
【精华总结】全文4000字、20个案例详解Pandas当中的数据统计分析与排序
Pandas模块当中的数据统计与排序,说到具体的就是value_counts()方法以及sort_values()方法。value_counts()方法,顾名思义,主要是用于计算各个类别出现的次数的,而sort_values()方法则是对数值来进行排序,当然除了这些,还有很多大家不知道的衍生的功能等待被挖掘,下面小编就带大家一个一个的说过去。导入模块并且读取数据库
import pandas as pd
df = pd.read_csv("titanic_train.csv")
df.head()
output

常规的用法
首先我们来看一下常规的用法,代码如下
df['Embarked'].value_counts()
output
S 644
C 168
Q 77
Name: Embarked, dtype: int64
下面我们简单来介绍一下value_counts()方法当中的参数,
DataFrame.value_counts(subset=None,
normalize=False,
sort=True,
ascending=False,
dropna=True)
subset: 表示根据什么字段或者索引来进行统计分析 normalize: 返回的是比例而不是频次 ascending: 降序还是升序来排 dropna: 是否需要包含有空值的行
对数值进行排序
df['Embarked'].value_counts(ascending=True)
output
Q 77
C 168
S 644
Name: Embarked, dtype: int64
对索引的字母进行排序
同时我们也可以对索引,按照字母表的顺序来进行排序,代码如下
df['Embarked'].value_counts(ascending=True).sort_index(ascending=True)
output
C 168
Q 77
S 644
Name: Embarked, dtype: int64
当中的ascending=True指的是升序排序
包含对空值的统计
value_counts()方法不会对空值进行统计,那要是我们也希望对空值进行统计的话,就可以加上dropna参数,代码如下df['Embarked'].value_counts(dropna=False)
output
S 644
C 168
Q 77
NaN 2
Name: Embarked, dtype: int64
百分比式的数据统计
df['Embarked'].value_counts(normalize=True)
output
S 0.724409
C 0.188976
Q 0.086614
Name: Embarked, dtype: float64
Pandas中加以设置,对数据的展示加以设置,代码如下pd.set_option('display.float_format', '{:.2%}'.format)
df['Embarked'].value_counts(normalize = True)
output
S 72.44%
C 18.90%
Q 8.66%
Name: Embarked, dtype: float64
当然除此之外,我们还可以这么来做,代码如下
df['Embarked'].value_counts(normalize = True).to_frame().style.format('{:.2%}')
output
Embarked
S 72.44%
C 18.90%
Q 8.66%
连续型数据分箱
Pandas模块当中的cut()方法相类似的在于,我们这里也可以将连续型数据进行分箱然后再来统计,代码如下df['Fare'].value_counts(bins=3)
output
(-0.513, 170.776] 871
(170.776, 341.553] 17
(341.553, 512.329] 3
Name: Fare, dtype: int64
Fare这一列同等份的分成3组然后再来进行统计,当然我们也可以自定义每一个分组的上限与下限,代码如下df['Fare'].value_counts(bins=[-1, 20, 100, 550])
output
(-1.001, 20.0] 515
(20.0, 100.0] 323
(100.0, 550.0] 53
Name: Fare, dtype: int64
分组再统计
pandas模块当中的groupby()方法允许对数据集进行分组,它也可以和value_counts()方法联用更好地来进行统计分析,代码如下df.groupby('Embarked')['Sex'].value_counts()
output
Embarked Sex
C male 95
female 73
Q male 41
female 36
S male 441
female 203
Name: Sex, dtype: int64
Series数据结构,要是我们想让Series的数据结果编程DataFrame数据结构,可以这么来做,df.groupby('Embarked')['Sex'].value_counts().to_frame()数据集的排序
sort_values()方法,例如我们根据“年龄”这一列来进行排序,排序的方式为降序排,代码如下df.sort_values("Age", ascending = False).head(10)
output
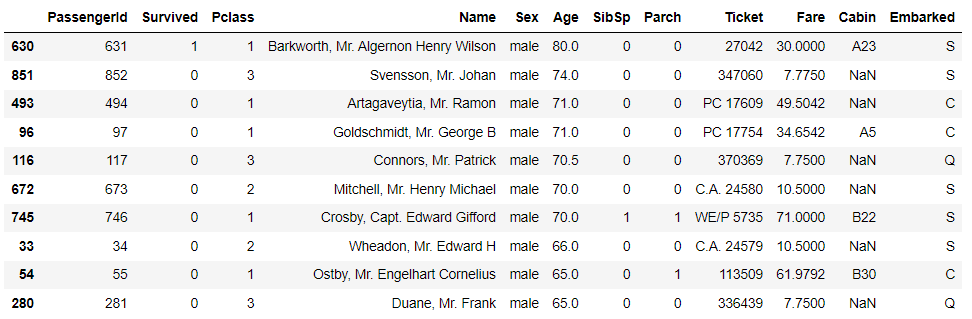
对行索引重新排序
DataFrame数据集行索引依然没有变,我们希望行索引依然可以是从0开始依次的递增,就可以这么来做,代码如下df.sort_values("Age", ascending = False, ignore_index = True).head(10)
output
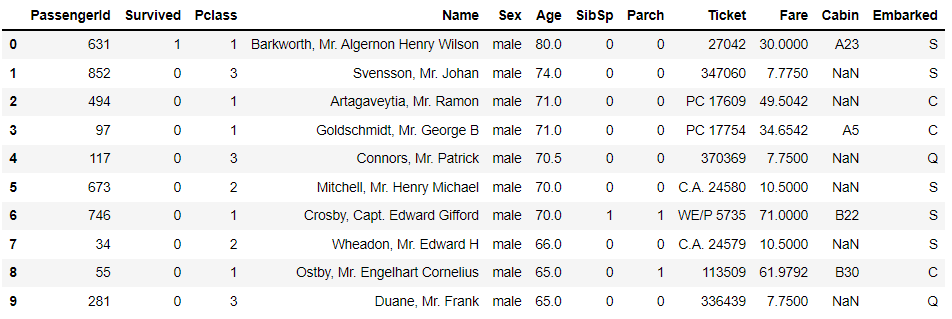
下面我们简单来介绍一下sort_values()方法当中的参数
DataFrame.sort_values(by,
axis=0,
ascending=True,
inplace=False,
kind='quicksort',
na_position='last', # last,first;默认是last
ignore_index=False,
key=None)
by: 表示根据什么字段或者索引来进行排序,可以是一个或者是多个 axis: 是水平方向排序还是垂直方向排序,默认是垂直方向 ascending: 排序方式,是升序还是降序来排 inplace: 是生成新的 DataFrame还是在原有的基础上进行修改kind: 所用到的排序的算法,有快排quicksort或者是归并排序mergesort、堆排序heapsort等等 ignore_index: 是否对行索引进行重新的排序
对多个字段的排序
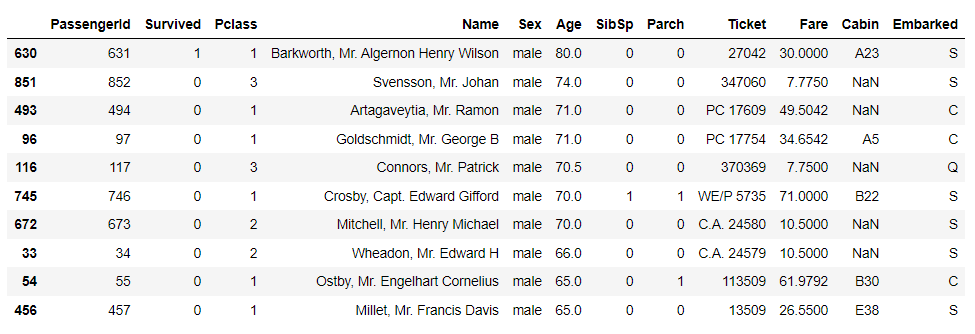
我们还可以对多个字段进行排序,代码如下
df.sort_values(["Age", "Fare"], ascending = False).head(10)
output
同时我们也可以对不同的字段指定不同的排序方式,如下
df.sort_values(["Age", "Fare"], ascending = [False, True]).head(10)
output
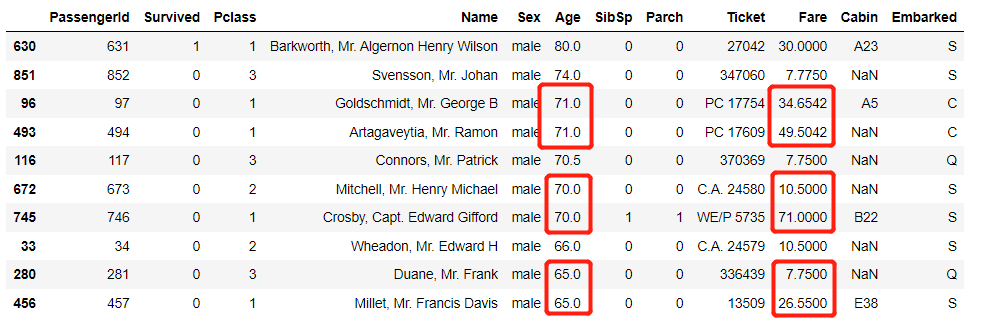
我们可以看到在“Age”一样的情况下,“Fare”字段是按照升序的顺序来排的
自定义排序
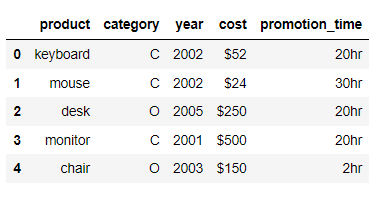
sort_values()方法当中,让其按照自己写的方法来排序,我们看如下的这组数据df = pd.DataFrame({
'product': ['keyboard', 'mouse', 'desk', 'monitor', 'chair'],
'category': ['C', 'C', 'O', 'C', 'O'],
'year': [2002, 2002, 2005, 2001, 2003],
'cost': ['$52', '$24', '$250', '$500', '$150'],
'promotion_time': ['20hr', '30hr', '20hr', '20hr', '2hr'],
})
output
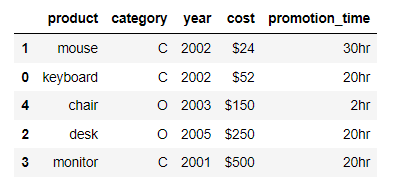
lambda方法自定义一个函数方法运用在sort_value()当中df.sort_values(
'cost',
key=lambda val: val.str.replace('$', '').astype('float64')
)
output
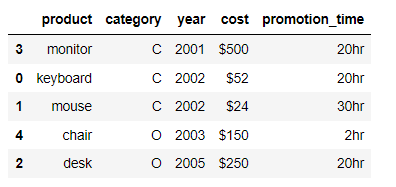
sort_values()方法当中,代码如下def sort_by_cost_time(x):
if x.name == 'cost':
return x.str.replace('$', '').astype('float64')
elif x.name == 'promotion_time':
return x.str.replace('hr', '').astype('int')
else:
return x
df.sort_values(
['year', 'promotion_time', 'cost'],
key=sort_by_cost_time
)
output
XS码、S码、M码、L码又或者是月份,Jan、Feb、Mar、Apr等等,需要我们自己去定义大小,这个时候我们需要用到的是CategoricalDtypecat_size_order = CategoricalDtype(
['XS', 'S', 'M', 'L', 'XL'],
ordered=True
)
cat_size_order
output
CategoricalDtype(categories=['XS', 'S', 'M', 'L', 'XL'], ordered=True)
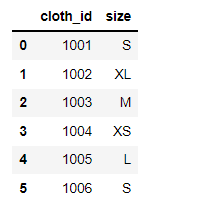
于是针对下面的数据
df = pd.DataFrame({
'cloth_id': [1001, 1002, 1003, 1004, 1005, 1006],
'size': ['S', 'XL', 'M', 'XS', 'L', 'S'],
})
output
我们将事先定义好的顺序应用到该数据集当中,代码如下
df['size'] = df['size'].astype(cat_size_order)
df.sort_values('size')
output
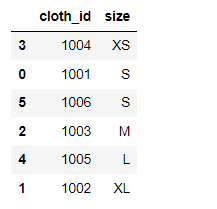
先通过astype()来转换数据类型,然后再进行排序。


评论