
手把手教你抓取链家二手房详情页的全部数据
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。
一、前言
前几天在Python白银交流群大家在交流链家网二手房详情页数据的抓取方法,如下图所示。关于首页的抓取,上一篇文章已经说明了,手把手教你抓取链家二手房首页的全部数据。
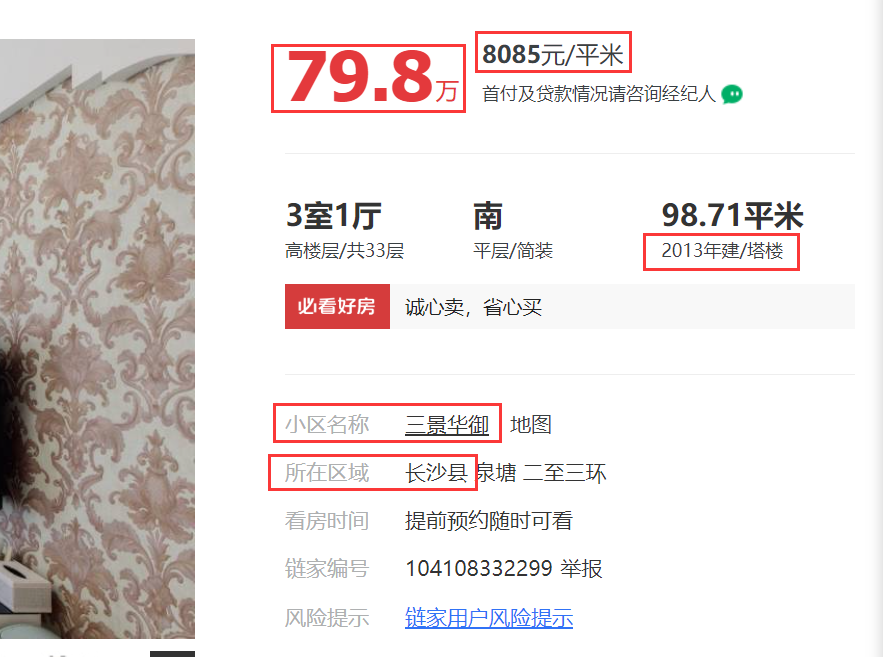
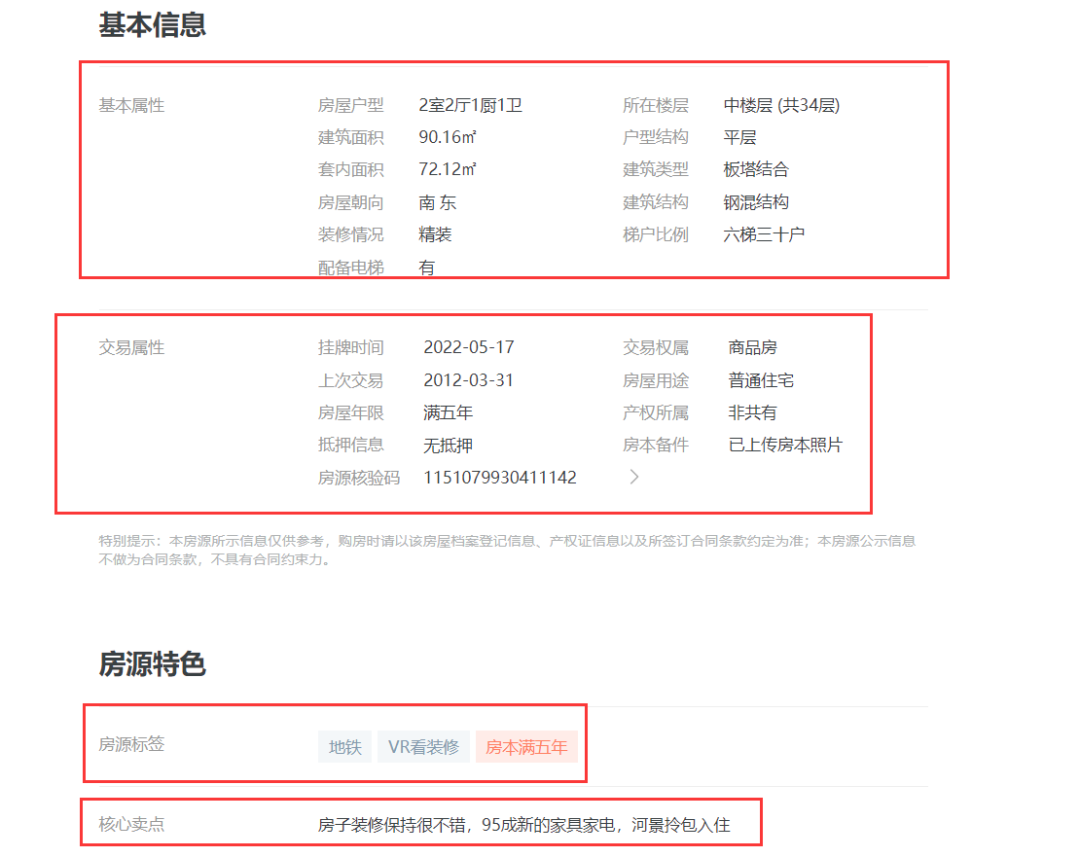
这里想要上图中红色圈圈里边的信息,东西还是很多的。
二、实现过程
这里群友【🇳 🇴 🇳 🇪】大佬给了两份代码,分享给大家。
方法一
这个方法需要配合详情页一起抓取,首先你需要拿到详情页的url,之后才可以使用下方的代码进行抓取,详情页爬虫的代码如下:
import os
import re
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
class HousePrices:
# dir='c:\\链家房价'#D盘
dir = 'C:\\Users\\pdcfi\\Desktop\\链家房价' # D盘
start_url = 'https://cs.lianjia.com/ershoufang/pg1/'
headers = {
'Host': 'cs.lianjia.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'Cookie': 'select_city=110000; lianjia_ssid=74f665ec-d197-4606-8984-13a060a7a339; lianjia_uuid=dcc2c7eb-d4ec-4c91-976e-e47240db8e8f; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1622355363; Hm_lpvt_9152f8221cb6243a53c83b956842be8a=1622355363; _jzqa=1.4299380220423246000.1622355363.1622355363.1622355363.1; _jzqb=1.1.10.1622355363.1; _jzqc=1; _jzqckmp=1; UM_distinctid=179bbea4504567-0d4c995a89d9998-1a387940-1aeaa0-179bbea4505537; CNZZDATA1253477573=963747252-1622352689-%7C1622352689; _qzja=1.1539867698.1622355363107.1622355363107.1622355363107.1622355363107.1622355363107.0.0.0.1.1; _qzjb=1.1622355363107.1.0.0.0; _qzjc=1; _qzjto=1.1.0; CNZZDATA1254525948=602998940-1622352085-%7C1622352085; CNZZDATA1255633284=1358575326-1622349996-%7C1622349996; CNZZDATA1255604082=2083114816-1622352761-%7C1622352761; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22179bbea4708260-00a97d6b6709128-1a387940-1764000-179bbea470986%22%2C%22%24device_id%22%3A%22179bbea4708260-00a97d6b6709128-1a387940-1764000-179bbea470986%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; sajssdk_2015_cross_new_user=1; _smt_uid=60b32da3.1b302184; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiZThkMDBlMzVkN2E3MDg0YTkyYWU5YzhiNzA1NzYxNjQ3YzM3NjY5NDhhNzE3NjdmYmUxM2UyZmM4MmE3ZjUyMzEwNmMyZjU3MzRkNmIzMjM0ZGMxNjkyOWM4MmQ2MzhiNDZlZWMwZGQ0NWYyNGViNjE3M2YyZmQ1ODc1YmVlZjkyN2FiNGU3YTVmOWM5MjEzMmY0ZWQ0M2QxZDU0NmQwMzVlNmUzODk4NTQ5MmI2MzAyNzY5YzIwZmE4ZjQyNzZlM2NjYzI0NjZmMjE4MGZiMWIxOTA2ZjU0ODA2NjIxZWU3NWQ5NWZlMWVmNzZhYWU1ODI5NDhjYjUxYTcyZTM3Y2ZlNTE4OTZjZDg3NGYyNDJlMTExZDhlN2E1Y2YwMWU5NGVmMTlmN2E1ZmI1M2MwZWJkZjgwMzAxOTM4ZjNlNzFkZDE4MjVjZjUxNjgyYWJiOWYwMTM1ZDhiYTJiMzgwYlwiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCIxODE5MDhkYVwifSIsInIiOiJodHRwczovL2JqLmxpYW5qaWEuY29tL2Vyc2hvdWZhbmcvcGcxLyIsIm9zIjoid2ViIiwidiI6IjAuMSJ9',
'Upgrade-Insecure-Requests': '1',
'Cache-Control': 'max-age=0'
}
def __init__(self):
if not os.path.exists(self.dir):
os.makedirs(self.dir)
print(self.dir + '文件夹初始化完成')
self.f = open(self.dir + '\\长沙二手房信息.csv', mode='a+', encoding='utf-8', newline='')
def get_page(self):
df = pd.read_csv('detail_page_url.csv')
df.drop_duplicates(keep='first', inplace=True)
url_list = df['detail_url'].values.tolist()
url_list = url_list[415:]
for index, url in enumerate(url_list):
print(index, url)
yield requests.get(url=url, headers=self.headers)
def get_house_info(self):
count = 1
for i in self.get_page():
house_info = BeautifulSoup(i.text, 'lxml')
house_name = house_info.select('.communityName a')[0].get_text(strip=True)
build_year = house_info.select('div.noHidden')[0].get_text(strip=True)
region = house_info.select('.areaName span a')[0].get_text(strip=True)
house_price = house_info.select('.total')[0].text + '万'
unit_price_value = house_info.select('.unitPriceValue')[0].text
house_intro_content = house_info.select('.introContent li')
intro_lst = [i.get_text('#', strip=1).split('#')[1] for i in house_intro_content]
try:
house_label_list = []
house_label = house_info.select('.tags')[0].get_text(strip=True)
# print(house_label)
# for i in house_label:
# i = i.strip()
# if i != '':
# house_label_list.append(i)
# house_label = ''.join(i for i in house_label_list)
# print(house_label)
except:
house_label = ''
house_data = [count, house_name, build_year, region, house_price, unit_price_value] + intro_lst + [house_label]
count += 1
yield house_data
def save_excel(self):
num = 1
excel_headers = ['序号', '小区名称', '建筑时间', '区域', '总价', '单价', '房屋户型', '所在楼层', '建筑面积', '户型结构', '套内面积', '建筑类型',
'房屋朝向', '建筑结构', '装修情况', '梯户比例', '供暖方式', '配备电梯', '挂牌时间', '交易权属', '上次交易', '房屋用途', '房屋年限', '产权所属',
'抵押信息', '房本备件', '标签']
csv_file = csv.writer(self.f)
csv_file.writerow(excel_headers)
house_data = self.get_house_info()
for item in house_data:
csv_file.writerow(item)
num += 1
print(item)
print('第{}条数据写入完成'.format(num))
print('写入完毕')
def __del__(self):
self.f.close()
if __name__ == '__main__':
lj = HousePrices()
lj.save_excel()
运行之后,结果如下图所示:

方法二
这里他是使用Scrapy框架抓取的,代码如下所示:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Created by iFantastic on 2022/6/7
import re
import scrapy
from scrapy.cmdline import execute
class LJ_spiders(scrapy.Spider):
name = 'lj'
start_urls = ['https://cs.lianjia.com/ershoufang/pg1/']
def parse(self, response, **kwargs):
for info in response.xpath('//div[@data-role="ershoufang"]/div[1]/a/@href'):
yield response.follow(url=info.get(),callback=self.parse_info)
def parse_info(self, response):
for info in response.xpath('//div[@data-role="ershoufang"]/div[2]/a/@href'):
yield response.follow(url=info.get(),callback=self.parse_page)
def parse_page(self,response):
url = response.url+'pg{}/'
pages = re.findall(r'"totalPage":(.*?),', response.text)[0]
for page in range(1, int(pages)+1):
yield scrapy.Request(url=url.format(page),callback=self.parse_item)
def parse_item(self, response):
for info in response.xpath("//div[@class='info clear']"):
yield {
'title': info.xpath('./div[@class="title"]/a/text()').get(),
'positionInfo': info.xpath('./div[@class="flood"]//a//text()').get(),
'houseInfo': info.xpath('./div[@class="address"]/div/text()').get(),
'totalPrice': info.xpath('//div[@class="priceInfo"]/div[1]/span/text()').get() + '万',
'unitPrice': info.xpath('//div[@class="priceInfo"]/div[2]/span/text()').get()
}
if __name__ == '__main__':
execute('scrapy crawl lj -o 长沙二手房.csv'.split())
# execute('scrapy crawl lj'.split())
上面的代码是Scrapy爬虫文件中的所有代码,速度非常快,可以轻而易举的把数据获取到。
运行之后,结果如下图所示:

后面遇到类似的,不妨拿出来实战下,事半功倍!
三、总结
大家好,我是皮皮。这篇文章主要分享了链家网二手房详情页的数据抓取,文中针对该问题给出了具体的解析和代码实现,一共两个方法,帮助粉丝顺利解决了问题。需要本文完整代码的小伙伴,可以私我获取。
最后感谢粉丝【dcpeng】提问,感谢【🇳 🇴 🇳 🇪】给出的思路和代码解析,感谢【dcpeng】、【猫药师Kelly】、【冫马讠成】、【月神】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
评论