
秀操作!值得收藏的训练trick。
大家好,我是 Jack。
Deep learning 在训练的时候往往有很多 trick ,不可否认这些 trick 也是 DL 成功的关键因素之一,所谓 “the devil is in the details” 。
除了 batch 大小的改变以及初始化等 trick ,还有哪些提升 performance 的利器?
我整理了一些知乎上看到的高赞回答和文章,希望对你有所帮助。
回答一
作者:DOTA
https://zhuanlan.zhihu.com/p/352971645
Focal Loss
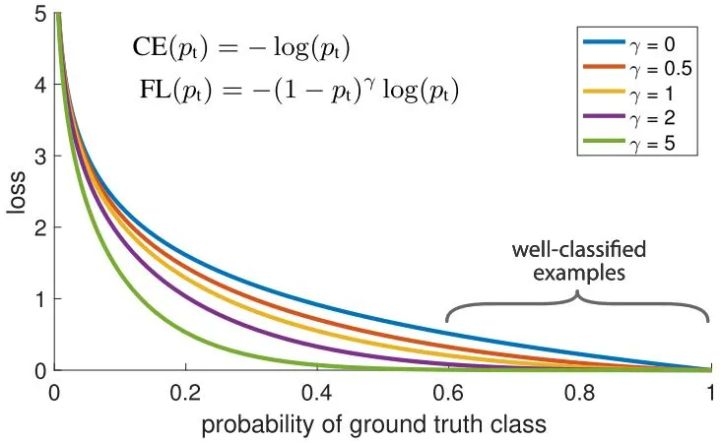
针对类别不平衡问题,用预测概率对不同类别的loss进行加权。Focal loss对CE loss增加了一个调制系数来降低容易样本的权重值,使得训练过程更加关注困难样本。
loss = -np.log(p)
loss = (1-p)^G * loss
Dropout
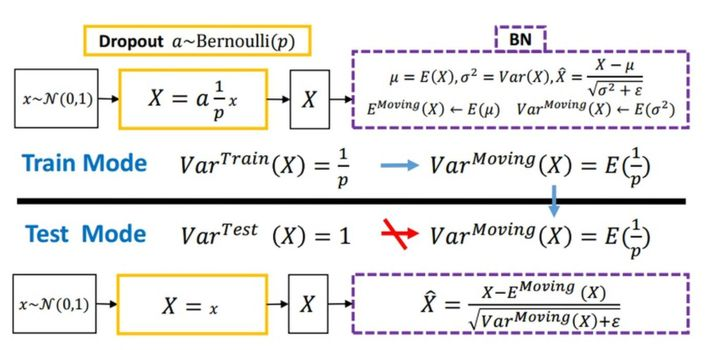
随机丢弃,抑制过拟合,提高模型鲁棒性。
Normalization
Batch Normalization 于2015年由 Google 提出,开 Normalization 之先河。其规范化针对单个神经元进行,利用网络训练时一个 mini-batch 的数据来计算该神经元的均值和方差,因而称为 Batch Normalization。
x = (x - x.mean()) / x.std()
relu
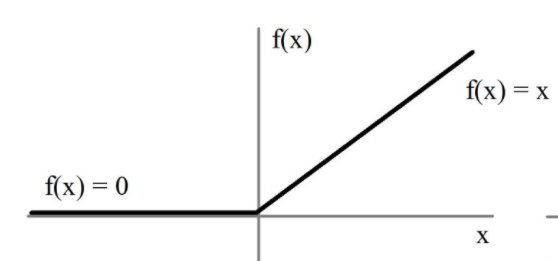
用极简的方式实现非线性激活,缓解梯度消失。
x = max(x, 0)
Cyclic LR
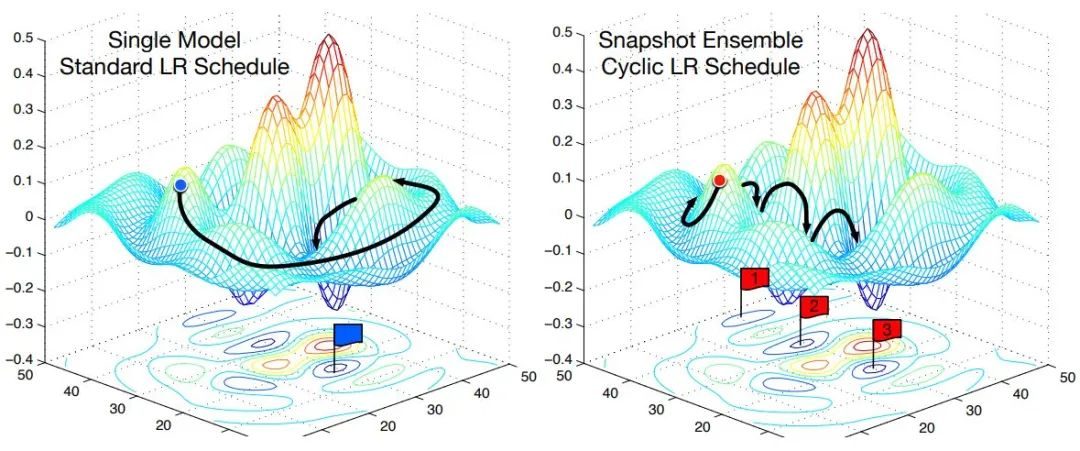
每隔一段时间重启学习率,这样在单位时间内能收敛到多个局部最小值,可以得到很多个模型做集成。
scheduler = lambda x: ((LR_INIT-LR_MIN)/2)*(np.cos(PI*(np.mod(x-1,CYCLE)/(CYCLE)))+1)+LR_MIN
With Flooding
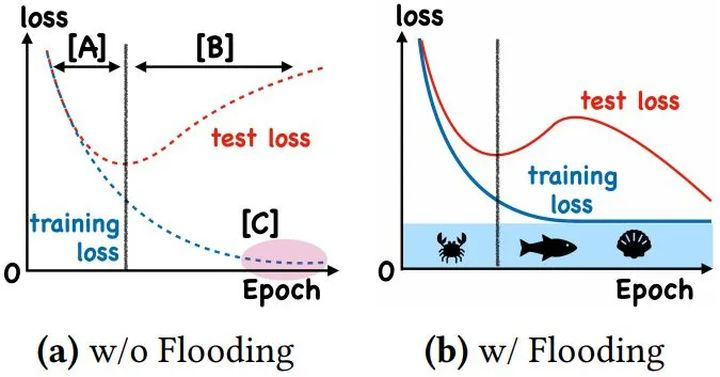
当training loss大于一个阈值时,进行正常的梯度下降;当training loss低于阈值时,会反过来进行梯度上升,让training loss保持在一个阈值附近,让模型持续进行"random walk",并期望模型能被优化到一个平坦的损失区域,这样发现test loss进行了double decent。
flood = (loss - b).abs() + b
Group Normalization
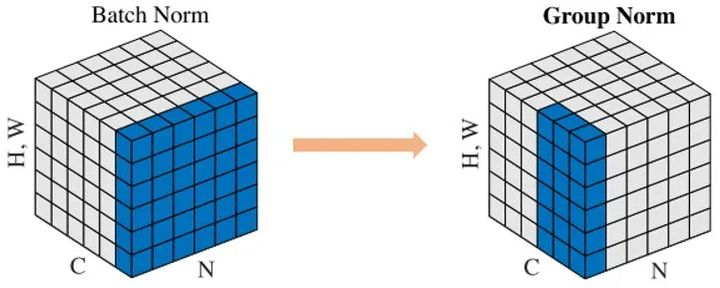
Face book AI research(FAIR)吴育昕-恺明联合推出重磅新作Group Normalization(GN),提出使用Group Normalization 替代深度学习里程碑式的工作Batch normalization。一句话概括,Group Normbalization(GN)是一种新的深度学习归一化方式,可以替代BN。
def GroupNorm(x, gamma, beta, G, eps=1e-5):
# x: input features with shape [N,C,H,W]
# gamma, beta: scale and offset, with shape [1,C,1,1]
# G: number of groups for GN
N, C, H, W = x.shape
x = tf.reshape(x, [N, G, C // G, H, W])
mean, var = tf.nn.moments(x, [2, 3, 4], keep dims=True)
x = (x - mean) / tf.sqrt(var + eps)
x = tf.reshape(x, [N, C, H, W])
return x * gamma + beta
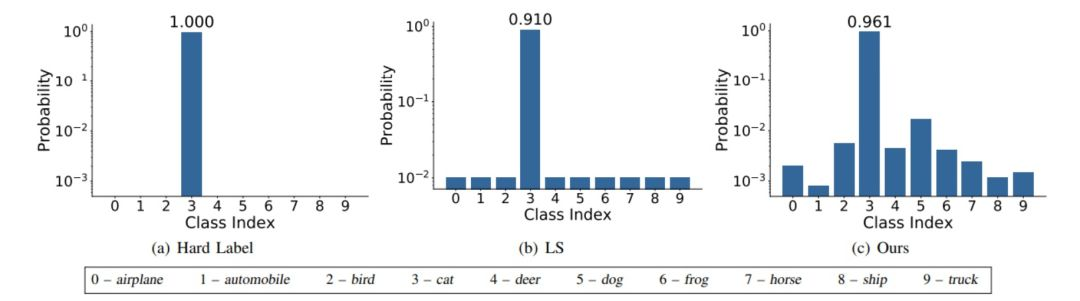
Label Smoothing
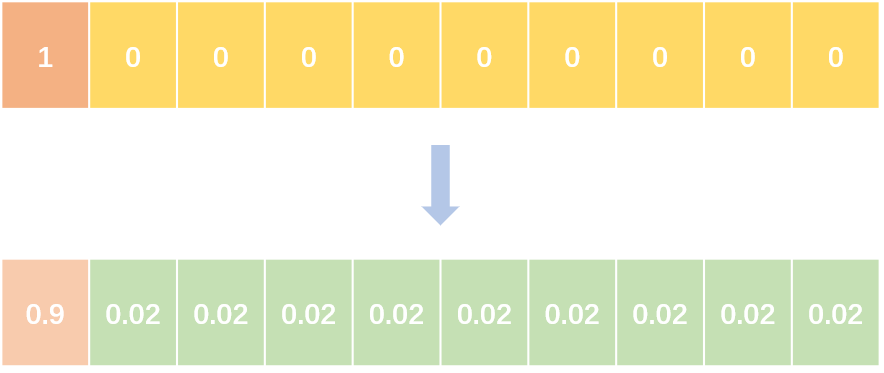
Label smoothing将 hard label 转变成 soft label ,使网络优化更加平滑。标签平滑是用于深度神经网络(DNN)的有效正则化工具,该工具通过在均匀分布和hard标签之间应用加权平均值来生成soft标签。它通常用于减少训练DNN的过拟合问题并进一步提高分类性能。
targets = (1 - label_smooth) * targets + label_smooth / num_classes
Wasserstein GAN
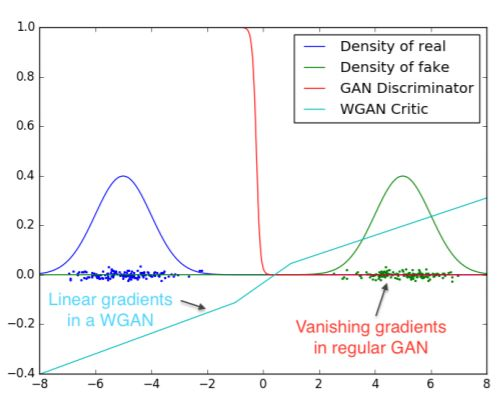
彻底解决GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度 基本解决了Collapse mode的问题,确保了生成样本的多样性训练过程中终于有一个像交叉熵、准确率这样的数值来指示 训练的进程,数值越小代表GAN训练得越好,代表生成器产生的图像质量越高 不需要精心设计的网络架构,最简单的多层全连接网络就可以做到以上3点。
Skip Connection
一种网络结构,提供恒等映射的能力,保证模型不会因网络变深而退化。
F(x) = F(x) + x
回答二
作者:永无止境 https://www.zhihu.com/question/30712664/answer/1341368789
在噪声较强的时候,可以考虑采用软阈值化作为激活函数:
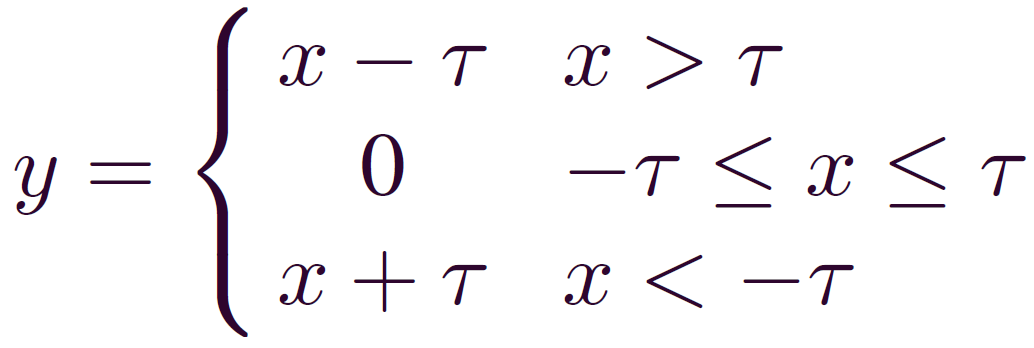
软阈值化几乎是降噪的必备步骤,但是阈值τ该怎么设置呢?
阈值τ不能太大,否则所有的输出都是零,就没有意义了。而且,阈值不能为负。
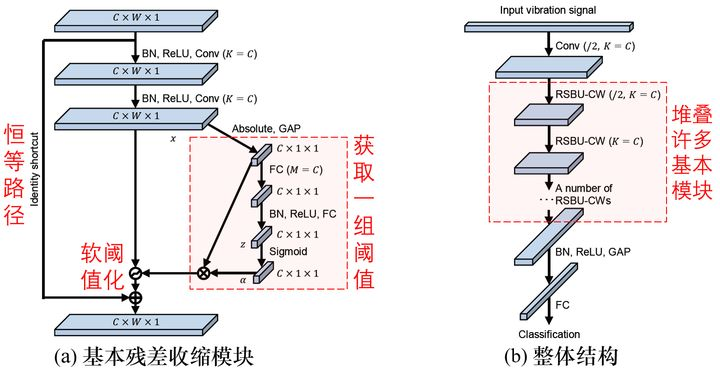
针对这个问题,深度残差收缩网络提供了一个思路,设计了一个特殊的子网络来自动设置:
文章一
作者:DLing
https://zhuanlan.zhihu.com/p/359960152
作为一个CV算法工程师,当一只脚踏入这一行大门的时候,你的领路人就会像神父一样,非常庄重的跟你说:“X先生,从今天开始,你就要和这一堆堆数据‘结婚’了,以后无论对方是否漂亮,干净,整洁,你都会不离不弃,永远爱她,维护着她,对她负责吗?”我相信,一个个激情满满的萌新算法工程师们想都不会想,一口一个“我会的,我对她们至死不渝。”每每想到这,我的心情就会像那个神父一样,嘴上祝福,心里想:我看你能坚持到什么时候?
算法工程师和数据之间的相爱相杀,一直是行业的共识,“成也数据,败也数据”其实是件很难受的事情,让算法工程师们饱受折磨和挫败感。虽然说现在搞深度学习的烂大街,但是其实门槛还是挺高的,一般公司,做这一块的基本是硕士起步,好一点的公司,可能还得名校硕士起步。但是处理数据,却是行业需要面临的通用问题,一个个憧憬进入各自行业大展拳脚,用“毕生所学”为社会发光发热的天之骄子们,最后发现工作中30%以上的时间是在看数据,筛数据,时间一久,肯定心性就被磨没了。
我自己也是个算法工程师,深知这里面有多少辛酸,所以,工作之余,我就在想,难道这东西就没有解决办法吗?拿这么长的时间去研究新技术,提升工程性能不香吗?天天看数据,看着看着就睡着了,还要被领导怼。终于,有一天灵光一闪,打比赛的时候,经常有人累死累活调一个模型,但是提交结果的时候,准确率不理想,而有些人使用模型融合,随便训几个模型,轻轻松松指标就很高,最后拿奖,导致很多比赛都禁止使用多模型融合的方法了。既然模型融合那么有效,我是不是可以把他用在数据挑选与清洗中?最后在工程实践中,发现确实是行之有效的。
正常的模型优化中,有以下两个方向是经常会碰到的:模型加数据迭代优化以及模型数据清洗。今天就以这两个方向为例,细致的讲一下,如何使用模型融合的方式去自动做,并达到不错的效果,节约算法工程师宝贵的时间。
模型加数据迭代优化
一般一个项目为了快速上线,初始模型效果不会特别好,基本功能能用就上,美其名曰“勤发版,勤迭代,小步快跑”,所以后续的持续优化必不可少。项目上线后,可以拿到的数据源源不断,但是怎么高效的从海量数据中找到自己想要的去优化模型却是件很值得思考的事。一般情况下,算法工程师往训练集里加数据优化模型会有两个套路,一个是无差别添数据,来多少加多少,不是说模型效果不好么?来来来,给你加十万,看你好不好;还有一个是只添外部反馈错误数据,项目上或者测试反馈了有一批错误数据,你看看要不要优化一下?但是这两种方式都各有弊端:
1) 无差别添数据;这种方式最大的弊端就是成本太高,不管是给数据标注的经济成本,还是等待数据标注的时间成本都很高,而且这种方式会给数据集带来很多的无用数据(就是目前模型效果已经很好的数据),让数据集变的臃肿,后期维护和训练起来,都更麻烦。
2) 只添外部反馈错误数据;这种方式也有弊端,就是模型迭代的很慢,而且也很被动,会永远被项目牵着走,没有主动性。
而这部分要讲的方法,就可以同时解决以上两种问题,可以将提前发现问题,并且提升算法工程师的工程效率,节约项目成本。下文以分类模型做示例:
前期需要准备两种模型,第一种是工程中在使用的模型,这个比较简单,工程中拿来用就行。重要的是第二种,用于进行模型融合的模型,这个模型的数量任意,理论上越多越好(本文示例用俩),建议模型结构之间拥有一定的差异,然后就是用选好的模型在原有模型数据集上进行训练,得到新的用于模型融合的模型,然后结合海量用于优化的数据,就可以开启高效的模型迭代优化了,具体方法如下:
根据数据集特性,对原始训练数据集进行一定的扩增,一般的crop,旋转,颜色抖动等就可以,主要还是看数据集是否合适这样的扩增;
使用选择好的模型,在上步中的数据集上进行训练,并得到相应的模型;
准备好用于优化模型的候选数据,然后一条条处理,按照上面训练模型时候的数据扩增方式,将img扩展成img1,...,imgn,然后分别用步骤2得到的模型进行推理,得到特征feature11,...,feature1n,feature21,...,feature2n; 当然,这个特征是指模型最后输出的特征,是使用softmax之前的特征还是softmax之后的概率随意,我个人喜欢用之前的特征;
将上一步获取到的特征进行融合(加权平均融合,不同模型不同权重都随意,我是喜欢简单点,加权平均),得到新的特征, 然后对新得到的特征进行softmax计算,得到最后的融合概率(上步直接取softmax后的概率的话,就不用求融合概率了);
后面就是依据上一步得到的每一类的概率以及工程模型推理的结果,如果工程模型得到的结果和融合模型一致,且得分很高,则认为工程中的模型对这条数据已经预测的很好了,不加进训练集训练也没啥问题;其余的则需要单独拎出来,并使用融合模型的结果给其打上标签,到时候人工复核下标签后,加入模型训练;
以上的步骤,在初始模型得到后,运行个几次,基本就能得到一个泛化能力还不错,准确率也还不错的模型,后面再定期迭代,基本可以保证这个模型长期的效果。
模型数据集清洗
除了模型的正常迭代,在模型优化过程中,还有一个特别重要的任务,这就是模型数据集的清洗。限于不同人对任务的理解,数据标注人员的标注质量,模型各届负责人的做事方法与责任心等等原因,算法工程师接到一个模型优化任务后,经常发现模型指标一直上不去,最后找来找去才发现是数据集问题,里面一堆的问题数据,但是一看数据集,动则几十万的数据集后,即使想清理,也是有心无力。这个时候,融合模型就又可以派上大用处了,具体方法如下:
和上文一样,准备N个模型,正常两个即可;然后将模型的原始数据集分成K(K>1)份,用于后续的模型训练和数据清洗;
每次使用K份中的一份作为训练集,其余作为测试集,训练集按照上文的方法进行数据扩增和模型训练,即最后可以获取到K组模型,每份模型中都有N组子模型;
依据上步得到的模型组合,对数据集进行K轮清洗,每一轮清洗的数据为当前子模型对应的测试集。当当前测试数据通过该组子模型融合后的结果与其标签一致(具体融合方法见上文),且得分超过设定阈值,则认为此数据标签正确,否则,需要把这个数据单独拎出;
经过K轮测试后,相当于原始数据中每一条数据都被各自的融合模型测试了K-1次,此时设置一个阈值,在整个测试过程中,该条数据被拎出的次数小于阈值,则认为该数据标签确认正确,否则由人工确认。
各种 trick,都是靠着经验积累,总结得来的,多学多练。
我是 Jack,我们下期见~

推荐阅读
• 好家伙,又火一个。。• 日入上万,Jack 年入百万?• 我有一个很大胆的想法!