
PyTorch中的傅立叶卷积:通过FFT有效计算大核卷积的数学原理和代码实现
共 6857字,需浏览 14分钟
·
2020-11-21 15:49

极市导读
本篇文章从卷积的定理介绍、Pytorch的实现以及测试方面对傅立叶卷积提供了详尽的介绍,文章在Pytorch的实现部分进行了非常详细的讲解并附有相关的代码。文末最后还附有作者对卷积与互相关证明。>>加入极市CV技术交流群,走在计算机视觉的最前沿

卷积
卷积在数据分析中无处不在。几十年来,它们已用于信号和图像处理。最近,它们已成为现代神经网络的重要组成部分。
在数学上,卷积表示为:

尽管离散卷积在计算应用程序中更为常见,但由于本文使用连续变量证明卷积定理(如下所述)要容易得多,因此在本文的大部分内容中,我将使用连续形式。之后,我们将返回离散情况,并使用傅立叶变换在PyTorch中实现它。离散卷积可以看作是连续卷积的近似值,其中连续函数在规则网格上离散化。因此,我们不会为离散情况重新证明卷积定理。
卷积定理
在数学上,卷积定理可以表示为:

连续傅里叶变换的位置(最大归一化常数):
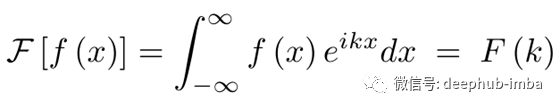
换句话说,位置空间的卷积等价于频率空间的直接乘法。这个想法是相当不直观的,但证明卷积定理是惊人的容易对于连续的情况。首先把方程的左边写出来。
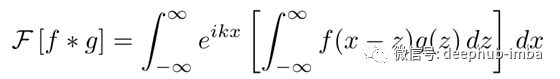
现在改变积分的顺序,替换变量(x = y + z),并分离两个被积函数。
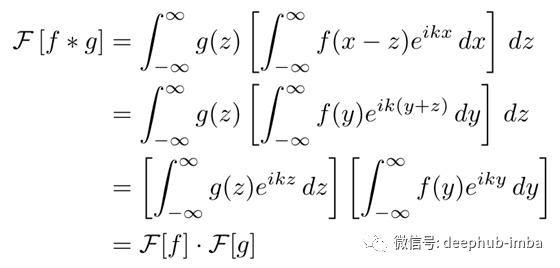
我们为什么要关心所有这些?因为快速傅立叶变换的算法复杂度比卷积低。直接卷积的复杂度为O(n²),因为我们将g中的每个元素传递给f中的每个元素。快速傅立叶变换可以在O(n log n)的时间内计算出来。当输入数组很大时,它们比卷积要快得多。在这些情况下,我们可以使用卷积定理来计算频率空间中的卷积,然后执行傅立叶逆变换以返回到位置空间。
当输入较小时(例如3x3卷积内核),直接卷积仍然更快。在机器学习应用程序中,使用较小的内核大小更为常见,因此PyTorch和Tensorflow之类的深度学习库仅提供直接卷积的实现。但是,在现实世界中,有很多使用大内核的用例,其中傅立叶卷积更为有效。
PyTorch实现
现在,我将演示如何在PyTorch中实现傅立叶卷积函数。它应该模仿torch.nn.functional.convNd的功能,并在实现中利用FFT,而无需用户做任何额外的工作。这样,它应该接受三个张量(信号,内核和可选的偏差),并填充以应用于输入。从概念上讲,此功能的内部工作原理是:
def fft_conv(
signal: Tensor, kernel: Tensor, bias: Tensor = None, padding: int = 0,
) -> Tensor:
# 1. Pad the input signal & kernel tensors
# 2. Compute FFT for both signal & kernel
# 3. Multiply the transformed Tensors together
# 4. Compute inverse FFT
# 5. Add bias and return
让我们根据上面显示的操作顺序逐步构建FFT卷积。在此示例中,我将构建一个1D傅立叶卷积,但是将其扩展到2D和3D卷积很简单。最后我们也会提供github的代码库。在该存储库中,我实现了通用的N维傅立叶卷积方法。
1 填充输入阵列
我们需要确保填充后信号和内核的大小相同。将初始填充应用于信号,然后调整填充以使内核匹配。
# 1. Pad the input signal & kernel tensors
signal = f.pad(signal, [padding, padding])
kernel_padding = [0, signal.size(-1) - kernel.size(-1)]
padded_kernel = f.pad(kernel, kernel_padding)
注意,我只在一侧填充内核。我们希望原始内核位于填充数组的左侧,以便它与信号数组的开始对齐。
2 计算傅立叶变换
这非常容易,因为在PyTorch中已经实现了N维FFT。我们只需使用内置函数,然后沿每个张量的最后一个维度计算FFT。
# 2. Perform fourier convolution
signal_fr = rfftn(signal, dim=-1)
kernel_fr = rfftn(padded_kernel, dim=-1)
3 乘以变换后的张量
这是我们功能中最棘手的部分。这有两个原因。
(1)PyTorch卷积在多维张量上运行,因此我们的信号和内核张量实际上是三维的。从PyTorch文档中的该方程式,我们看到矩阵乘法是在前两个维度上执行的(不包括偏差项):
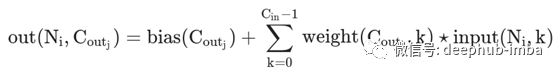
我们需要包括此矩阵乘法以及转换后的维度上的直接乘法。
(2)在官方文档中所示,PyTorch实际上实现了互相关方法而不是卷积。(TensorFlow和其他深度学习库也是如此。)互相关与卷积密切相关,但有一个重要的符号变化:
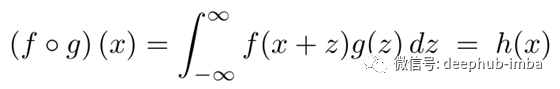
与卷积相比,这有效地逆转了核函数(g)的方向。我们不是手动翻转核函数,而是通过求傅里叶空间中核函数的复共轭来修正。因为我们不需要创建一个全新的张量,所以这大大加快了存储效率。(本文末尾的附录中包含了如何/为什么这样做的简要演示。)
# 3. Multiply the transformed matrices
def complex_matmul(a: Tensor, b: Tensor) -> Tensor:
"""Multiplies two complex-valued tensors."""
# Scalar matrix multiplication of two tensors, over only the first two dimensions.
# Dimensions 3 and higher will have the same shape after multiplication.
scalar_matmul = partial(torch.einsum, "ab..., cb... -> ac...")
# Compute the real and imaginary parts independently, then manually insert them
# into the output Tensor. This is fairly hacky but necessary for PyTorch 1.7.0,
# because Autograd is not enabled for complex matrix operations yet. Not exactly
# idiomatic PyTorch code, but it should work for all future versions (>= 1.7.0).
real = scalar_matmul(a.real, b.real) - scalar_matmul(a.imag, b.imag)
imag = scalar_matmul(a.imag, b.real) + scalar_matmul(a.real, b.imag)
c = torch.zeros(real.shape, dtype=torch.complex64)
c.real, c.imag = real, imag
return c
# Conjugate the kernel for cross-correlation
kernel_fr.imag *= -1
output_fr = complex_matmul(signal_fr, kernel_fr)
PyTorch 1.7改进了对复数的支持,但是autograd中还不支持对复数值张量的许多操作。现在,我们必须编写自己的complex_matmul方法作为补丁。虽然不是最佳的解决方案,但它目前可以工作。
4 计算逆变换
使用torch.irfftn可以很容易地计算出逆变换。然后,裁剪出多余的数组填充。
# 4. Compute inverse FFT, and remove extra padded values
output = irfftn(output_fr, dim=-1)
output = output[:, :, :signal.size(-1) - kernel.size(-1) + 1]
5 添加偏置并返回
添加偏置项也非常容易。请记住,偏置对输出阵列中的每个通道都有一个元素,并进行相应的整形。
# 5. Optionally, add a bias term before returning.
if bias is not None:
output += bias.view(1, -1, 1)
放在一起
为了完整起见,让我们将所有这些代码段编译为一个内聚函数。
def fft_conv_1d(
signal: Tensor, kernel: Tensor, bias: Tensor = None, padding: int = 0,
) -> Tensor:
"""
Args:
signal: (Tensor) Input tensor to be convolved with the kernel.
kernel: (Tensor) Convolution kernel.
bias: (Optional, Tensor) Bias tensor to add to the output.
padding: (int) Number of zero samples to pad the input on the last dimension.
Returns:
(Tensor) Convolved tensor
"""
# 1. Pad the input signal & kernel tensors
signal = f.pad(signal, [padding, padding])
kernel_padding = [0, signal.size(-1) - kernel.size(-1)]
padded_kernel = f.pad(kernel, kernel_padding)
# 2. Perform fourier convolution
signal_fr = rfftn(signal, dim=-1)
kernel_fr = rfftn(padded_kernel, dim=-1)
# 3. Multiply the transformed matrices
kernel_fr.imag *= -1
output_fr = complex_matmul(signal_fr, kernel_fr)
# 4. Compute inverse FFT, and remove extra padded values
output = irfftn(output_fr, dim=-1)
output = output[:, :, :signal.size(-1) - kernel.size(-1) + 1]
# 5. Optionally, add a bias term before returning.
if bias is not None:
output += bias.view(1, -1, 1)
return output
测试
最后,我们将确认这在数值上等于使用torch.nn.functional.conv1d进行直接一维卷积。我们为所有输入构造随机张量,并测量输出值的相对差异。
import torch
import torch.nn.functional as f
torch.manual_seed(1234)
kernel = torch.randn(2, 3, 1025)
signal = torch.randn(3, 3, 4096)
bias = torch.randn(2)
y0 = f.conv1d(signal, kernel, bias=bias, padding=512)
y1 = fft_conv_1d(signal, kernel, bias=bias, padding=512)
abs_error = torch.abs(y0 - y1)
print(f'\nAbs Error Mean: {abs_error.mean():.3E}')
print(f'Abs Error Std Dev: {abs_error.std():.3E}')
# Abs Error Mean: 1.272E-05
# Abs Error Std Dev: 9.937E-06
每个元素相差约1e-5-相当准确,考虑到我们使用的是32位精度!我们还可以执行一个快速基准测试来衡量每种方法的速度:
from timeit import timeit
direct_time = timeit(
"f.conv1d(signal, kernel, bias=bias, padding=512)",
globals=locals(),
number=100
) / 100
fourier_time = timeit(
"fft_conv_1d(signal, kernel, bias=bias, padding=512)",
globals=locals(),
number=100
) / 100
print(f"Direct time: {direct_time:.3E} s")
print(f"Fourier time: {fourier_time:.3E} s")
# Direct time: 1.523E-02 s
# Fourier time: 1.149E-03 s
所测得的基准将随着您所使用的机器而发生重大变化。(我正在使用非常老的Macbook Pro进行测试。)对于1025的内核大小,傅立叶卷积似乎要快10倍以上。
总结
本片文章对傅立叶卷积提供了详尽的介绍。我认为这是一个很酷的技巧,并且可以在许多实际应用中使用它。我也很喜欢数学,因此很高兴看到编程和纯数学的这种交汇。欢迎并鼓励所有评论和建设性批评。
本文的代码 https://github.com/fkodom/fft-conv-pytorch
附录
卷积与互相关
在本文前面,我们通过在傅立叶空间中获取内核的复共轭来实现互相关。这有效地扭转了内核的方向,现在我想证明为什么。首先,请记住卷积和互相关的公式:

然后,让我们看一下内核的傅里叶变换(g):

取G的复共轭。请注意,内核g(x)是实值,因此不受共轭影响。然后,更改变量(y = -x)并简化表达式。

因此,我们有效地改变了内核的方向!
文章地址:https://towardsdatascience.com/fourier-convolutions-in-pytorch-4cbd23c70005
推荐阅读
