
「抓取」微信读书生成的唯一标识获取详情信息
共 3201字,需浏览 7分钟
·
2020-12-31 09:29
昨天有位小姐姐请我帮忙,让我看如何生成获取微信读书里获取图书详细信息的唯一标识,业务方给她的需要是抓取微信读书里的详细信息,我当然是义不容辞的看一下。
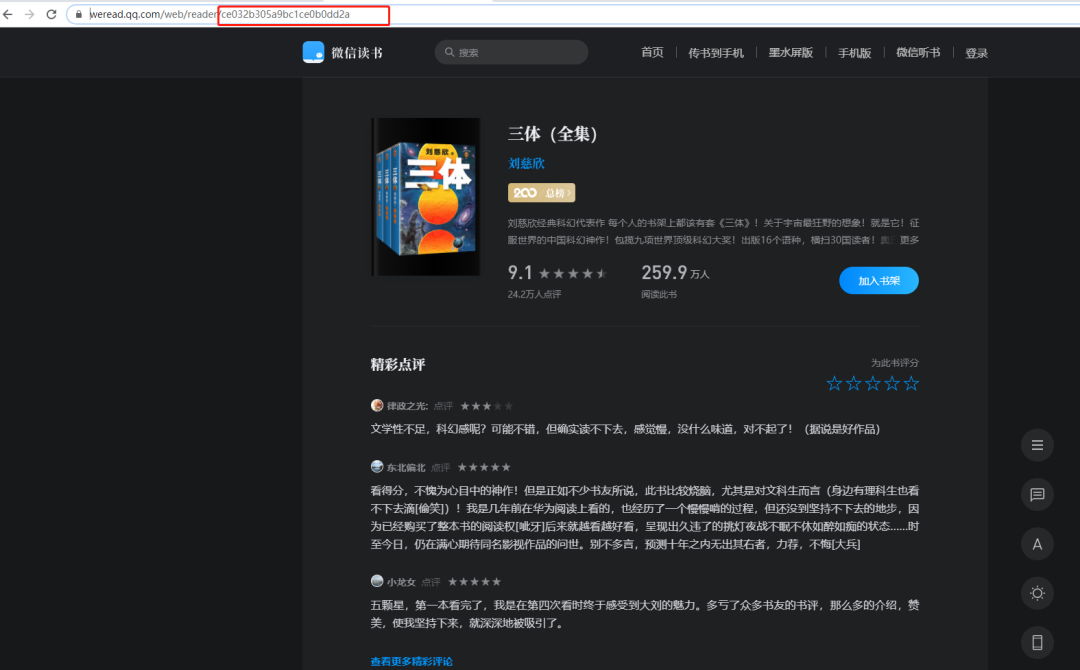
定位来源
通过F12查看一下这个特殊的字符串是不是通过接口返回来的,如何是通过服务端返回来的,那么通过调取接口就可以获取到,如果不是调接口返回那么换一种思路。
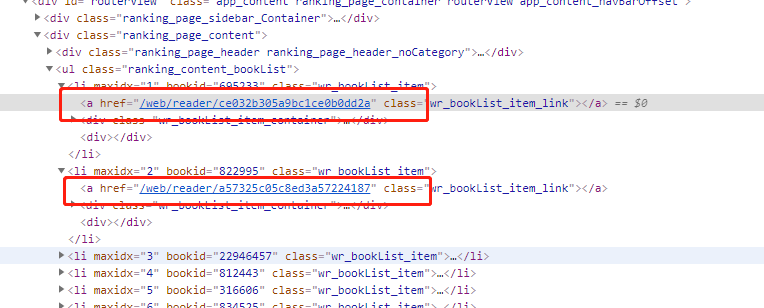
很快通过查看network发现并不是接口直接返回,那么可能就是通过某一个特殊的标识,通过加密算法生成的唯一字符串
转化思路
通过页面元素自身的属性class查看,看看是不是存在动态的自定义属性
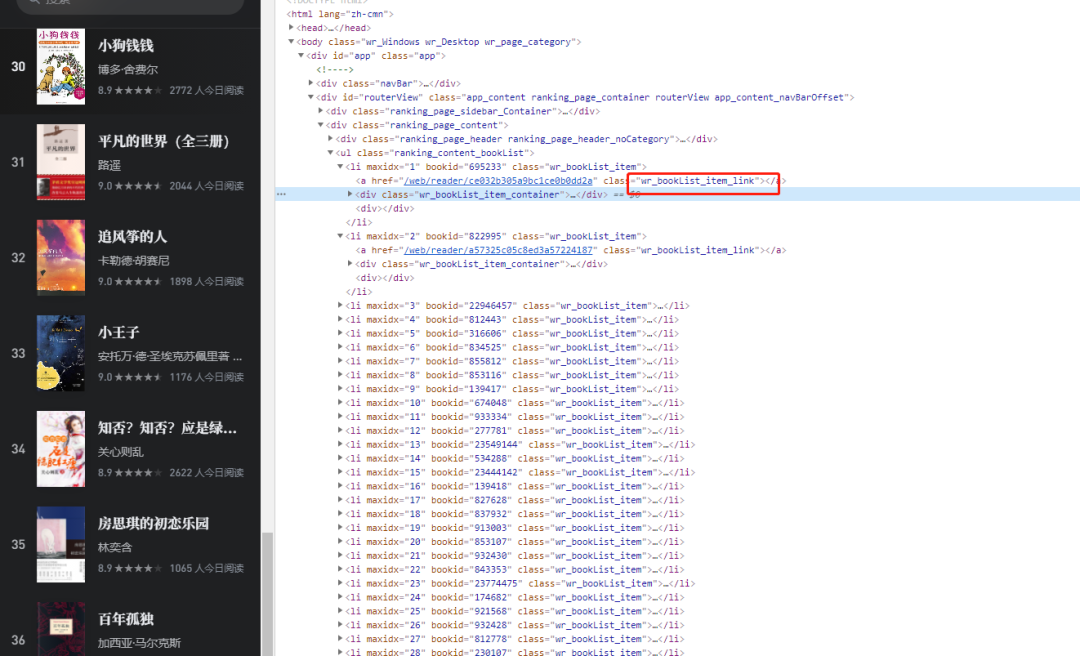
果不奇然在sources中找到了动态添加自定义属性的方法,可以看到a标签上的href属性是动态生成的
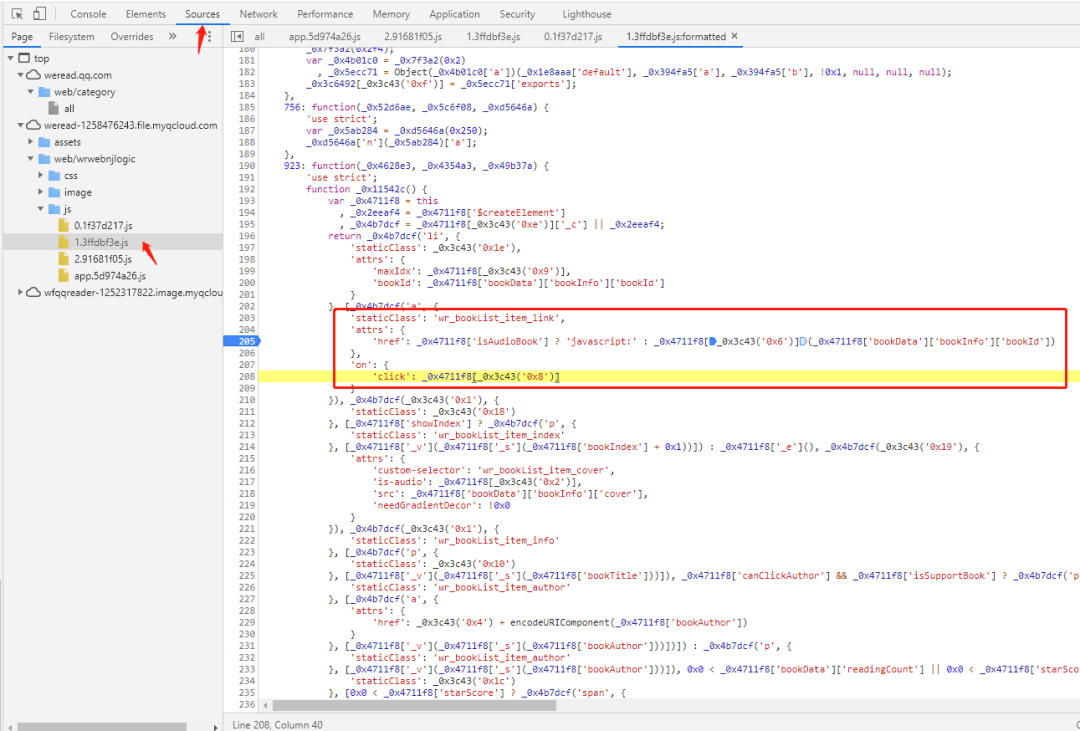
然后就可以按部就班的依次查找这个方法的参数以及返回值,找到这个方法最终来源就可以找到这个算法的核心了
查找方法
查找方法中的参数
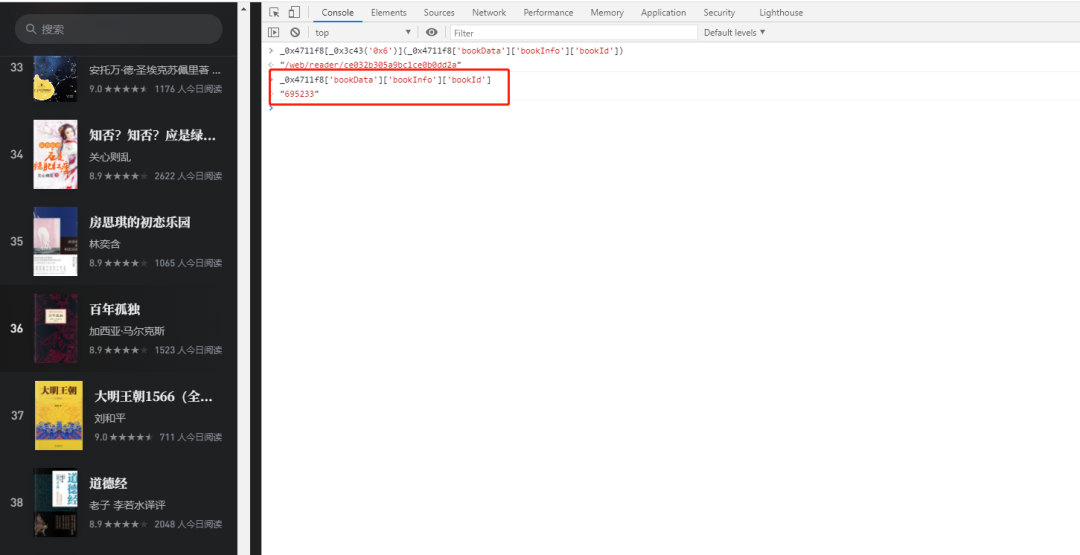
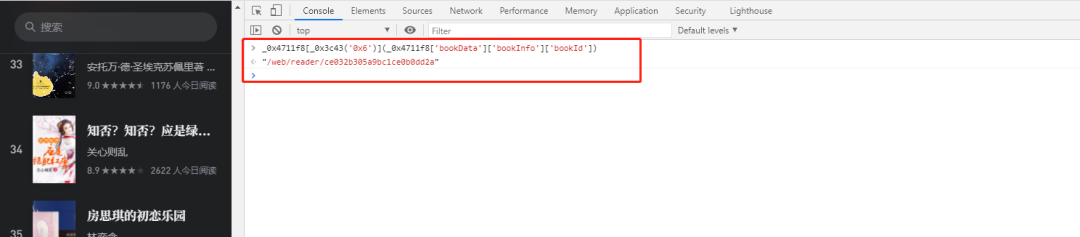
显然这个_0x4711f8['bookData']['bookInfo']['bookId']是图书的bookId
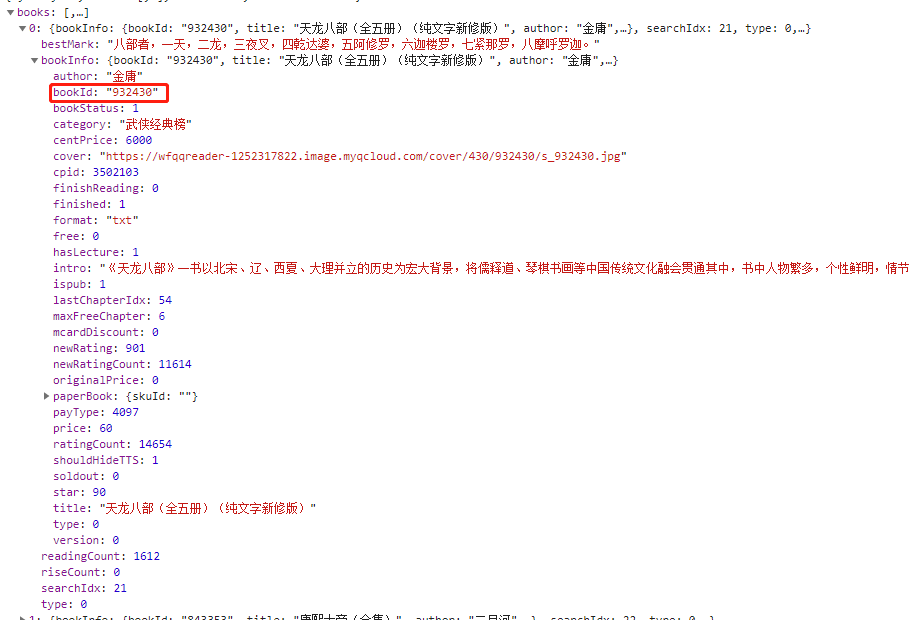
如果有疑问的话,我们可以看一下_0x4711f8这个对象是啥
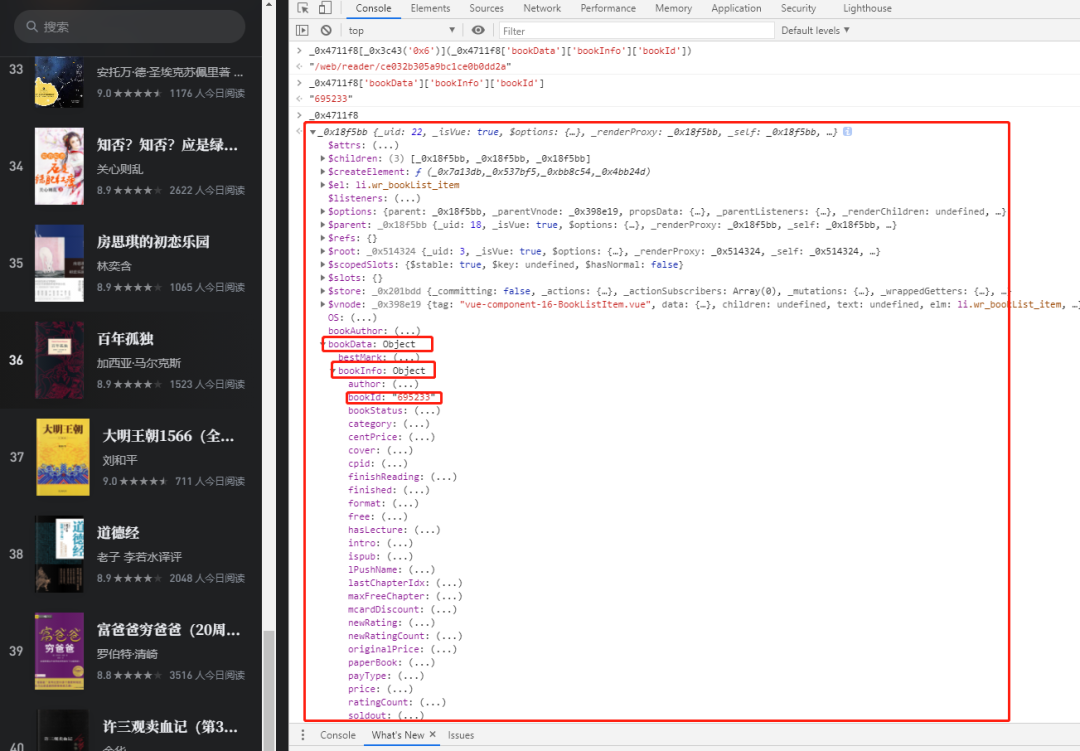
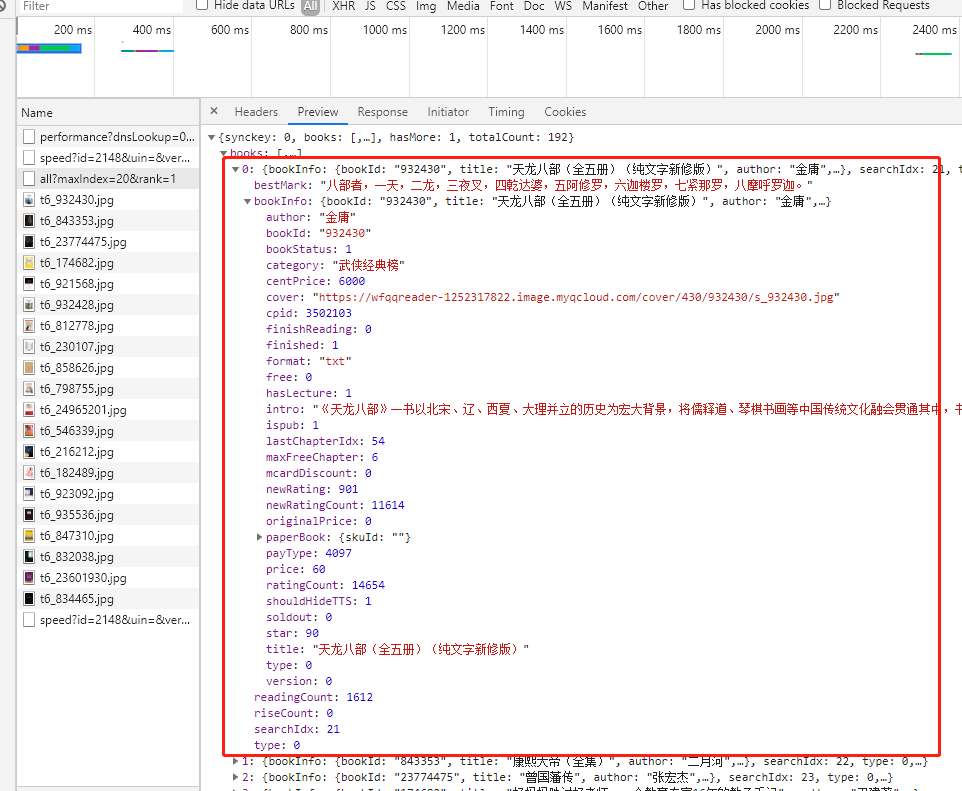
有没有很熟悉的感觉vue,这个页面的开始使用过vue来写的,将接口https://weread.qq.com/web/bookListInCategory/all?maxIndex=20&rank=1里返回的数据存到了bookData属性里。
查找方法
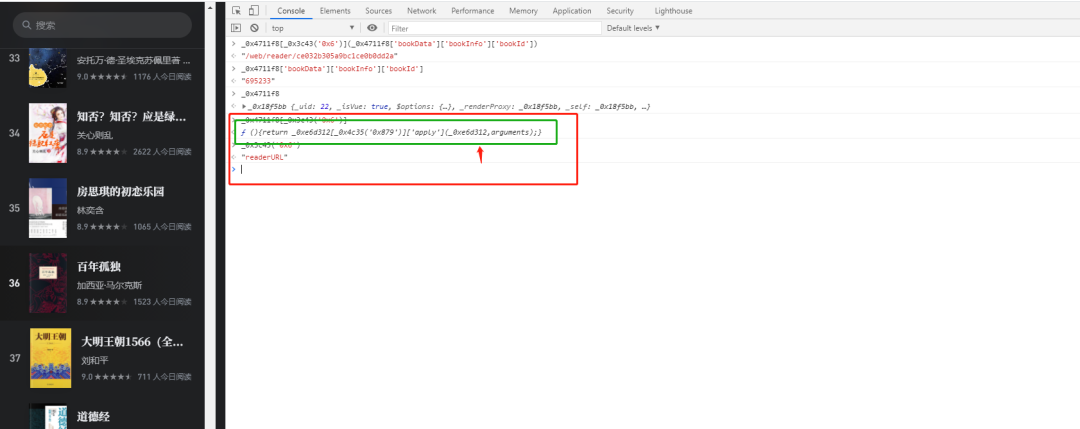
_0x3c43('0x6')代表的是readerURL方法名,双击上图标绿色的部分,浏览器会自动定位到代码部分即
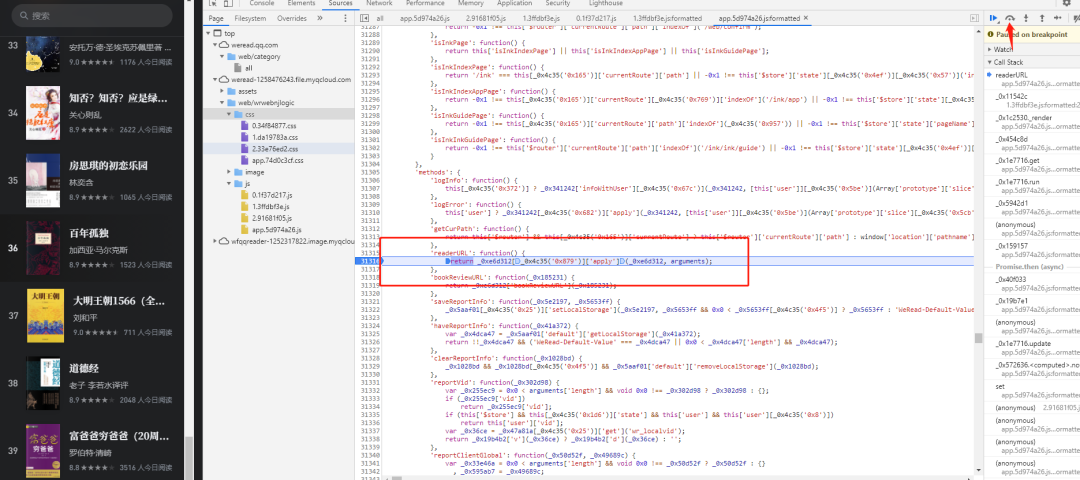
点击右上角代码调试按钮,让代码部分继续往下走,进入我们找到的方法可以看到函数中有两个参数_0xe6d312是改变this的指向,arguments是我们传递过来的参数
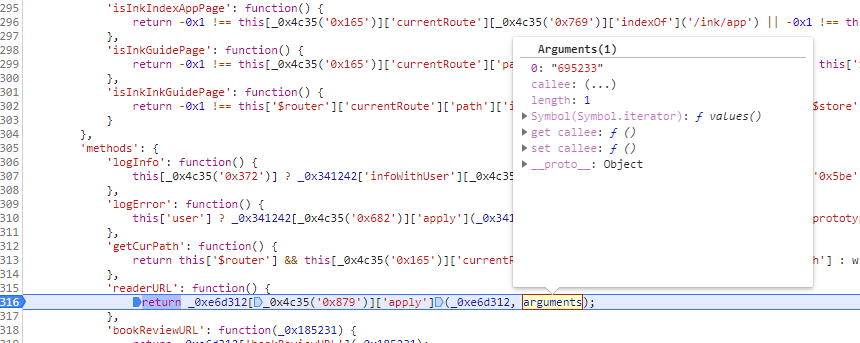
下面查找_0xe6d312[_0x4c35('0x879')]方法,双击标红色的地方,自动跳到代码所在部分
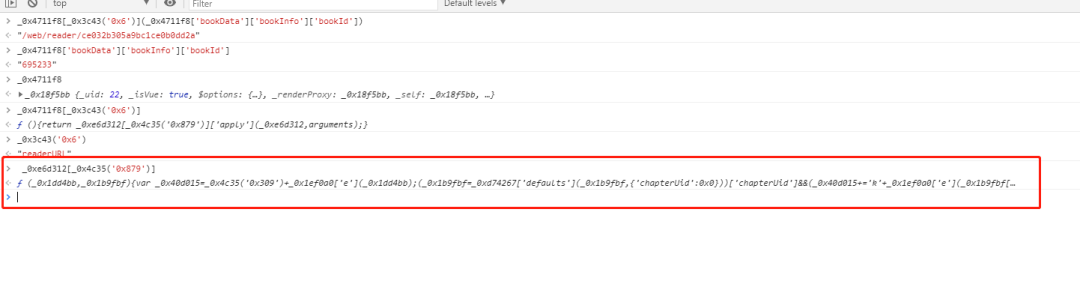
继续通过断点调试,我们可以看到生成我们需要的字符串就是_0x1ef0a0['e'](_0x1dd4bb)这个方法
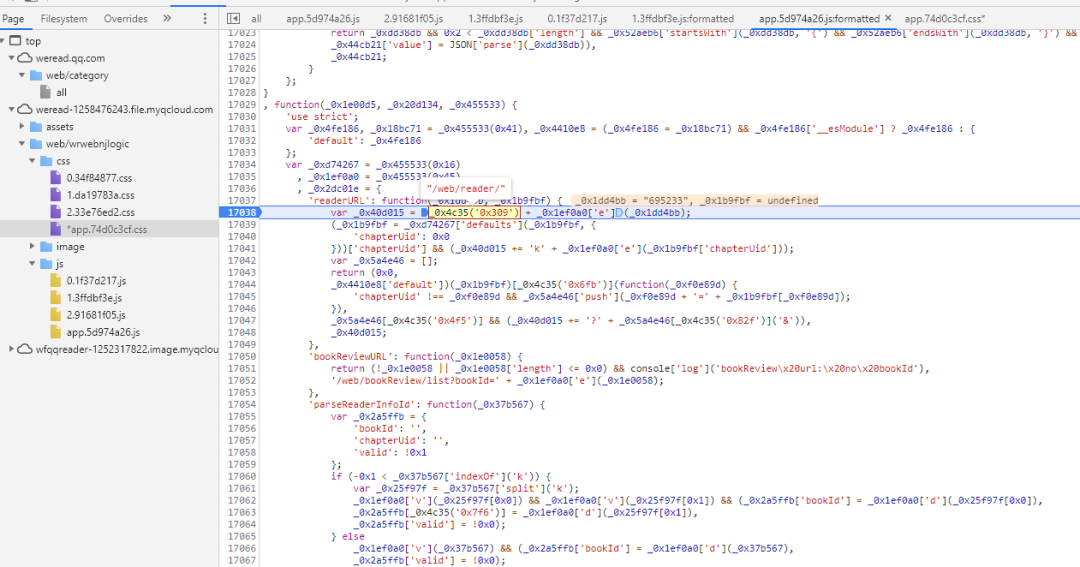
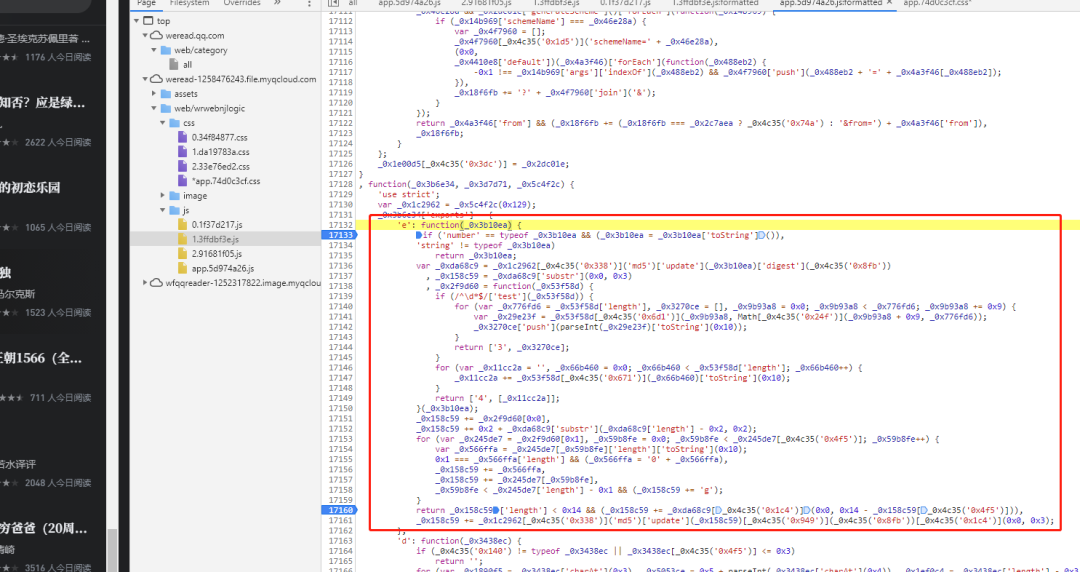
继续断点调试,最终找到算法的位置,即下图标红的位置。
node实现
下面我们通过node.js实现这个算法
const crypto = require("crypto");
function createId(bookId){
let str = crypto.createHash("md5").update(bookId).digest('hex');
let strSub = str.substr(0,3);
let fa = function(id){
if (/^\d*$/['test'](id)) {
for (var len = id['length'], c = [], a = 0; a < len; a += 9) {
var b = id['slice'](a, Math.min(a + 9, len));
c['push'](parseInt(b)['toString'](16));
}
return ['3', c];
}
for (var d = '', i = 0; i < id['length']; i++) {
d += id['charCodeAt'](i)['toString'](16);
}
return ['4', [d]];
}(bookId);
strSub += fa[0],
strSub += 2 + str['substr'](str['length'] - 2, 2);
for (var m = fa[1], j = 0; j < m.length; j++) {
var n = m[j].length.toString(16);
1 === n['length'] && (n = '0' + n),
strSub += n,
strSub += m[j],
j < m['length'] - 1 && (strSub += 'g');
}
return strSub.length< 20 && (strSub += str.substr(0, 20 - strSub.length)),
strSub += crypto.createHash("md5").update(strSub).digest('hex').substr(0, 3);;
}
let strId = createId(bookId)
console.log(strId);
效果如下图所示
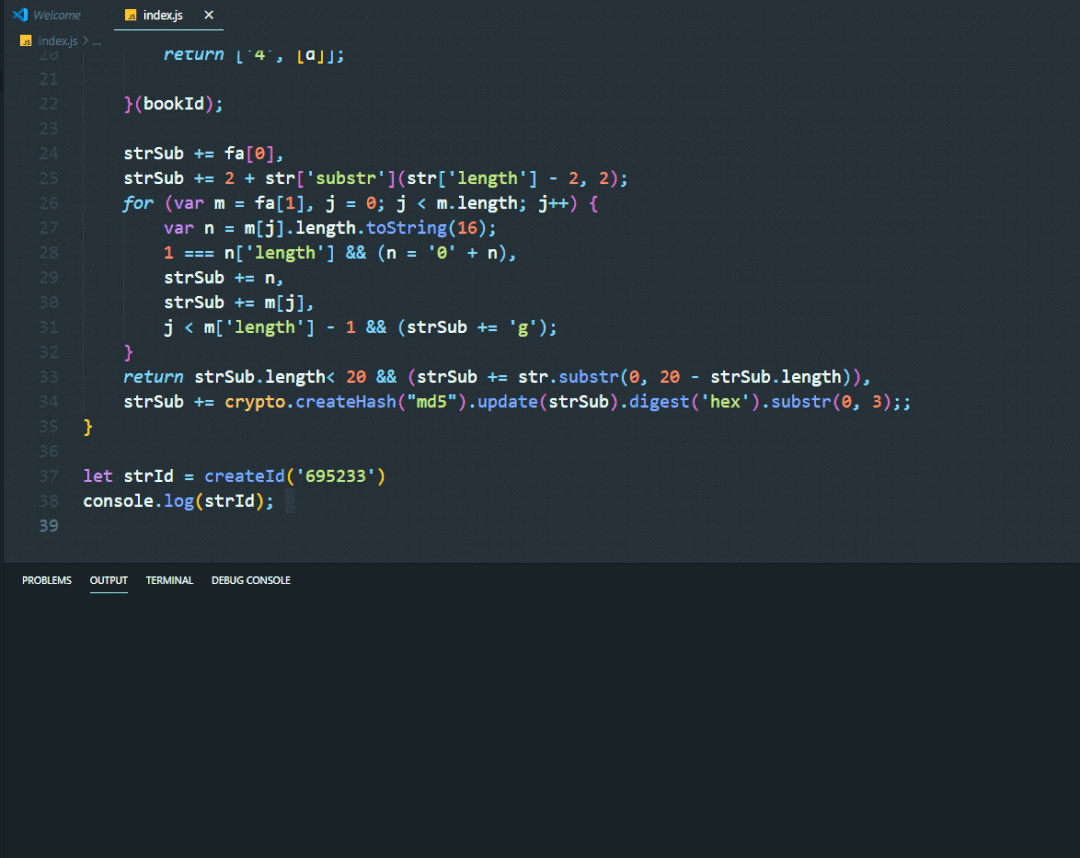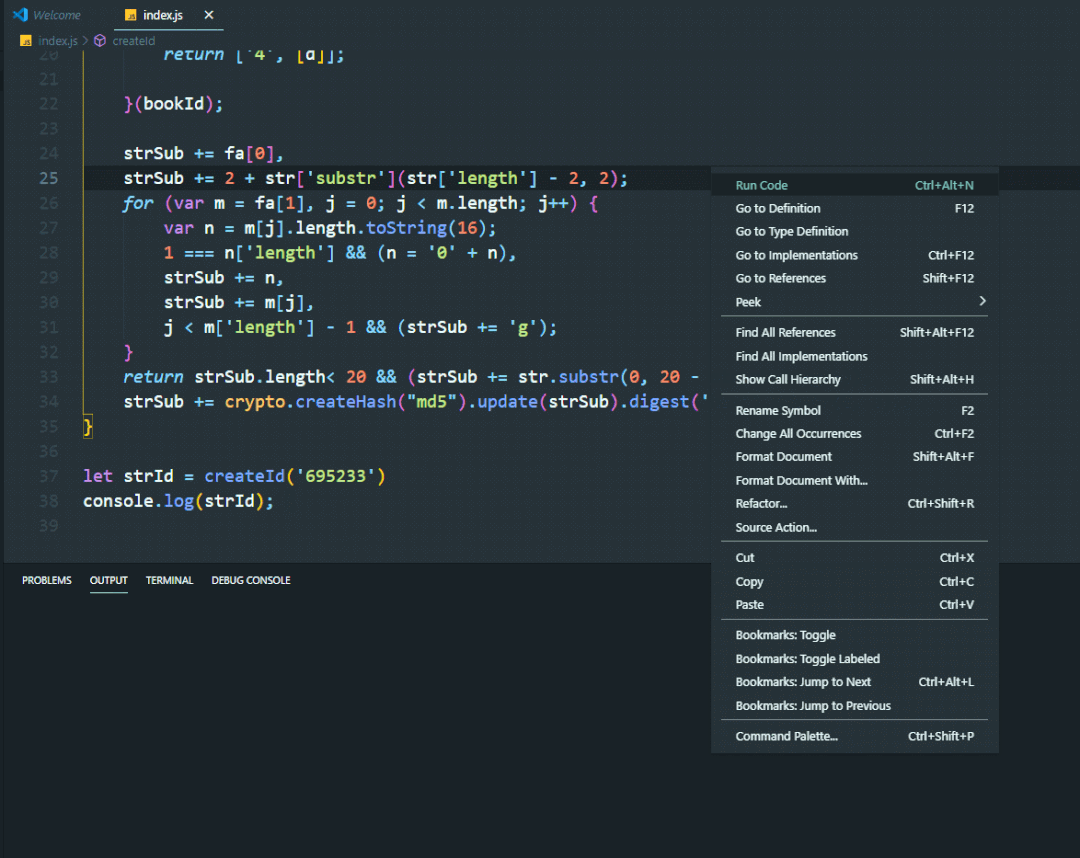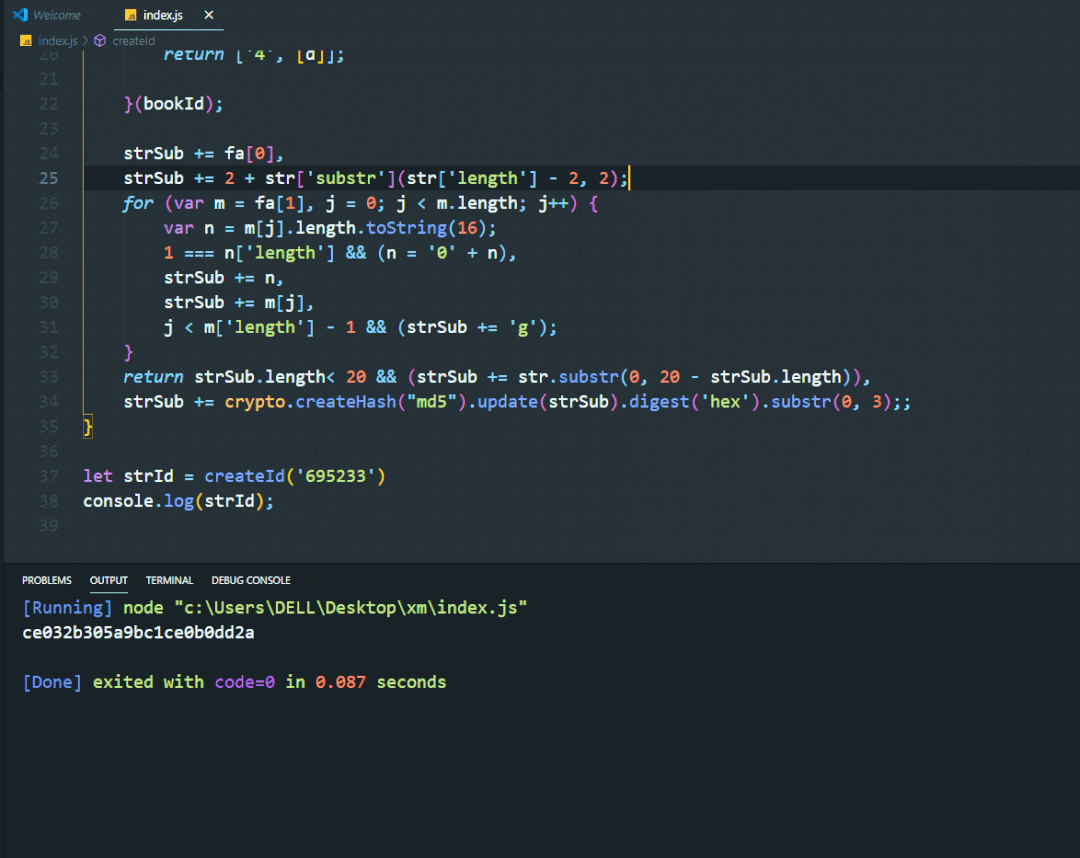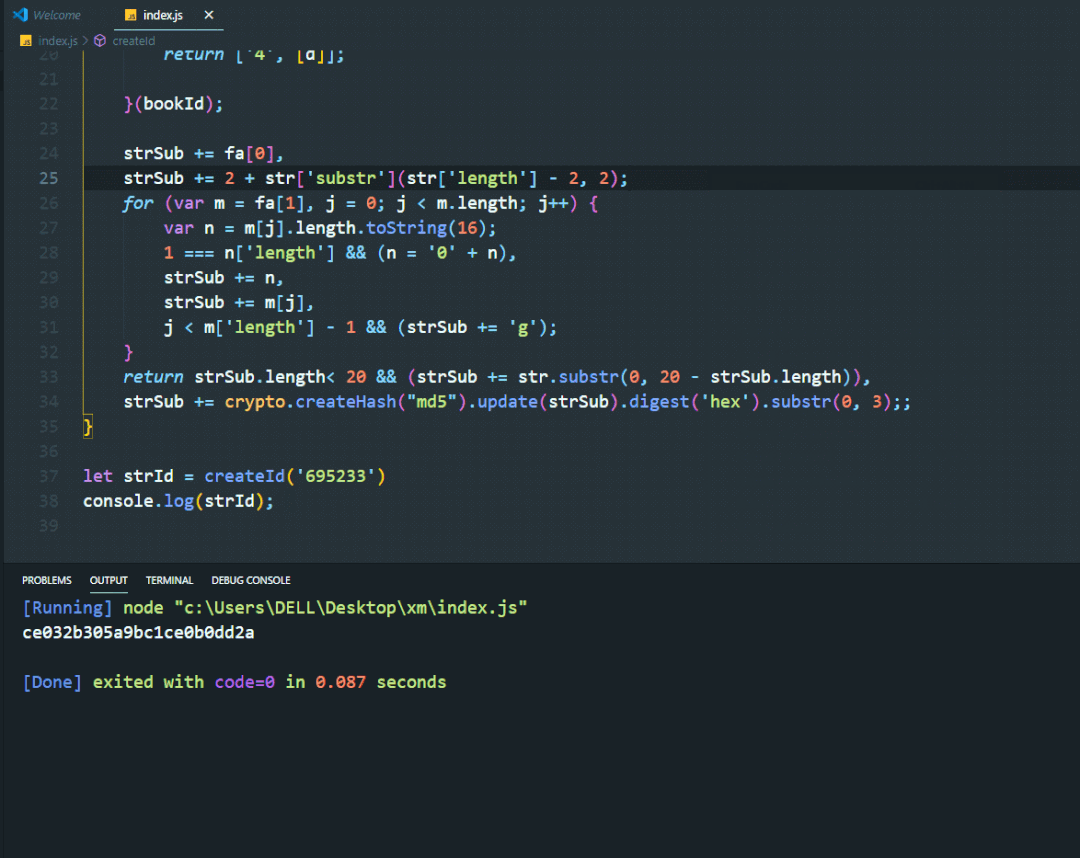
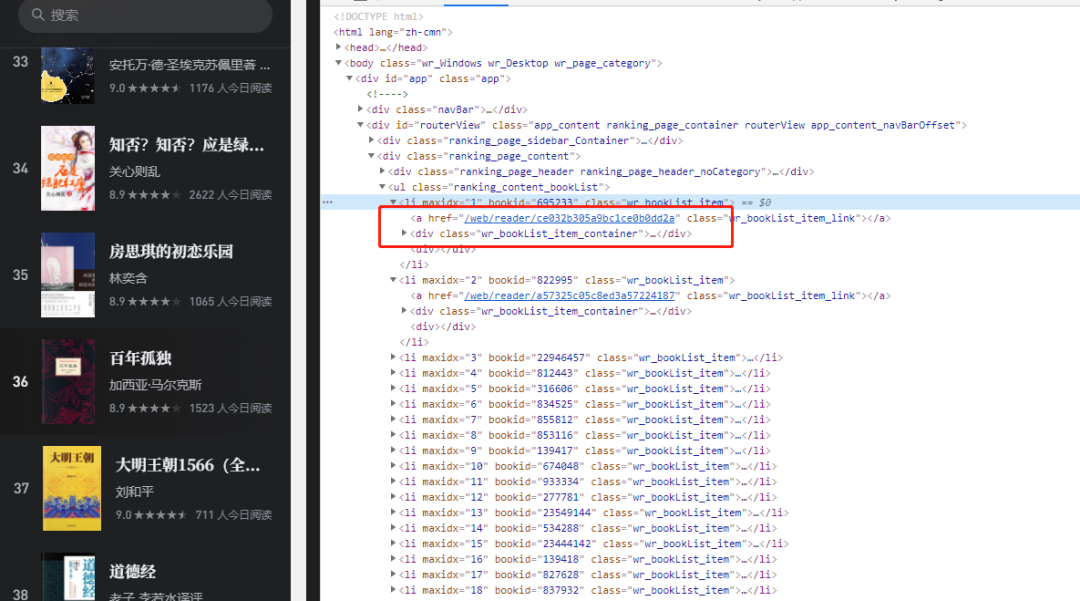
通过对比我们生成的字符串和页面生成的是一致的,多次测试满足要求。
python实现
import hashlib
import re
def creatid(bookId):
str = hashlib.md5(bookId.encode("utf8")).hexdigest()
strSub = str[0:3]
reg = re.search('(\d+)',bookId).group(1)
if reg:
lenth = len(bookId)
for a in range(0,lenth):
b = bookId[a:min(a+9,lenth)]
c_str = hex(int(b))[2:]
fa =['3',[c_str]]
a += 9
if a >= lenth:
break
strSub += fa[0]
strSub += '2' + str[len(str)-2:]
m = fa[1]
for j in range(0,len(m)):
n = hex(len(m[j]))[2:]
if len(n) == 1:
n = '0'+ n
strSub += n + m[j]
if len(strSub) < 20:
strSub += str[0:20-len(strSub)]
strSub += hashlib.md5(strSub.encode("utf8")).hexdigest()[0:3]
print(strSub)
if __name__ == "__main__":
creatid(bookId)
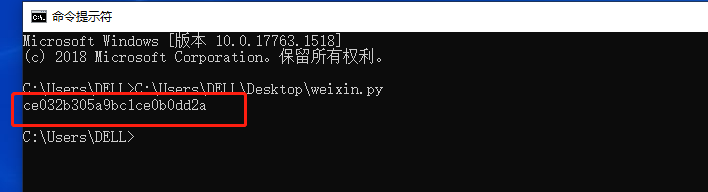
运行结果:
关注数:10亿+ 文章数:10亿+
粉丝量:10亿+ 点击量:10亿+
悬赏博主专区请扫描这里
喜爱数: 1亿+ 发帖数: 1亿+
回帖数: 1亿+ 结贴率: 99.9%
—————END—————
喜欢本文的朋友,欢迎关注公众号 程序员哆啦A梦,收看更多精彩内容
点个[在看],是对小达最大的支持!
如果觉得这篇文章还不错,来个【分享、点赞、在看】三连吧,让更多的人也看到~


