
2021数据挖掘赛题方案来了!
赛题背景及任务
心电图是临床最基础的一个检查项目,因为安全、便捷成为心脏病诊断的利器。由于心电图数据与诊断的标准化程度较高,相对较易于运用人工智能技术进行智能诊断算法的开发。本实践针对心电图数据输出二元(正常 v.s 异常)分类标签。
比赛地址:http://ailab.aiwin.org.cn/competitions/64
赛题数据
数据将会分为可见标签的训练集,及不可见标签的测试集两大部分。其中训练数据提供 1600 条 MAT 格式心电数据及其对应诊断分类标签(“正常”或“异常”,csv 格式);测试数据提供 400 条 MAT格式心电数据。
数据目录
DATA |- trainreference.csv TRAIN目录下数据的LABEL
|- TRAIN 训练用的数据
|- VAL 测试数据
数据格式 12导联的数据,保存matlab格式文件中。数据格式是(12, 5000)。 采样500HZ,10S长度有效数据。具体读取方式参考下面代码。 0..12是I, II, III, aVR, aVL, aVF, V1, V2, V3, V4, V5和V6数据。单位是mV。
import scipy.io as sio
ecgdata = sio.loadmat("TEST0001.MAT")['ecgdata']
trainreference.csv格式:每行一个文件。格式:文件名,LABEL (0正常心电图,1异常心电图)
实践思路
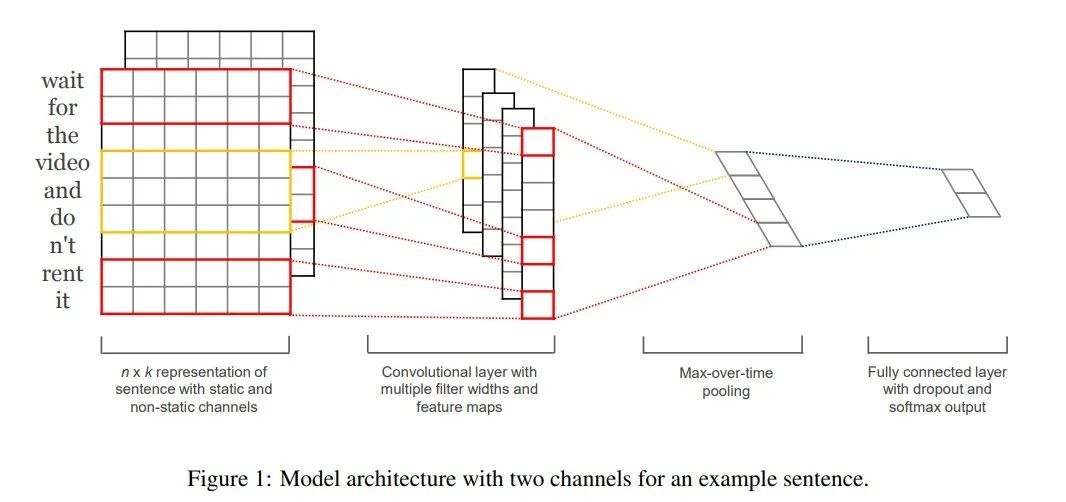
TextCNN 模型是由 Harvard NLP 组的 Yoon Kim 在2014年发表的 《Convolutional Neural Networks for Sentence Classification 》一文中提出的模型,由于 CNN 在计算机视觉中,常被用于提取图像的局部特征图,且起到了很好的效果,所以该作者将其引入到 NLP 中,应用于文本分类任务,试图使用 CNN 捕捉文本中单词之间的关系。
本实践使用TextCNN模型对心电数据进行分类。
改进思路
使用多折交叉验证,训练多个模型,对测试集预测多次。 在读取数据时,加入噪音,或者加入mixup数据扩增。 使用更加强大的模型,textcnn这里还是过于简单。
实践代码
数据读取
!\rm -rf val train trainreference.csv 数据说明.txt !
unzip 2021A_T2_Task1_数据集含训练集和测试集.zip > out.log
import codecs, glob, os
import numpy as np
import pandas as pd
import paddle
import paddle.nn as nn
from paddle.io import DataLoader, Dataset
import paddle.optimizer as optim
from paddlenlp.data import Pad
import scipy.io as sio
train_mat = glob.glob('./train/*.mat')
train_mat.sort()
train_mat = [sio.loadmat(x)['ecgdata'].reshape(1, 12, 5000) for x in train_mat]
test_mat = glob.glob('./val/*.mat')
test_mat.sort()
test_mat = [sio.loadmat(x)['ecgdata'].reshape(1, 12, 5000) for x in test_mat]
train_df = pd.read_csv('trainreference.csv')
train_df['tag'] = train_df['tag'].astype(np.float32)
class MyDataset(Dataset):
def __init__(self, mat, label, mat_dim=3000):
super(MyDataset, self).__init__()
self.mat = mat
self.label = label
self.mat_dim = mat_dim
def __len__(self):
return len(self.mat)
def __getitem__(self, index):
idx = np.random.randint(0, 5000-self.mat_dim)
return paddle.to_tensor(self.mat[index][:, :, idx:idx+self.mat_dim]), self.label[index]
模型构建
class TextCNN(paddle.nn.Layer):
def __init__(self, kernel_num=30, kernel_size=[3, 4, 5], dropout=0.5):
super(TextCNN, self).__init__()
self.kernel_num = kernel_num
self.kernel_size = kernel_size
self.dropout = dropout
self.convs = nn.LayerList([nn.Conv2D(1, self.kernel_num, (kernel_size_, 3000))
for kernel_size_ in self.kernel_size])
self.dropout = nn.Dropout(self.dropout)
self.linear = nn.Linear(3 * self.kernel_num, 1)
def forward(self, x):
convs = [nn.ReLU()(conv(x)).squeeze(3) for conv in self.convs]
pool_out = [nn.MaxPool1D(block.shape[2])(block).squeeze(2) for block in convs]
pool_out = paddle.concat(pool_out, 1)
logits = self.linear(pool_out)
return logits
model = TextCNN()
BATCH_SIZE = 30
EPOCHS = 200
LEARNING_RATE = 0.0005
device = paddle.device.get_device()
print(device)
gpu:0模型训练
Train_Loader = DataLoader(MyDataset(train_mat[:-100], paddle.to_tensor(train_df['tag'].values[:-100])), batch_size=BATCH_SIZE, shuffle=True)
Val_Loader = DataLoader(MyDataset(train_mat[-100:], paddle.to_tensor(train_df['tag'].values[-100:])), batch_size=BATCH_SIZE, shuffle=True)
model = TextCNN()
optimizer = optim.Adam(parameters=model.parameters(), learning_rate=LEARNING_RATE)
criterion = nn.BCEWithLogitsLoss()
Test_best_Acc = 0
for epoch in range(0, EPOCHS):
Train_Loss, Test_Loss = [], []
Train_Acc, Test_Acc = [], []
model.train()
for i, (x, y) in enumerate(Train_Loader):
if device == 'gpu':
x = x.cuda()
y = y.cuda()
pred = model(x)
loss = criterion(pred, y)
Train_Loss.append(loss.item())
pred = (paddle.nn.functional.sigmoid(pred)>0.5).astype(int)
Train_Acc.append((pred.numpy() == y.numpy()).mean())
loss.backward()
optimizer.step()
optimizer.clear_grad()
model.eval()
for i, (x, y) in enumerate(Val_Loader):
if device == 'gpu':
x = x.cuda()
y = y.cuda()
pred = model(x)
Test_Loss.append(criterion(pred, y).item())
pred = (paddle.nn.functional.sigmoid(pred)>0.5).astype(int)
Test_Acc.append((pred.numpy() == y.numpy()).mean())
print(
"Epoch: [{}/{}] TrainLoss/TestLoss: {:.4f}/{:.4f} TrainAcc/TestAcc: {:.4f}/{:.4f}".format( \
epoch + 1, EPOCHS, \
np.mean(Train_Loss), np.mean(Test_Loss), \
np.mean(Train_Acc), np.mean(Test_Acc) \
) \
)
if Test_best_Acc < np.mean(Test_Acc):
print(f'Acc imporve from {Test_best_Acc} to {np.mean(Test_Acc)} Save Model...')
paddle.save(model.state_dict(), "model.pdparams")
Test_best_Acc = np.mean(Test_Acc)
结果预测
Test_Loader = DataLoader(MyDataset(test_mat, paddle.to_tensor([0]*len(test_mat))),
batch_size=BATCH_SIZE, shuffle=False)
layer_state_dict = paddle.load("model.pdparams")
model.set_state_dict(layer_state_dict)
test_perd = np.zeros(len(test_mat))
for tta in range(10):
test_pred_list = []
for i, (x, y) in enumerate(Test_Loader):
if device == 'gpu':
x = x.cuda()
y = y.cuda()
pred = model(x)
test_pred_list.append(
paddle.nn.functional.sigmoid(pred).numpy()
)
test_perd += np.vstack(test_pred_list)[:, 0]
print(f'Test TTA {tta}')
test_perd /= 10
test_path = glob.glob('./val/*.mat')
test_path = [os.path.basename(x)[:-4] for x in test_path]
test_path.sort()
test_answer = pd.DataFrame({
'name': test_path,
'tag': (test_perd > 0.5).astype(int)
})评论