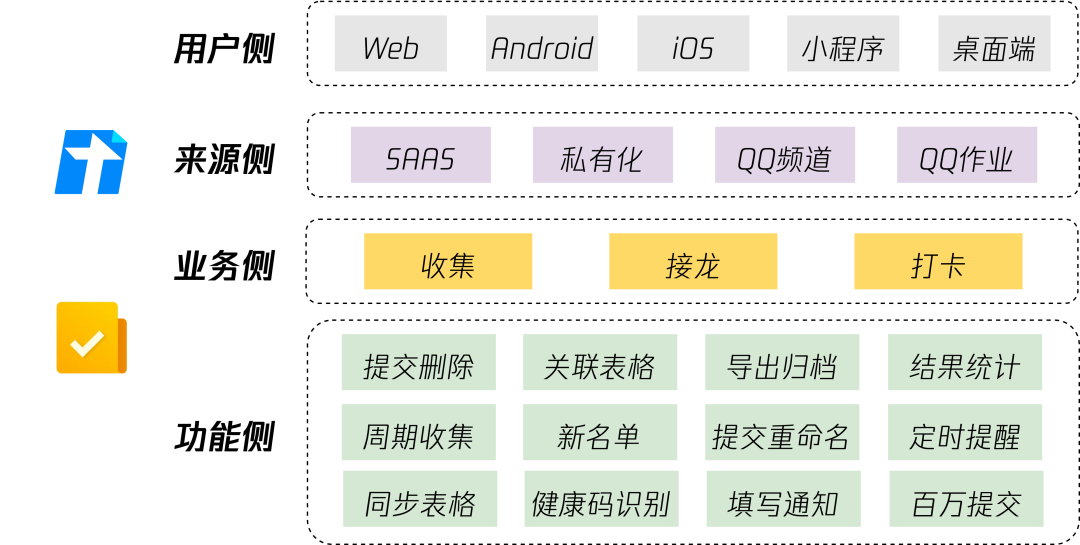
1 业务介绍
2 技术背景
3 架构设计
4 业务模块
5 服务质量
6 业务收益
- 核心服务为C++“翻译”过来的 C++ 风格单体非标 tRPC-Go 服务,代码量较大,不利于多人敏捷协作开发,业务快速迭代时期夹带发布风险高,故障爆炸半径大。
- 业务逻辑耦合严重,接口未做轻重分离,稳定性较差,性能存在瓶颈。
- 业务可观测性存在问题。
在这样的技术背景下,腾讯文档团队对收集表后台服务进行了全面的重构,实现了百万级大收集极限业务场景下提供稳定解决方案的业务收益,完善了底层技术基座,优化了产品体验,实现了开着飞机换引擎的重构效果。
01
02
2.1 老单体服务
-
核心服务是一个由 C++“翻译”过来的 C++ 风格单体非标 tRPC-Go 服务,代码量较大,不利于多人敏捷协作开发,业务快速迭代时期夹带发布风险高,故障爆炸半径大。 -
代码规范度差,不符合公司 Go 代码规范,由一个庞大的指针对象全局传递,不符合高内聚、低耦合的设计原则,导致难以观测系统运行时上下文状态。
2.2 稳定性差
-
业务逻辑耦合严重,接口未做轻重分离,边缘业务接口影响主链路失败率,无法提高核心接口成功率和被调耗时。 -
核心接口高耗时,导致热收集表并发提交场景存在较大性能瓶颈。
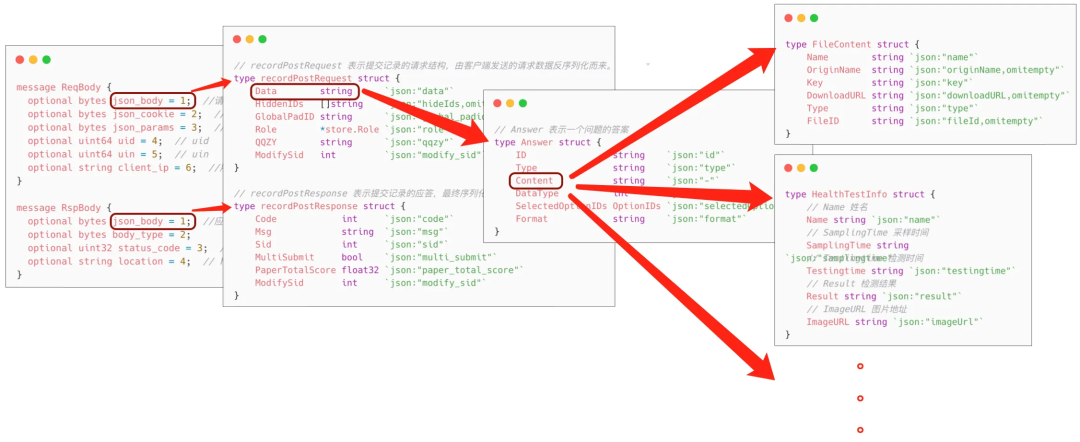
2.3 协议未约束
-
由前端定义 json 结构构造请求入参,后台未约束为强约束型 pb 结构,导致缺乏数据校验。 -
前端请求脏数据拉低后台接口平均成功率,后台无法清楚感知数据变更,导致成功率常年不达2个9。 -
原 formcollect 服务接口和一些数据结构被设计为嵌套解析。各级字段以 json 字符串存储,访问时需要层层解析,修改底层字段值后还需要层层编码。对核心数据结构的编解码代码分散在服务各处,一些数据预处理和修复逻辑也多处复制粘贴。
2.4 存储混乱
-
生产和测试存储混用,不同业务之间存储混用,导致彼此相互影响,一损俱损。 -
对于前端请求数据无脑落盘,导致存储中脏数据严重。
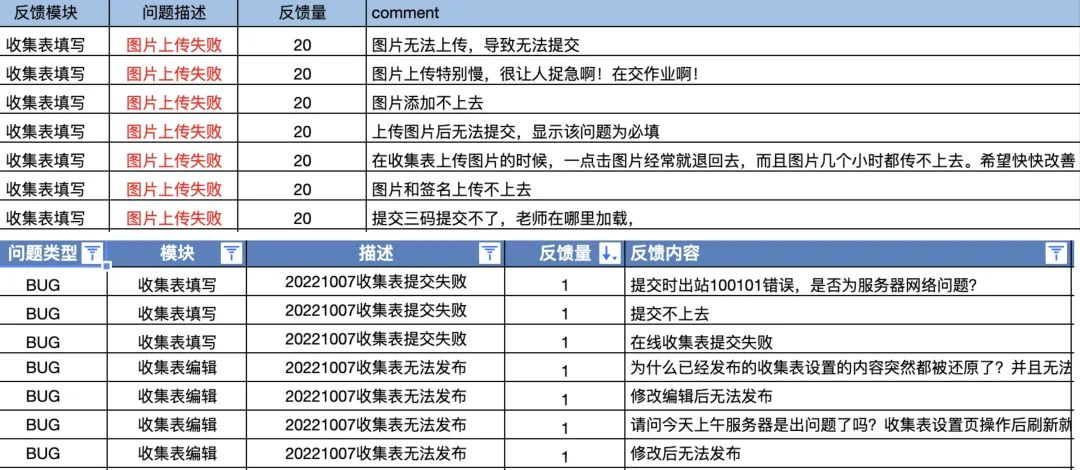
2.5 业务可观测性差
-
缺乏业务监控和日志上报,未从可观测性角度去观测系统局部以统筹整体。 -
无效告警多,且由于不正规处理方式,导致无法区分业务逻辑是否正常,缺乏人力跟进处理。 -
用户反馈频繁,但有效处理极少,常年稳居头部反馈。
-
核心链路轻重分离,非核心链路异步化拆分,降低主接口耗时。 -
松耦合设计,保证所有后台接口柔性可用。 -
严格遵循公司代码规范,模块内部高内聚,模块之间低耦合。 -
执行分级CR制度,先模块同事相互 CR 后,再交由 CR 骨干/专家进行二次 Review。 -
生产测试存储隔离,提高现网存储稳定性。
03
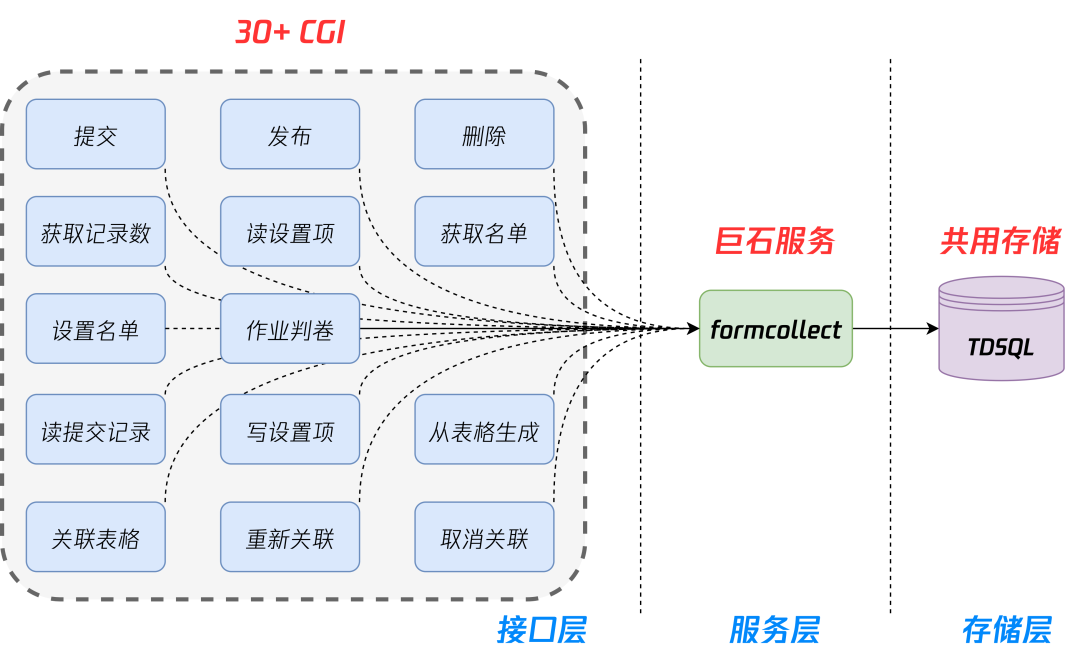
3.1 后台架构
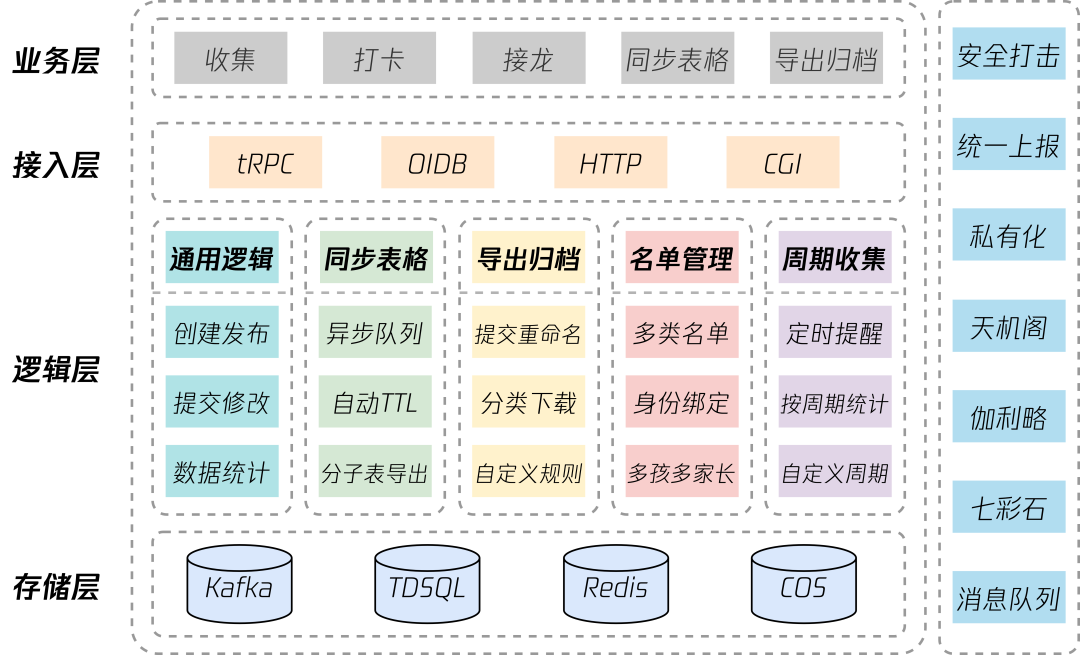
3.2 设计原则
3.2.1 研发规范
3.2.2 轻重分离
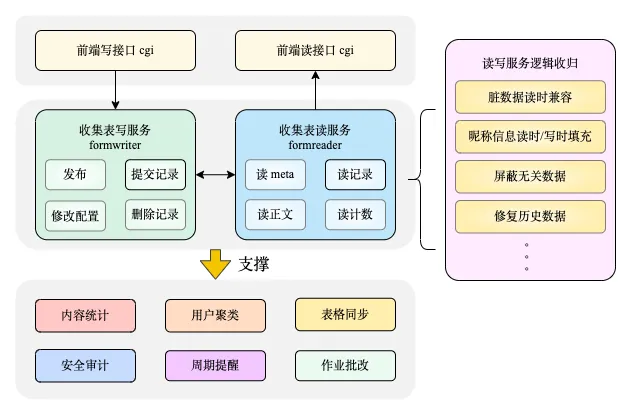
3.2.3 柔性可用
3.2.4 松耦合架构
3.2.5 存储隔离
-
按照业务模块进行垂直拆分 DB,实现物理隔离。 -
按照用户环境进行拆分 DB,生产与测试环境物理隔离,避免相互影响。 -
DB 和缓存、中间件由单分区和标准架构升级多分区集群架构,主从副本分散到不同可用区。 -
按照收集表数量水平分成10个 DB,按收集表 ID 一致性 Hash 到不同 DB 的表。 -
按照收集表 ID 一致性 Hash 到单 DB 的不同分片。
3.2.6 高度可观测
04
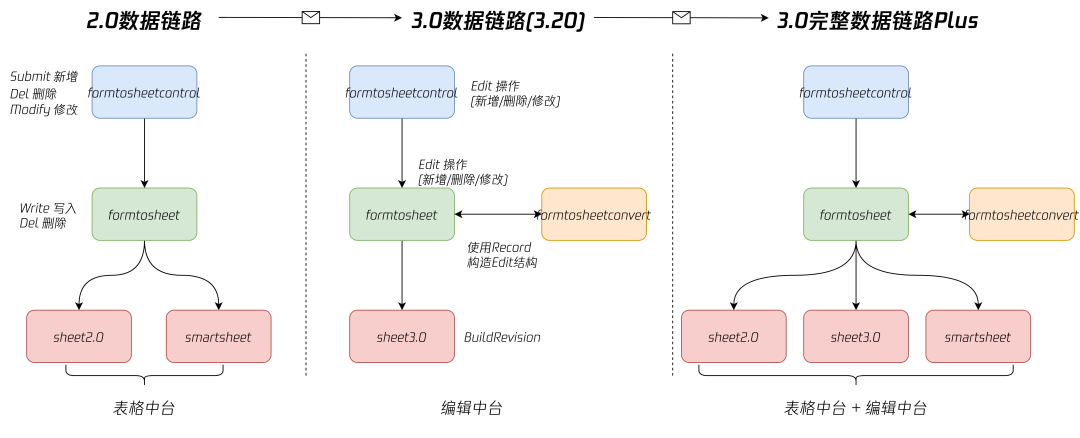
4.1 数据同步在线表格
-
用户量少,收集表少场景:业务处于发展前期,此时1.0链路同步写数据到表格即可满足业务基本诉求。 -
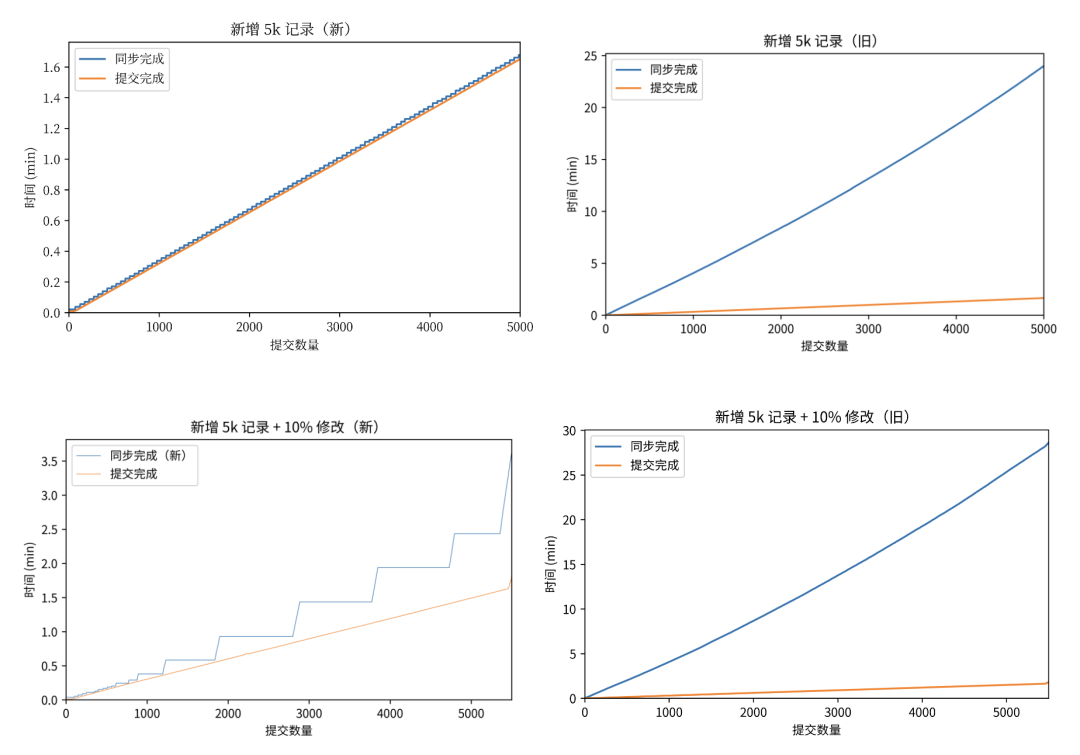
用户量上涨,单收集表提交量上涨:因为下游接口耗时提高或偶现抖动,导致同步写数据容易造成数据丢失,且单纯重试无法解决。此时1.0链路无法满足业务诉求,启动对同步写操作解耦,通过消息队列将数据交由下游消费者处理,消费者失败重试阻塞消费。 -
用户量猛增,单收集表提交量上百万:由于需要保证数据同步顺序与提交顺序一致,单收集表提交数据需经过一致性 Hash 生产到 Kafka 对应 Partition。但因为上游脏数据和下游耗时波动等原因,在热收集表场景 Kakfa 容易消费失败导致 Kafka 发生频繁 Rebalance,从而造成 Partition 内消息积压严重。
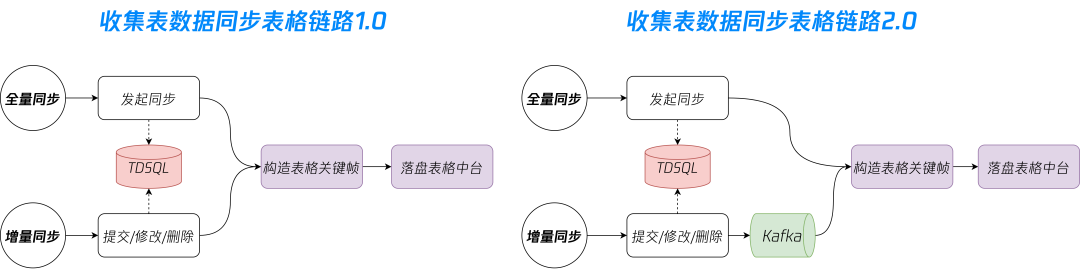
-
品类之间数据模型是异构的,收集表和表格侧的读写性能不同,大表格写的慢,且逐条同步有锁导致处理效率不高。 -
单篇大收集表数据同步消费慢,会阻塞分片队列里其他的文档数据同步,导致其他普通收集表也延迟同步。
-
没有记录流水表,没有记录逐条数据的同步中间状态,简单的立即重试失败后即丢弃,再也没有重试机会。 -
可能导致失败的原因:下游表格中台有单机限流、单文档限流;oidbpad 也有单机处理队列限制,当负载较高时,都有可能处理失败。
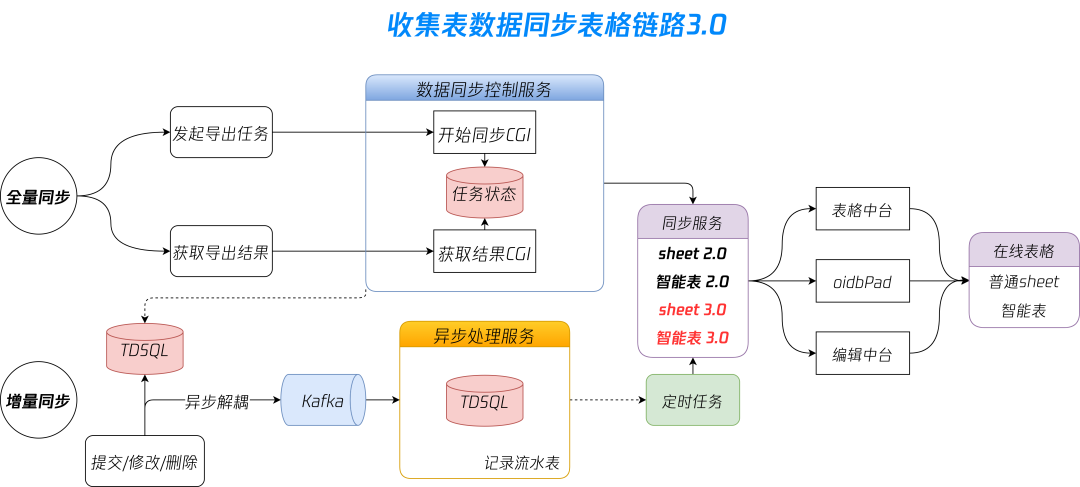
4.2 新名单重构与实现
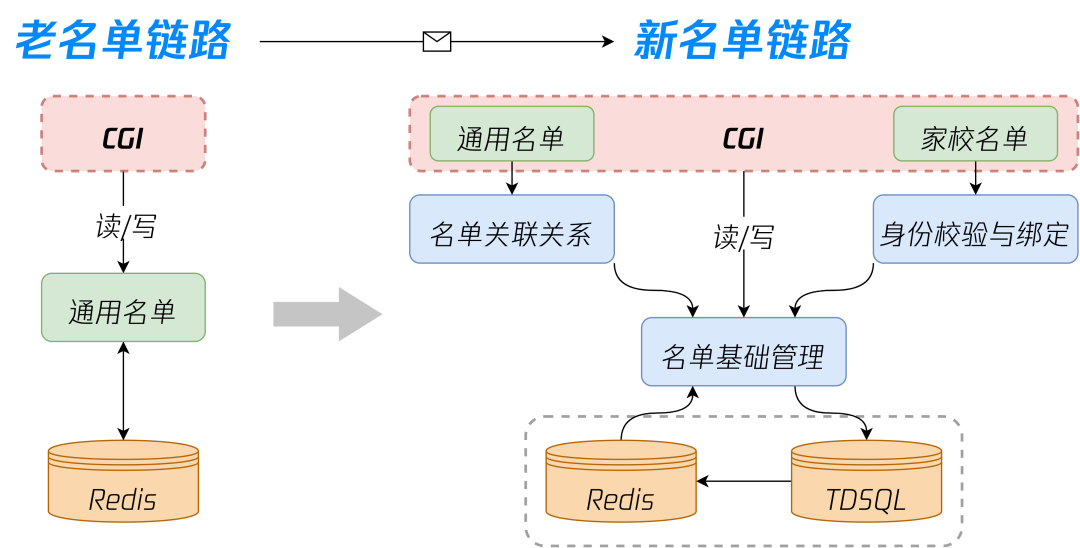
-
在复杂业务逻辑情况下,良好的架构分层和模块高内聚可以有效降低业务逻辑复杂度,如果后续增加名单类型如企业名单等,可以将开发范围控制在基础管理的增删改查和身份校验模块,对于关联关系和绑定不需涉及业务逻辑改动,有效降低对系统的理解成本。 -
对于缓存实效瞬间导致的大量请求打到存储,容易引起存储瞬间高负载情况进而导致缓存击穿,我们在收集表名单模块和基础读链路也引入了 singleflight 组件,阻塞大量重复读请求,将同时刻的并发请求聚合为单个下游请求,在单收集表高并发打开提交场景对后端存储起到很好保护作用。

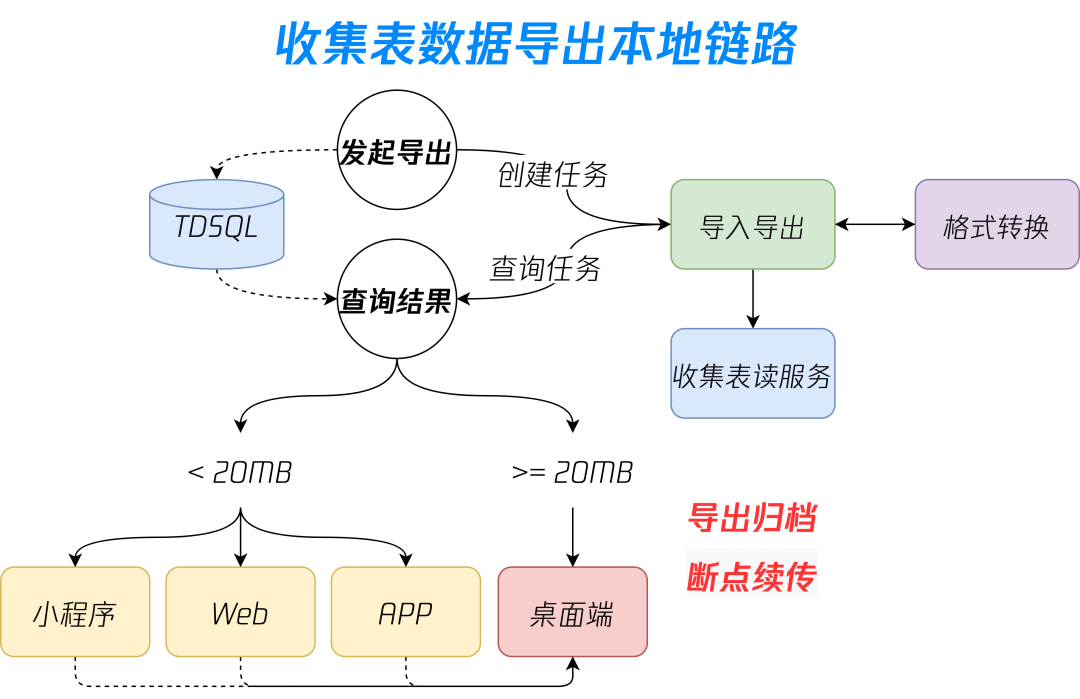
4.3 导出归档
-
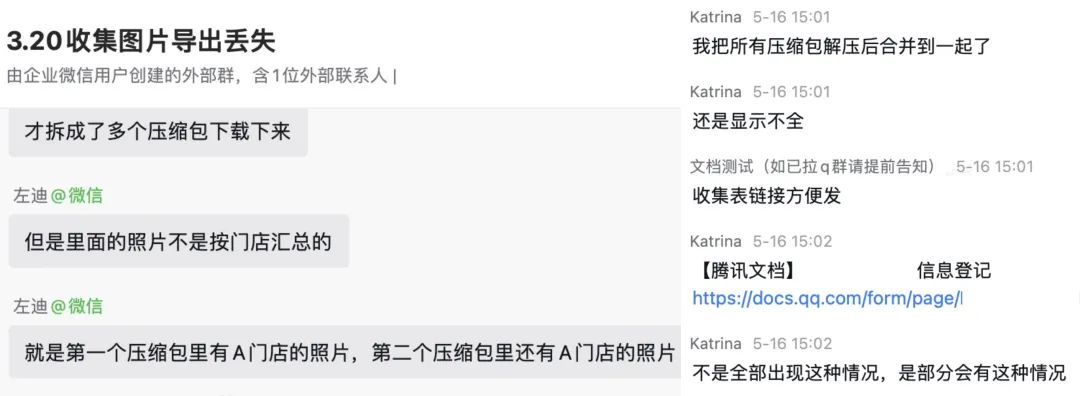
当遇到热点收集表,如挑战杯信息统计、信息截图收集等可能过百万提交场景,单收集表超大容量会给下游导入导出侧带来较大挑战,会因文件总量过大导致下游服务偶现 OOM。 -
分压缩包逻辑可能导致单个用户的多个提交附件被分到多个压缩包内,时常有用户反馈导出本地后有丢数据,实际并没有数据丢失,而是因为某些用户在当前压缩包的内容不完整而被分到其他压缩包中造成的错觉,属于用户痒点。
05
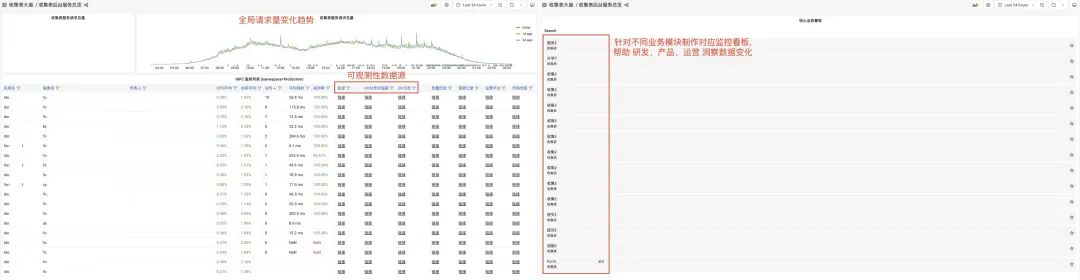
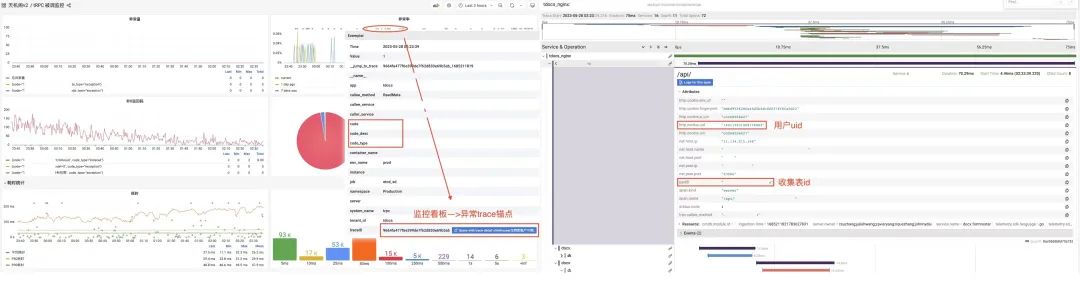
5.1 可观测性
5.2 持续规划
5.3 持续构建
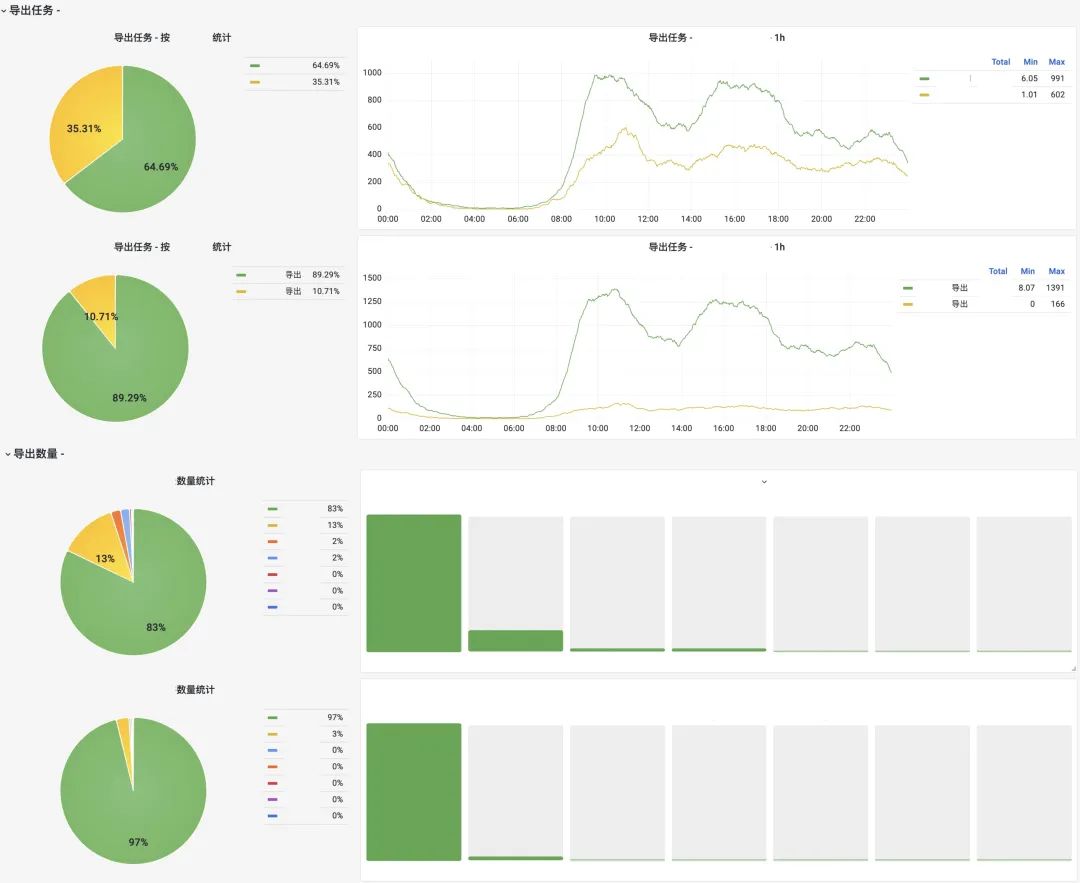
5.4 持续交付
5.5 持续运维
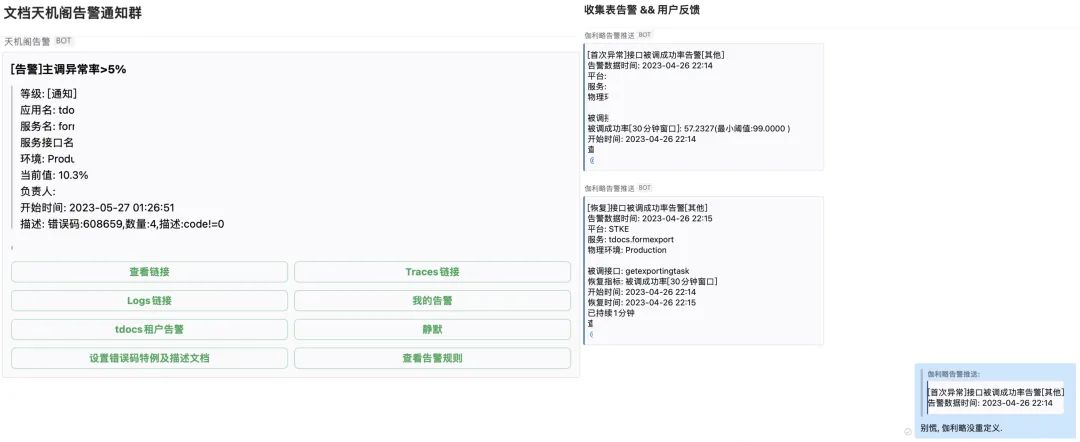
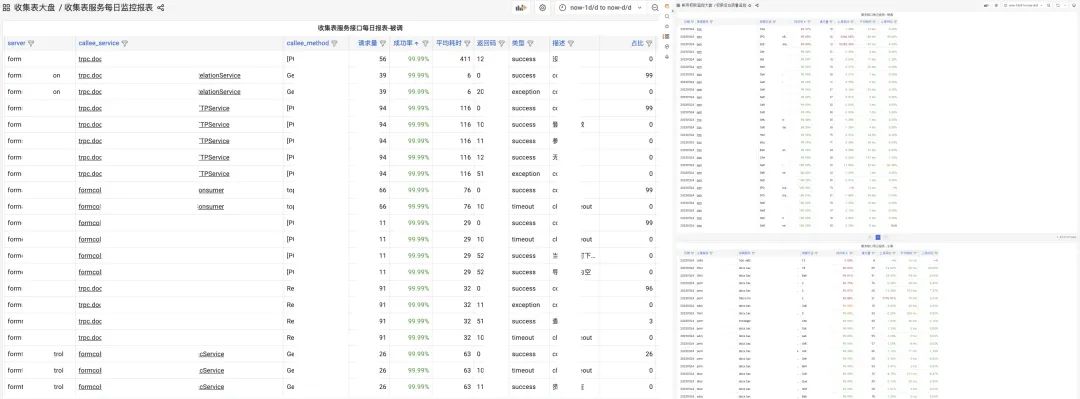
5.6 持续性能分析
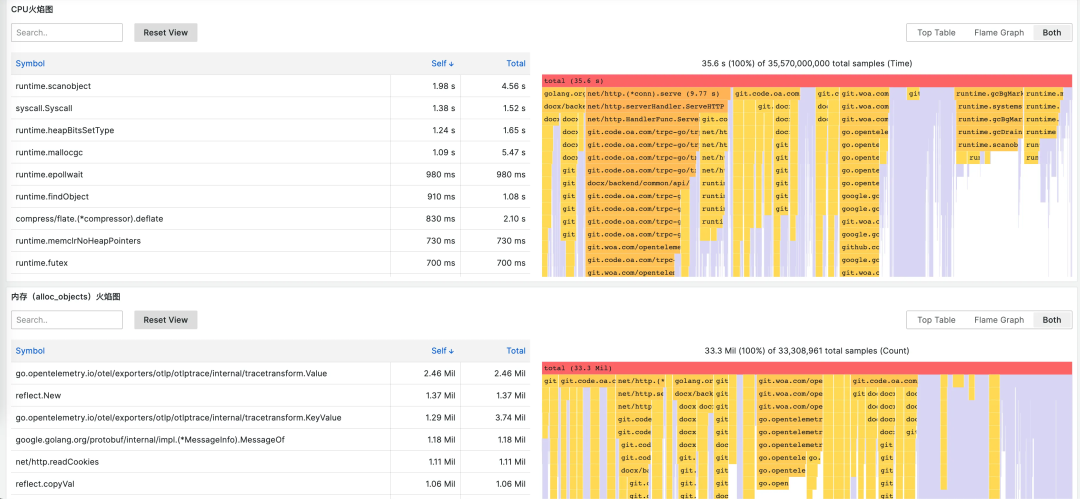
-
减少分析和故障排查的工作量。持续性能分析使不同应用程序版本和环境的性能比较变得容易。它可以减少发现性能瓶颈(包括微小瓶颈)所需的工作量,最终增加持续性能改进的可能性。 -
降低成本最显着的好处是服务器资源利用率的显著降低。此外,考虑到云环境会给大型组织带来多少成本,代码分析将直接转化为降低运营成本。得益于持续性能分析最大限度地减少了开发人员执行性能任务所花费的时间,基础设施成本变得更容易实现。 -
可扩展性和可靠性。由于不断消除性能瓶颈,整体可扩展性也可以显着提高。此外,由于瓶颈通常是资源过载等生产事故的原因,因此还可以通过显着减少瓶颈来提高可靠性。 -
从生产环境中的不良性能中恢复。当新的部署被引入生产时,并不总是双赢的局面。有时,指标在生产中表现不佳。不过可以回滚到最后一个已知的稳定部署, 并对在预生产环境中重现的问题进行根本原因分析。代码分析可以帮助查明预生产环境中的问题。但是,在生产环境中,负载等不可预测的方面仍然难以复制。持续分析使用来自当前性能不佳的系统(回滚或发布之前)的信息解决了这一挑战。它将先前 Profiling 中的数据关联起来,并快速确定性能不佳的原因。
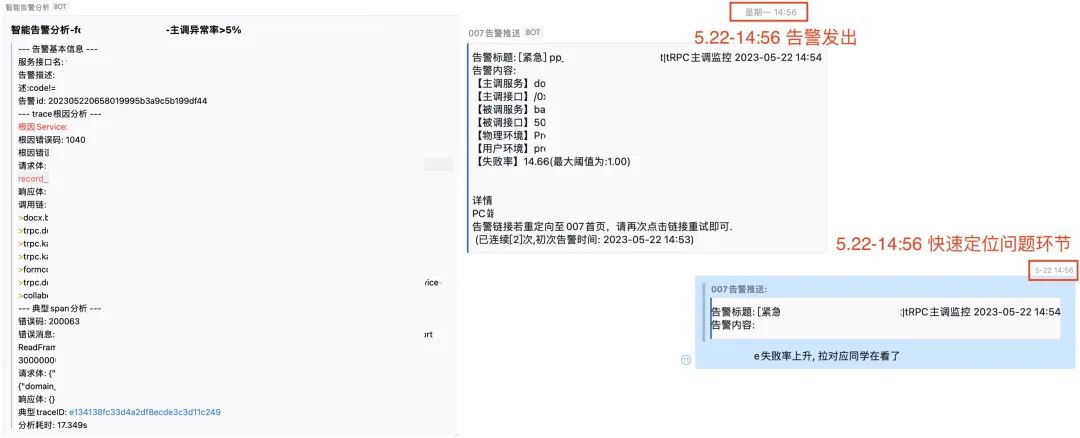
5.7 智能告警
5.8 持续反馈
06


📢📢欢迎加入腾讯云开发者社群,享前沿资讯、大咖干货,找兴趣搭子,交同城好友,更有鹅厂招聘机会、限量周边好礼等你来~

(长按图片立即扫码)





评论