
独家 | 每个数据科学家都应该熟悉的 5 个统计学悖论

翻译:潘玏妤
校对:赵茹萱
本文约3200字,建议阅读5分钟 本文 我们将探讨每个数据科学工作者都应该熟悉的5个统计学悖论。
目录
1.Accuracy Paradox 准确度悖论 2.False Positive Paradox 假阳性悖论 3.Gambler’s Fallacy 赌徒谬误 4.Simpson’s Paradox 辛普森悖论 5.Berkson’s Paradox 伯克森悖论 6.Conclusion 总结
接下来我们通过一个Python实例来解释上述内容:

在医学测试中可以找到一些准确度悖论的真实案例。假设有一种患病概率为十万分之一的罕见病。如果创建了一个在检测疾病方面有99.9%准确度的测试,并将其提供给只有0.1%的患病人群,则该测试将具有99.9%的高准确率。然而,它将导致大量的假阳性(False Positive),也就是说,许多健康人将被错误地诊断为患有该疾病。
精确度和召回率在评估分类任务的表现上比准确度更好。而这两个指标(精确度和召回率)与我们下一节讨论的假阳性悖论有关。
2.False Positive Paradox 假阳性悖论
Python解释假阳性悖论的简单示例:

例如,想象一个病患占总人口1%的疾病的医学测试。如果该测试有99%的准确率,则它有99%的概率正确识别疾病的存在或不存在。但倘若对1000人进行检测,那么将会有10人被测出阳性,尽管事实上只有1人患病。这意味着阳性测试结果更可能是假阳性而不是真阳性。
下面是另一个针对假阳性悖论的Python代码示例:

3.Gambler’s Fallacy 赌徒谬误
我们可以借助Python中的numpy模拟投掷一枚公平的硬币来说明这一点:

赌徒谬误会在股票市场等生活场景中出现。一些投资者可能认为,如果一只股票的价值连续几天持续上涨,之后它就更有可能下跌,尽管市场运动其实仍然是内在不可预测的,并受一系列因素的影响。
4.Simpson’s Paradox 辛普森悖论
辛普森悖论是指在一个具有某种趋势的数据集中,倘若我们把这个数据集分成许多子数据集,那么原趋势会消失或子数据集呈现的趋势与原趋势相反。如果数据被错误处理与分析,这可能会导致错误的结论。
我们通过一个例子来更好地理解这一现象。假设我们想比较一所大学男女申请者的录取率。已知我们有两个院系的数据:院系A和院系B。
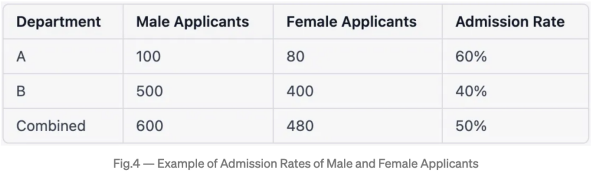
出现这种悖论是因为每个院系的申请人数和录取率都不一样。院系A整体录取率较高,但女性申请者比例较低。院系B整体录取率较低,但女性申请者比例较高。
在Python中,我们可以使用以下代码演示这个示例:

在代码中,我们用上表中的数据创建了一个dataframe,计算录取率并显示数据图表。然后计算整体录取率,得出为19.44%。最后,我们将数据按院系和性别分组,并计算每个分组的录取率。我们看到两个院系的女性录取率都较高,尽管男性的整体录取率较高。这是辛普森悖论的一个例子。
5.Berkson’s Paradox 伯克森悖论
我们将萼片长度和宽度作为两个感兴趣的变量,使用鸢尾花数据集来解释这个悖论。 首先,可以在pandas中使用corr()方法计算这两个变量之间的相关系数:

然而,如果我们按品种分割数据集并分别计算每个品种的相关系数,我们可能会得到不同的结果。比如,如果我们只考虑setosa,我们会得到一个正相关:

这种矛盾的出现是因为setosa的萼片长度和宽度的数值范围比其他品种小。因此,当我们只考虑setosa时,整个数据集内的负相关性被setosa内的正相关性所掩盖。
6.Conclusion 结论
1. 准确度悖论告诉我们,仅仅依靠准确度不足以评估分类任务,精确度和召回率能提供更多有价值的信息; 2.假阳性悖论强调了理解假阳性相对于假阴性的重要性; 3.赌徒谬误提醒我们,每个事件都是独立的,过去的结果不会影响未来; 4.辛普森悖论表明:整体数据有可能掩盖细节变量之间的关系,从而导致错误的结论; 5.最后,伯克森悖论显示了从总体中选取非随机样本时,抽样偏差是如何发生的。
编辑:王菁
译者简介
潘玏妤,流连于剧院和美术馆的CS本科生,沉迷于AI与数据科学相关学术前沿信息的古典音乐爱好者。
翻译组招募信息
工作内容: 需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到: 定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利: 来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“ 阅读原文 ”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
点击 “阅读原文” 拥抱组织
评论