
深度:Kafka 集群突破百万 partition 的技术探索
共 5486字,需浏览 11分钟
·
2021-05-02 00:03
导语:本篇文章主要从元数据,controller 逻辑等方面介绍了如何解决支撑百万 partition 的问题,运营大规模集群其实还涉及到磁盘故障、冷读、数据均衡等数据方面的问题,监控和报警服务同样非常的重要。
本文来源:腾讯云中间件
对于小业务量的业务,往往多个业务共享 kafka 集群,随着业务规模的增长需要不停的增加 topic 或者是在原 topic 的基础上扩容 partition 数,另外一些后来大体量的业务在试水阶段也可能不会部署独立的集群,当业务规模爆发时,需要迅速扩容扩容集群节点。在不牺牲稳定性的前提下单集群规模有限,常常会碰到业务体量变大后无法在原集群上直接进行扩容,只能让业务创建新的集群来支撑新增的业务量,这时用户面临系统变更的成本,有时由于业务关联的原因,集群分开后涉及到业务部署方案的改变,很难短时间解决。
为了快速支持业务扩容,就需要我们在不需要业务方做任何改动的前提下对集群进行扩容,大规模的集群,往往意味着更多的 partition 数,更多的 broker 节点,下面会描述当集群规模增长后主要面临哪些方面的挑战。
Kafka 的 topic 在 broker 上是以 partition 为最小单位存放和进行复制的, 因此集群需要维护每个 partition 的 Leader 信息,单个 partition 的多个副本都存放在哪些 broker 节点上,处于复制同步状态的副本都有哪些。为了存放这些元数据,kafka 集群会为每一个 partition 在 zk 集群上创建一个节点,partition 的数量直接决定了 zk 上的节点数。
假设集群上有 1 万个 topic,每个 topic 包含 100 个 partition,则 ZK 上节点数约为 200 多万个,快照大小约为 300MB,ZK 节点数据变更,会把数据会写在事务日志中进行持久化存储,当事务日志达到一定的条目会全量写入数据到持久化快照文件中,partition 节点数扩大意味着快照文件也大,全量写入快照与事务日志的写入会相互影响,从而影响客户端的响应速度,同时 zk 节点重启加载快照的时间也会变长。
2. Partition 复制
Kafka 的 partition 复制由独立的复制线程负责,多个 partition 会共用复制线程,当单个 broker 上的 partition 增大以后,单个复制线程负责的 partition 数也会增多,每个 partition 对应一个日志文件,当大量的 partition 同时有写入时,磁盘上文件的写入也会更分散,写入性能变差,可能出现复制跟不上,导致 ISR 频繁波动,调整复制线程的数量可以减少单个线程负责的 partition 数量,但是也加剧了磁盘的争用。
3. Controller 切换时长
由于网络或者机器故障等原因,运行中的集群可能存在 controller 切换的情况,当 controller 切换时需要从 ZK 中恢复 broker 节点信息、topic 的 partition 复制关系、partition 当前 leader 在哪个节点上等,然后会把 partition 完整的信息同步给每一个 broker 节点。
在虚拟机上测试,100 万 partition 的元数据从 ZK 恢复到 broker 上约需要 37s 的时间,100 万 partition 生成的元数据序列化后大约 80MB(数据大小与副本数、topic 名字长度等相关),其他 broker 接收到元数据后,进行反序列化并更新到本机 broker 内存中,应答响应时间约需要 40s(测试时长与网络环境有关)。
Controller 控制了 leader 切换与元数据的下发给集群中其他 broker 节点,controller 的恢复时间变长增加了集群不可用风险,当 controller 切换时如果存在 partition 的 Leader 需要切换,就可能存在客户端比较长的时间内拿不到新的 leader,导致服务中断。
4. broker 上下线恢复时长
日常维护中可能需要对 broker 进行重启操作,为了不影响用户使用,broker 在停止前会通知 controller 进行 Leader 切换,同样 broker 故障时也会进行 leader 切换,leader 切换信息需要更新 ZK 上的 partition 状态节点数据,并同步给其他的 broker 进行 metadata 信息更新。当 partition 数量变多,意味着单个 broker 节点上的 partitiion Leader 切换时间变长。
通过上述几个影响因素,我们知道当 partition 数量增加时会直接影响到 controller 故障恢复时间;单个 broker 上 partition 数量增多会影响磁盘性能,复制的稳定性;broker 重启 Leader 切换时间增加等。当然我们完全可以在现有的架构下限制每个 broker 上的 partition 数量,来规避单 broker 上受 partition 数量的影响,但是这样意味着集群内 broker 节点数会增加,controller 负责的 broker 节点数增加,同时 controller 需要管理的 partition 数并不会减少,如果我们想解决大量 partition 共用一个集群的场景,那么核心需要解决的问题就是要么提升单个 controller 的处理性能能力,要么增加 controller 的数量。
1. 单 ZK 集群
从提升单个 controller 处理性能方面可以进行下面的优化:
并行拉取 zk 节点
Controller 在拉取 zk 上的元数据时,虽然采用了异步等待数据响应的方式,请求和应答非串行等待,但是单线程处理消耗了大约 37s,我们可以通过多线程并行拉取元数据,每个线程负责一部分 partition,从而缩减拉取元数据的时间。
在虚拟机上简单模拟获取 100 万个节点数据,单线程约花费 28s,分散到 5 个线程上并行处理,每个线程负责 20 万 partition 数据的拉取,总时间缩短为 14s 左右(这个时间受虚拟机本身性能影响,同虚拟机上如果单线程拉取 20 万 partition 约只需要 6s 左右),因此在 controller 恢复时,并行拉取 partition 可以明显缩短恢复时间。
变更同步元数据的方式
上文中提到 100 万 partition 生成的元数据约 80MB,如果我们限制了单 broker 上 partition 数量,意味着我们需要增加 broker 的节点数,controller 切换并行同步给大量的 broker,会给 controller 节点带来流量的冲击,同时同步 80MB 的元数据也会消耗比较长的时间。因此需要改变现在集群同步元数据的方式,比如像存放消费位置一样,通过内置 topic 来存放元数据,controller 把写入到 ZK 上的数据通过消息的方式发送到内置存放元数据的 topic 上,broker 分别从 topic 上消费这些数据并更新内存中的元数据,这类的方案虽然可以在 controller 切换时全量同步元数据,但是需要对现在的 kafka 架构进行比较大的调整(当然还有其他更多的办法,比如不使用 ZK 来管理元数据等,不过这不在本篇文章探讨的范围内)。
那有没有其他的办法,在对 kafka 架构改动较小的前提下来支持大规模 partition 的场景呢?我们知道 kafka 客户端与 broker 交互时,会先通过指定的地址拉取 topic 元数据,然后再根据元数据连接 partition 相应的 Leader 进行生产和消费,我们通过控制元数据,可以控制客户端生产消费连接的机器,这些机器在客户端并不要求一定在同一个集群中,只需要客户端能够拿到这些 partition 的状态信息,因此我们可以让不同的 topic 分布到不同的集群上,然后再想办法把不同集群上的 topic 信息组合在一起返回给客户端,就能达到客户端同时连接不同集群的效果,从客户端视角来看就就是一个大的集群。这样不需要单个物理集群支撑非常大的规模,可以通过组合多个物理集群的方式来达到支撑更大的规模,通过这种方式,扩容时不需要用户停机修改业务,下面我们就来描述一下怎么实现这种方案。
2. 小集群组建逻辑集群
下面针对这些问题一一进行讲解:
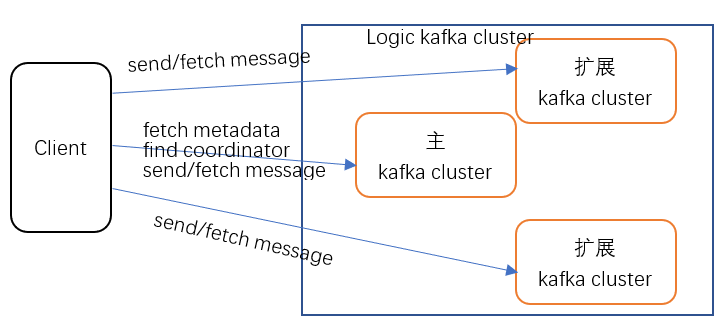
metadata 服务
针对 metadata 组装问题,我们可以在逻辑集群里的多个物理集群中选一个为主集群,其他集群为扩展集群,由主集群负责对外提供 metadata、消费位置、事务相关的服务,当然主集群也可以同时提供消息的生产消费服务,扩展集群只能用于业务消息的生产和消费。我们知道当 partition 的 Leader 切换时需要通过集群中的 controller 把新的 metadata 数据同步给集群中的 broker。当逻辑集群是由多个相互独立的物理集群组成时,controller 无法感知到其他集群中的 Broker 节点。
我们可以对主集群中的 metada 接口进行简单的改造,当客户端拉取 metadata 时,我们可以跳转到其他的集群上拉取 metadata, 然后在主集群上进行融合组装再返回给客户端。
虽然跳转拉取 metadata 的方式有一些性能上的消耗,但是正常情况下并不在消息生产和消费的路径上,对客户端影响不大。通过客户端拉取时再组装 metadata,可以规避跨物理集群更新 metadata 的问题,同时也能够保证实时性。
消费分组与事务协调
当消费分组之间的成员需要协调拉取数据的 partition 时,服务端会根据保存消费位置 topic 的 partition 信息返回对应的协调节点,因此我们在一个逻辑集群中需要确定消费位置 topic 分布的集群,避免访问不同物理集群的节点返回的协调者不一样,从不同集群上拉取到的消费位置不一样等问题。我们可以选主集群的 broker 节点提供消费和事务协调的服务,消费位置也只保存在主集群上。
通过上述的一些改造,我们就可以支持更大的业务规模,用户在使用时只需要知道主集群的地址就可以了。
组建逻辑集群除了上述的核心问题外,我们也需要关注 topic 的分配,由于腾讯云的 ckafka 本身就会把 broker 上创建 topic 的请求转发给管控模块创建,因此可以很方便的解决 topic 在多个物理集群的分布,也可以规避同一逻辑集群上,不同物理集群内可能出现同名 topic 的问题。
单物理集群分裂
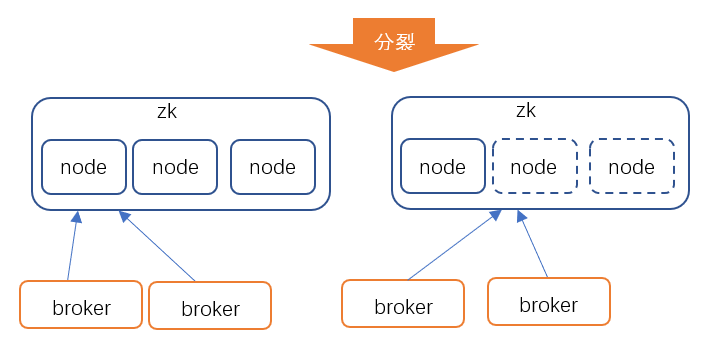
进行集群的分裂涉及到 ZK 集群的分裂和对 broker 节点进行分组拆分,首先对集群中的 broker 节点分成两组,每组连接不同的 ZK 节点,比如我们可以在原来的 zk 集群中增加 observer 节点,新增的 broker 为一组,原来集群中的 broker 为一组,我们让新 broker 只填写 observer 的地址。ZK 集群分裂前,通过 KAFKA 内置迁移工具可以很方便地把不同的 topic 迁移到各自的 broker 分组上,同一个 topic 的 partition 只会分布在同一个分组的 broker 节点上,后续把 observer 节点从现有的 ZK 集群中移除出去,然后让 observer 与别的 ZK 节点组成新的 ZK 集群,从而实现 kafka 集群的分裂。
通过提升 controller 的性能,和通过把多个物理集群组装成一个逻辑集群的做法都可以提升单集群承载 partition 的规模。但是相比而言,通过组建多个物理集群的方式对 kafka 现有的架构改动更小一些,故障恢复的时间上更有保障一些,服务更稳定。
当然业务在使用 kafka 服务时,如果业务允许保持一个 partition 数量适度的集群规模,通过业务拆分的方式连接不同的集群也是一种很好的实践方式。
丁俊,腾讯云消息队列 Ckafka 负责人,拥有多年消息、缓存、NOSQL 等基础设施的研发经验。腾讯云 CKafka 团队一直在不断探索,致力于为用户提供可靠的消息服务。