
用 Python 爬取起点小说网

目标
爬取一本仙侠类的小说下载并保存为txt文件到本地。本例为“大周仙吏”。
项目准备
软件:Pycharm
第三方库:requests,fake_useragent,lxml
网站地址:https://book.qidian.com
网站分析
打开网址:
网址变为:https://book.qidian.com/info/1020580616#Catalog
判断是否为静态加载网页,Ctrl+U打开源代码,Ctrl+F打开搜索框,输入:第一章。
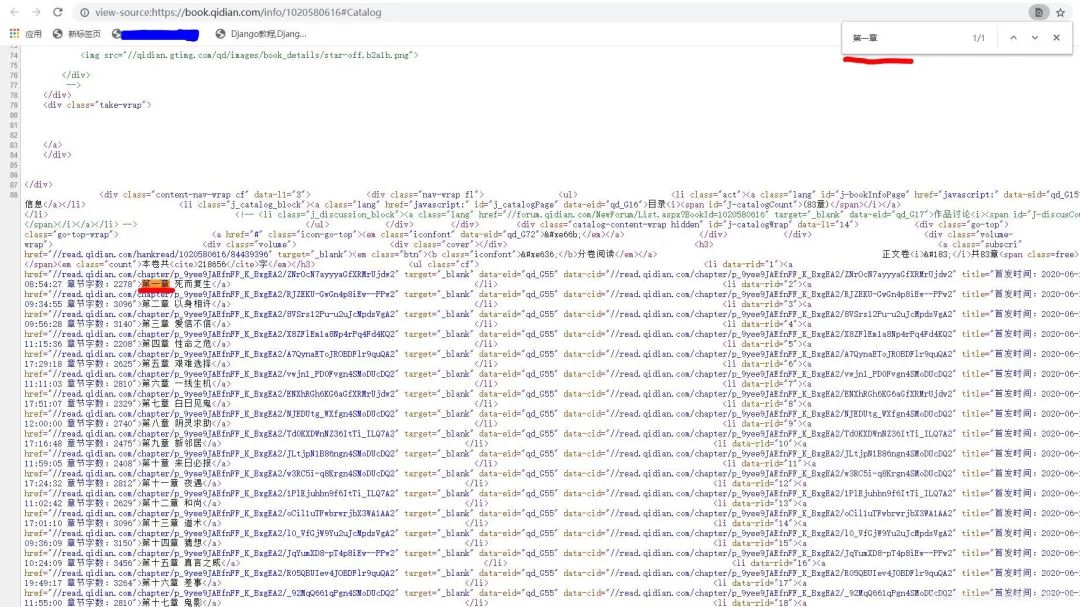
在这里是可以找到的,判定为静态加载。
反爬分析
同一个ip地址去多次访问会面临被封掉的风险,这里采用fake_useragent,产生随机的User-Agent请求头进行访问。
代码实现
1.导入相对应的第三方库,定义一个class类继承object,定义init方法继承self,主函数main继承self。
import requests
from fake_useragent import UserAgent
from lxml import etree
class photo_spider(object):
def __init__(self):
self.url = 'https://book.qidian.com/info/1020580616#Catalog'
ua = UserAgent(verify_ssl=False)
#随机产生user-agent
for i in range(1, 100):
self.headers = {
'User-Agent': ua.random
}
def mian(self):
pass
if __name__ == '__main__':
spider = qidian()
spider.main()
2.发送请求,获取网页。
def get_html(self,url):
response=requests.get(url,headers=self.headers)
html=response.content.decode('utf-8')
return html
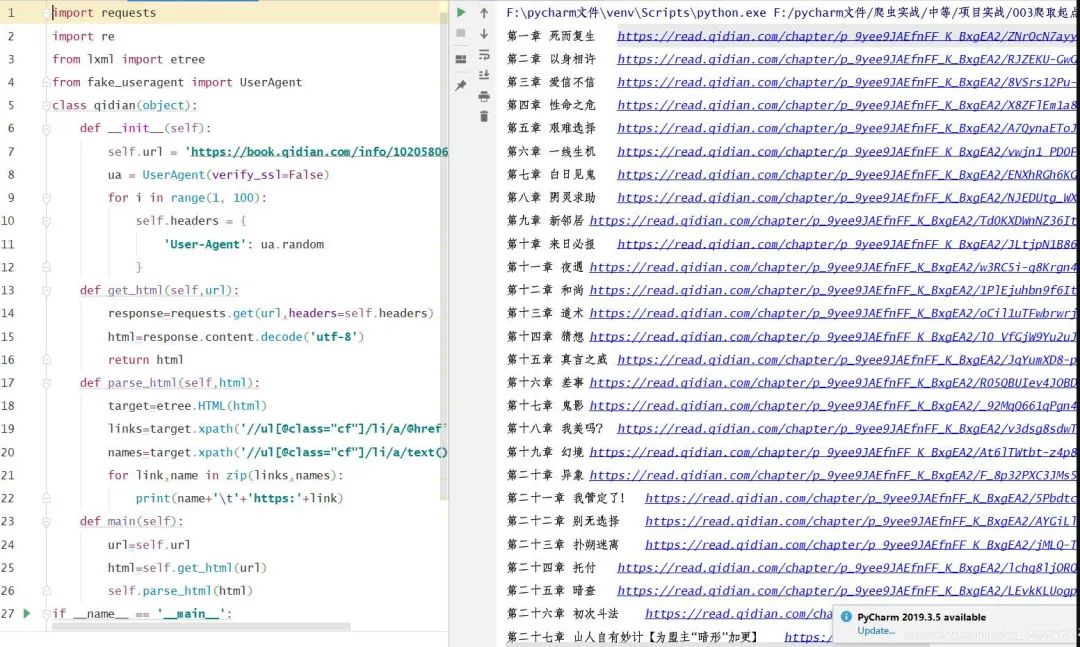
3.获取图片的链接地址。
import requests
from lxml import etree
from fake_useragent import UserAgent
class qidian(object):
def __init__(self):
self.url = 'https://book.qidian.com/info/1020580616#Catalog'
ua = UserAgent(verify_ssl=False)
for i in range(1, 100):
self.headers = {
'User-Agent': ua.random
}
def get_html(self,url):
response=requests.get(url,headers=self.headers)
html=response.content.decode('utf-8')
return html
def parse_html(self,html):
target=etree.HTML(html)
links=target.xpath('//ul[@class="cf"]/li/a/@href')#获取链接
names=target.xpath('//ul[@class="cf"]/li/a/text()')#获取每一章的名字
for link,name in zip(links,names):
print(name+'\t'+'https:'+link)
def main(self):
url=self.url
html=self.get_html(url)
self.parse_html(html)
if __name__ == '__main__':
spider=qidian()
spider.main()
打印结果:
4.解析链接,获取每一章内容。
def parse_html(self,html):
target=etree.HTML(html)
links=target.xpath('//ul[@class="cf"]/li/a/@href')
for link in links:
host='https:'+link
#解析链接地址
res=requests.get(host,headers=self.headers)
c=res.content.decode('utf-8')
target=etree.HTML(c)
names=target.xpath('//span[@class="content-wrap"]/text()')
results=target.xpath('//div[@class="read-content j_readContent"]/p/text()')
for name in names:
print(name)
for result in results:
print(result)
打印结果:(下面内容过多,只贴出一部分。)

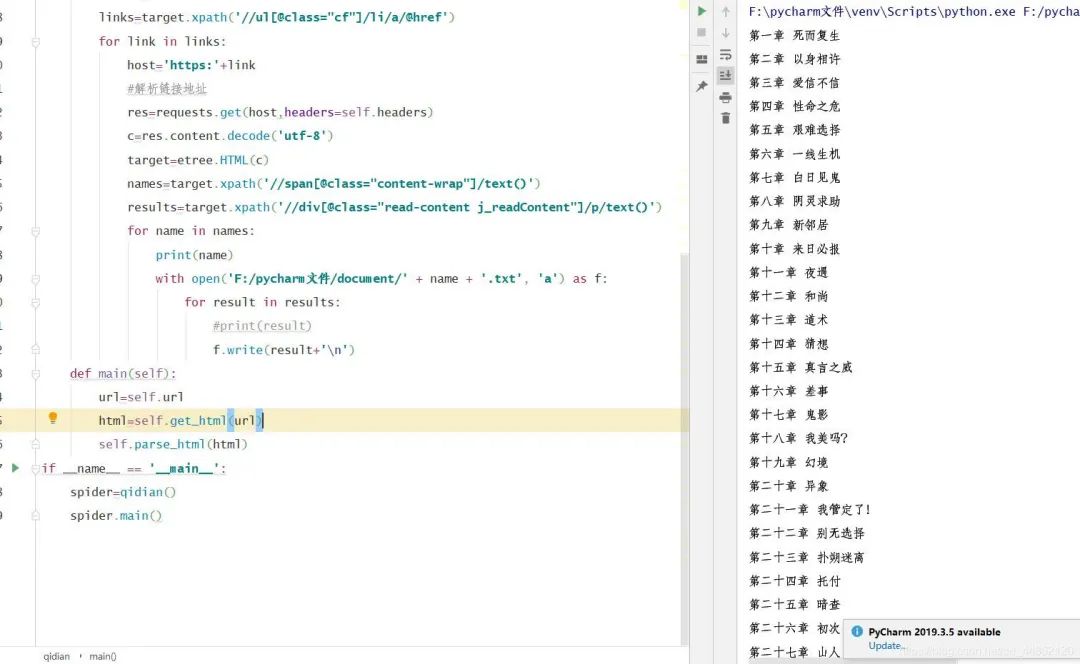
5.保存为txt文件到本地。
with open('F:/pycharm文件/document/' + name + '.txt', 'a') as f:
for result in results:
#print(result)
f.write(result+'\n')
效果显示:
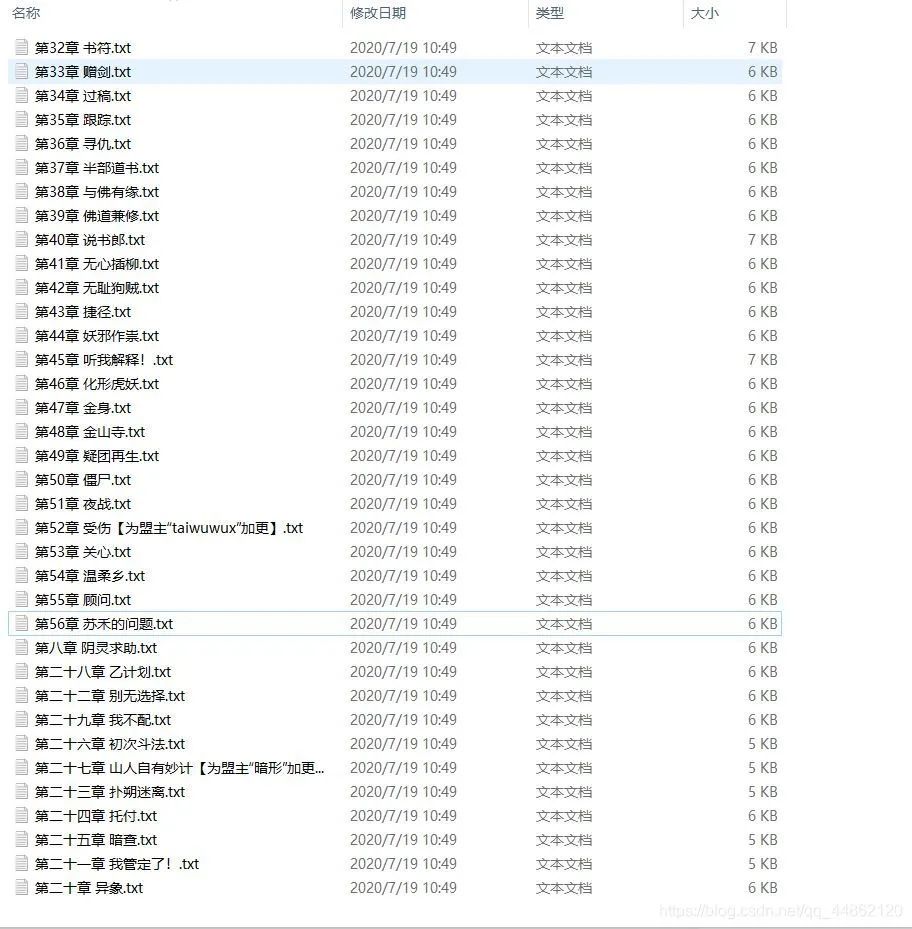
打开文件目录:
完整代码
import requests
from lxml import etree
from fake_useragent import UserAgent
class qidian(object):
def __init__(self):
self.url = 'https://book.qidian.com/info/1020580616#Catalog'
ua = UserAgent(verify_ssl=False)
for i in range(1, 100):
self.headers = {
'User-Agent': ua.random
}
def get_html(self,url):
response=requests.get(url,headers=self.headers)
html=response.content.decode('utf-8')
return html
def parse_html(self,html):
target=etree.HTML(html)
links=target.xpath('//ul[@class="cf"]/li/a/@href')
for link in links:
host='https:'+link
#解析链接地址
res=requests.get(host,headers=self.headers)
c=res.content.decode('utf-8')
target=etree.HTML(c)
names=target.xpath('//span[@class="content-wrap"]/text()')
results=target.xpath('//div[@class="read-content j_readContent"]/p/text()')
for name in names:
print(name)
with open('F:/pycharm文件/document/' + name + '.txt', 'a') as f:
for result in results:
#print(result)
f.write(result+'\n')
def main(self):
url=self.url
html=self.get_html(url)
self.parse_html(html)
if __name__ == '__main__':
spider=qidian()
spider.main()
更多阅读
特别推荐

点击下方阅读原文加入社区会员
评论