
Pandas的merge操作,像数据库一样尽情join

今天是我们一起来聊聊dataframe的合并。
常见的数据合并操作主要有两种,第一种是我们新生成了新的特征,想要把它和旧的特征合并在一起。第二种是我们新获取了一份数据集,想要扩充旧的数据集。这两种合并操作在我们日常的工作当中非常寻常,那么究竟应该怎么操作呢?让我们一个一个来看。
merge
首先我们来看dataframe当中的merge操作,merge操作类似于数据库当中两张表的join,可以通过一个或者多个key将多个dataframe链接起来。
我们首先来创建两个dataframe数据:
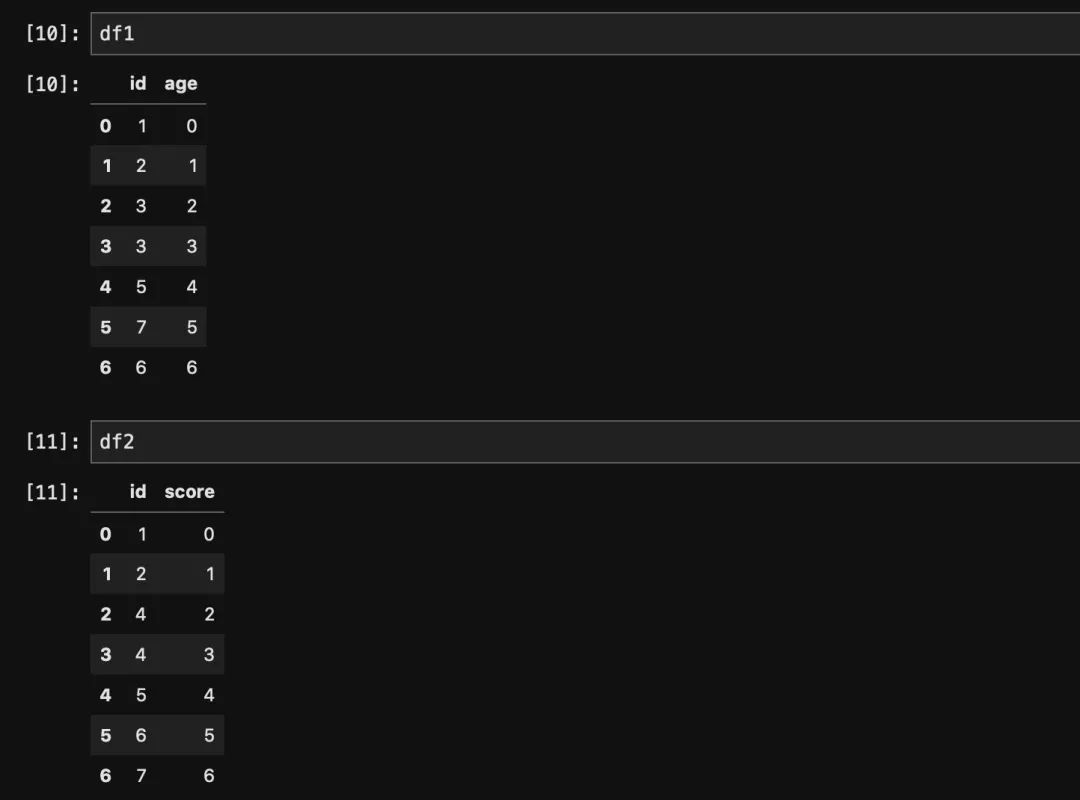
df1 = pd.DataFrame({'id': [1, 2, 3, 3, 5, 7, 6], 'age': range(7)})
df2 = pd.DataFrame({'id': [1, 2, 4, 4, 5, 6, 7], 'score': range(7)})
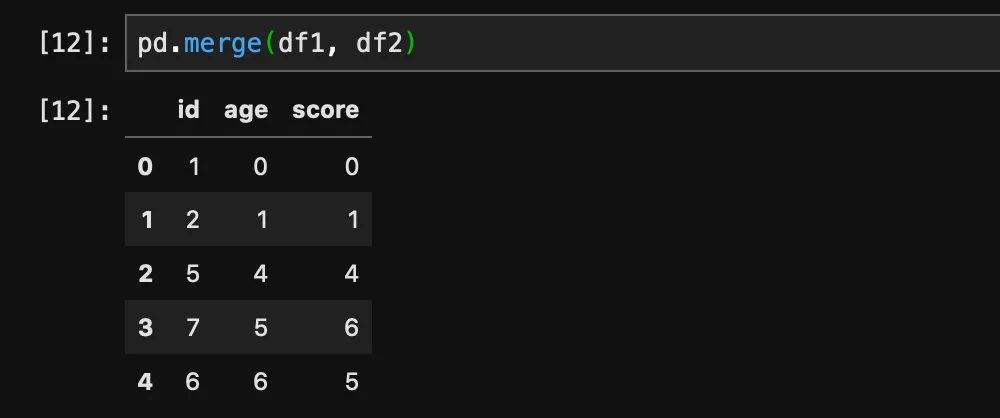
我们可以看到这两个dataframe当中都有id这个字段,如果我们想要将它们根据id关联起来,我们可以用pd.merge函数完成:
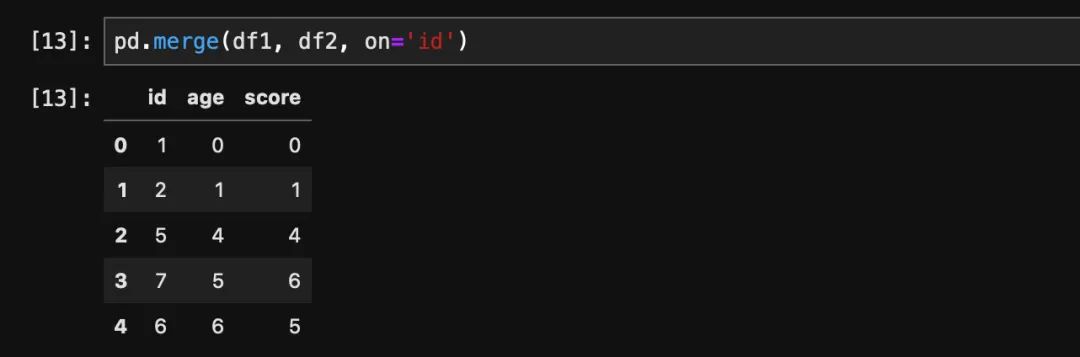
这里虽然我们没有指定根据哪一列完成关联,但是pandas会自动寻找两个dataframe的名称相同列来进行关联。一般情况下我们不这么干,还是推荐大家指定列名。指定列名很简单,我们只需要传入on这个参数即可。
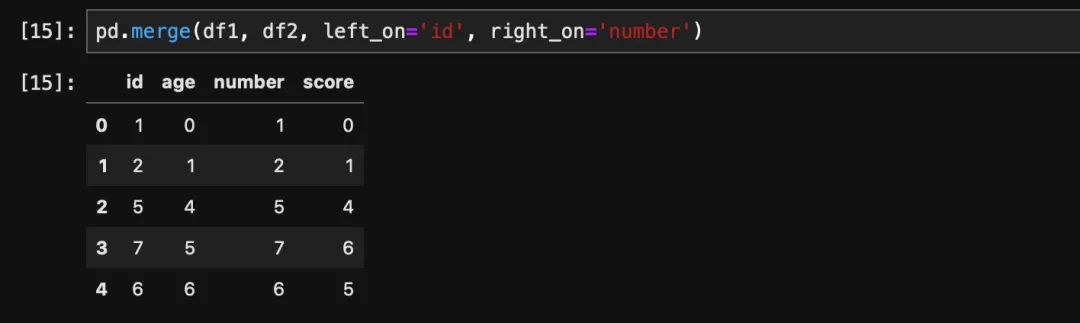
如果需要根据多列关联,我们也可以传入一个数组。但假如两个dataframe当中的列名不一致怎么办,比如这两个dataframe当中的一列叫做id,一列叫做number,该怎么完成join呢?
df1 = pd.DataFrame({'id': [1, 2, 3, 3, 5, 7, 6], 'age': range(7)})
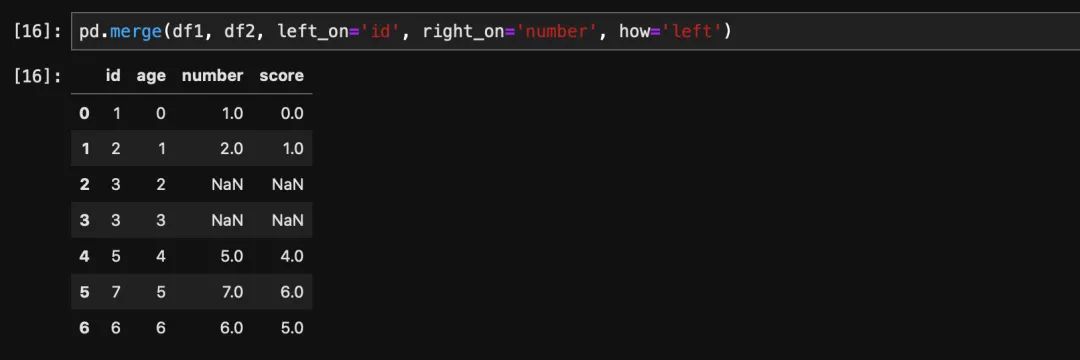
df2 = pd.DataFrame({'number': [1, 2, 4, 4, 5, 6, 7], 'score': range(7)})这个时候就需要用left_on指定左表用来join的列名,用right_on指定右表用来join的列名。
谈到join,不得不提另外一个问题就是join的方式。我们都知道在数据库的表join操作当中我们通常的join方式有4种。分别是innner join,left join,right join和outer join。我们观察一下上面的结果会发现关联之后的数据条数变少了,这是因为默认的方式是inner join,也就是两张表当中都存在的数据才会被保留。如果是left join,那边左边当中所有的数据都会保留,关联不上的列置为None,同理,如果是right join,则右表全部保留,outer join则会全部保留。
join的方式选择通过how这个参数控制,比如如果我们想要左表保留,我们传入how='left'即可。
除此之外,merge操作还有一些其他的参数,由于篇幅限制我们不一一介绍了,大家感兴趣可以去查阅相关文档。
数据合并
另外一个常用的操作叫做数据合并,为了和merge操作区分,我用了中文。虽然同样是合并,但是它的逻辑和merge是不同的。对于merge来说,我们需要关联的key,是通过数据关联上之后再合并的。而合并操作是直接的合并,行对行合并或者是列对列合并,是忽视数据的合并。
这个合并操作我们之前在numpy的介绍当中曾经也提到过,我们这里简单回顾一下。
首先我们先创建一个numpy的数组:
import numpy as np
arr = np.random.rand(3, 4)
之后呢,我们可以用concatenate函数把这个数组横着拼或者是竖着拼,默认是竖着拼:

我们也可以通过axis这个参数让它变成横着拼:

对于dataframe同样也有这样的操作,不过换了一个名字叫做concat。如果我们不指定的话会竖着拼接:
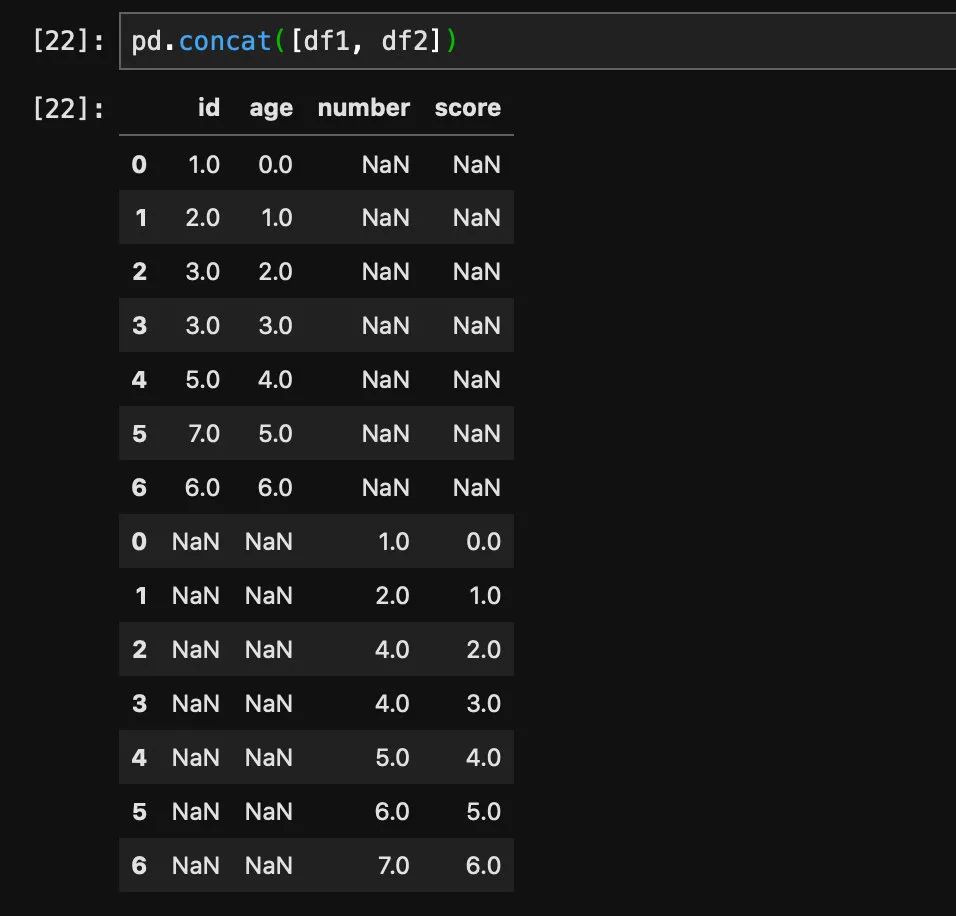
竖着拼接的时候会按照列进行对齐,如果列名对不上就会填充NaN。
通过axis参数我们可以让它横向拼接:
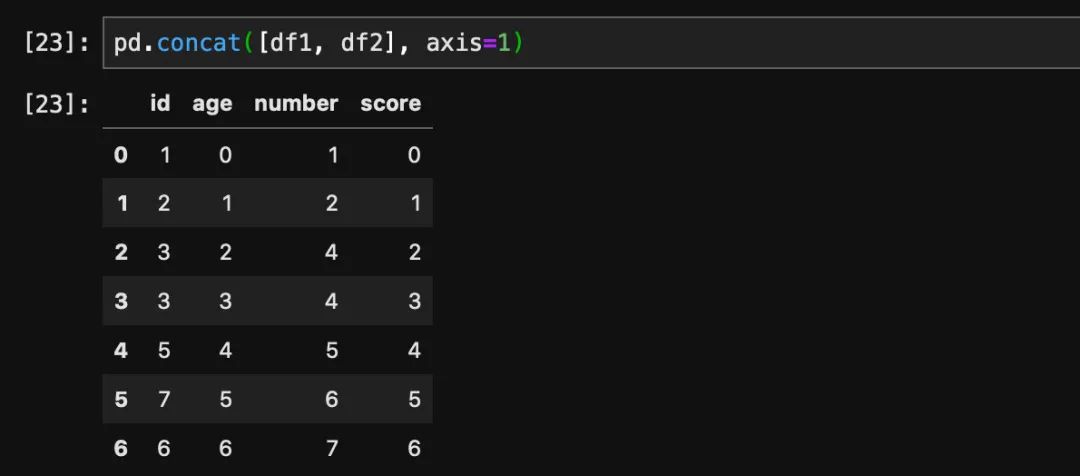
以上就是concat的基本用法了,除了基本用法之外,concat还有一些其他的应用,比如说处理index层次索引等等。只是这些用法相对来说比较小众,使用频率不高,就不赘述了。
