
模型压缩经典解读:解决训练数据问题,无需数据的神经网络压缩技术

极市导读
目前很少有工作关注在无数据情况下的网络压缩,然而,这些方法得到的压缩后的网络准确率下降很多,这是因为这些方法没有利用待压缩网络的信息。为了解决这一问题,本文介绍2种无需训练数据的网络压缩方法。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 无需训练数据的网络压缩技术 DAFL (ICCV 2019)
(来自华为诺亚方舟实验室)
1.1 DAFL 原理分析
1.11 知识蒸馏方法获得学生网络
1.12 通过 GAN 生成无标注的训练图片
1.13 实验结果2 适合大数据集的无需训练数据的网络压缩技术 (Arxiv 2021)
(来自谷歌)
2.1 原理分析
2.11 知识蒸馏方法获得学生网络
2.12 通过 GAN 生成无标注的训练图片
2.13 使用多个生成器
2.14 实验结果
随着深度学习技术的发展,深度神经网络 (CNN) 已经被成功的应用于许多实际任务中 (例如,图片分类、物体检测、语音识别等)。由于CNN需要巨大的计算资源,为了将它直接应用到手机、摄像头等小型移动设备上,许多神经网络的压缩和加速算法被提出。现在的问题是这些神经网络的压缩和加速算法都有一个基本的假设,那就是:训练数据是可获得的。
但是实际情况是:在现实中的应用上,由于隐私因素的制约或者传输条件的限制,我们无法获得训练数据。比如:在医学图像场景中,用户不想让自己的照片 (数据) 被泄露;训练数据太多没办法传到云端,甚至是存储这些巨大量的数据集对于小型企业都是个难题;所以,使用常规的模型压缩办法在这些限制下无法被使用。
甚至,预训练网络的基本架构和参数都是未知的,就像一个黑盒,只能通过输入来获取输出信息。所以剪枝,量化等等常用的模型压缩方法就更无从下手了。
但是,目前很少有工作关注在无数据情况下的网络压缩,然而,这些方法得到的压缩后的网络准确率下降很多,这是因为这些方法没有利用待压缩网络的信息。为了解决这一问题,本文介绍2种无需训练数据的网络压缩方法。
在这里需要强调的一点是:当前有许多用 GAN 来生成自然图像/高清图片/漫画图片/风格迁移/去雨/去噪/去模糊/去马赛克,等等等等各种生成任务。但是,它们无一例外在 GAN 模型的训练过程中都使用了大量的训练数据,而这在实际的业务条件下有时候是不被允许的。
1 无需训练数据的网络压缩技术 DAFL (ICCV 2019)
论文名称:Data-Free Learning of Student Networks
论文地址:
https://arxiv.org/pdf/1904.01186
开源地址:
https://github.com/huawei-noah/DAFL
1.1 DAFL 原理分析:
华为诺亚方舟实验室联合北京大学和悉尼大学提出了在无数据情况下的网络蒸馏方法 DAFL,比之前的最好算法在MNIST上提升了6个百分点,并且使用 resnet18 在 CIFAR-10 和 100 上分别达到了 92% 和 74% 的准确率 (无需训练数据)。
它的特点是:
待压缩网络看作一个固定的判别器 。 用生成器 输出的生成图片代替训练数据集进行训练。 设计了一系列的损失函数来训练生成器 。 使用生成数据结合蒸馏算法得到压缩后的网络。
主要步骤是:
通过待压缩网络训练生成器 通过生成器 输出生成图片作为训练样本 通过训练样本蒸馏待压缩网络 得到压缩后的网络
1.11 知识蒸馏方法获得学生网络
蒸馏算法最早由Hinton提出,待压缩网络 (教师网络) 为一个具有高准确率但参数很多的神经网络,初始化一个参数较少的学生网络,通过让学生网络的输出和教师网络相同,学生网络的准确率在教师的指导下得到提高。
从结构和参数的角度看,如上文所述,待压缩的大网络的结构和参数都是未知的,这就使得我们无法通过剪枝或者量化等经典的神经网络压缩方法进行模型压缩,我们唯一已知的就是待压缩的大网络的输入和输出接口。
从训练数据的角度看,DAFL 的训练样本是由生成器 生成的,是没有标签的,所以没法通过有监督的方式学习学生网络,基于这两点,作者引入了教师学生网络学习范式,利用蒸馏算法实现利用未标注生成样本对黑盒网络的压缩。
令 和 分别代表教师和学生网络,则作者使用交叉熵损失来使得学生网络的输出符合教师网络的输出,具体的损失函数为:
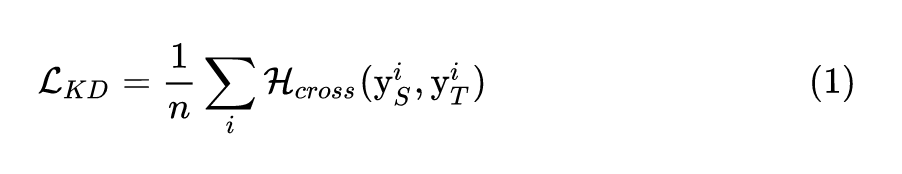
式中, 指交叉熵损失函数, 和 分别是教师和学生网络的输出。通过引入教师学生算法,作者解决了生成图片没有标签的问题,并且可以在待压缩网络结构未知的情况下对其进行压缩。
1.12 通过 GAN 生成无标注的训练图片
从训练数据的角度看,在整个网络压缩的过程中,我们都没有任何给定的训练数据,在此情况下,神经网络的压缩变得十分困难。所以作者通过 GAN 来输出一些无标注的训练图片,以便于神经网络的压缩。生成对抗网络 (GAN) 是一种可以生成数据的方法,包含生成网络 与判别网络 ,生成网络希望输出和真实数据类似的图片来骗过判别器,判别网络通过判别生成图片和真实图片的真伪来帮助生成网络训练。
具体而言,给定一个任意的噪声向量 (noise vector) ,生成器 会把它映射成虚假的图片 即 。另一方面, 判别器 要区分来的一张图片是真实的 还是生成器伪造的 , 所以,对于 GAN 而言,它的目标函数可以写成:
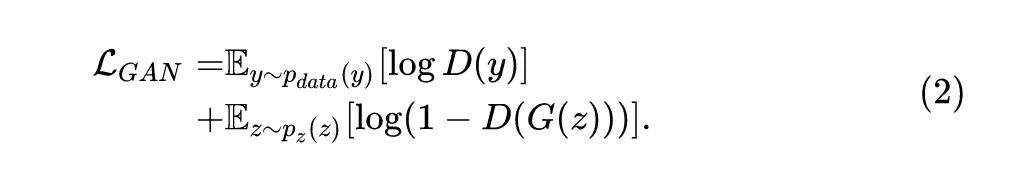
这个目标函数 的优化方法是 。就是每轮优化分为2步,第1步是通过 gradient ascent 优化 的参数,第2步是通过 gradient descent 优化 的参数。然而,我们会 发现传统的 GAN 需要基于真实数据 来训练判别器,这对于我们来说是无法进行的。所以基于传 统的 GAN 训练方法 2 式是不行的。
许多研究表明,训练好的判别器 具有提取图像特征的能力,提取到的特征可以直接用于分类任务,所以,由于待压缩网络使用真实图片进行训练,也同样具有提取特征的能力,从而具有一定的分辨图像真假的能力。而且这个待压缩网络我们是已有的。于是,我们把待压缩网络作为一个固定的判别器 ,以此来训练我们的生成网络 。
首先,待压缩网络作为一个固定的判别器 ,我们就认为它是已经训练好参数的判别器 ,我们利用它来训练生成器的基本思想是下式:
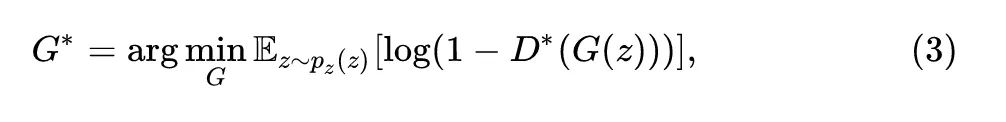
式中, 就是已经训练好参数的判别器,生成器 的参数经过3式持续优化使得 逐渐上升,代表着生成器的输出越来越能够骗过判别器。
但是,在传统GAN中,传统的判别器 的输出是判定图片是否真假 (Real or Fake?),只要让生成网络生成在判别器中分类为真的图片即可训练,但是,我们的待压缩网络为分类网络,其输出是分类结果 (1-num_classes),所以待压缩网络无法直接作为一个固定的判别器 。因此需要重新设计生成网络的目标。通过观察真实图片在分类网络的响应,作者提出了以下损失函数。
1) 伪标签交叉熵损失
在图像分类任务中,神经网络的训练采用的是交叉熵损失函数,在训练完成后,真实图片在网络中的输出将会是一个one-hot的向量,即分类类别对应的输出为1,其他的输出为0。于是,我们希望生成图片也具有类似的性质。给定一组任意的噪声向量 ,它们通过生成器 之后得到的生成图片是 ,这里 。
现在把这些生成图片 输入给待压缩的网络,通过 得到输出 ,预测标签就是通过 计算得到 。定义伪标签交叉熵损失为:
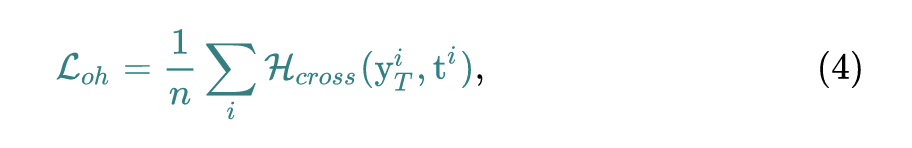
其中 就是标准的交叉熵函数,由于生成图片并没有一个真实的标签,我们直接将其输出最大值对应的标签设定为它的伪标签。 伪标签交叉熵损失的意思就是对于一张生成的图片,它的标签就按照教师网络的输出来决定,这是训练生成器 的第1个损失。
2) 特征激活损失函数
在神经网络的训练中,由卷积核提取的特征也是输入图片的一种重要表示。先前的许多工作表明,卷积核提取的特征包含着图片的许多重要信息,将训练数据输入训练好的深度网络中,卷积核会产生更大的响应 (相比于噪声或与此网络无关的数据),基于此,作者提出了特征激活损失函数。定义生成图片 经过教师网络得到的特征是 ,则特征激活损失函数定义为:
反向传播优化生成器参数的方法是:
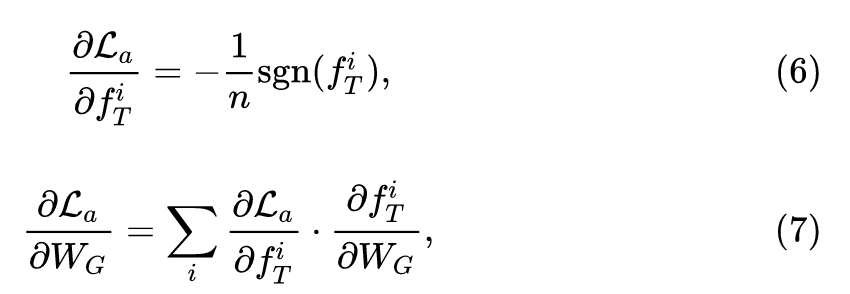
因为待压缩网络 (即教师网络) 是训练好的,所以目标是让生成图像在待压缩网络中的特征响应值更大,来使图片更接近训练数据。这里作者采用了1范数来优化,原因是1范数相比于2范数会产生更加稀疏的值,而神经网络的响应也常常是稀疏的。
3) 信息熵损失函数
为了让神经网络更好的训练,真实的训练数据对于每个类别的样本数目通常都保持一致,例如MNIST每个类别都含有 6000 张图片。于是,为了让生成网络产生各个类别样本的概率基本相同,作者引入信息熵,信息熵是针对一个概率分布而言的。假设现在有概率分布 ,概率分布 的信息熵的计算方法就是:
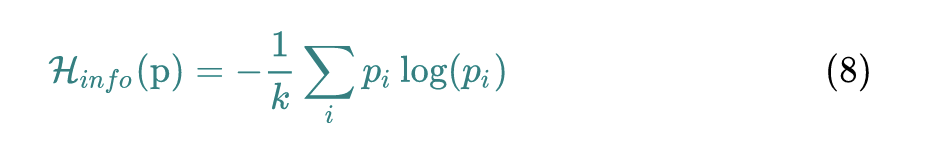
概率分布 越均匀,信息熵 就越小。极限情况当 时,信息熵 取极大值 。所以信息熵损失函数定义为:
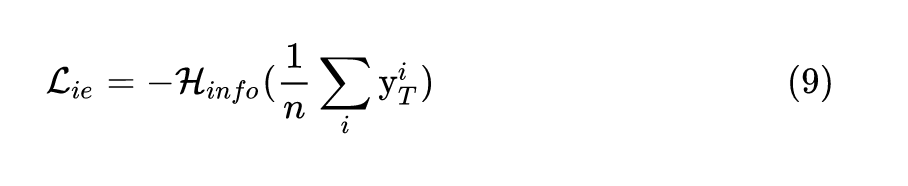
其中 为标准的信息熵,信息熵的值越大,对于生成的一组样本经过待压缩教师网络的输出特征 来讲,每个类别的数目就越平均,从而保证了生成样本的类别平均。
反向传播优化生成器参数的方法是:
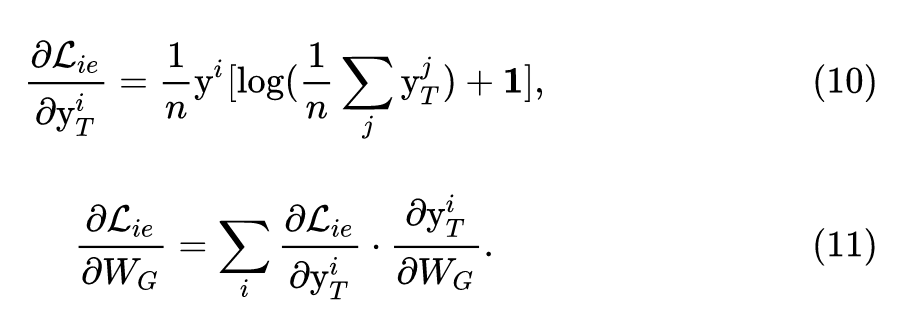
最后,我们将这三个损失函数 (4,5,9式) 组合起来,就可以得到我们生成器总的损失函数:
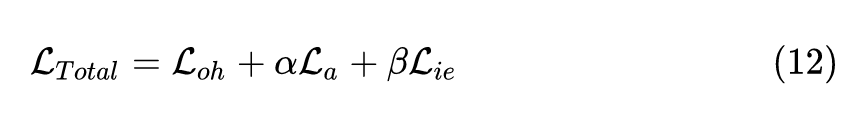
通过优化以上的损失函数,训练得到的生成器可以和真实的样本在待压缩网络具有类似的响应,从而更接近真实样本,且生成的数据的分布十分均匀。
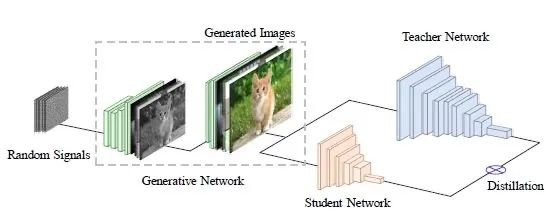
DAFL 的流程和算法如下图1和图2所示。把待压缩网络当做判别器 ,通过上式 12 作为损失函数来训练生成器 。通过生成器 来得到足够的生成图片,这些图片的分布与训练教师网络的训练数据是一致的。然后,再通过上式 1 的蒸馏损失和这些生成图片对教师网络进行蒸馏得到学生网络。

1.13 实验结果
作者在MNIST、CIFAR、CelebA三个数据集上分别进行了实验。
MNIST 实验
MNIST 数据集: 10类,60000 training+10000 testing。
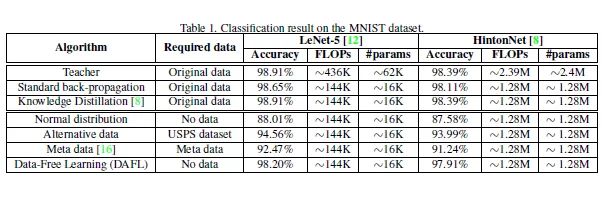
作者实验了卷积模型和全连接模型,卷积模型使用 LeNet-5。全连接模型使用 Hinton 提出的具有3个全连接层的网络 Hinton-784-1200-1200-10 作为待压缩模型,将他们的通道数目减半分别作为学生模型 (LeNet-5-HALF 和 Hinton-784-800-800-10)。
图3的前三行是在原始数据集的实验结果。我们以 LeNet-5 模型为例。
使用原始数据集,教师网络可以达到 98.91% 的精度。 使用原始数据集,学生网络可以达到 98.65% 的精度。 使用原始数据集,学生网络+蒸馏方法可以达到 98.91% 的精度,无损。 不使用任何数据集,只使用噪声图片+蒸馏方法只能达到 88.01% 的精度。 使用另一个替代数据集USUP,学生网络+蒸馏方法可以达到 94.56% 的精度。 不使用任何数据集,使用之前的一个基于元数据的方法可以达到 92.47% 的精度。 不使用任何数据集,使用 DAFL 方法可以达到 98.20% 的精度。大大超越了之前的方法,并且比使用替代数据集得到的结果也要好很多,和使用原始数据得到的结果基本相似。
CIFAR 实验
CIFAR-10 数据集: 10类,50000 training+10000 testing。
CIFAR-100 数据集: 100类,50000 training+10000 testing。
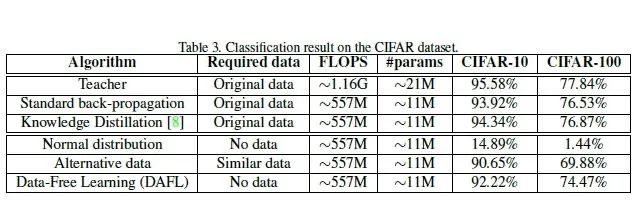
作者还在 CIFAR-10 和 CIFAR-100 数据集上进行了实验,使用的教师和学生模型分别为 Resnet-34 和 Resnet-18。
图3的前三行是在原始数据集的实验结果。我们以 CIFAR-10 数据集的结果为例。
使用原始数据集,教师网络可以达到 95.58% 的精度。 使用原始数据集,学生网络可以达到 93.92% 的精度。 使用原始数据集,学生网络+蒸馏方法可以达到 94.34% 的精度,轻微有损。 不使用任何数据集,只使用噪声图片+蒸馏方法只能达到 14.89% 的精度,相当于训练失败。 使用 CIFAR-10 的数据作为 CIFAR-100 的替代训练集,使用CIFAR-100 的数据作为 CIFAR-10 的替代训练集,虽然 CIFAR-10 和 CIFAR-100 非常相似,并且具有一些重叠的图片,然而,得到的结果距离使用原始数据集仍然有较大的差距,学生网络+蒸馏方法可以达到 90.65% 的精度,有损。证明了在实际情况中使用相似的数据集来替代原始数据集并不能取得很好效果。 不使用任何数据集,使用 DAFL 方法可以达到 92.22% 的精度。本论文提出的方法同样取得了和使用原始数据集的蒸馏算法相似的结果,并且超越了使用替代数据集的结果。
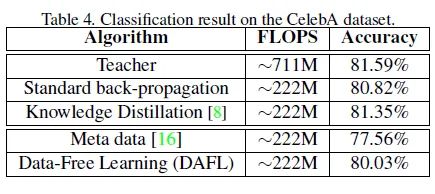
CelebA 实验
CelebA 数据集:202599 training images
作者又在 CelebA 数据集上进行了实验,使用的教师和学生模型分别为 AlexNet 和 AlexNet-Half。GAN 模型取 DCGAN。
使用原始数据集,教师网络可以达到 81.59% 的精度。 使用原始数据集,学生网络可以达到 80.82% 的精度。 使用原始数据集,学生网络+蒸馏方法可以达到 81.35% 的精度,轻微有损。 不使用任何数据集,使用之前的一个基于元数据的方法可以达到 77.56% 的精度。 不使用任何数据集,使用 DAFL 方法可以达到 80.03% 的精度,同样取得了很好的结果。
对比实验
由于我们的方法由很多损失函数组成,我们通过消融实验来分析每个损失函数项的必要性。对比试验的数据集是 MNIST,教师网络是 LeNet-5,学生网络是 LeNet-5-HALF。
下图6是消融实验的结果,一个三个损失函数:伪标签交叉熵损失,特征激活损失函数,信息熵损失函数。可以看到,如果一个都不用,就相当于是直接使用噪声蒸馏学生网络,则准确率是88.01%。使用不同的损失函数,精度如图,每一项损失都很重要。

可视化结果
作者对教师和学生得到的卷积核做了可视化,如下图7所示。可以发现,我们的方法学到的学生网络和教师网络具有非常相似的结构,证明了本论文方法的有效性。

作者还对训练得到的生成器 产生的图片进行了可视化,如下图8所示。注意生成的图像是没有 label 的,它们的类别是由教师网络的预测定义的。图8显示了每个类图像的平均值。虽然没有提供真实的图像,但生成的图像与训练图像具有相似的模式,这说明生成器可以以某种方式学习数据的分布。

小结
DAFL 是一个新的无需训练数据的网络压缩方法,它的特点是: 待压缩网络看作一个固定的判别器 ,用生成器 输出的生成图片代替训练数据集进行训练,设计了伪标签交叉熵损失,特征激活损失函数,信息熵损失函数来训练生成器 ,使用生成数据结合蒸馏算法得到压缩后的网络。
2 适合大数据集的无需训练数据的网络压缩技术 (Arxiv 2021)
论文名称:Large-Scale Generative Data-Free Distillation
论文地址:
Large-Scale Generative Data-Free Distillation
https://arxiv.org/abs/2012.05578
2.1 原理分析:
谷歌提出的这个适合大数据集的无需训练数据的网络压缩技术基于上节介绍的 DAFL,解决的主要问题是 DAFL 没法在大数据集上使用的问题。
知识蒸馏方法是解决无标注模型压缩问题的一种重要的手段。但是正如前文所述,它的假设是在蒸馏阶段训练数据集是可得到的。但是实际情况是:在现实中的应用上,由于隐私因素的制约或者传输条件的限制,我们无法获得训练数据。比如:在医学图像场景中,用户不想让自己的照片 (数据) 被泄露;训练数据太多没办法传到云端,甚至是存储这些巨大量的数据集对于小型企业都是个难题;所以,使用常规的模型压缩办法在这些限制下无法被使用。
上节介绍的 DAFL 是一个新的无需训练数据的网络压缩方法,它的特点是: 待压缩网络看作一个固定的判别器 ,用生成器 输出的生成图片代替训练数据集进行训练,设计了伪标签交叉熵损失,特征激活损失函数,信息熵损失函数来训练生成器 ,使用生成数据结合蒸馏算法得到压缩后的网络。
本文就是基于 DAFL 实现的,解决了 DAFL 无法在大数据集 ImageNet 上使用的问题。
在这里需要再次强调的一点是:当前有许多用 GAN 来生成自然图像/高清图片/漫画图片/风格迁移/去雨/去噪/去模糊/去马赛克,等等等等各种生成任务。但是,它们无一例外在 GAN 模型的训练过程中都使用了大量的训练数据,而这在实际的业务条件下有时候是不被允许的。
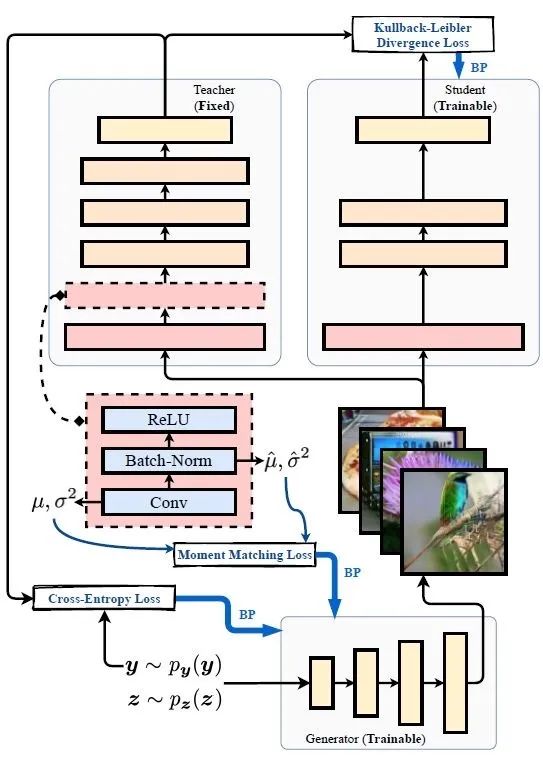
本文的方法框架如下图9所示。本质上和 DAFL 的两个阶段是一致的,都是先用生成器 输出的生成图片代替训练数据集进行训练,然后使用生成数据结合蒸馏算法得到压缩后的网络。下面介绍作者是怎么做,能够解决了 DAFL 无法在大数据集 ImageNet 上使用的问题的。
2.11 知识蒸馏方法获得学生网络
蒸馏算法最早由Hinton提出,待压缩网络 (教师网络) 为一个具有高准确率但参数很多的神经网络,初始化一个参数较少的学生网络,通过让学生网络的输出和教师网络相同,学生网络的准确率在教师的指导下得到提高。
从结构和参数的角度看,如上文所述,待压缩的大网络的结构和参数都是未知的,这就使得我们无法通过剪枝或者量化等经典的神经网络压缩方法进行模型压缩,我们唯一已知的就是待压缩的大网络的输入和输出接口。
令 和 分别代表教师和学生网络,则作者使用交叉熵损失来使得学生网络的输出符合教师网络的输出,具体的损失函数为:
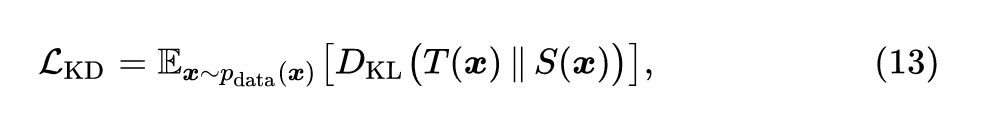
式中, 指KL 散度损失函数,描述的是教师网络和学生网络的输出的差异, 指训练数据的分布,这里的训练数据和 DAFL 一样后续通过 GAN 来生成。通过引入教师学生算法,作者解决了生成图片没有标签的问题,并且可以在待压缩网络结构未知的情况下对其进行压缩。
2.12 通过 GAN 生成无标注的训练图片
从训练数据的角度看,在整个网络压缩的过程中,我们都没有任何给定的训练数据,在此情况下,神经网络的压缩变得十分困难。所以作者通过 GAN 来输出一些无标注的训练图片,以便于神经网络的压缩。生成对抗网络 (GAN) 是一种可以生成数据的方法,包含生成网络 与判别网络 ,生成网络希望输出和真实数据类似的图片来骗过判别器,判别网络通过判别生成图片和真实图片的真伪来帮助生成网络训练。
这个基本的流程和 DAFL 是一致的,但是本文的目标函数设计与 DAFL 有差别。
1) Inceptionism loss
这个损失函数设计来自于 Inceptionism: Going deeper into neural networks 这篇论文。Inceptionism-style 图像生成,又叫做 DeepDream,是一种在已训练好的网络情况下,可视化能产生特定输出的输入图片的样子的方法。比如现在有一个训练好的网络,我们想知道什么样的图片可以让这个网络分类为 "狗"。怎么做呢?首先用随机噪声初始化一个可训练的图片 trainable image,不断地更新其参数,使得这个已有的网络的输出与 "狗" 这个类越接近越好,也就是训练这个 trainable image,让网络输出更像 "狗"。
那么回到我们的任务上面,我们现在有一个生成器 ,它会输出一堆图片,比如说其中一张是 ,作者依然是使用给定的,预训练好的教师网络的输出来标注它:
我们认为 就是这张图片 对应的类别。那么在训练生成器 的时候需要优化下式这个损失函数:
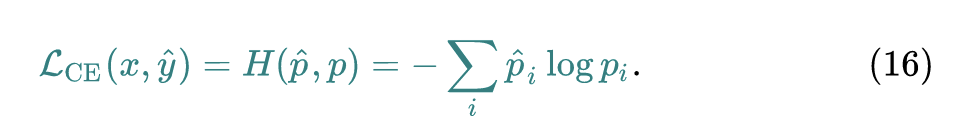
式16其实和式4是一模一样的,都是标准的交叉熵函数,由于生成图片并没有一个真实的标签,我们直接将其输出最大值对应的标签设定为它的伪标签。 伪标签交叉熵损失的意思就是对于一张生成的图片,它的标签就按照教师网络的输出来决定。
不同的是 Inceptionism loss 不只是单单优化式16,为了使得生成的图片更加接近自然图片,作者另外加了一个先验,比如相邻像素之间的特定联系,体现在加了一个归一化损失:
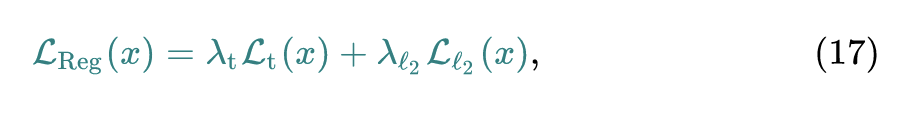
式中, 是指 total variation loss, 是指 范数,其加权就是这个归一化损失。
所以,Inceptionism loss 就是再结合16式和这个归一化损失:
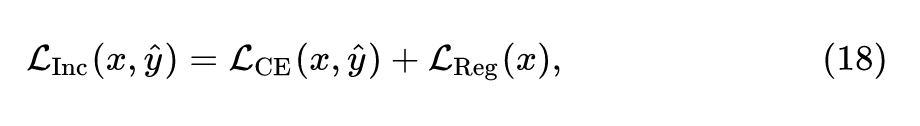
2) Moment matching loss
Inceptionism loss 只对教师网络的输出做了约束,现在还没有对于中间层的约束。 之前的研究表明神经网络的不同层的输出具有不同的特点,也可以用在不同的任务上面。比如浅层的输出一般是用于检测一些低阶特征比如说物体的边角等等;深层的输出一般是用于检测一些高阶特征比如说语义信息。根据实际情况数据的观测,只使用 Inceptionism loss 会导致中间特征出现异常值,所以这启发作者要针对中间特征加一些约束项。
作者考虑到了 Batch Norm 层,它可以帮助提供这些中间特征。Batch Norm 操作一般是通过滑动平均的均值和方差 ( moving averaged mean and variance) re-centering 和 rescaling 来归一化中间层的输出,所以说 Batch Norm 层其实隐式地存储了输入数据的一些信息。
给定教师网络的 Batch Norm 层的均值和方差 ,我们去计算某张生成的图片 的均值和方差 ,我们希望它们尽量地接近,方法就是:
最小化 散度:
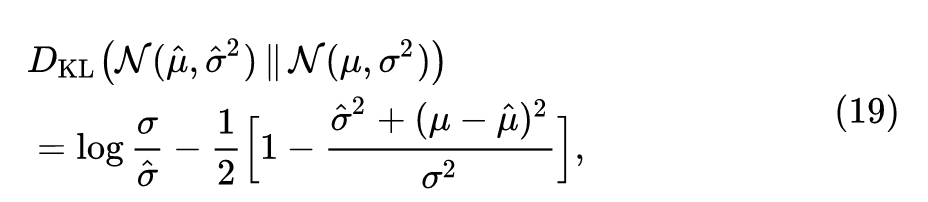
式中 代表高斯分布。
或者直接距离接近:
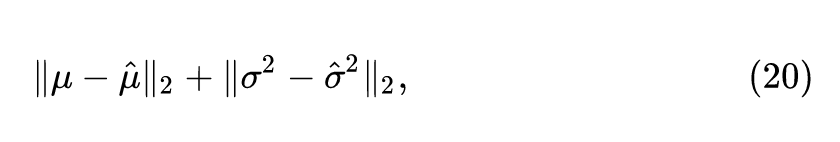
本文最终使用了式20的方法,简单直接,所以 Moment matching loss 定义为:
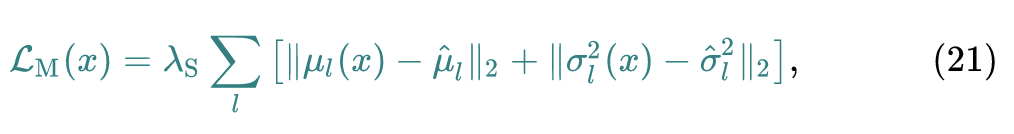
最后,我们将这三个损失函数 (17,21式) 组合起来,就可以得到我们生成器总的损失函数:
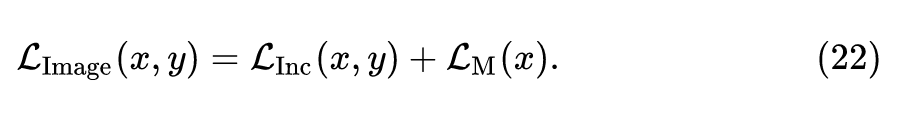
生成器的优化目标是:
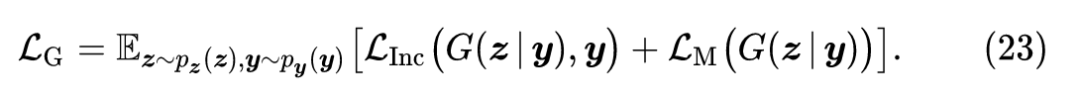
通过优化以上的损失函数,训练得到的生成器可以和真实的样本在待压缩网络具有类似的响应,从而更接近真实样本,且生成的数据的分布十分均匀。
2.13 使用多个生成器
模式坍塌是 GAN 网络中的一个很严重的问题,生成器 往往不会输出各式各样的生成图片,反而会产生很单一的样式的图片,且不会随着输入隐变量的变化而变化。
为什么在这个任务中会产生模式坍塌的问题?一种可能的解释是:生成器持续地产生一种图片,这种图片经过教师网络会输出一个很像 One-hot 编码的结果,这个结果就会导致 消失了,即使其他的损失函数还没有优化到最优值。下图10就是一个典型的模式坍塌的例子,生成器 生成了很多的自然图片,但是无一例外都是红色的车。

为了解决模式坍塌的问题,训练多个 Generator 是一种简单有效的解决模式坍塌问题的方法。每个 Generator 只生成一个类的数据,比如说在训练第1个 Generator 时,它的训练目标就是使得教师网络的输出和 越接近越好。生成的图片如下图所示。

2.14 实验结果
作者在CIFAR-10、CIFAR-100、ImageNet三个数据集上分别进行了实验。
CIFAR-10 实验
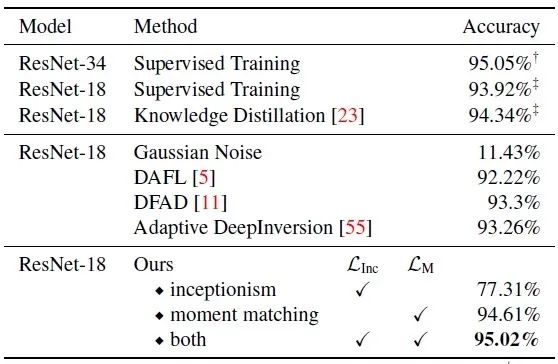
使用的教师和学生模型分别为 Resnet-34 和 Resnet-18,结果如下图12所示。
图12的前三行是在原始数据集的实验结果。我们以 CIFAR-10 数据集的结果为例。
使用原始数据集,教师网络可以达到 95.05% 的精度。 使用原始数据集,学生网络可以达到 93.92% 的精度。 使用原始数据集,学生网络+蒸馏方法可以达到 94.34% 的精度,轻微有损。 不使用任何数据集,只使用噪声图片+蒸馏方法只能达到 11.43% 的精度,相当于训练失败。 使用 DAFL 方法,学生网络+蒸馏方法可以达到 92.22% 的精度。 使用 DFAD 方法,学生网络+蒸馏方法可以达到 93.3% 的精度。 使用 Adaptive DeepInversion 方法,学生网络+蒸馏方法可以达到 93.26% 的精度。 使用本文的方法,学生网络+蒸馏方法最高可以达到 95.02% 的精度,去掉一些损失函数以后,精度会有略微的下降,证明本文所提出的损失函数的重要性。
下图13是不同方法生成的图片的可视化结果的对比。正如我们所看到的,尽管ADI可以产生比以往的方法高得多的图像质量,但它倾向于合成具有不同纹理但背景相似的图像 (如马类、船类和卡车类)。相比之下,本文的方法可以生成更真实的图像,与真实图片的分布更加相似。

CIFAR-100 实验
使用的教师和学生模型分别为 Resnet-34 和 Resnet-18,结果如下图14所示。
图14的前三行是在原始数据集的实验结果。我们以 CIFAR-10 数据集的结果为例。
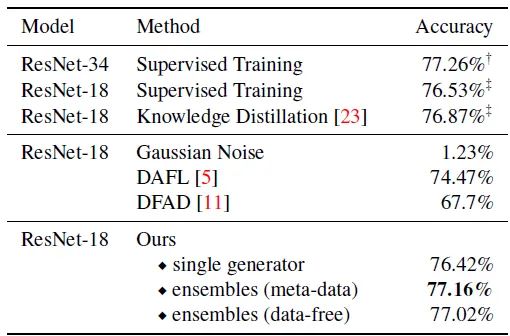
使用原始数据集,教师网络可以达到 77.26% 的精度。 使用原始数据集,学生网络可以达到 76.53% 的精度。 使用原始数据集,学生网络+蒸馏方法可以达到 76.87% 的精度,轻微有损。 不使用任何数据集,只使用噪声图片+蒸馏方法只能达到 1.23% 的精度,相当于训练失败。 使用 DAFL 方法,学生网络+蒸馏方法可以达到 74.47% 的精度。 使用 DFAD 方法,学生网络+蒸馏方法可以达到 67.7% 的精度。 使用 Adaptive DeepInversion 方法,学生网络+蒸馏方法可以达到 93.26% 的精度。 使用本文的方法,在单个 Generator 的情况下,学生网络+蒸馏方法最高可以达到 76.42% 的精度,去掉一些损失函数以后,精度会有略微的下降,证明本文所提出的损失函数的重要性。在需要少量的数据的情况下,成为meta-data的方法,可以达到77.16%的精度,使用多个 Generator 的情况下,不使用任何数据,可以达到77.02%的精度。
ImageNet 实验
使用的教师模型为 Resnet-34。
作者训练了1000个 Generator,每个 Generator的结构和之前的实验保持一致,额外添加了2个 upscale 层提升生成图片的维度。 由于内存限制,作者还将隐变量 的维度从 1024 减少到512。为了估计每个类的统计数据,我们对每个类采样100张图像。注意,这种抽样可以在教师网络训练期间进行。
结果如下图15所示,对比的几个模型是:
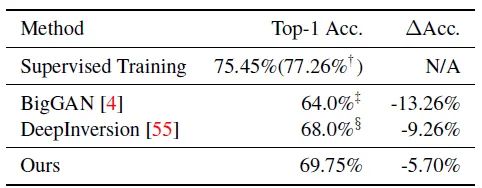
使用原始数据集,有监督地训练模型,在 Imagenet 上可以达到 75.45% 的精度。 数据集使用 BigGAN 来生成,学生网络+蒸馏方法可以达到 64.0% 的精度,有损。 数据集使用 DeepInversion 来生成,学生网络+蒸馏方法可以达到 68.0% 的精度,有损。DeepInversion 通过对 trainable images 的直接优化来合成图像。这种方法是非常耗时,但在理论上比使用生成模型有潜力产生更多样化的图像。 数据集使用本文方法来生成,学生网络+蒸馏方法可以达到 69.75% 的精度,有损。
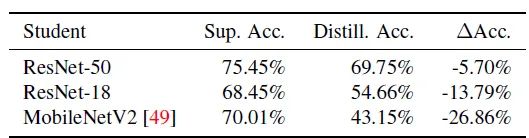
最后作者也比较了不同架构的学生网络的蒸馏结果,如下图16所示。使用的教师模型为 Resnet-34,其精度为75.45%。作者对所有的学生网络使用相同的生成器 。ResNet-50的性能最好,与有监督方式训练的模型相比,精度下降了5.70%。然而,ResNet-18 和MobileNetV2 上的性能结果要差得多,与有监督方式训练的模型有更大的差距。这表明,学生和教师结构之间可能存在一些纠缠,使得在 ResNet-50 上学习的生成器 MobileNetV2 和 ResNet-18 上的效率低于 ResNet-50 作为学生网络。如何提高其泛化能力仍是未来研究的课题。
小结
本质上和 DAFL 的两个阶段是一致的,都是先用生成器 输出的生成图片代替训练数据集进行训练,然后使用生成数据结合蒸馏算法得到压缩后的网络。本文方法通过 Inceptionism loss 和 Moment matching loss,以及训练多个生成器来解决 DAFL 无法在大数据集 ImageNet 上使用的问题。
总结
目前很少有工作关注在无数据情况下的网络压缩,然而,这些方法得到的压缩后的网络准确率下降很多,这是因为这些方法没有利用待压缩网络的信息。为了解决这一问题,本文介绍了2种无需训练数据的网络压缩方法,它们的损失函数配置如下:
| 损失函数 | 1 | 2 | 3 |
|---|---|---|---|
| DAFL | 伪标签交叉熵损失 | 特征激活损失函数 | 信息熵损失函数 |
| 本文 | 伪标签交叉熵损失 | 归一化损失 | Moment matching loss |
DAFL 比之前的最好算法在 MNIST 上提升了6个百分点,并且使用 resnet18 在 CIFAR-10 和 100 上分别达到了 92% 和 74% 的准确率 (无需训练数据)。第2篇谷歌的工作实现了进一步涨点,并且也适用于了 ImageNet 这一大数据集。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“79”获取CVPR 2021:TransT 直播链接~

# 极市原创作者激励计划 #
