
NER综述 | 命名实体识别的过去和现在
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


转载 | PaperWeekly
作者 | 周志洋
单位 | 腾讯算法工程师
方向 | 对话机器人
命名实体识别(NER, Named Entity Recognition),是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。
本文将以 BERT 作为时间节点,详细介绍 NER 历史使用过的一些方法,以及在 BERT 出现之后的一些方法。
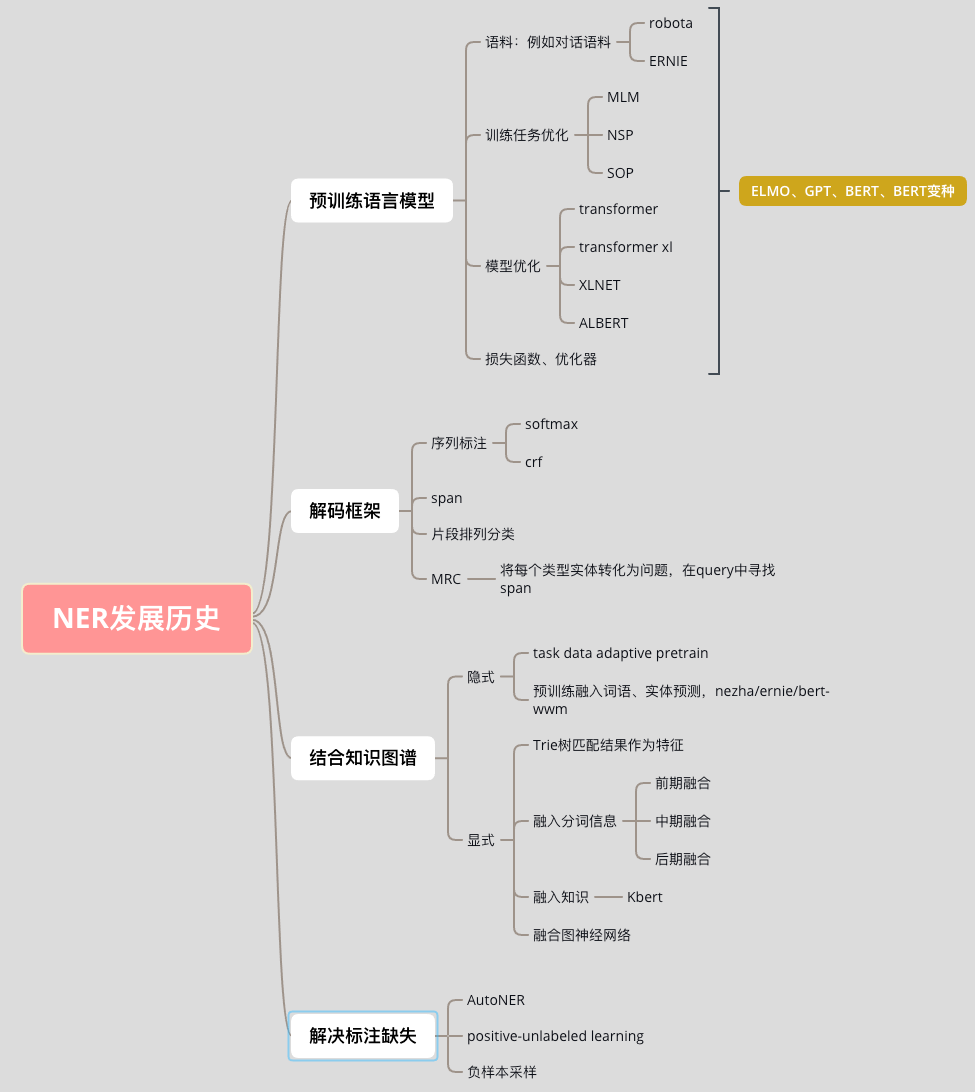
01 NER—过去篇
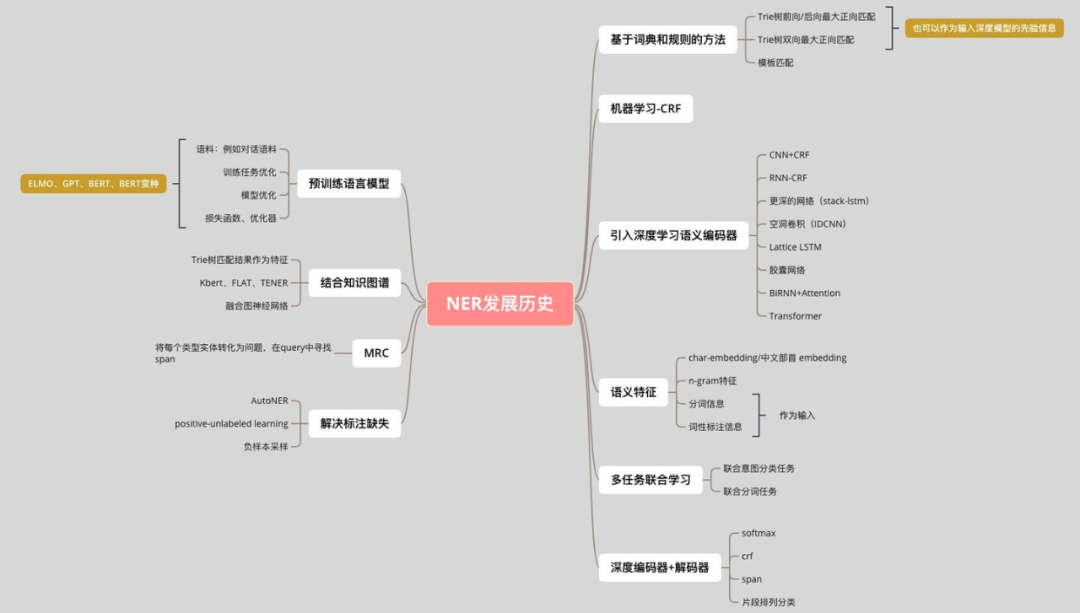
1.1 评价指标
1.2 基于词典和规则的方法
正向最大匹配 & 反向最大匹配 & 双向最大匹配。
覆盖 token 最多的匹配。
句子包含实体和切分后的片段,这种片段+实体个数最少的。
1.3 基于机器学习的方法

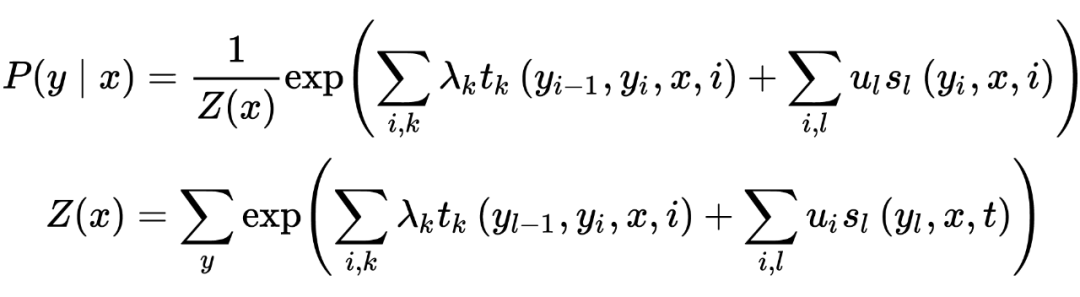
来(chao)自李航的统计学习方法
1.4 引入深度学习语义编码器
1.4.1 BI-LSTM + CRF
Bidirectional LSTM-CRF Models for Sequence Tagging [2]
文中对比了 5 种模型:LSTM、BI-LSTM、CRF、LSTM-CRF、BI-LSTM-CRF,LSTM:通过输入门,遗忘门和输出门实现记忆单元,能够有效利用上文的输入特征。BI-LSTM:可以获取时间步的上下文输入特征。CRF:使用功能句子级标签信息,精度高。
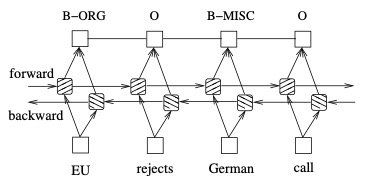
比较经典的模型,BERT 之前很长一段时间的范式,小数据集仍然可以使用。
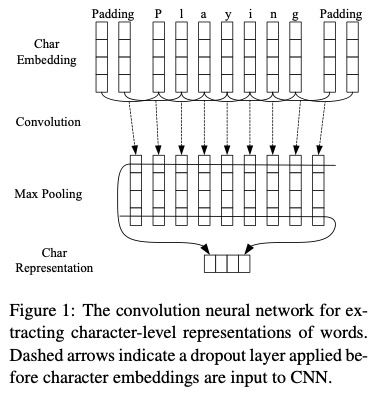
1.4.2 stack-LSTM & char-embedding
Neural Architectures for Named Entity Recognition [3]
SHIFT:将一个单词从 buffer 中移动到 stack 中;
OUT:将一个单词从 buffer 中移动到 output 中;
REDUCE:将 stack 中的单词全部弹出,组成一个块,用标签 y 对其进行标记, 并将其 push 到 output 中。

stack-LSTM 来源于:Transition-based dependency parsing with stack long-short-term memory [4]
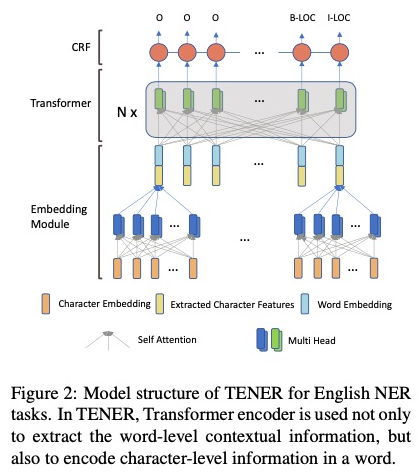
1.4.3 CNN + BI-LSTM + CRF
End-to-end Sequence Labeling via Bi-directional LSTM- CNNs-CRF [5]
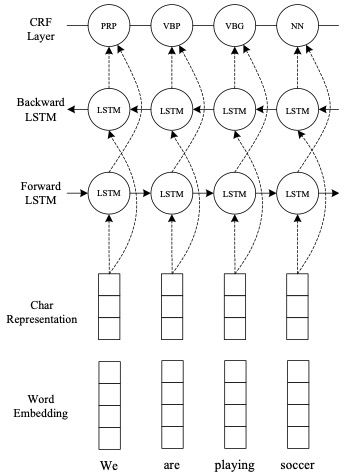
1.4.4 IDCNN
2017 Fast and Accurate Entity Recognition with Iterated Dilated Convolutions [6]
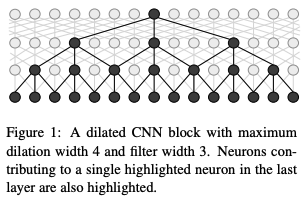
1.4.5 胶囊网络
Joint Slot Filling and Intent Detection via Capsule Neural Networks [7]
Git: https://github.com/czhang99/Capsule-NLU

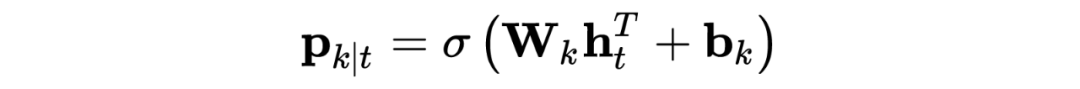


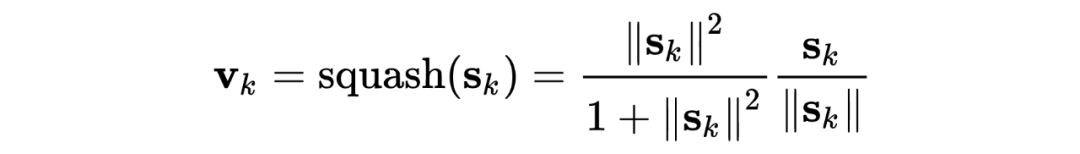
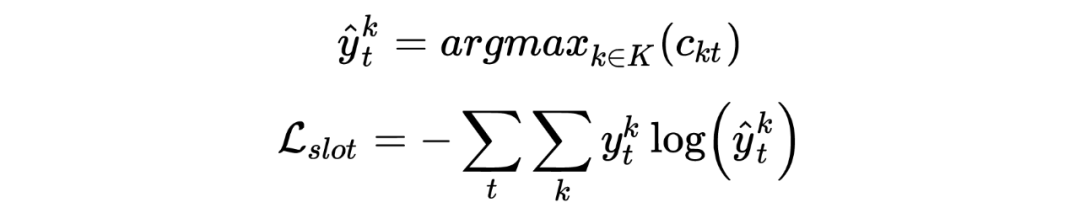
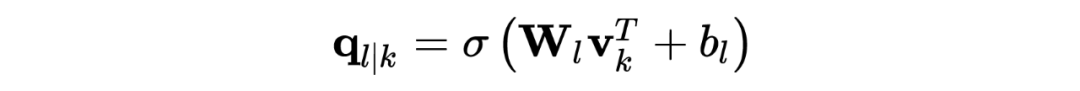
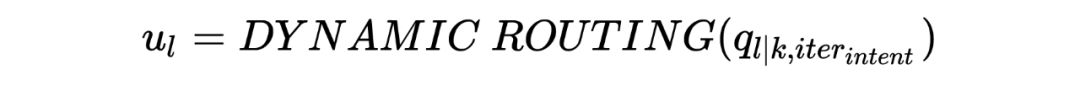
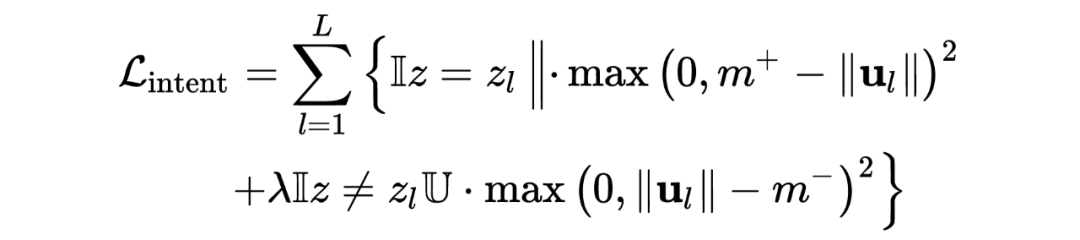
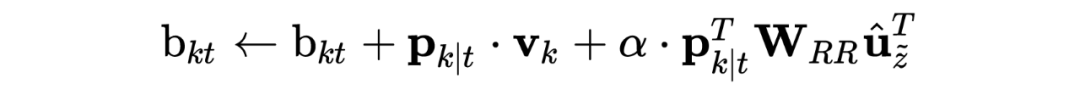
1.4.6 Transformer
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [10]
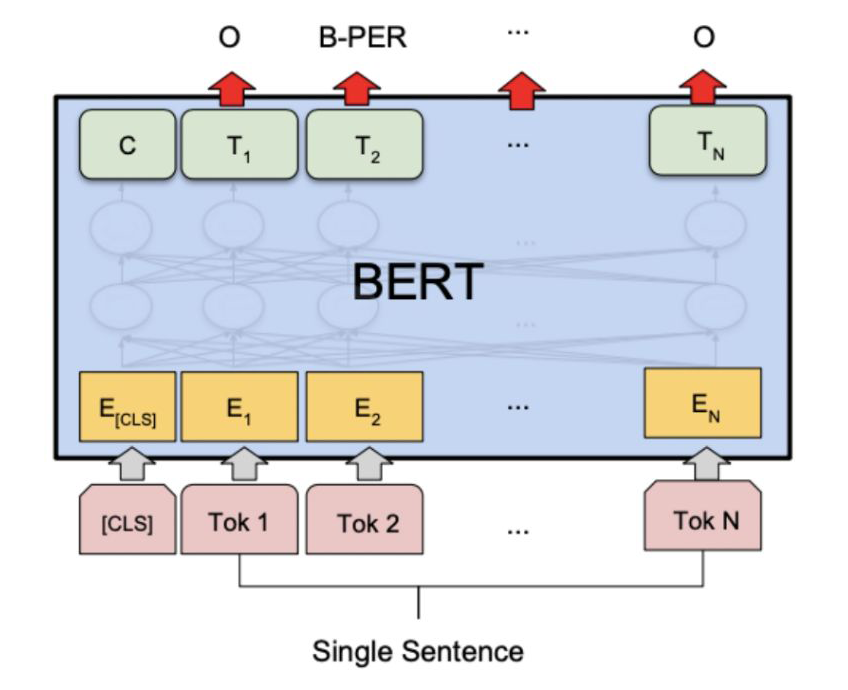
1.5 语义特征
1.5.1 char-embedding
Neural Architectures for Named Entity Recognition [9]
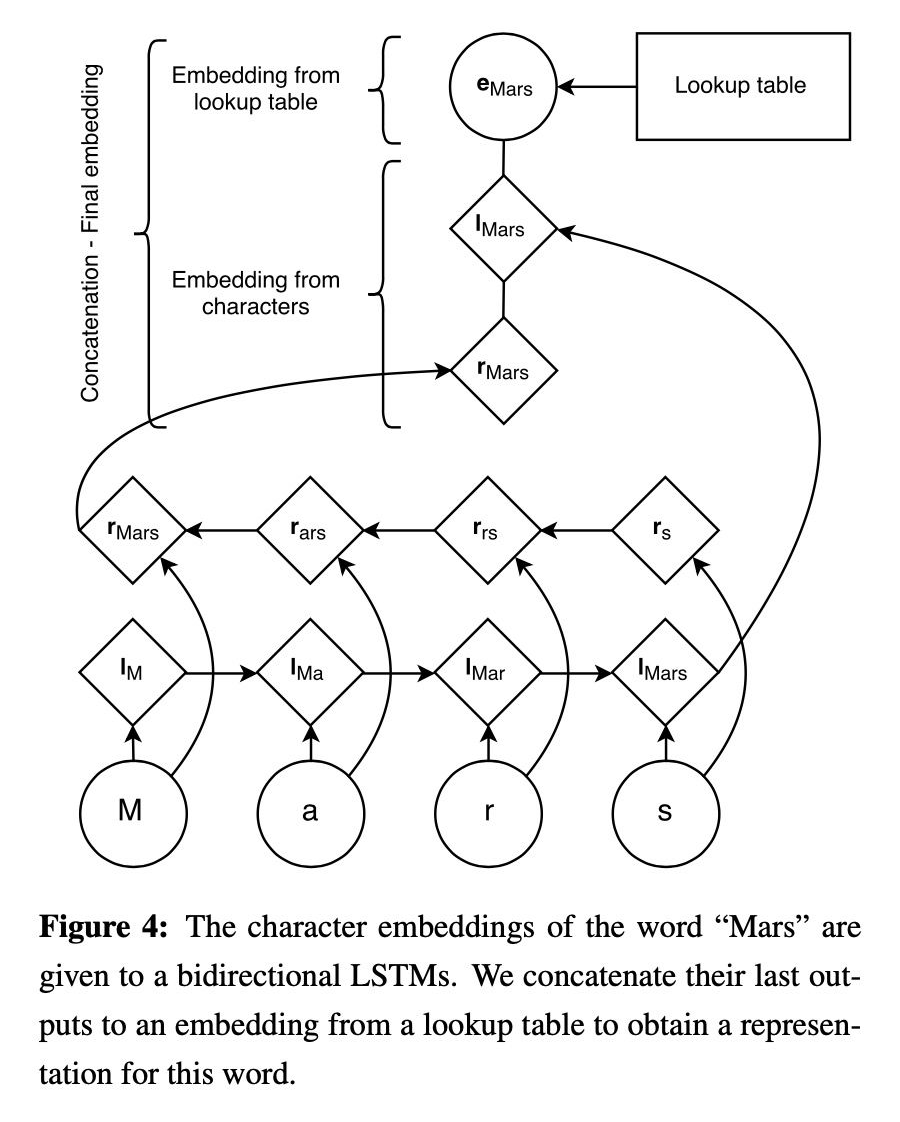
1.5.2 Attending to Characters in Neural Sequence Labeling Models
Attending to Characters in Neural Sequence Labeling Models [12]
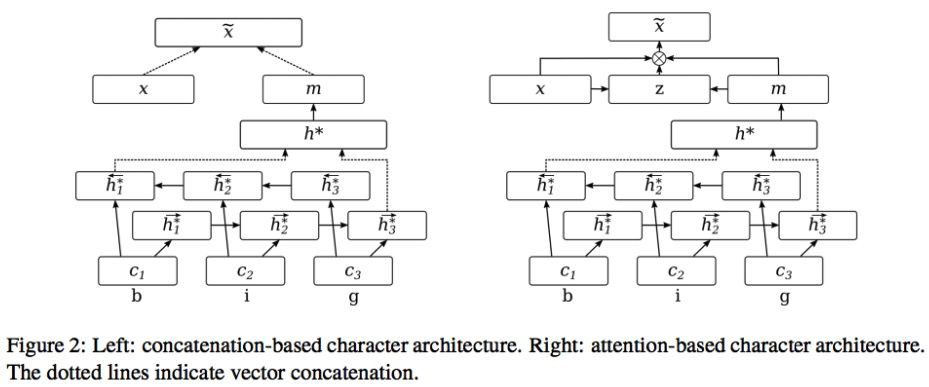
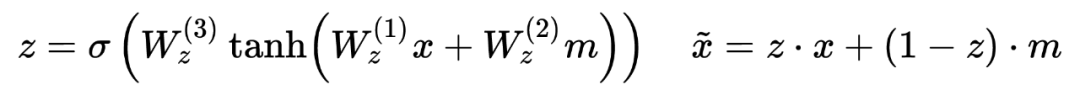
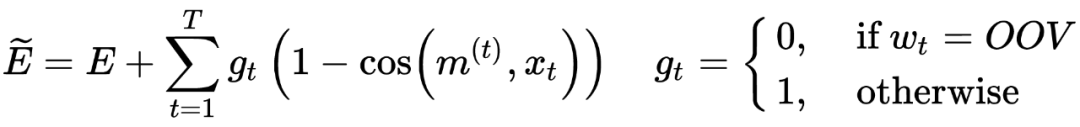
char-embedding 学习的是所有词语之间更通用的表示,而 word-embedding 学习的是特特定词语信息。对于频繁出现的单词,可以直接学习出单词表示,二者也会更相似。
1.5.3 Radical-Level Features(中文部首)
Character-Based LSTM-CRF with Radical-LevelFeatures for Chinese Named Entity Recognition [13]
1.5.4 n-gram prefixes and suffixes
Named Entity Recognition with Character-Level Models [14]
1.6 多任务联合学习
1.6.1 联合分词学习
Improving Named Entity Recognition for Chinese Social Mediawith Word Segmentation Representation Learning [15]
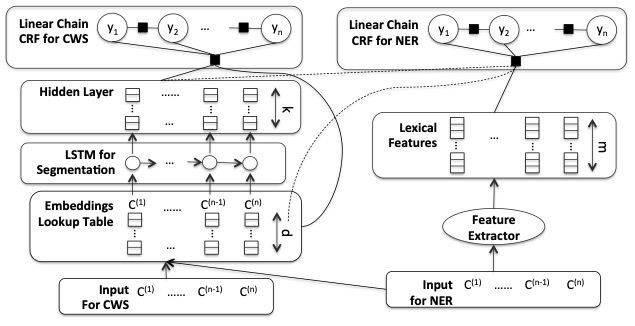
1.6.2 联合意图学习
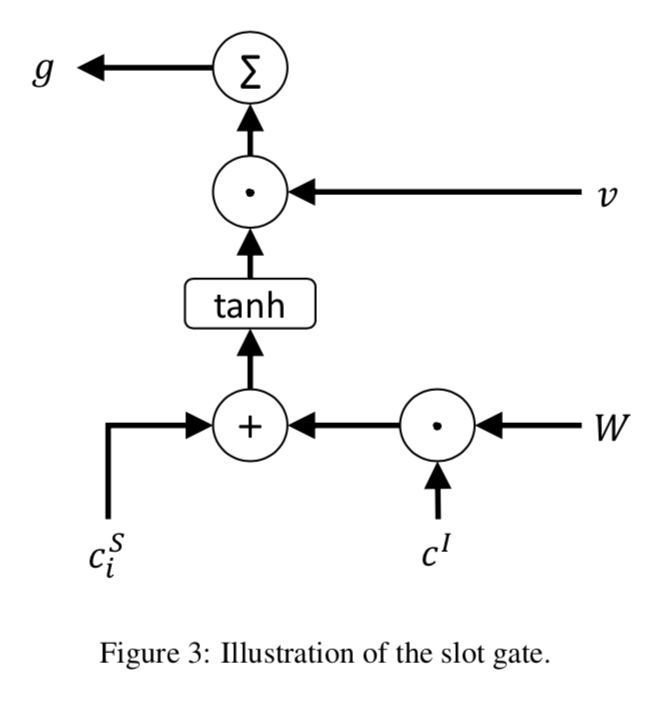
slot-gated
Slot-Gated Modeling for Joint Slot Filling and Intent Prediction [16]
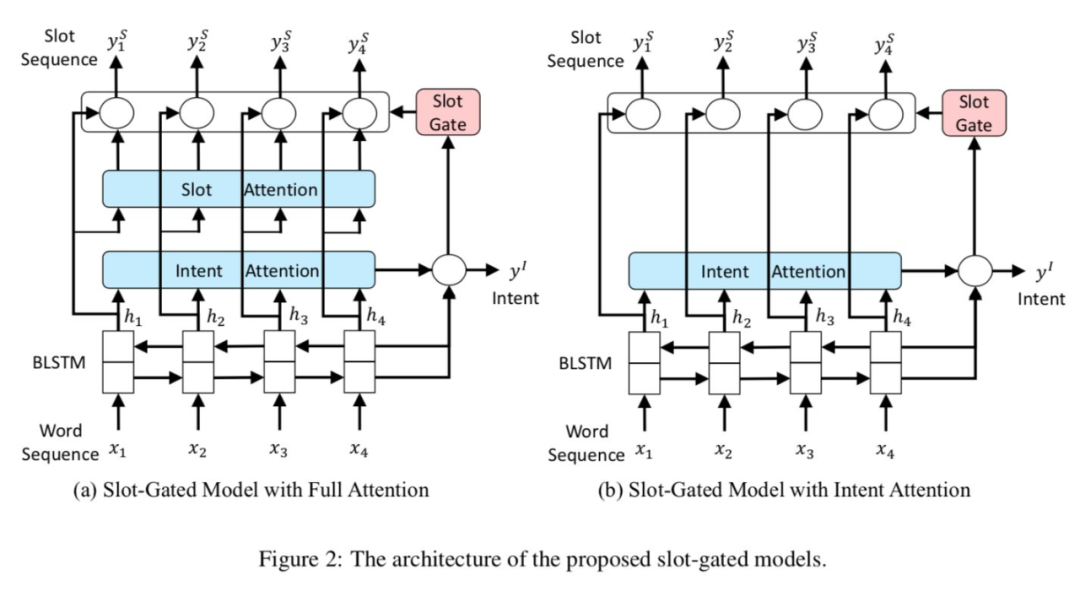
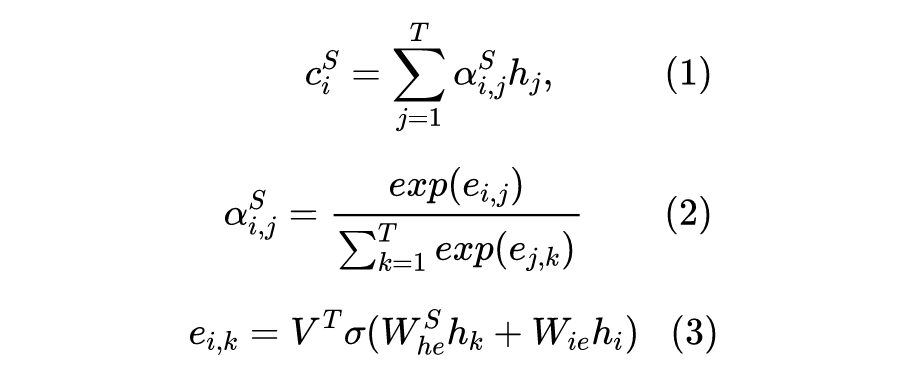
,和 一致。, 计算的是 和当前输入向量 之间的关系。作者 TensorFlow 源码 用的卷积实现,而 用的线性映射 _linear()。T 是 attention 维度,一般和输入向量一致。
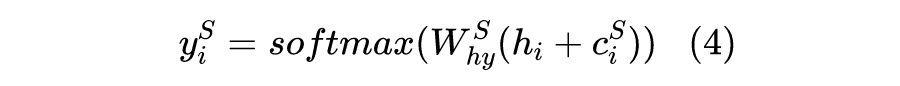
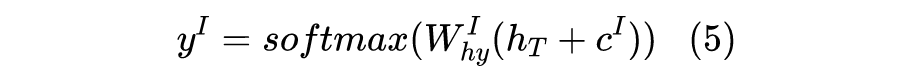

,d 是输入向量 h 的维度。 ,获得 的权重。 论文源码使用的是:
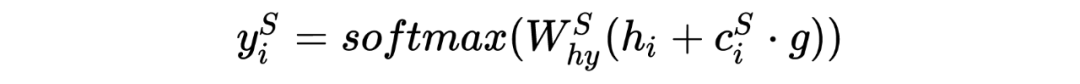
Stack-Propagation
A Stack-Propagation Framework with Token-level Intent Detection for Spoken Language Understanding [18]
Git: https://github.com/%20LeePleased/StackPropagation-SLU
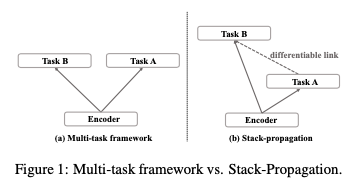
它是区别于多任务,不同的任务通过 stack(级联?)的方式一起学习优化。
Token intent(意图阶段):假设每个 token 都会有一个意图的概率分布(标签是句子的意图,通过大量数据训练,就能够学到每个 token 的意图分布,对于每个意图的‘偏好’),最终句子的意图预测通过将每个 token 的意图预测结果投票决定。 Slot Filling:输入包含下面三部分:,其中 是上一阶段 token intent 的预测结果的 intent id,然后经过一个意图向量矩阵,转化为意图向量,输入给实体预测模块,解码器就是一层 lstm+softmax。
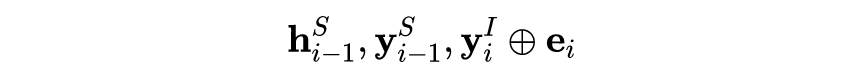
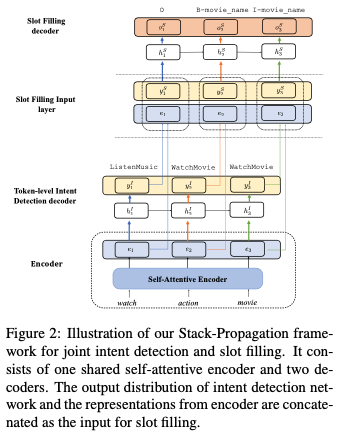
1.6.3 BERT for Joint Intent Classification and Slot Filling
BERT for Joint Intent Classification and Slot Filling [19]
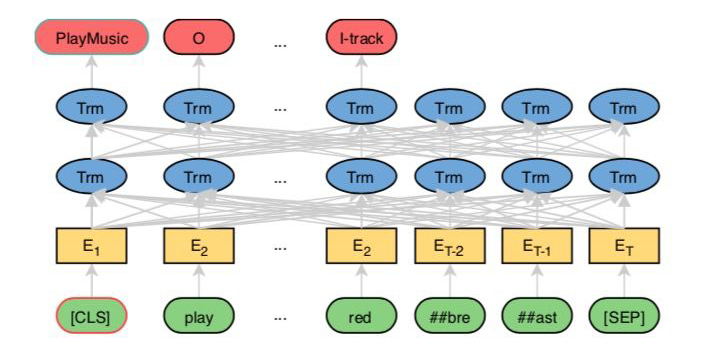
这里归类的解码器似乎也不太合适,但是也找不到好的了。
SpanNER: Named EntityRe-/Recognition as Span Prediction [20] Coarse-to-Fine Pre-training for Named Entity Recognition [21]


token“林”预测为 start,“伟”预测为 end,那么“林丹对阵李宗伟”也可以解码为一个实体。
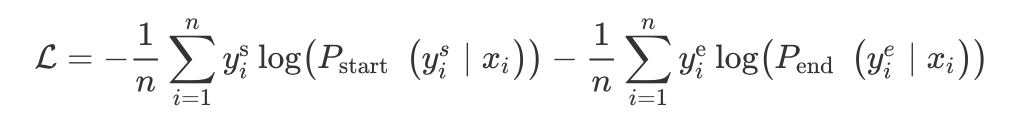
2.1.2 MRC(阅读理解)
A Unified MRC Framework for Named Entity Recognition [22]

对于不同的实体,需要去构建问题模板,而问题模板怎么构建呢?人工构建的话,那么人构建问题的好坏将直接影响实体识别。 增加了计算量,原来输入是句子的长度,现在是问题+句子的长度。 span 的问题,它也会有(当然 span 的优点它也有),或者解码器使用 crf。
2.1.3 片段排列+分类
Span-Level Model for Relation Extraction [23] Instance-Based Learning of Span Representations [24]

片段的编码,pooling 或者 start 和 end 向量的拼接,一般比较倾向于后者。 片段的长度,然后通过 embedding 矩阵转为向量。 句子特征,例如 cls 向量。
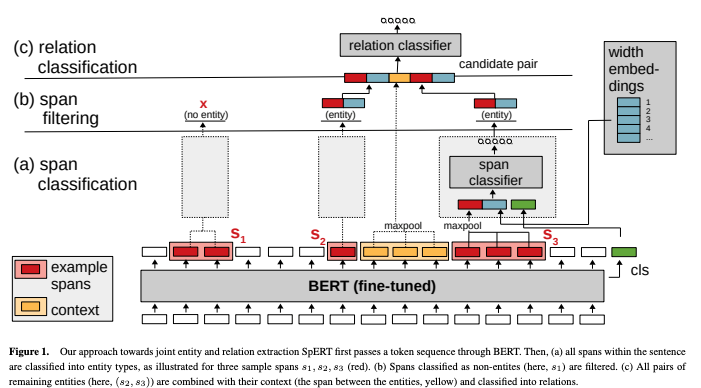
SpERT:Span-based Joint Entity and Relation Extraction with Transformer Pre-training [25]
对于长度为 N 的句子,如果不限制长度的话,会有 N(N+1)/2,长文本的话,片段会非常多,计算量大,而且负样本巨多,正样本极少。
如果限制候选片段长度的话,那么长度又不灵活。

2.2.2 显示融合
Trie树匹配结果作为特征
融合分词信息(multi-grained: fine-grained and coarse-grained)
multi-grained 翻译应该是多粒度,但是个人认为主要是融入了分词的信息,因为 bert 就是使用字。
前期融合:
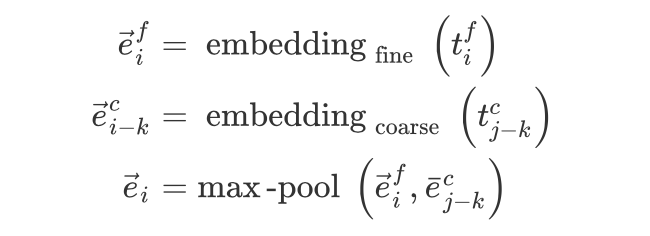
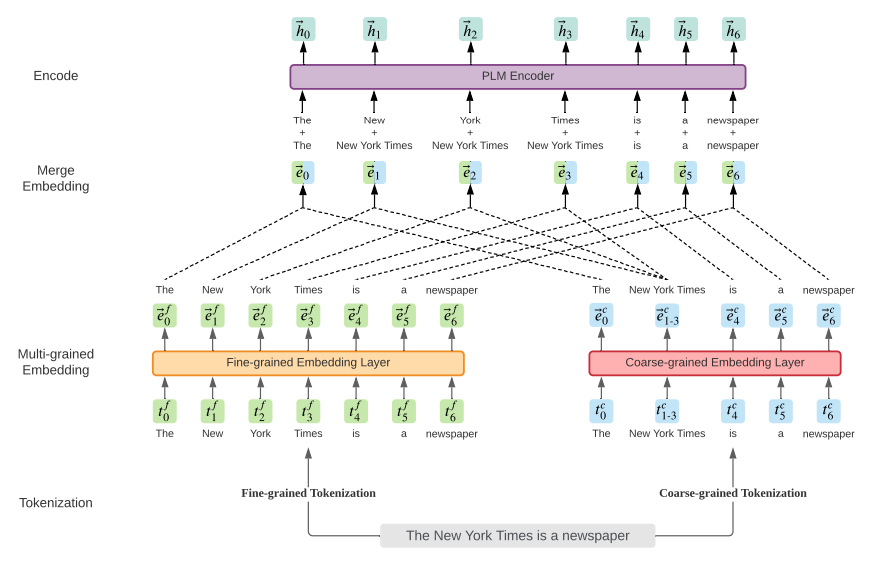
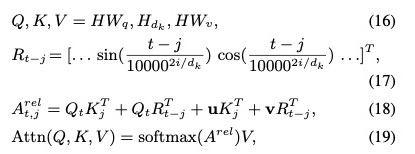
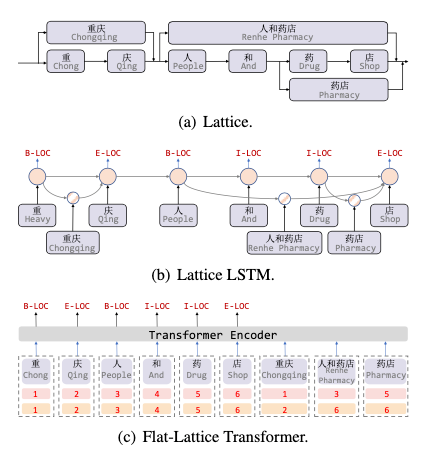
中期融合
ZEN: Pre-training Chinese Text Encoder Enhanced by N-gram Representations [30]
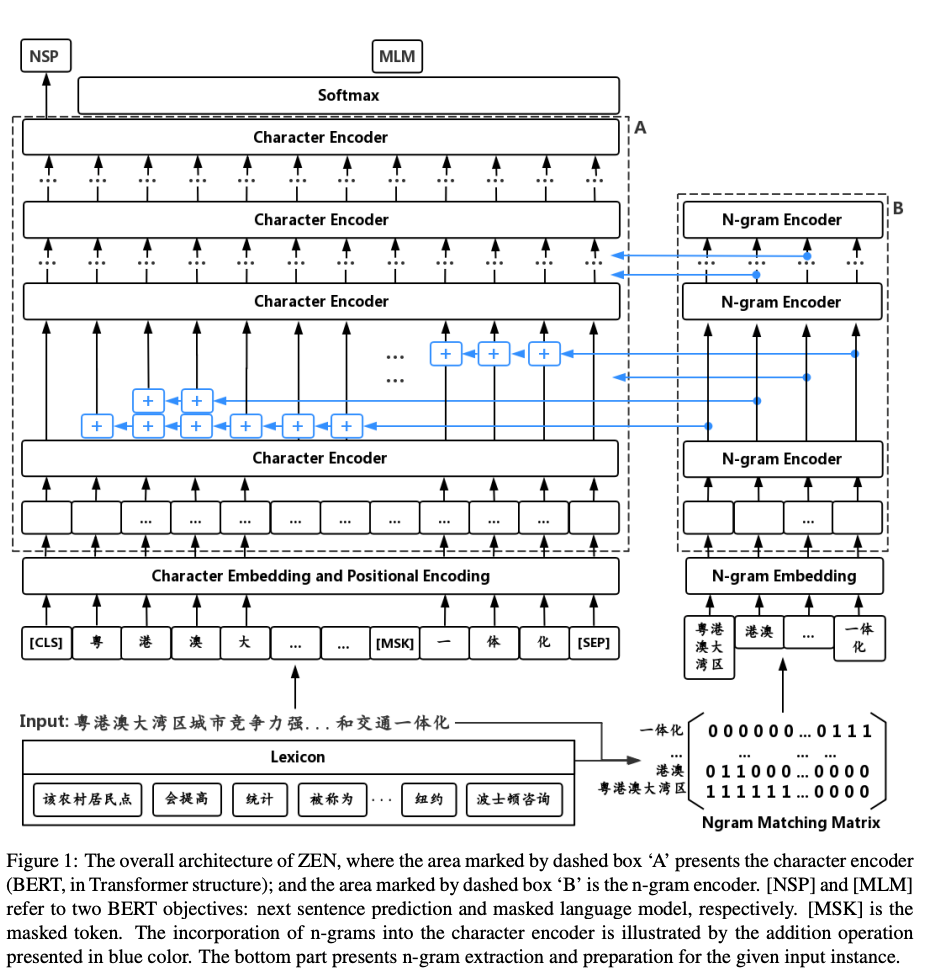
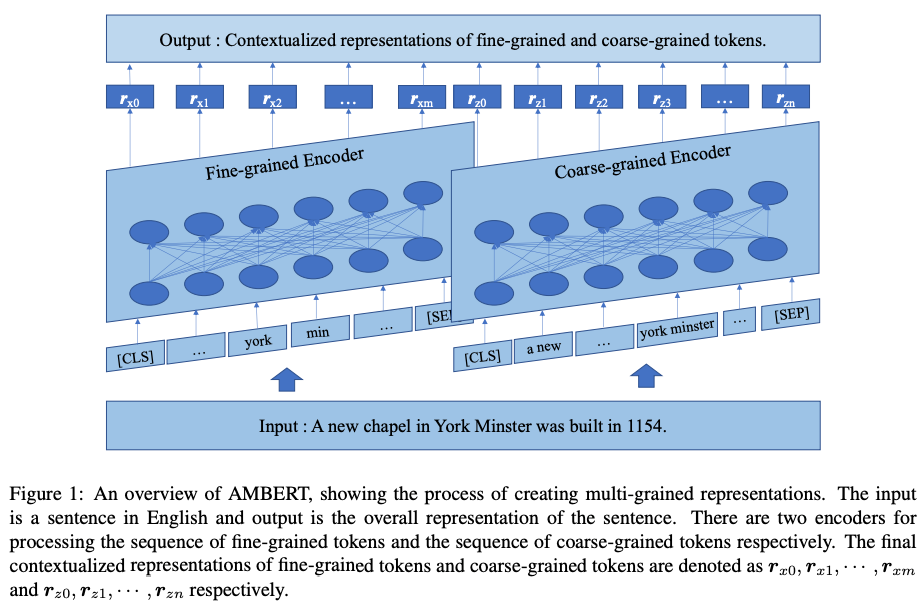
融合知识图谱信息
K-BERT: Enabling Language Representation with Knowledge Graph [32]
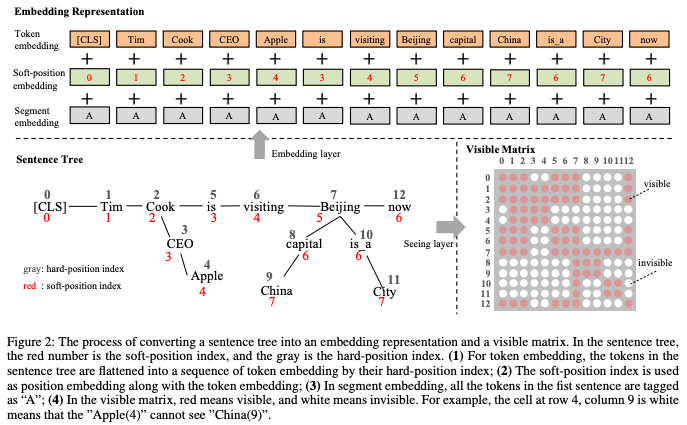
位置编码,原始句子的位置保持不变,序列就不变,同时对于插入的“CEO”、"Apple"和“cook”的位置是连续,确保图谱知识插入的位置。 同时对于后面的 token,“CEO”、"Apple属于噪声,因此利用可见矩阵机制,使得“CEO”、"Apple"对于后面的 token 不可见,对于 [CLS] 也不可见。
2.3 标注缺失
2.3.1 AutoNER
Learning Named Entity Tagger using Domain-Specific Dictionary [33]
Better Modeling of Incomplete Anotations for Named Entity Recognition [34]
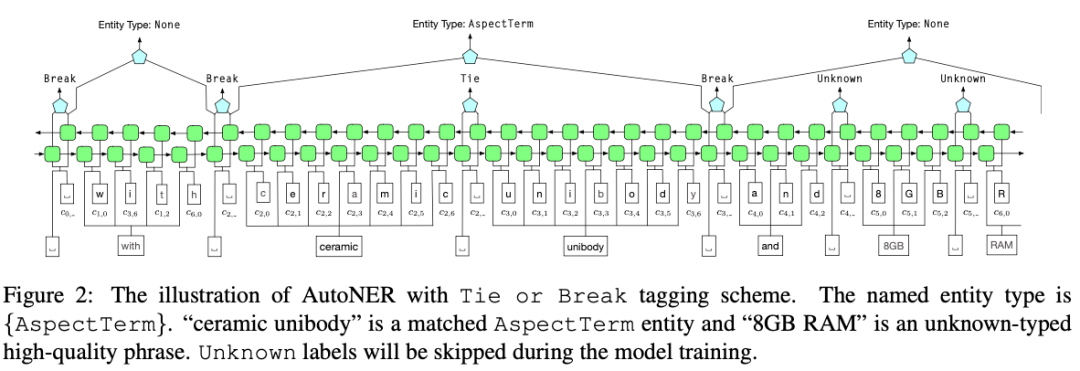
2.3.2 PU learning
Distantly Supervised Named Entity Recognition using Positive-Unlabeled Learning [37]
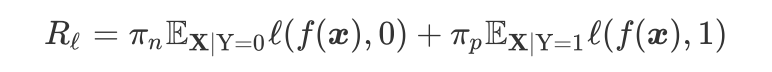
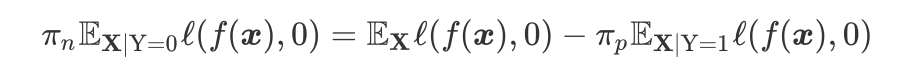
2.3.3 负采样
Empirical Analysis of Unlabeled Entity Problem in Named Entity Recognition [38]
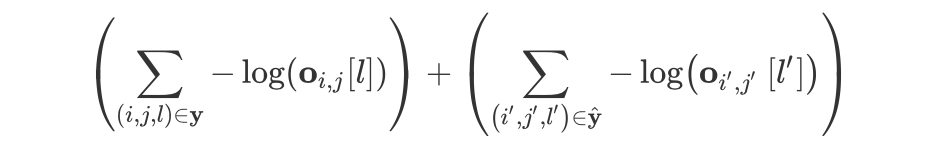
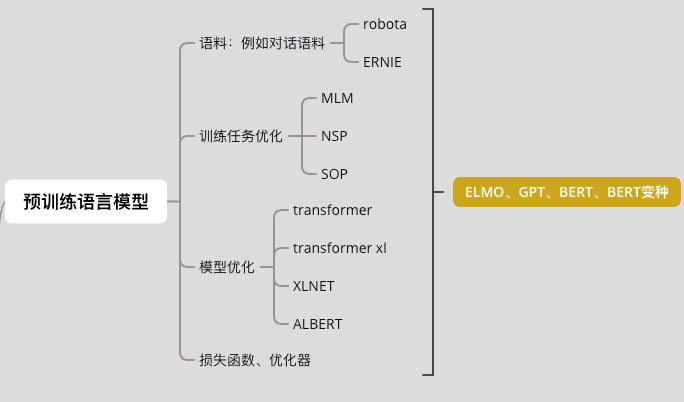
2.4 预训练语言模型
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!