
如何批量给PDF添加水印?

我们有时候需要把一些机密文件发给多个客户,为了避免客户泄露文件,会在机密文件中添加水印。每个客户收到的文件内容相同,但是水印都不相同。这样一来,如果资料泄露了,通过水印就知道是从谁手上泄露的。
今天,一个做市场的朋友找我咨询PDF加水印的问题,如下图所示:
他有一个Excel文件,文件里面有10000个经销商的名字,他要把价目表PDF发给这些经销商,每个经销商收到的PDF文件上面的水印都是这个经销商自己的名字。
这个需求手动操作肯定要累死人。但是如果用Python来做,就非常简单。代码不超过30行。
准备环境
要完成这个需求,需要安装两个模块,分别叫做reportlab和pikepdf。使用Pip安装就可以了:
python3 -m pip install reportlab pikepdf
然后,需要找到一个.ttf或者.ttc格式的中文字体。你可以直接从网上下载中文字体文件。也可以使用系统自带的中文字体。这里以寻找macOS系统默认的宋体为例。
macOS系统字体在/System/Library/Fonts,宋体对应的.ttc文件地址是/System/Library/Fonts/Supplemental/Songti.ttc。对于系统默认的字体,我们只需要知道它的对应的文件名叫做Songti.ttc就可以了。如果是从网上下载的第三方字体,需要使用绝对路径或者相对于项目代码的相对路径。
获得经销商名字对应的列表
由于这位朋友不会使用pandas,那么我们就尽量使用Python原生的方法来获得经销商名字列表。假设经销商信息对应的Excel如下图所示:

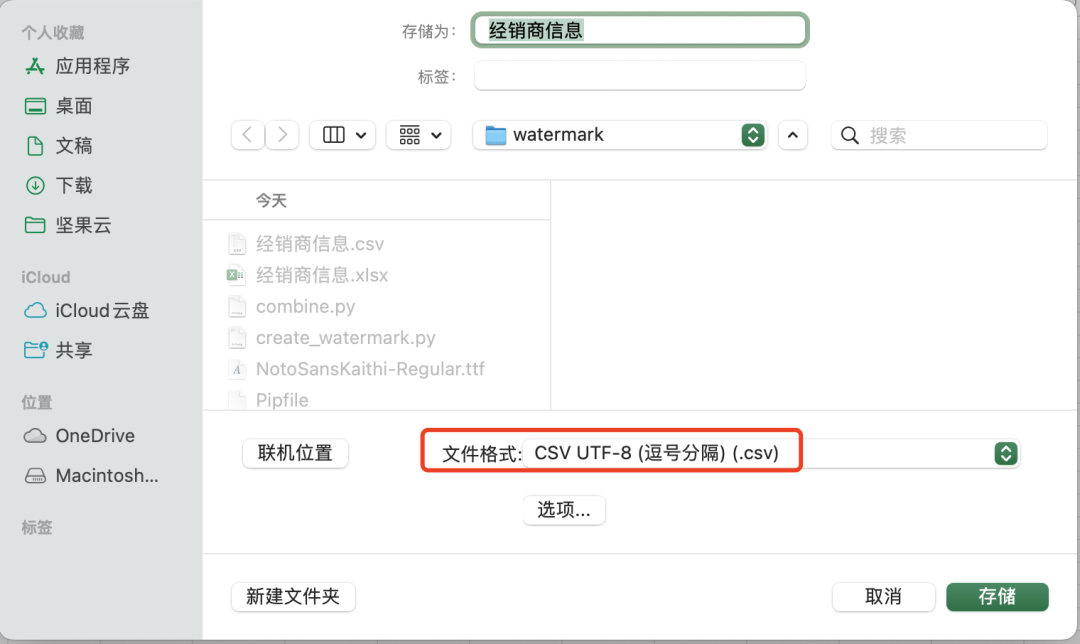
我们首先把这个Excel文件导出成csv文件:
然后,我们用Python读取这个csv文件,获得经销商名字列表:
import csv
with open('经销商信息.csv') as f:
reader = csv.DictReader(f)
name_list = [x['经销商名字'] for x in reader]
print(name_list)
运行效果如下图所示:

生成水印PDF
一般来说,我们不能直接把一段文字作为水印添加到另一个PDF文件中。我们只有先把这段文字生成图片或者生成水印PDF文件,然后把这个图片或者水印PDF作为『图层』覆盖到目标PDF上面。
因此,现在需要给每一个经销商生成对应的水印PDF文件。这个PDF中只含有水印文字。效果如下图所示:
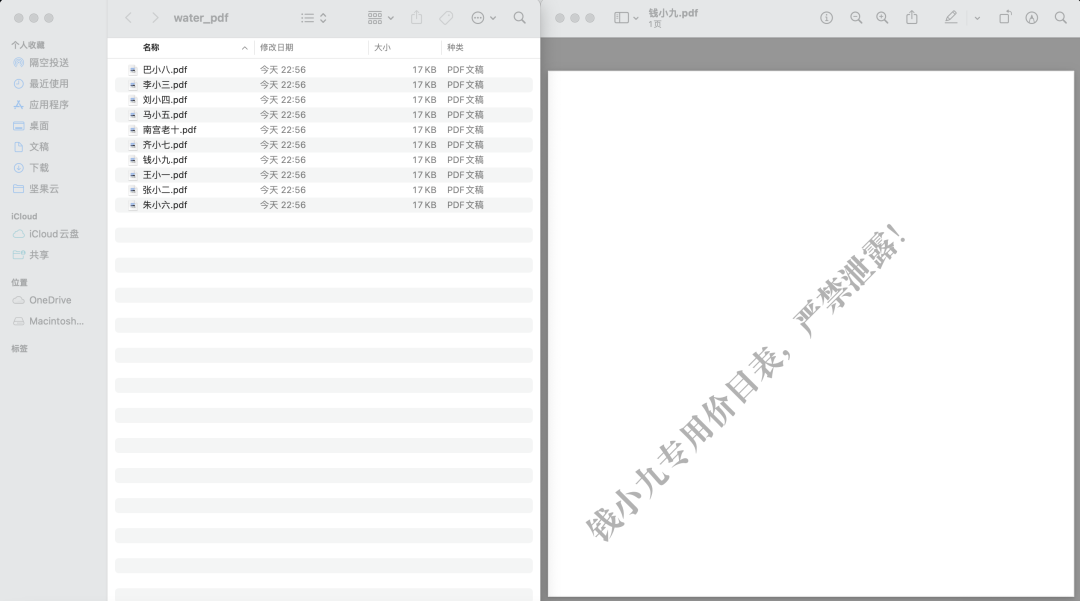
对应的代码create_watermark.py如下:
import csv
from pathlib import Path
from reportlab.lib import units
from reportlab.pdfgen import canvas
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
with open('经销商信息.csv') as f:
reader = csv.DictReader(f)
name_list = [x['经销商名字'] for x in reader]
pdfmetrics.registerFont(TTFont('Songti', 'Songti.ttc')) # 加载中文字体
water_mark_folder = Path('water_pdf') # 用一个文件夹存放所有的水印PDF
water_mark_folder.mkdir(exist_ok=True)
for name in name_list:
path = str(water_mark_folder / Path(f'{name}.pdf'))
c = canvas.Canvas(path, pagesize=(200 * units.mm, 200 * units.mm)) # 生成画布,长宽都是200毫米
c.translate(0.1 * 200 * units.mm, 0.1 * 200 * units.mm)
c.rotate(45) # 把水印文字旋转45°
c.setFont('Songti', 35) # 字体大小
c.setStrokeColorRGB(0, 0, 0) # 设置字体颜色
c.setFillColorRGB(0, 0, 0) # 设置填充颜色
c.setFillAlpha(0.3) # 设置透明度,越小越透明
c.drawString(0, 0, f'{name}专用价目表,严禁泄露!')
c.save()
代码的具体作用,已经写到注释中了。运行以后会在当前项目根目录生成water_pdf文件夹,里面就是生成的水印PDF。
合并水印与目标PDF
最后一步,把每一个经销商的水印PDF与目标PDF进行合并。水印PDF作为一个图层覆盖到目标PDF上面。
使用pikepdf完成这个工作非常简单,编写一个combine.py文件,代码如下:
import glob
from pathlib import Path
from pikepdf import Pdf, Page, Rectangle
water_pdf_list = glob.glob('water_pdf/*.pdf')
result = Path('result')
result.mkdir(exist_ok=True)
col = 2 # 每页多少列水印
row = 3 # 每页多少行水印
for path in water_pdf_list:
target = Pdf.open('./PythonisinstanceGolang.pdf') # 必须每次重新打开PDF,因为添加水印是inplace的操作
file = Path(path)
name = file.stem
water_mark_pdf = Pdf.open(path)
water_mark = water_mark_pdf.pages[0]
for page in target.pages:
for x in range(col): # 每一行显示多少列水印
for y in range(row): # 每一页显示多少行PDF
page.add_overlay(water_mark,
Rectangle(page.trimbox[2] * x / col,
page.trimbox[3] * y / row,
page.trimbox[2] * (x + 1) / col,
page.trimbox[3] * (y + 1) / row))
result_name = Path('result', f'{name}_添加水印.pdf')
target.save(str(result_name))
运行以后,会在项目根目录生成一个result文件夹,里面就是添加了水印的PDF文件了,如下图所示:

这里有必要对代码中的一些地方进行解释。带上行号的代码如下图所示:
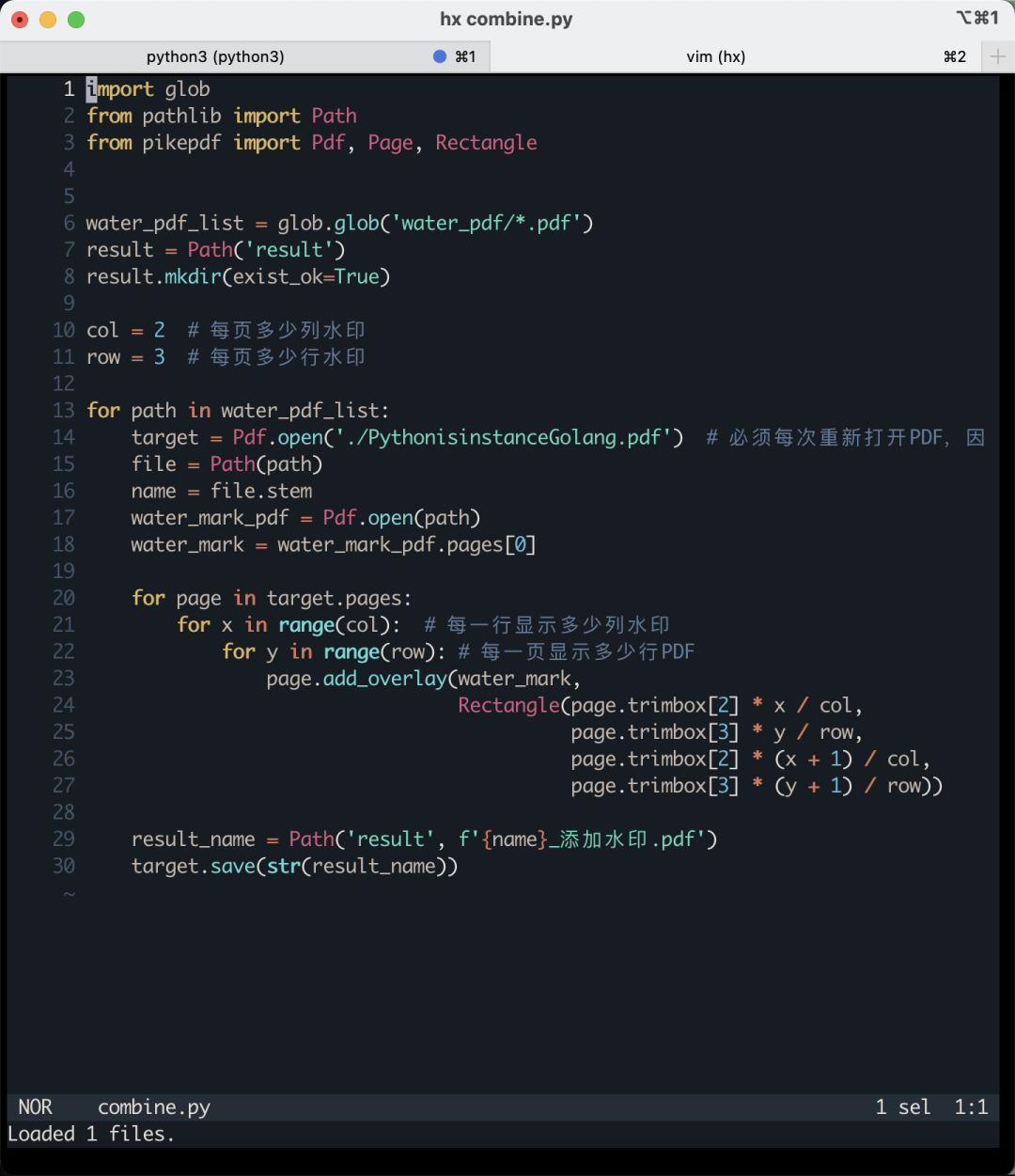
代码第21行和22行,有两个for循环,他们的作用是给一个页面上添加多个水印。请大家注意下图我画圈的地方:

每一页都有6个水印,分成3行2列。其中的3行对应了变量row的值。2列对应了变量col的值。大家也可以根据自己的需要修改这两个数字。甚至每一页的水印随机变换位置,防止被去水印的程序移除。
page.trimbox[2]是PDF页面的宽度,page.trimbox[3]是PDF页面的高度。
总结
大家注意在这篇文章中,我把任务分成了3个部分,分别是:
Excel转CSV,让Python方便读取 Python读取CSV生成水印PDF 水印PDF与目标PDF文件合并
这三个部分的代码是可以合并在一个.py文件里面的,但是我没有这样做,是考虑到问这个问题的同学不是程序员,Python水平只是入门,如果合并在一起,代码量多了以后,出问题都不知道错在哪里。
在计算机领域,所有问题都可以通过把问题拆分成多个部分分别单独运行或者增加若干个中间层来解决。今天用的方法就是把问题拆分的方法。对于初学者来说,每一步都是相对独立的,都能立刻看到效果。第二步只需要依赖第一步的结果,第三步只需要依赖第二步的结果,这样每一步的输入输出非常清楚,可以显著降低问题的复杂度。如果报错了,也更容易知道是哪个地方有问题。
END

