
【04期】分库分表之后,id 主键如何处理?

阅读本文大概需要 6 分钟。
来自:java面试题精选
面试官心理分析
面试题剖析
基于数据库的实现方案
数据库自增 id
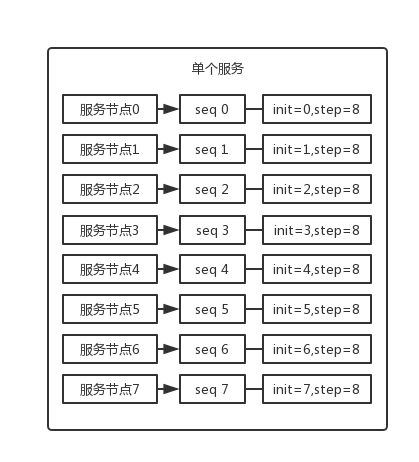
设置数据库 sequence 或者表自增字段步长
UUID
UUID.randomUUID().toString().replace(“-”, “”) -> sfsdf23423rr234sfdaf
获取系统当前时间
snowflake 算法
1 bit:不用,为啥呢?因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0。
41 bit:表示的是时间戳,单位是毫秒。41 bit 可以表示的数字多达
2^41 - 1,也就是可以标识2^41 - 1个毫秒值,换算成年就是表示69年的时间。10 bit:记录工作机器 id,代表的是这个服务最多可以部署在 2^10台机器上哪,也就是1024台机器。但是 10 bit 里 5 个 bit 代表机房 id,5 个 bit 代表机器 id。意思就是最多代表
2^5个机房(32个机房),每个机房里可以代表2^5个机器(32台机器)。12 bit:这个是用来记录同一个毫秒内产生的不同 id,12 bit 可以代表的最大正整数是
2^12 - 1 = 4096,也就是说可以用这个 12 bit 代表的数字来区分同一个毫秒内的 4096 个不同的 id。
0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 1 1001 | 0000 00000000
public class IdWorker {
private long workerId;
private long datacenterId;
private long sequence;
public IdWorker(long workerId, long datacenterId, long sequence) {
// sanity check for workerId
// 这儿不就检查了一下,要求就是你传递进来的机房id和机器id不能超过32,不能小于0
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(
String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(
String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
System.out.printf(
"worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",
timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = sequence;
}
private long twepoch = 1288834974657L;
private long workerIdBits = 5L;
private long datacenterIdBits = 5L;
// 这个是二进制运算,就是 5 bit最多只能有31个数字,也就是说机器id最多只能是32以内
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 这个是一个意思,就是 5 bit最多只能有31个数字,机房id最多只能是32以内
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
private long sequenceBits = 12L;
private long workerIdShift = sequenceBits;
private long datacenterIdShift = sequenceBits + workerIdBits;
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private long sequenceMask = -1L ^ (-1L << sequenceBits);
private long lastTimestamp = -1L;
public long getWorkerId() {
return workerId;
}
public long getDatacenterId() {
return datacenterId;
}
public long getTimestamp() {
return System.currentTimeMillis();
}
public synchronized long nextId() {
// 这儿就是获取当前时间戳,单位是毫秒
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);
throw new RuntimeException(String.format(
"Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
// 这个意思是说一个毫秒内最多只能有4096个数字
// 无论你传递多少进来,这个位运算保证始终就是在4096这个范围内,避免你自己传递个sequence超过了4096这个范围
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
// 这儿记录一下最近一次生成id的时间戳,单位是毫秒
lastTimestamp = timestamp;
// 这儿就是将时间戳左移,放到 41 bit那儿;
// 将机房 id左移放到 5 bit那儿;
// 将机器id左移放到5 bit那儿;将序号放最后12 bit;
// 最后拼接起来成一个 64 bit的二进制数字,转换成 10 进制就是个 long 型
return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift)
| (workerId << workerIdShift) | sequence;
}
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
// ---------------测试---------------
public static void main(String[] args) {
IdWorker worker = new IdWorker(1, 1, 1);
for (int i = 0; i < 30; i++) {
System.out.println(worker.nextId());
}
}
}
推荐阅读:
【01期】Spring,SpringMVC,SpringBoot,SpringCloud有什么区别和联系?
【03期】如何决定使用 HashMap 还是 TreeMap?
微信扫描二维码,关注我的公众号
朕已阅 
评论