
广告场景中的文本分类项目实战总结
共 7252字,需浏览 15分钟
·
2021-08-17 21:08
导读:本文是“数据拾光者”专栏的第三十七篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇主要分享了我在绿厂广告场景中历时两年的文本分类项目模型优化实践集合,是我完成度最高的项目之一,从0到1将NLP前沿模型应用到业务实践产生广告消耗,本身收获很大。欢迎感兴趣的小伙伴一起沟通交流,后面会继续分享从样本层面优化文本分类任务实践。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者
摘要:本篇主要分享了我在绿厂广告场景中历时两年的文本分类项目模型优化实践。第一部分内容是背景介绍,包括业务介绍、项目背景及目标、技术选型、分类器组织方案以及技术选型,了解了项目背景的来龙去脉才能更好的完成项目;第二部分内容是文本分类项目模型优化实践,主要包括基于BERT文本分类模型架构、Encoder优化、句向量表示优化、分类层优化、损失函数优化以及文本分类任务转化成句子对关系任务等。通过上述优化实践,可以让我们对文本分类任务有更加深入的了解。文本分类项目应该是我完成度最高的项目之一,从0到1将NLP前沿模型应用到业务实践产生广告消耗,本身收获很大。欢迎感兴趣的小伙伴一起沟通交流,后面会继续分享从样本层面优化文本分类任务实践。
下面主要按照如下思维导图进行学习分享:
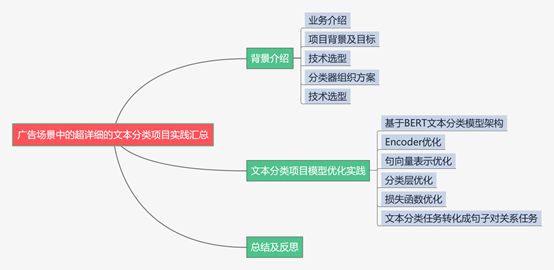
01
背景介绍
1.1 业务介绍
之前也介绍过,我们组的一个核心业务是为用户打上兴趣标签,从而为广告主圈选人群。下面是一个比较形象的介绍图:
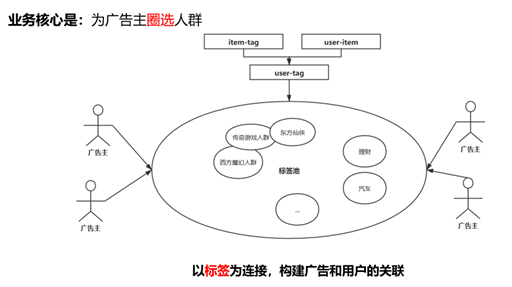
从上图可以看出,我们业务的核心是为广告主圈选人群。举例说明,比如现在有个传奇游戏的广告主,他想为自己的传奇游戏打广告,那么在曝光资源有限的前提下,想获得最好的广告转化效果,那么广告主希望将广告尽量曝光给那些对传奇游戏可能感兴趣的人群。如何找到那些对传奇游戏感兴趣的人群就是我们团队主要做的事情了。做这件事的本质是给用户打上兴趣标签。具体如何给用户打上兴趣标签是比较复杂的事情了。我们可以通过埋点来获取用户操作数据源的数据也就是user-item关联,通过人工打标或者机器学习打标的方法对不同的数据源进行打标得到item-tag关联,最后经过关联操作就可以得到user-tag的关系。通过这种方式我们就可以给用户打上兴趣标签了,具体通过统计建模的方式给用户打上兴趣标签的方法之前也分享过一篇文章,感兴趣的小伙伴可以看看:《广告中那些趣事系列1:广告统一兴趣建模流程》
1.2 项目背景及目标
上面介绍了我们的一个核心业务是给用户打上兴趣标签,这里先看下我们的标签挖掘系统框架图以及文本分类项目在框架中的位置关系图:

我们标签挖掘体系从下到上分成四层结构,最底下的一层是数据接入层,主要作用是接入各种数据,主要分成三部分。第一部分是用户操作数据源的user-item,这部分数据比较容易获得,通过埋点可以拿到用户操作终端里各个数据源的数据,比如我们经常登录王者荣耀app,那么相当于就可以拿到user-app的关联,其他数据源是类似的;第二部分是item-text,其实就是获取各个数据源的文本数据,比如app数据源中有app名称、描述等,这些数据是进行打标的依据;第三部分数据是一些非兴趣的用户定向数据,比如性别、年龄等。
接下来是文本理解层,主要是给数据源打标。这里会先根据广告主的需求构建类目体系,然后基于这个类目体系来给数据源打标也就是构建item-tag的关联,这里会通过文本分类和关键词抽取的方法给数据源打上标签。这里给数据源打标就是我们文本分类项目需要完成的任务。
然后是行为建模层,就是根据用户的行为来构建用户和标签的关联、用户之间的关联以及广告和标签的关联。用户和标签的关联主要包括自然兴趣和商业兴趣,用户之间的关联主要是指人群扩量,广告和标签的关联主要是对投放广告的投前分析和投中优化。
最后是上游的业务应用,主要是给用户投放对应的广告也就是user-ad关联。这里我们可以将构建的用户和标签的关联用于广告定向,还可以用于作为上游的排序特征等等。
从标签挖掘系统框架中可以看出我们的文本分类项目主要是深入理解数据源从而给数据源打标,而数据源打标质量的好坏会直接影响广告投放的效果。在实际项目中给数据源打标主要分成人工打标和机器学习打标两大类。项目前期对于像app这种量级不大(量级在十万左右),同时准确度要求很高的数据源来说主要通过人工打标,而对于用户搜索query这种量级非常的大(日度量级在千万级别)的数据源通过人工打标则非常不现实,更靠谱的办法是通过机器学习的方法进行,所以我们的文本分类项目目标就是使用NLP文本分类算法对数量庞大的query、url等数据源进行打标。
1.3 技术选型
介绍完项目背景之后就是技术选型了。之前刚好参加公司的比赛做了一个低俗文本分类器,调研了传统的文本分类算法和当前非常火的BERT预训练模型,下面是模型效果对比图:
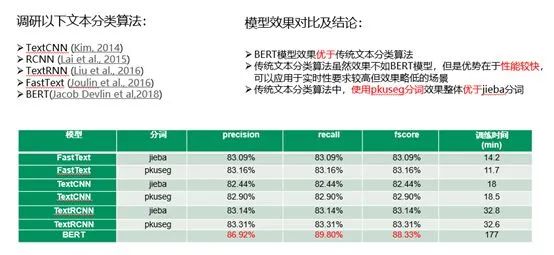
上图中主要调研了传统的文本分类算法比如TextCNN、FastText等以及当前很火的BERT预训练模型,发现整体来看BERT的模型效果要优于传统文本分类算法,主要原因是预训练模型学习到海量的语言学知识,然后通过迁移学习将语言学知识用于下游任务。虽然传统的文本分类算法效果不如BERT,但是模型预测速度较快,可以应用到一些实时性要求较高但是效果略微降低的场景中。因为传统的文本分类算法需要对中文语句进行分词,所以实验还对比了当前两种不同的分词算法jieba和北大pkuseg对文本分类的效果影响,最后发现北大的pkuseg分词的文本分类效果更优一些。通过算法调研,我们最终决定了文本分类项目使用BERT来进行文本分类。关于BERT模型详解之前也写过一篇文章,感兴趣的小伙伴可以去看看:《广告行业中那些趣事系列3:NLP中的巨星BERT》
1.4 分类器组织方案
经过技术选型我们确定了使用BERT来构建文本分类器,接下来是如何构建分类器组织方案。因为我们的标签体系是四级标签结构可能包含数百个标签,那么是构建多分类器还是N个二分类任务呢?最终我们确定了构建N个二分类任务的方式,下面是主要原因分析图:
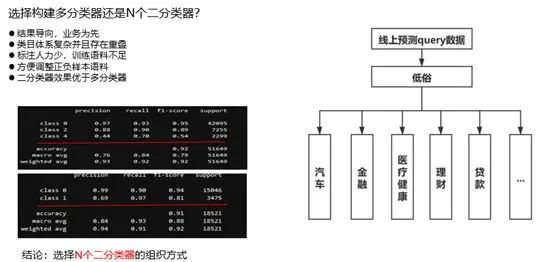
最终我们线上使用的是N个二分类器的组织方案,主要原因有以下几个:首先是基于当前的业务模式。因为我们在开发标签分类器的时候主要是根据广告主的需求分批开发,在这样的情况下N个二分类器的组织方案会更加贴近业务一些;然后因为我们的标签类目体系非常复杂,可能存在交叉重叠的情况,这种情况下开发多分类器的效果会有一定下降。我们通过实验的方式论证了N个二分类器的效果是要优于多分类器的;其次开发分类器是需要一定的标注语料的,而我们的标注人力非常紧张,在这种情况下会根据业务的优先级重点标注某部分语料,这也使得N个二分类器的方式会更加高效一些;其次N个二分类器的组织方案方便调整语料,对于每个分类器其实都是独立的,所以可以很方便的根据模型效果来调整样本,而多分类器是一个统一的整体,很容易出现A类别提升但是B类别下降的情况。基于以上业务实践和实验效果论证我们使用了N个二分类器的组织方式。当然这种方式也存在一些小问题,当开发的标签数量非常大时会存在维护困难的情况,这时候就需要通过自动化脚本来提升维护效率。
02
文本分类项目模型优化实践
2.1 基于BERT文本分类模型架构
上一章我们确定了主要通过BERT来构建文本分类器,分类器组织方案使用N个二分类器。下面是使用BERT构建分类器结构图:
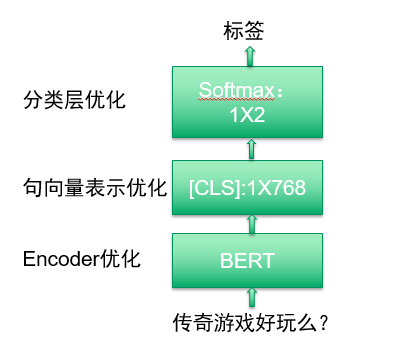
从上图中可以看出基于BERT构建分类器结构图主要包括三个流程,第一个流程是使用BERT作为编码器获得文本的向量表示。通过BERT可以获取两种维度的向量,一种是字粒度的向量,一种是语句维度的向量。假如输入的文本是“传奇游戏好玩么?”七个字,BERT会在句首和句尾分别添加开始标志CLS和结束标志SEP,这样经过BERT之后就会得到9X768维度的字向量,这里9的原因是7个字+2个特殊标志位;第二个流程是获取语句表示向量,BERT论文中建议使用CLS作为文本的语句向量;第三个流程是构建分类层,这里最简单的是使用一层全连接层softmax作为分类层。实际工作中我们文本分类项目模型层面的优化也主要是基于这三个流程进行优化。
2.2 Encoder优化
Encoder优化主要是为了获取文本更好的向量表示,所以这里主要是对BERT这一类预训练模型进行优化。我们预训练模型的优化流程大约是下面的线路:
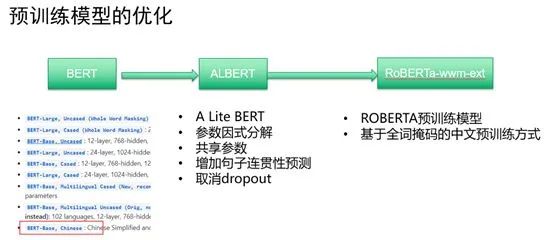
项目初期我们调研了BERT开源的预训练权重,因为我们主要是在中文搜索场景,所以选择了BERT-Base-Chinese版本,这个版本主要是google使用中文语料训练得到的预训练权重。
然后我们尝试使用了当时BERT最好的衍生品ALBERT预训练模型。ALBERT简称为A lite BERT,简单的理解是一种轻量级的BERT。ALBERT出现的背景是原生BERT虽然效果好应用范围广,但是本身非常笨重。这里以google基础版本BERT-base为例,模型参数量级达到亿级别。在这样的情况下,模型训练和预测速度会变慢。为了获得一种能和原生BERT效果媲美同时模型训练和预测速度大幅提升的模型,ALBERT应运而生。想提升BERT模型的速度,就得想办法减少参数,那就需要知道BERT的参数量在哪里。下面是BERT的参数量来源图:
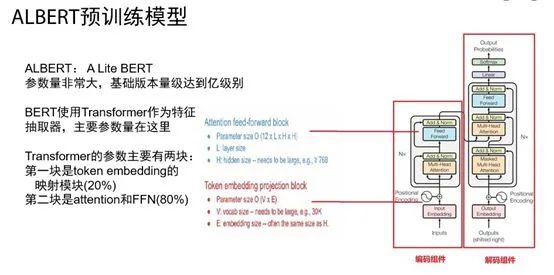
从上图中可以看出,因为BERT使用Transformer作为特征抽取器,所以BERT的主要参数量就来自于Transformer。Transformer中的参数主要包括两部分,第一部分是Token embedding映射模块,参数量占比为20%;第二块是Attention层和前向反馈层FFN,参数量占比为80%。要想减少BERT模型参数量,那么就得从上面两块来优化。
为了提升模型的速度,ALBERT主要使用了如下几种优化策略:
策略1:对embedding参数因式分解(Factorized embedding parameterization)
策略2:共享层与层之间的参数(Cross-layer parameter sharing)
策略3:构建自学习任务-句子连贯性预测
策略4:去掉dropout
总体来看,ALBERT的实质是使用参数减少技术来降低内存消耗从而最终达到提高BERT的训练速度,主要优化了以下几个方面:
通过因式分解和共享层与层之间的参数减少了模型参数量,提升了参数效率;
通过SOP替代NSP,增强了网络学习句子连续性的能力,提升了自监督学习任务的能力;
通过去掉dropout可以节省很多临时变量,有效提升模型训练过程中内存的利用率,提升了模型的效率,减少了训练数据的规模。
关于ALBERT的详细介绍,小伙伴可以查看下我之前写过的一篇文章《广告行业中那些趣事系列6:BERT线上化ALBERT优化原理及项目实践(附github)》。
将ALBERT应用到我们实际项目中,发现模型的效果有略微降低,但是模型的训练速度和预测速度大幅提升。
最后我们尝试了RoBERTa-wwm-ext预训练模型,这也是我们目前线上正在使用的预训练模型。RoBERTa-wwm-ext模型对比与原生BERT模型来说主要有两大块的优化,第一块是RoBERTa模型,第二块是基于全词掩码Whole Word Mask(WWM)。关于RoBERTa-wwm-ext预训练模型优化主要如下图所示:

如上图所示,RoBERTa-wwm-ext相比于原生BERT主要有两大块优化,第一块是RoBERTa模型。RoBERTa是由FacebookAI和华盛顿大学的研究团队共同完成,英文全称是“Robustly optimized BERT approach”,中文翻译过来就是强力优化的BERT方法,通俗易懂。因为RoBERTa的作者认为原生BERT训练不足,所以进行了一项复杂研究,包括仔细评估了超参数和训练集大小等等对BERT预训练模型的影响。对应到RoBERTa模型具体的优化项主要有以下几部分:
动态Mask操作
取消NSP任务
设置更大的batch size训练
使用更多的数据集同时训练的更久
调整优化器Adam参数
使用Byte level构建词表
通过上面六个优化项,使得RoBERTa在文本分类任务中效果有很大的提升。
RoBERTa-wwm-ext相比于原生BERT的第二块优化就是使用了全词掩码的预训练方式。从上图中右边部分可以看出,原生BERT从字粒度进行掩码操作,比如对苹和莲进行了Mask操作。而基于全词掩码的预训练方式则是从词粒度进行掩码操作,比如会对苹果和榴莲两个词进行Mask操作。这种全词掩码的预训练操作其实和百度的Ernie模型有异曲同工之妙,主要是结合中文的实际应用场景,应用知识图谱加入更多中文语义的信息,从而使得模型的效果有一定提升。
整体来看我们预训练模型的优化经历了google原生中文BERT到ALBERT再到最后目前线上使用的RoBERTa-wwm-ext的过程。
2.3 句向量表示优化
对于文本分类任务来说,BERT论文建议直接取CLS向量作为句向量表示,因为作者认为CLS已经可以作为语句向量的表示。下面是句向量表示图:

关于句向量表示优化,我们尝试了最后一层Transformer的首字符句向量(CLS)、每个字对应的Embedding取均值AVG、取和SUM,最后使用了第一层Transformer和最后一层Transformer得到的字向量累加之后再取均值操作。这么做的原因是对文本进行token
embedding词编码之后第一层Transformer得到的embedding向量包含更多的词向量信息,最后一层Transformer之后的embedding向量包含更多语句向量信息,将两者累加之后可以最大程度上保留词和语句的向量信息。
2.4 分类层优化
通过句向量表示我们可以得到一个768维的向量,接下来就是分类层优化。最简单的分类层就是直接添加一个softmax全连接层进行分类。对于二分类任务来说,通常会使用sigmoid函数,但是通过实验对比发现softmax函数效果会优于sigmoid函数。之前在知乎上看到这个问题的回答,里面的结论是从理论角度来说二分类问题两者是没有区别的,但是因为Pytorch、TensorFlow等框架计算矩阵方式的问题,导致两者在反向传播的过程中还是有区别的。对于NLP而言使用softmax的处理方式会优于sigmoid,而CV则相反,使用sigmoid会优于softmax。我们在NLP实验中也证明使用softmax的效果是优于sigmoid。
除了最后一层分类层使用softmax之外,还可以根据训练集规模大小以及任务的难度来决定是否使用更多的分类层。实验中对比了1-3层全连接层对模型效果的影响,1层就是直接最后添加一层softmax全连接层,2层则是先将768转化为256维度之后再接softmax,3层则是将768转换为256再转换为128最后再接softmax。最后实验结果是使用两层全连接层效果是最好的。
2.5 损失函数优化
在文本分类任务或者说机器学习任务中经常会遇到样本不均衡问题,这时候可以考虑从损失函数进行优化,比如可以尝试Focal loss、GHM loss等进行优化。我们实际任务中使用Focal loss也能一定程度上提升模型的线上效果。关于文本分类任务中解决样本不均衡问题可以参考我之前写过的一篇文章:《广告行业中那些趣事系列24:从理论到实践解决文本分类中的样本不均衡问题》
2.6 文本分类任务转化成句子对关系任务
我们还尝试了将文本分类任务转化成句子对关系任务。比如我们现在需要构建一个汽车分类器,原本数据集格式是query,label(0或者1),现在我们将文本分类任务转化成句子对关系任务,就可以很好的利用标签信息,获取汽车标签相关的信息,构建数据集query,汽车标签相关信息,label。通过这种方式可以有效的利用标签文本信息,从而提升文本分类效果。实验证明将文本分类任务转换成句子对关系任务也能有效的提升文本分类效果。这里需要注意一个问题,如果将文本分类任务转化成句子对关系任务,则不能使用RoBERTa预训练模型,主要因为RoBERTa模型取消了NSP任务,这时候可以直接使用原生BERT模型或者百度的ERNIE模型。
03
总结及反思
本篇主要分享了我在绿厂广告场景中历时两年的文本分类项目模型优化实践。第一部分内容是背景介绍,包括业务介绍、项目背景及目标、技术选型、分类器组织方案以及技术选型,了解了项目背景的来龙去脉才能更好的完成项目;第二部分内容是文本分类项目模型优化实践,主要包括基于BERT文本分类模型架构、Encoder优化、句向量表示优化、分类层优化、损失函数优化以及文本分类任务转化成句子对关系任务等。通过上述优化实践,可以让我们对文本分类任务有更加深入的了解。文本分类项目应该是我完成度最高的项目之一,从0到1将NLP前沿模型应用到业务实践产生广告消耗,本身收获很大。欢迎感兴趣的小伙伴一起沟通交流,后面会继续分享从样本层面优化文本分类任务实践。