
上岸阿里,成功的背后是不为人知的坚持 | 深度学习知识考点总结
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达

1

2
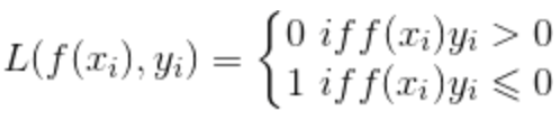
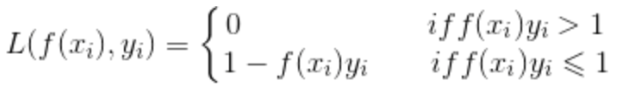
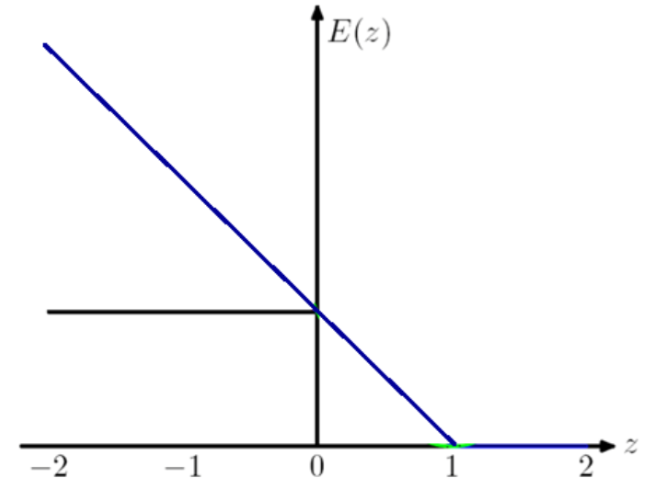
常用于多分类问题,描述了概率分布之间的不同,y是标签,p是预测概率:
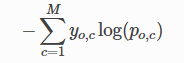
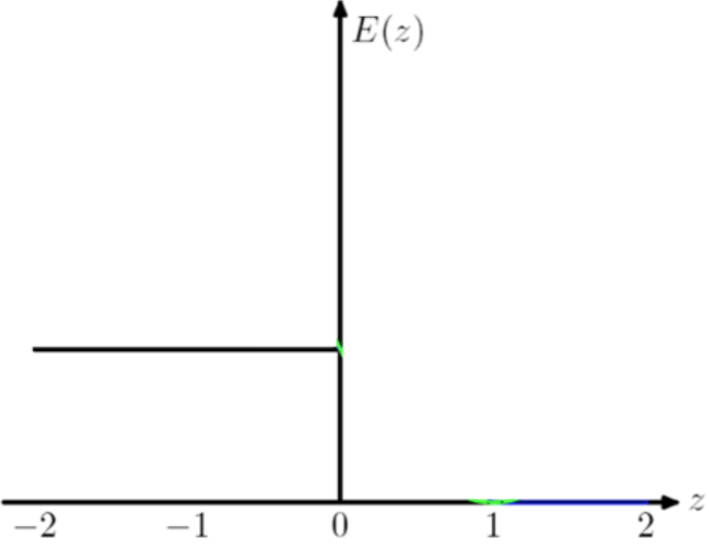
在逻辑回归也就是二分类问题中,上述公式可以写成:
![]()
这就是logistic loss。logistic loss 其实是 cross-entropy loss 的一个特例。
指数损失函数:
AdaBoost 算法常用的损失函数。
3、训练中出现过拟合的原因?深度学习里的正则方法有哪些/如何防止过拟合?
答:1)数据集不够;2)参数太多,模型过于复杂,容易过拟合;3)权值学习过程中迭代次数太多,拟合了训练数据中的噪声和没有代表性的特征。
Regularization is a technique which makes slight modifications to the learning algorithm such that the model generalizes better. 正则化是一种技术,通过调整可以让算法的泛化性更好,控制模型的复杂度,避免过拟合。1)L1&L2正则化;2)Dropout(指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络);3)数据增强、加噪;4)early stopping(提前终止训练);5)多任务联合;6)加BN。
4、l1、l2原理?dropout具体实现原理,随机还是固定,训练过程和测试过程如何控制,是针对sample还是batch?
答:L1 正则化向目标函数添加正则化项,以减少参数的绝对值总和;而 L2 正则化中,添加正则化项的目的在于减少参数平方的总和。线性回归的L1正则化通常称为LASSO(Least Absolute Shrinkage and Selection Operator)回归。LASSO回归可以使得一些特征的系数变小,甚至还有一些绝对值较小的系数直接变为0,从而增强模型的泛化能力,因此特别适用于参数数目缩减与参数的选择,因而用来估计稀疏参数的线性模型。
为什么L1正则化相比L2正则化更容易获得稀疏解?采用L1范数时平方误差项等值线与正则化项等值线的交点常出现在坐标轴上,即w1或w2为0,而在采用L2范数时,两者的交点常出现在某个象限中,即w1或w2均非0。因此,L1范数比L2范数更易于得到稀疏解。(周志华机器学习)
dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。训练的时候使用dropout,测试的时候不使用。Dropout的思想是训练DNNs的整体然后平均整体的结果,而不是训练单个DNN。DNNs以概率p丢弃神经元,因此保持其它神经元概率为q=1-p。当一个神经元被丢弃时,无论其输入及相关的学习参数是多少,其输出都会被置为0。丢弃的神经元在训练阶段的前向传播和后向传播阶段都不起作用:因为这个原因,每当一个单一的神经元被丢弃时,训练阶段就好像是在一个新的神经网络上完成。大概是sample吧。(我感觉有点像非结构化稀疏剪枝)
5、weight decay和范数正则有什么关系?
6、详细比较sigmoid、relu、leaky-relu等激活函数?
答:sigmoid公式:
![]()
它输入实数值并将其“挤压”到0到1范围内,适合输出为概率的情况,但是现在已经很少有人在构建神经网络的过程中使用sigmoid。
Sigmoid函数饱和使梯度消失。当神经元的激活在接近0或1处时会饱和,在这些区域梯度几乎为0,这就会导致梯度消失,几乎就有没有信号通过神经传回上一层。
Sigmoid函数的输出不是零中心的。因为如果输入神经元的数据总是正数,那么关于
 的梯度在反向传播的过程中,将会要么全部是正数,要么全部是负数,这将会导致梯度下降权重更新时出现z字型的下降。
的梯度在反向传播的过程中,将会要么全部是正数,要么全部是负数,这将会导致梯度下降权重更新时出现z字型的下降。
tanh公式:

Tanh非线性函数图像如下图所示,它将实数值压缩到[-1,1]之间。
Tanh解决了Sigmoid的输出是不是零中心的问题,但仍然存在饱和问题。为了防止饱和,现在主流的做法会在激活函数前多做一步batch normalization,尽可能保证每一层网络的输入具有均值较小的、零中心的分布。
relu公式:
![]()
ReLU非线性函数图像如下图所示。
sigmoid和tanh在求导时含有指数运算,而ReLU求导几乎不存在任何计算量。
单侧抑制;
稀疏激活性;
ReLU单元比较脆弱并且可能“死掉”,而且是不可逆的,因此导致了数据多样化的丢失。通过合理设置学习率,会降低神经元“死掉”的概率。
Leaky ReLU公式:
![]()
其中α是很小的负数梯度值,比如0.01,Leaky ReLU非线性函数图像如下图所示。这样做目的是使负轴信息不会全部丢失,解决了ReLU神经元“死掉”的问题。
ELU公式:

ELU函数是针对ReLU函数的一个改进型,相比于ReLU函数,在输入为负数的情况下,是有一定的输出的,而且这部分输出还具有一定的抗干扰能力。这样可以消除ReLU死掉的问题,不过还是有梯度饱和和指数运算的问题。
7、说说BN,BN的全称,BN的作用,为什么能解决梯度爆炸?BN一般放在哪里?
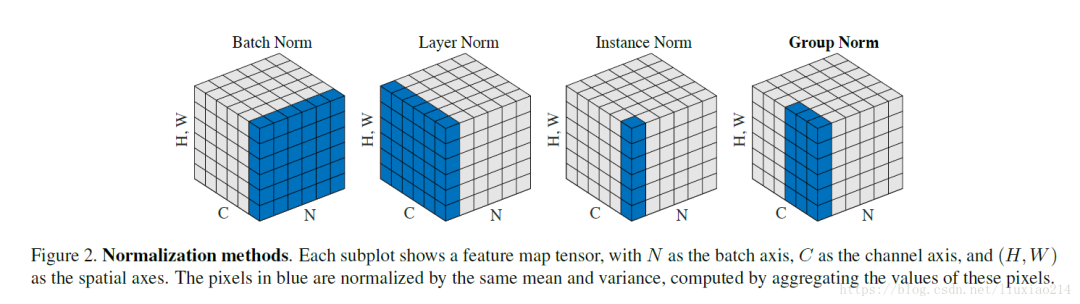
答:Batch Normalization。归一化的作用,经过BN的归一化消除了尺度的影响,避免了反向传播时因为权重过大或过小导致的梯度消失或爆炸问题,从而可以加速神经网络训练。BN一般放在激活函数后面。
1)BN归一化的维度是[N,H,W],那么channel维度上(N,H,W方向)的所有值都会减去这个归一化的值,对小的batch size效果不好;2)LN归一化的维度是[H,W,C],那么batch维度上(H,W,C方向)的所有值都会减去这个归一化的值,主要对RNN作用明显;3)IN归一化的维度是[H,W],那么H,W方向的所有值都会减去这个归一化的值,用在风格化迁移;4)GN是将通道分成G组,归一化的维度为[H,W,C//G]。
8、skip connection的作用。
答:防止梯度消失;传递浅层信息,比如边缘、纹理和形状。CNNs with skip connections have been the main stream for modern network design since it can mitigate the gradient vanishing/exploding issue in ultra deep networks by the help of skip connections.
9、图像分割领域常见的loss function?
答:第一,softmax+cross entropy loss,比如fcn和u-net。
第二,第一的加权版本,比如segnet,每个类别的权重不一样。
第三,使用adversarial training,加入gan loss。
(第四,sigmoid+dice loss,比如v-net,只适合二分类。
第五,online bootstrapped cross entropy loss,比如FRNN。
第六,类似于第四,sigmoid+jaccard(IoU),只适合二分类,但是可推广到多类。)
10、BN应该放在非线性激活层的前面还是后面?
答:在BN的原始论文中,BN是放在非线性激活层前面的。但是现在目前在实践中,倾向于把BN放在ReLU后面,也有评测表明BN放ReLu后面更好。还有一种观点,BN放在非线性函数前还是后取决于你想要normalize的对象,更像一个超参数。
11、语义分割和无人驾驶分割的区别?
答:无人驾驶分割主要用的是视频语义分割。
视频语义分割任务具有低延迟,高时序相关等要求,因此需要在图片语义分割的任务中进一步发展。尤其是在自动驾驶任务中,视频数据量大,车速快,车载计算能力有限,因此对自动驾驶相关的计算机视觉算法在时间消耗上都有很严格的要求。
如何有效利用视频帧之间的时序相关性将对视频分割结果产生很大影响,目前主流分为两派,一类是利用时间连续性增强语义分割结果的准确性,另一种则关注如何降低计算成本,以达到实时性要求。
12、实例分割和语义分割的区别?
答:语义分割:该任务需要将图中每一点像素标注为某个物体类别。
同一物体的不同实例不需要单独分割出来。比如标记出羊,而不需要羊1,羊2,羊3,羊4,羊5。
实例分割是物体检测+语义分割的综合体。相对物体检测的边界框,实例分割可精确到物体的边缘;相对语义分割,实例分割可以标注出图上同一物体的不同个体(羊1,羊2,羊3...)。
13、VGGNet的卷积核尺寸是多少?max pooling使用的尺寸?为什么使用3*3的尺寸?
答:VGGNet论文中全部使用了3*3的卷积核和2*2的池化核,通过不断加深网络结构来提升性能。使用3*3的卷积核,既可以保证感受野,又能减少卷积的参数。两个3*3的卷积层叠加,等价于一个5*5的卷积核的效果,3个3*3的卷积核的叠加相当于一个7*7的卷积核,而且参数更少,拥有和7*7卷积核一样的感受视野,三个卷积层的叠加,经过了更多次的非线性变换,对特征的学习能力更强。
计算一下5×5卷积核参数,输入时RGB三通道图像,输出channel为2,计算一共需要多少参数。其中,25×3×2=150。
14、了解Inception网络吗?
答:v1版本使用了不同大小的卷积核,不同大小的感受野拼接意味着不同尺度特征的融合。增加网络宽度的好处,来源于不同尺度的卷积核并联,从而实现了对multi-scale特征的利用。卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了。但是带来了一个问题,计算成本大大增加,不仅仅5x5就卷积计算成本高,concatenate会增加每层feature map的数量,因此提出了1x1卷积(NIN)用来降维。googlenet就用了inception v1的结构,还用到了auxiliary loss,防止梯度消失。

v2版本将v1中的5*5卷积替换成了两个3*3,可以减少参数。更进一步,将3*3卷积替换成了3*1和1*3卷积,可以更进一步减少参数。任意nxn的卷积都可以通过1xn卷积后接nx1卷积来替代。实际上,作者发现在网络的前期使用这种分解效果并不好,还有在中度大小的feature map上使用效果才会更好。该结构被正式用在GoogLeNet V2中。
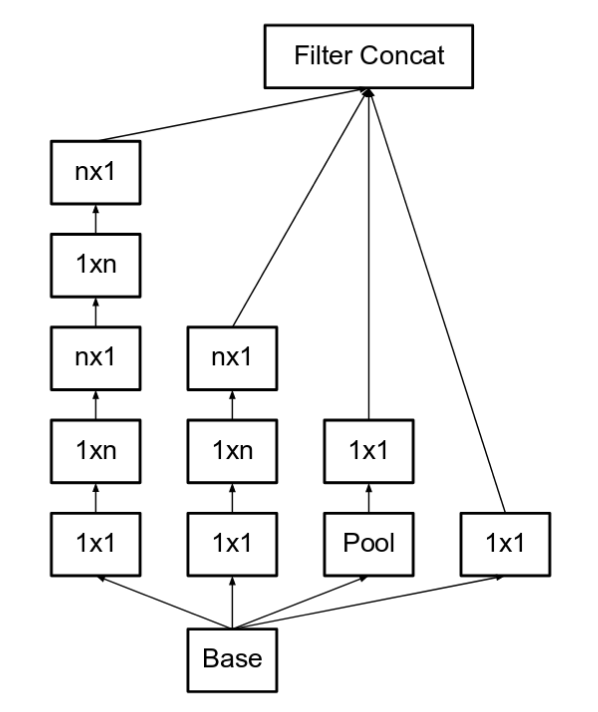
v3版本和v2版本出现在同一篇文章中,Rethinking the Inception Architecture for Computer Vision。v3比v2多的是分解了7*7卷积,辅助分类器使用了 BatchNorm。
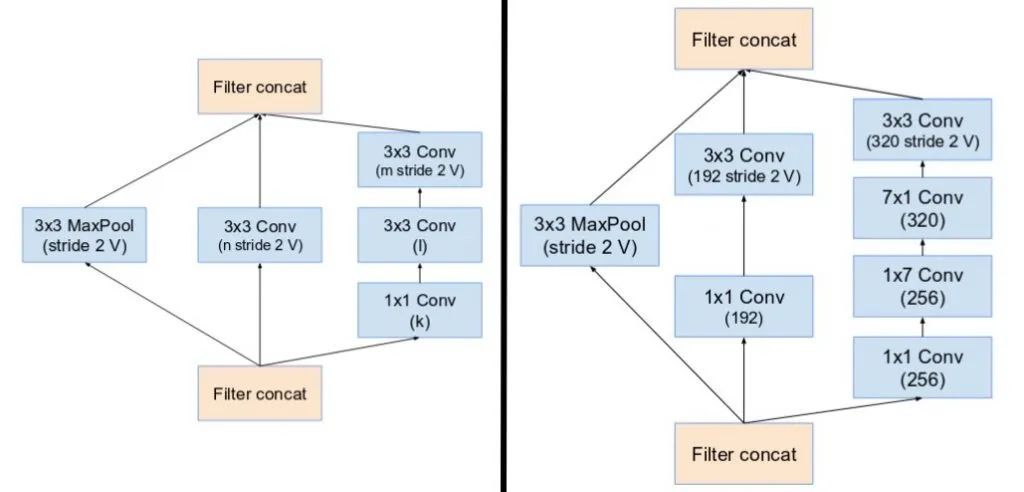
v4版本添加了reduction block,用于改变网格的宽度和高度。
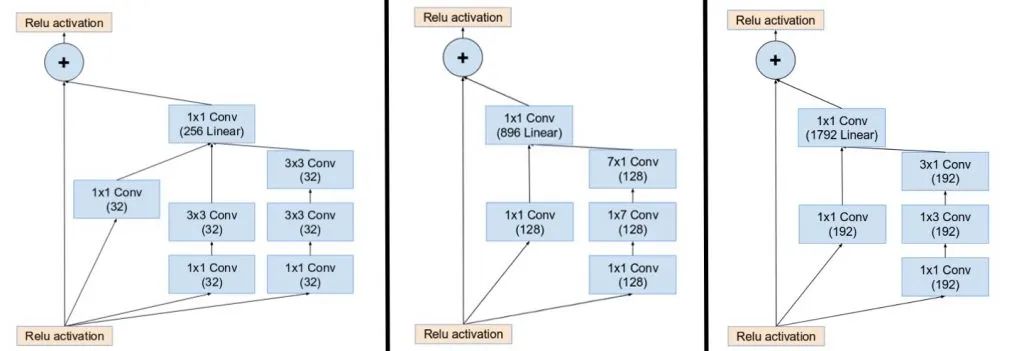
inception-resnet引入残差连接,将 inception 模块的卷积运算输出添加到输入上。
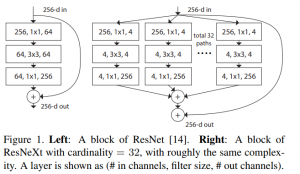
15、了解ResNext网络吗?
答:采用 VGG 堆叠的思想和 Inception 的 split-transform-merge 思想,但是可扩展性比较强,可以认为是在增加准确率的同时基本不改变或降低模型的复杂度。本质上是引入了group操作同时加宽了网络。
16、1×1的卷积核有什么作用?
答:1)可以升维降维;2)卷积参数少;3)加入非线性;4)在一篇论文中看到的描述,1×1 learns complex cross-channel interactions. 在一个blog看到的描述, This convolution is used in order to “blend” information among channels.
17、了解几种常见池化方法?池化怎么反向传播?
答:1)平均池化,把一个patch中的值求取平均来做pooling,那么反向传播的过程也就是把某个元素的梯度等分为n份分配给前一层,这样就保证池化前后的梯度之和保持不变。2)最大池化是把patch中最大的值传递给后一层,而其他像素的值直接被舍弃掉。那么反向传播也就是把梯度直接传给前一层某一个像素,而其他像素不接受梯度,也就是为0。所以max pooling操作和mean pooling操作不同点在于需要记录下池化操作时到底哪个像素的值是最大。
18、global average pooling的原理?
答:出自NIN论文,主要是是将最后一层的特征图进行整张图的一个均值池化,形成一个特征点,将这些特征点组成最后的特征向量。
19、FCN网络为什么用全卷积层代替全连接层?
答:个人理解。输入的图像尺寸可以是动态的,如果是全连接输入的图像尺寸必须是固定的;可以输出密集的像素级别的预测,将端到端的卷积网络推广到语义分割中;卷积可以减少参数量。
20、SegNet的结构原理?
答:SegNet是典型的编码解码的过程,Encoder过程中,卷积的作用是提取特征,卷积后不改变图片大小;在Decoder过程中,同样使用不改变图片大小的卷积,卷积的作用是为upsampling变大的图像丰富信息,使得在Pooling过程中丢失的信息可以通过学习在Decoder中得到。decoder不是采用的转置卷积,而是池化+卷积实现的上采样。每次Pooling,都会保存通过max选出的权值在2x2 filter中的相对位置,在Upsamping层中可以得到在Pooling中相对Pooling filter的位置。所以Upsampling中先对输入的特征图放大两倍,然后把输入特征图的数据根据Pooling indices放入。
21、pspnet原理?
答:PSPNet的提出是为了聚合不同区域的上下文信息,从而提高获取全局信息的能力。比如语义分割结果的大环境是一条河,河里的船有可能被识别成车,但是如果有了全局信息,就知道河里是不可能有车的,所以就不会出现这种问题的。encoder部分采用的是ResNet,和普通的resnet不一样的部分是把7*7卷积换成了3个3*3卷积,我觉得这点就挺有用的,因为7*7会降低分辨率,损失了很多信息,用3个3*3的卷积感受野没有变,但是信息损失的相对小了。
而且在resnet中还用到了空洞卷积,空洞卷积的作用就是让卷积核变得蓬松,在已有的像素上,skip掉一些像素,或者输入不变,对conv的kernel参数中插一些0的weight,达到一次卷积看到的空间范围变大的目的,所以感受野变大了,同时计算量不变,更重要的是图像的分辨率没有改变不会损失信息。提取特征之后用到了金字塔池化模块,分别用四个池化等级加卷积提取不同尺度的特征,最终和原提取特征一起用concat操作聚合到了一起。

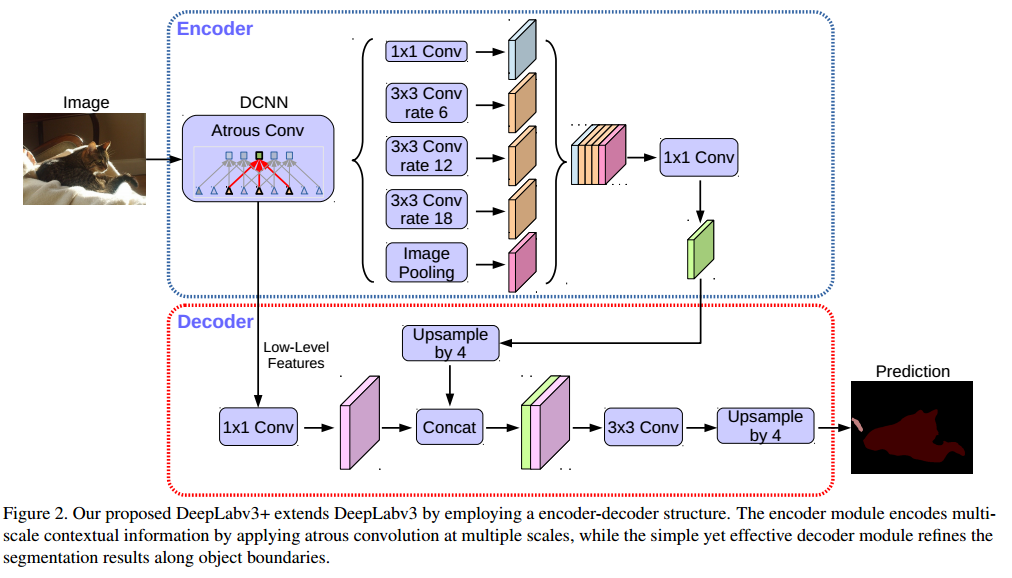
22、Deeplab的改进?Deeplab V3结构原理?Deeplab V3+改进?
答:Deeplab-v1是用了含有空洞卷积的VGG加上CRF后处理。
v2是在v1基础上改进的,用的是有空洞卷积的ResNet101,还提出了ASPP模块,并行的采用多个采样率的空洞卷积提取特征,再将特征融合。不再使用传统的CRF方法,而是利用dense CRF的方法,得到较为优秀的结果。

V3之后的文章就没有用CRF了。相对v2改动不是很大,还是用了空洞卷积,主要改进了ASPP模块,加入了BN和图像级别特征。另外文章指出了,在训练的时候将GT应该保持不动,将概率图插值之后再进行计算loss。

v3+将encoder部分替换成了X-inception,加入了深度可分离卷积,鉴于对最后的概率图依然使用大倍数的双线性插值恢复到与原图一样的大小还是过于简单,因此在这个版本中,增加了一个恢复细节的解码器部分。
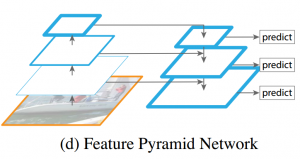
23、特征金字塔FPN?
答:何恺明发表在CVPR2015的论文Feature Pyramid Networks for Object Detection提到的,既可以在不同分辨率的feature map上检测对应尺度的目标,同时feature map又具有足够的特征表达能力,这是因为每层的feature map来源于当前层和更高级层的特征融合。每一级的feature map尺寸都是2倍的关系,“2x up”采用的是最简单的最近邻上采样。
24、Densenet什么时候比Resnet效果好?
答:数据集比较小的时候。因为数据集小的时候容易产生过拟合,但是DenseNet能很好解决过拟合问题,这一点从DenseNet不做数据增强的CIFAR数据集上的表现就能看出来,错误率明显下降了。DenseNet抗过拟合的原因有一个很直观的解释:神经网络每一层提取的特征都相当于对输入数据的一个非线性变换,而随着深度的增加,变换的复杂度也在增加,因为有着更多的非线性函数的复合。相比于一般神经网络的分类器直接依赖于网络最后一层(复杂度最高)的特征,DenseNet可以综合利用浅层复杂度低的特征,因而更容易得到一个光滑的泛化性能好的函数。
25、data augmentation怎么处理?
答:Color Jittering:对颜色的数据增强:图像亮度、饱和度、对比度变化;Random Scale:尺度变换;Random Crop:采用随机图像差值方式,对图像进行裁剪、缩放;Horizontal/Vertical Flip:水平/垂直翻转;Shift:平移变换;Rotation/Reflection:旋转/仿射变换;Noise:高斯噪声、模糊处理。
26、Restnet中各个stage是什么含义,如何串联在一起?Resnet50和Resnet101有什么区别?
答:第一个stage图像尺寸没有变,接下来每一个stage图像尺寸都缩小二倍。resnet50一共有四个stage,分别有3,4,6,3个block。resnet101一共有四个stage,分别有3,4,23,3个block。每个block有3层,resnet101相比resnet50只在第三个stage多了17个block,也就是多了17*3=51层。
27、你觉得ShuffleNet的缺点是什么?
答:根据shufflenet v2,组卷积使用过多,内存访问量比较大。
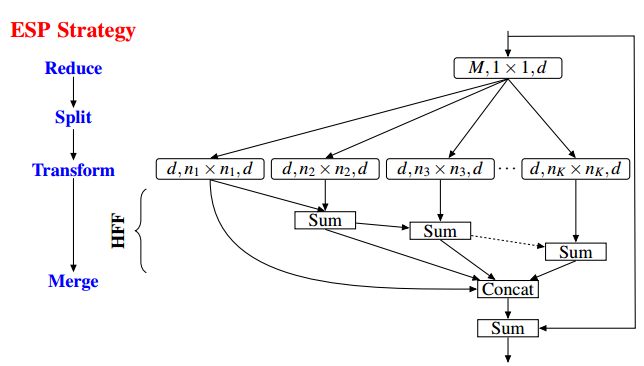
28、了解空洞卷积吗?你觉得空洞卷积有什么样的问题?
答:空洞卷积是在已有的像素上,skip掉一些像素,或者输入不变,对conv的kernel参数中插一些0的weight,达到一次卷积看到的空间范围变大的目的。连续空洞卷积的感受野是指数级增长。
空洞卷积有两个问题:1)The Gridding Effect:空洞卷积使卷积核不连续,损失了连续信息,而且当扩张率增加的时候,采样点之间间隔较远,局部信息丢失,就会产生很差的网格效应;2)Long-ranged information might be not relevant:我们从 dilated convolution 的设计背景来看就能推测出这样的设计是用来获取 long-ranged information。然而光采用大 dilation rate 的信息或许只对一些大物体分割有效果,不利于小物体分割。如何同时处理不同大小的物体的关系,则是设计好 dilated convolution 网络的关键。
解决办法:1)图森组的论文Understanding Convolution for Semantic Segmentation设计了HDC的结构,第一个特性是,叠加卷积的 dilation rate 不能有大于1的公约数。比如 [2, 4, 6] 则不是一个好的三层卷积,依然会出现 gridding effect。第二个特性是,我们将 dilation rate 设计成锯齿状结构,例如 [1, 2, 5, 1, 2, 5] 循环结构。第三个特性是,我们需要满足一下这个式子:
![]()
一个简单的例子: dilation rate [1, 2, 5] with 3 x 3 kernel (可行的方案),而这样的锯齿状本身的性质就比较好的来同时满足小物体大物体的分割要求(小dilation rate来关心近距离信息,大dilation rate 来关心远距离信息)。
2)Atrous Spatial Pyramid Pooling (ASPP):ASPP 则在网络 decoder 上对于不同尺度上用不同大小的 dilation rate 来抓去多尺度信息,每个尺度则为一个独立的分支,在网络最后把他合并起来再接一个卷积层输出预测 label。这样的设计则有效避免了在 encoder 上冗余的信息的获取,直接关注与物体之间之内的相关性。
3)在ECCV2018的论文ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation中说明ASPP仍会存在gridding artifacts的情况,所以他们提出用级联特征融合的方法改善这种情况。
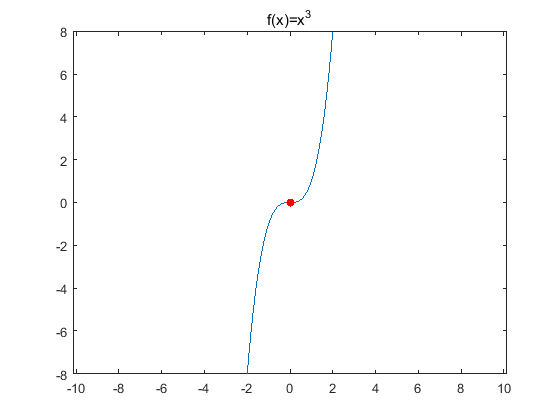
29、为什么牛顿法不常用?
答:牛顿法虽然收敛速度很快,但是需要计算梯度和二阶导数,也就是一个Hessian矩阵:1)有些时候,损失函数的显式方程不好求;2)输入向量的维度N较大时,H矩阵的大小是N*N,计算量很大而且内存需求也很大;3)牛顿法的步长是通过导数计算得来的,所以当临近鞍点的时候,步长会越来越小,这样牛顿法就很容易陷入鞍点之中。而sgd的步长是预设的固定值,相对容易跨过一些鞍点。
神经网络优化问题中的鞍点即一个维度向上倾斜且另一维度向下倾斜的点。鞍点和局部极小值相同的是,在该点处的梯度都等于0,不同在于在鞍点附近Hessian矩阵是不定的(行列式小于0),而在局部极值附近的Hessian矩阵是正定的。鞍点处的梯度为零,鞍点通常被相同误差值的平面所包围(这个平面又叫Plateaus,Plateaus是梯度接近于零的平缓区域,会降低神经网络学习速度),在高维的情形,这个鞍点附近的平坦区域范围可能非常大,这使得SGD算法很难脱离区域,即可能会长时间卡在该点附近(因为梯度在所有维度上接近于零)。(f(x)=x^3 中的(0,0)就是鞍点)
在鞍点数目极大的时候,这个问题会变得非常严重。高维非凸优化问题之所以困难,是因为高维参数空间存在大量的鞍点。
30、深度学习优化算法比较
目标函数关于参数的梯度:
![]()
根据历史梯度计算一阶和二阶动量:
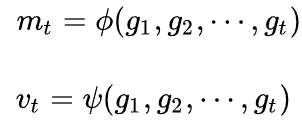
更新模型参数:
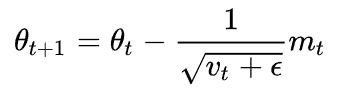
vanilla SGD:朴素SGD最为简单,没有动量的概念, η是学习率,更新步骤是:
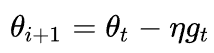
SGD的缺点在于收敛速度慢,可能在鞍点处震荡。并且,如何合理的选择学习率是SGD的一大难点。
Momentum:SGD 在遇到沟壑时容易陷入震荡。为此,可以为其引入动量 Momentum,加速 SGD 在正确方向的下降并抑制震荡。
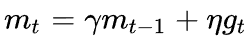
SGD-M在原步长之上,增加了与上一时刻步长相关的一阶动量γmt-1,γ通常取0.9左右。这意味着参数更新方向不仅由当前的梯度决定,也与此前累积的下降方向有关。这使得参数中那些梯度方向变化不大的维度可以加速更新,并减少梯度方向变化较大的维度上的更新幅度。由此产生了加速收敛和减小震荡的效果。
SGD 还有一个问题是困在局部最优的沟壑里面震荡。想象一下你走到一个盆地,四周都是略高的小山,你觉得没有下坡的方向,那就只能待在这里了。可是如果你爬上高地,就会发现外面的世界还很广阔。因此,我们不能停留在当前位置去观察未来的方向,而要向前一步、多看一步、看远一些。因此有了NAG。
Nesterov Accelerated Gradient:是在SGD、SGD-M的基础上的进一步改进。改进点在于步骤1。我们知道在时刻t的主要下降方向是由累积动量决定的,自己的梯度方向说了也不算,那与其看当前梯度方向,不如先看看如果跟着累积动量走了一步,那个时候再怎么走。因此,NAG在步骤1,不计算当前位置的梯度方向,而是计算如果按照累积动量走了一步,那个时候的下降方向:
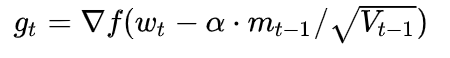
然后用下一个点的梯度方向,与历史累积动量相结合,计算步骤2中当前时刻的累积动量。
SGD、SGD-M 和 NAG 均是以相同的学习率去更新θ的各个分量,此前我们都没有用到二阶动量。二阶动量的出现,才意味着“自适应学习率”优化算法时代的到来。SGD及其变种以同样的学习率更新每个参数,但深度神经网络往往包含大量的参数,这些参数并不是总会用得到(想想大规模的embedding)。对于经常更新的参数,我们已经积累了大量关于它的知识,不希望被单个样本影响太大,希望学习速率慢一些;对于偶尔更新的参数,我们了解的信息太少,希望能从每个偶然出现的样本身上多学一些,即学习速率大一些。
Adagrad:二阶动量vt是迄今为止所有梯度值的平方和,学习率等效成:
![]()
对于此前频繁更新过的参数,其二阶动量的对应分量较大,学习率就较小。这一方法在稀疏数据的场景下表现很好。但是需要手动设置一个全局的学习率。
Adadelta:在Adagrad中, vt是单调递增的,使得学习率逐渐递减至 0,可能导致训练过程提前结束。为了改进这一缺点,可以考虑在计算二阶动量时不累积全部历史梯度,而只关注最近某一时间窗口内的下降梯度。
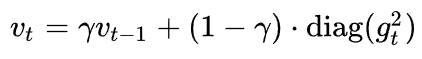
其二阶动量采用指数移动平均公式计算,这样即可避免二阶动量持续累积的问题。和SGD-M中的参数类似,γ通常取0.9左右。不依赖于全局学习率。
RMSprop:可以看做为Adadalta的一个特例,Adadalta中的某个参数取0.5再求根的时候就变成RMS,对于变化较大的值方向能够抑制变化,较小的值方向加速变化,消除摆动加速收敛,但依赖全局学习率。
Adam:是RMSprop和momentum的结合。和 RMSprop 对二阶动量使用指数移动平均类似,Adam中对一阶动量也是用指数移动平均计算。
NAdam:在 Adam之上融合了 NAG的思想。
目前看过一些论文,感觉主流还是SGD或者是adam,resnet用的就是adam。据大多数文章来看,Adam收敛更快,但是调参的参数更好的话sgd准确率比adam要高。这个我也深有体会,曾经用adam和sgd同时训练一个任务,sgd的效果更好。
6
下载1:动手学深度学习
在「AI算法与图像处理」公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
