
他山之石 | 美团知识图谱与商品理解
数据派THU
共 8458字,需浏览 17分钟
·
2022-05-26 21:05

本文约8000字,建议阅读15+分钟
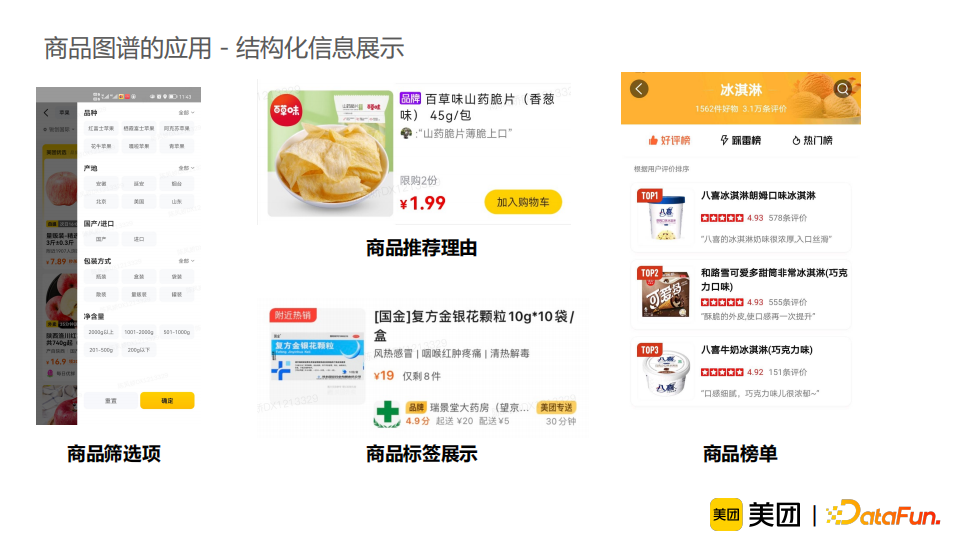
本次分享将着重介绍如何利用美团大脑中已建设的商品图谱,发挥知识数据的价值,提供更加精准的商品理解能力。
在模型探索方面,我们将介绍基于知识增强的商品理解模型,通过多阶段知识增强,提升模型准确性和泛化性。 在模型训练方面,我们将分享一些样本治理方面的经验和心得,以更加高效、低成本的方式提升模型能力。
美团大脑简介 知识增强的商品理解 样本治理 商品图谱的应用


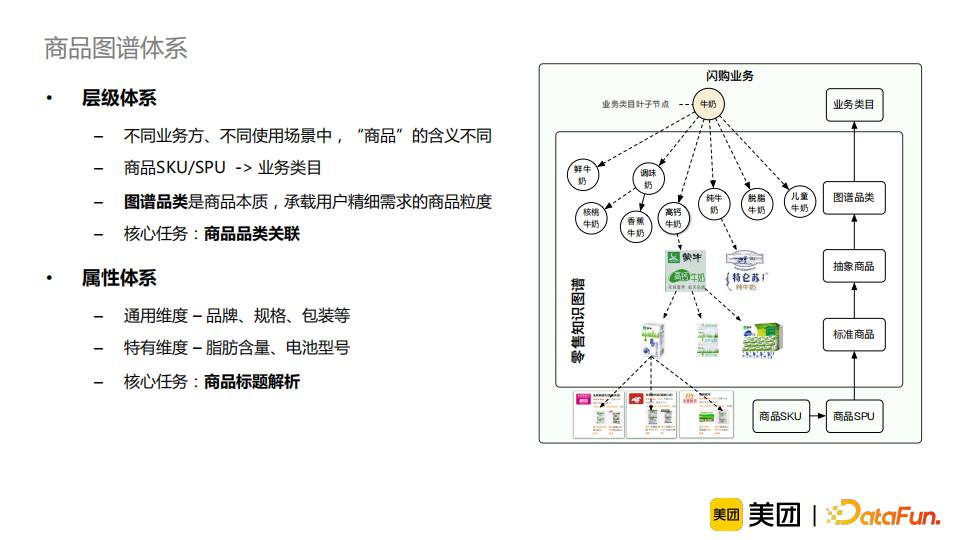

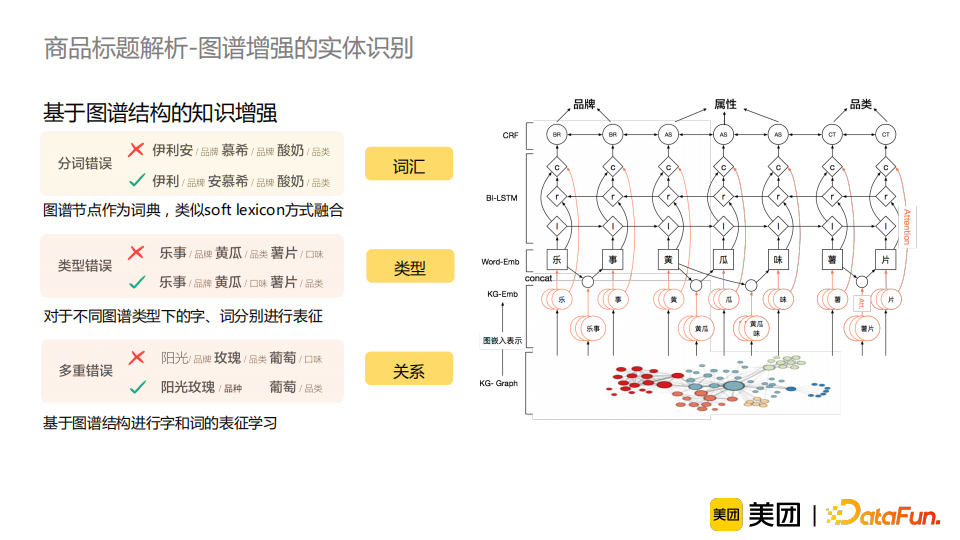
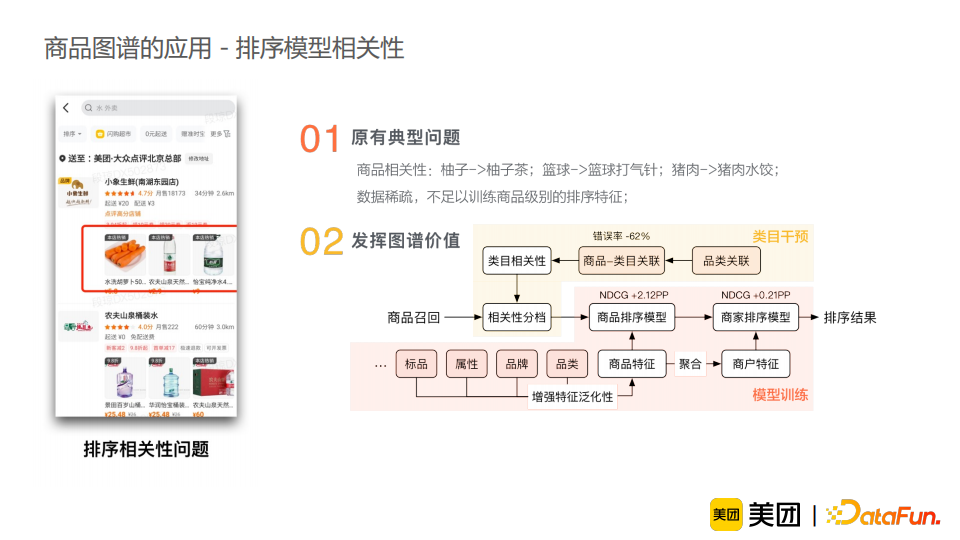
商品中品类、品牌垂域特有的词汇较多。如“伊利”“安慕希”“酸奶”这一例子,若模型没有见过“伊利”、“安慕希”这一类词汇,它很难对标题做出正确的切分; 消歧需要依赖常识知识。比如“乐事”“黄瓜”“薯片”这一例子,“黄瓜”可以是一个品类或者是一个口味,这需要知识来辅助模型进行正确地消歧; 标注数据少且含有较多噪音。这是因为实体识别任务标注难度较大,所以样本中难免包含错误信息。这就意味着我们的模型不能仅仅依赖标注的数据来进行实体识别任务,还应适当地引入外部的知识作为辅助。


通过衡量在当前的商品下词汇的相关度,显式地对词汇进行消岐,使这个过程变得可解释; 通过融入容易获得的知识z作为锚点,计算商品到知识z的分布和词汇到知识z的分布,间接地得到商品与词汇的关联; 通过融合统计特征作为先验知识,达到在线可控的目的。例如对于一个新词或者发现一类有错误的词汇,我们可以通过改变其对应的统计特征来在线干预一类问题。
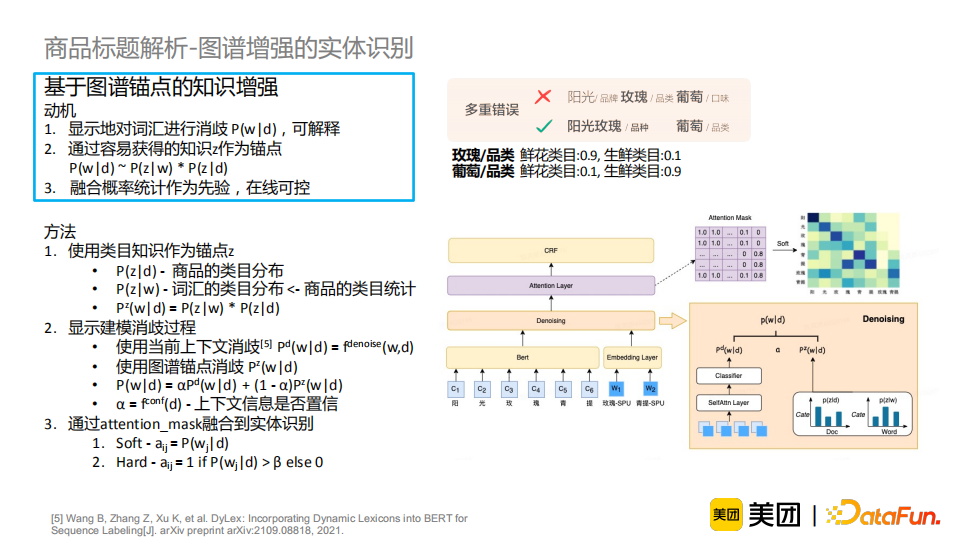
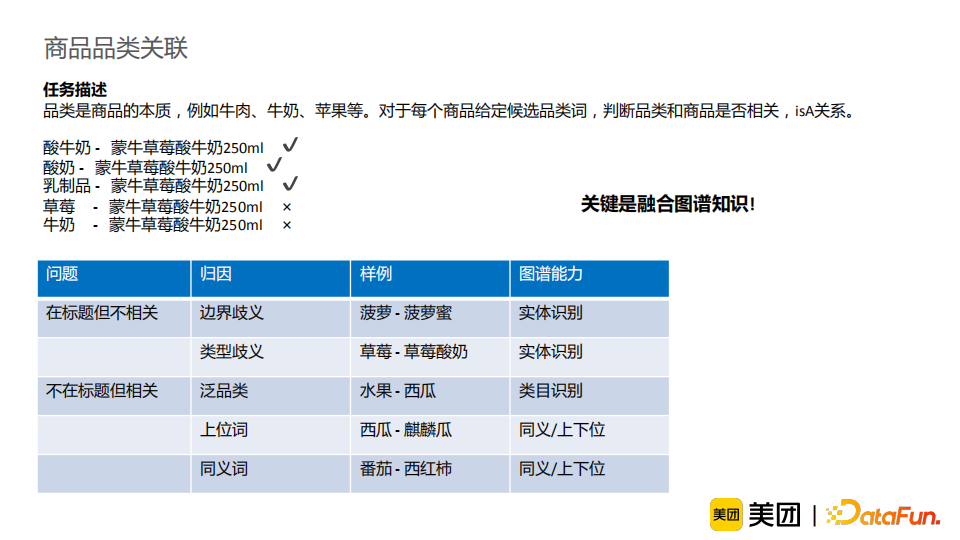
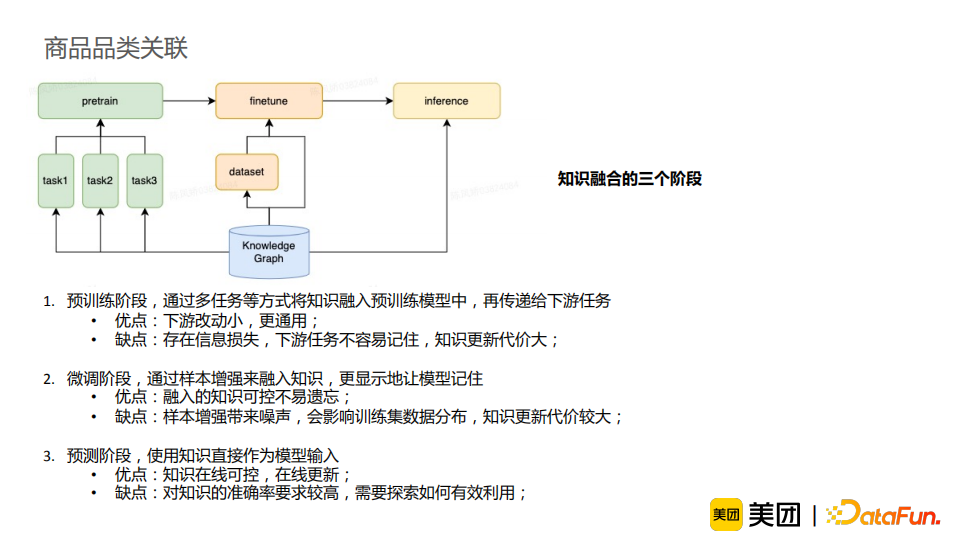
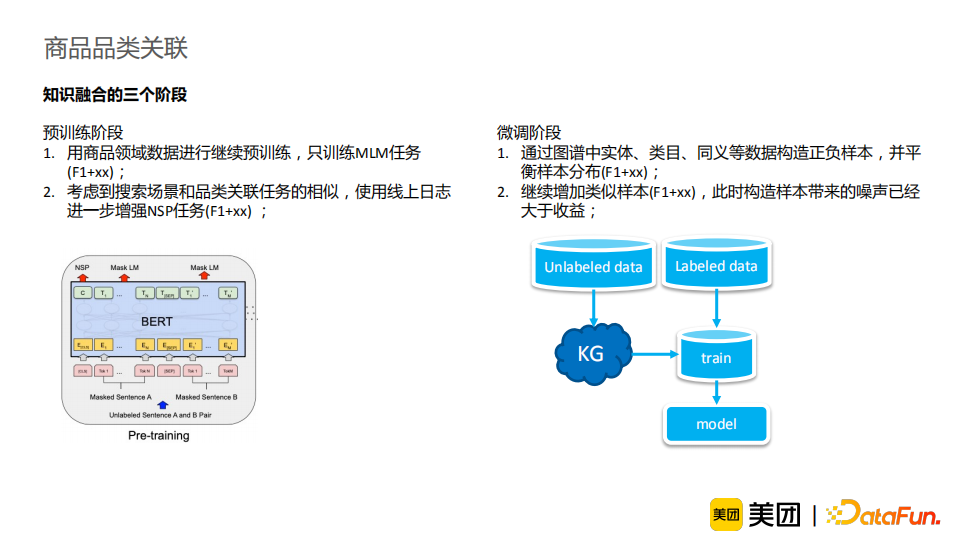
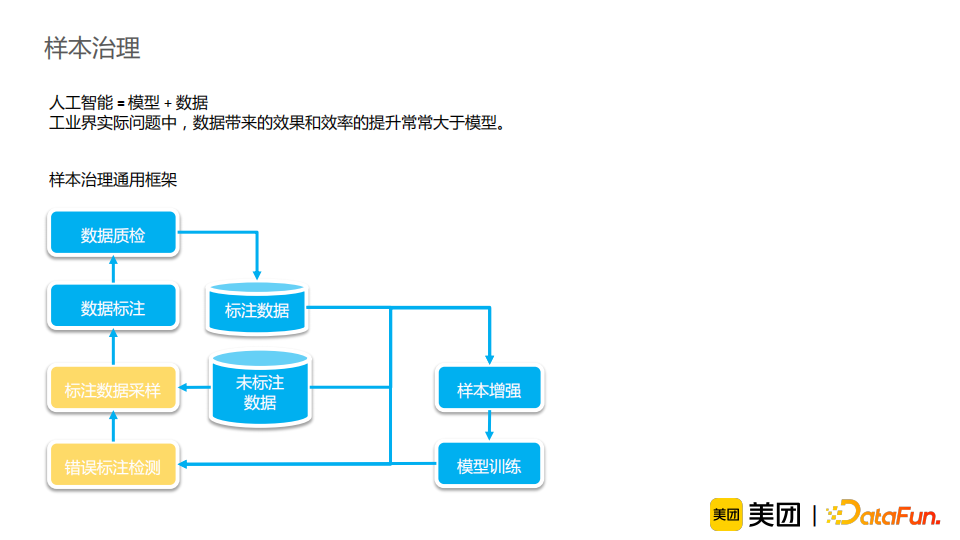

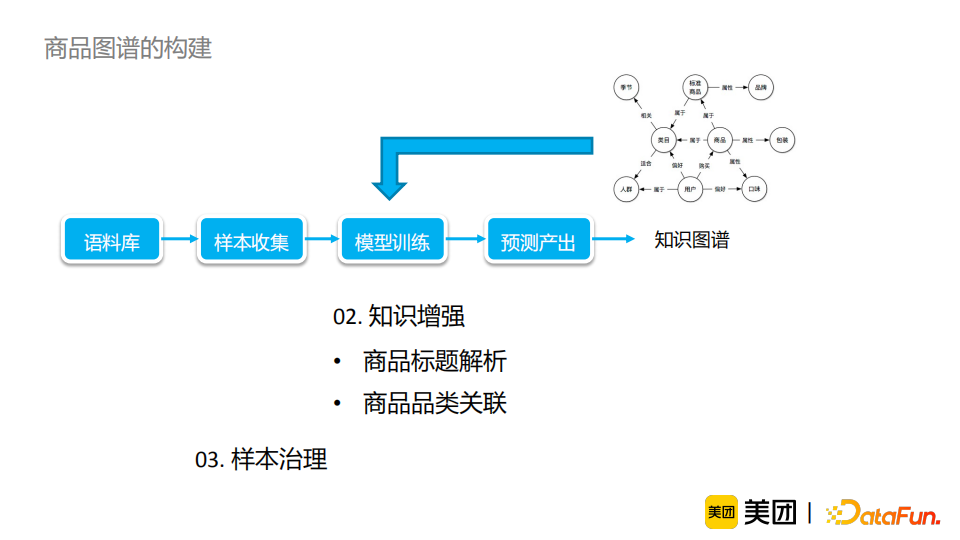
知识增强:介绍了如何充分利用图谱知识丰富信息,并借助容易获取的知识来解决较难的任务。进一步地,我们将知识融合分为三个阶段,并进行相应使用的介绍。从结果来看,知识增强能有效提升模型效果,并使模型解释性更强,并且在线可控,适合工业界需求,其潜力仍待挖掘。 样本治理:介绍了标注数据采样和错误样本检测的经验和方法。模型与数据是缺一不可的,样本治理的工作应当受到重视并得到积累。
评论