从视频到语言: 视频标题生成与描述研究综述

来源:专知 本文约5000字,建议阅读9分钟
最新视频视频标题生成与描述研究综述论文。

http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c200662

1. 基于模板/规则的视频描述

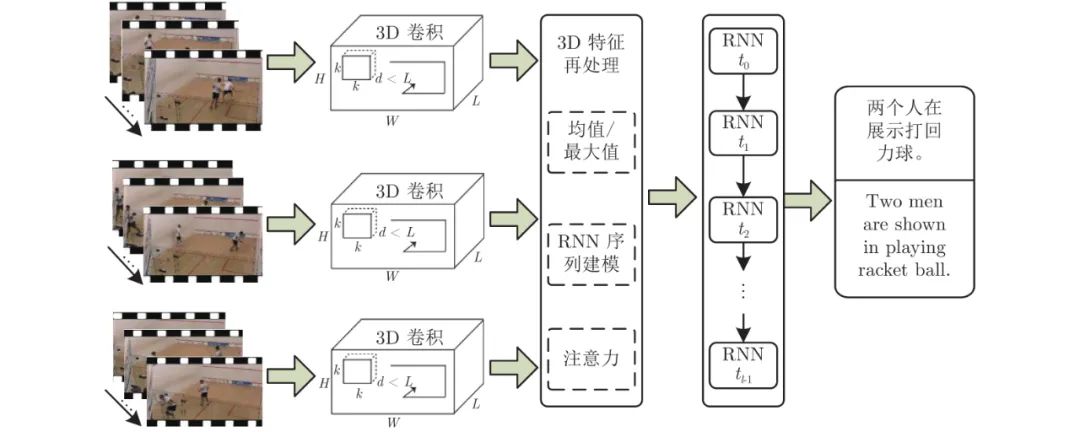
2. 基于神经网络的视频描述
3. 相关数据集与评价方法
4. 总结与展望
评论
 下载APP
下载APP
来源:专知 本文约5000字,建议阅读9分钟
最新视频视频标题生成与描述研究综述论文。
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c200662