
如何打造一个大模型生成的数据目录?
今年以来,自己一直在做大模型应用方面的思考,在“智典”应用落地之际,今天就来跟大家分享一下我们在数据目录元数据自动生成方面的探索和实践。

高质量的数据目录是企业高效开发利用数据的基础。经过多年构建的数据治理体系,我们的企业级数据目录已经建立起来。该目录自底向上包含三个层次:数据资源目录、数据资产目录和数据开放目录,各层都对应于数据处理生命周期的不同阶段,纳管的数据资源已经超过2万项。
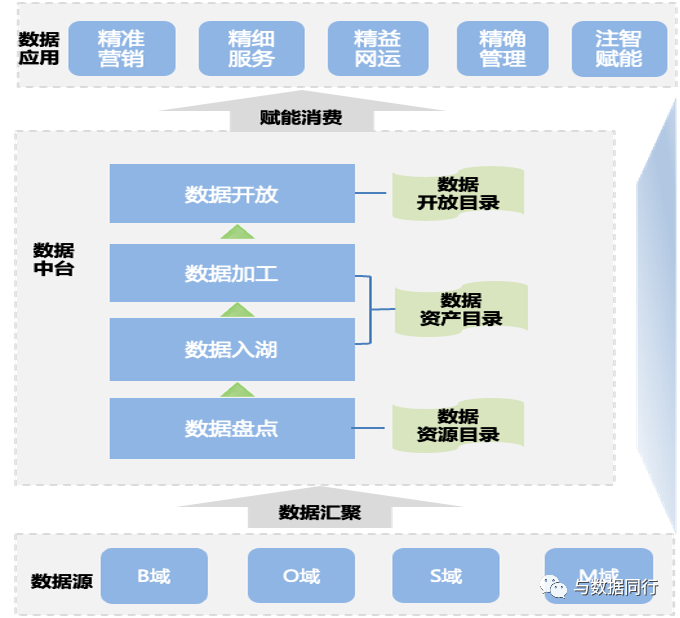
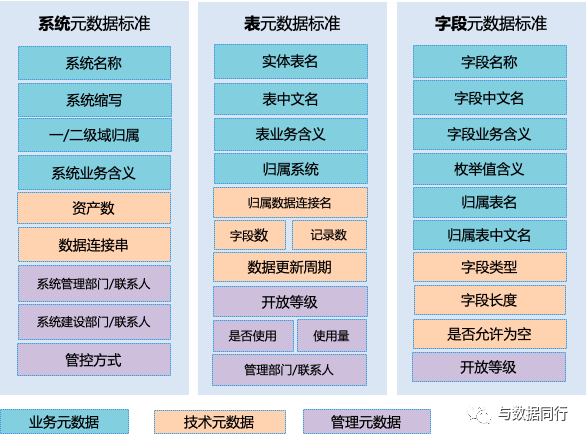
为了确保数据目录的完整性,设计了40+的标准属性:
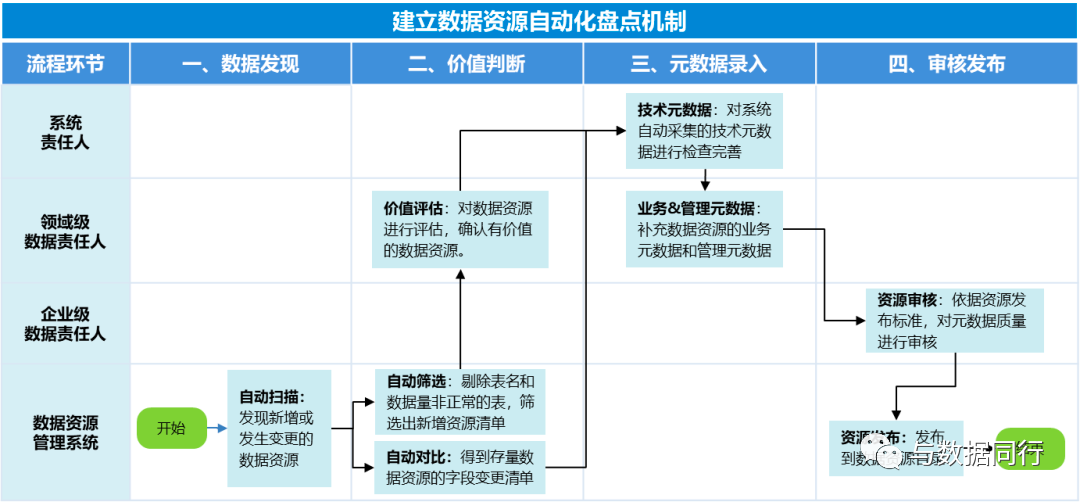
围绕企业数据目录,建立起了一套数据目录的闭环管理流程,当前盘点数据的周期已经实现按天自动动态更新,月变更数据超过1000项:
应该来讲,我们已经实现了企业数据目录的从0到1,但随着运营的逐步深入,当前面临着三个方面的挑战:
首先,企业级数据目录覆盖了B/O/M/S四大领域,可是各个领域的数据管理水平参差不齐,源端提供的数据目录的元数据信息缺失严重,而且质量不高,数据目录的完整率仅为10%,字段级的元数据信息准确率不到70%,业务人员看不懂的现象普遍存在,运维人员的咨询服务量大幅增加,制约着企业数据目录价值的发挥。
其次,要维护好企业级数据目录的元数据,需要掌握大量跨领域的专业知识,但我们数据运营团队当前并不具备这个条件。尽管依托于企业级数据治理组织、机制和流程,与其他领域建立了良好的合作关系,但沟通成本还是很高的。特别是当很多知识还掌握在第三方合作伙伴手中时,这个问题更加凸显。
最后,我们采取了多种措施来完善数据目录,包括组织各领域的专家来补充信息,还尝试用众包的方式来吸收公众的智慧。但是,这些方法很依赖于专家们的时间和投入,因此成本非常高。我们估计,要完善数万条数据目录信息,需要数万人天的工作量,并且需要持续的努力。这种方法不仅现实性不高,而且人工维护的数据质量也很难得到保证。
从我的经验看,维护元数据有三种模式:
第一种,后向维护,即等到数据资源开发完成后再补充元数据信息。这种方法不会太干扰正常的生产流程,但代价很大,因为它需要在工作完成后回过头来补充信息,这既费力又难以长期坚持。
第二种,前向录入,即在数据资源开发过程中就开始录入元数据信息。虽然这种方法能从一开始就保证元数据的存在,但它可能会严重拖慢业务流程,因为它要求开发人员在忙于上线产品的同时,还得分心去处理元数据。这几乎没有成功案例,而且即便可行,元数据的质量也很难得到保证。
第三种,自动生成,即尝试自动生成元数据,比如通过代码解析等技术。这听起来很理想,但实际上要求很高,而且很难做到准确和全面,大多数尝试都以失败告终。
我的经验告诉我,维护元数据这种对业务价值间接的工作,必须要考虑性价比。大模型出来后,大家立即想到了基于大模型的能力来完善数据目录的元数据信息的低成本的解决方案,其优势体现在三个方面:
1、打破领域知识壁垒
尽管我们对业务数据有很好的了解,但我们对网络数据(比如接入网、传输网、核心网)的了解就不够全面。幸运的是,大型语言模型擅长处理这种全球通用的知识,这可以帮助我们填补知识上的空白。这是“智典”成功的关键。
2、用通俗的语言诠释
哪怕我们对业务数据再熟悉,如果团队成员无法用简单明了的语言来描述数据,那么元数据就可能会变得模糊不清。大型语言模型能够使用简单、精确并且容易理解的方式来表达专业知识。只需给它足够的上下文信息,它就能生成清晰的摘要。
3、数据目录的自动化
前期我们在数据目录的运营上花费了大量的精力,每次扫描到新的数据资源,不仅要进行元数据信息的补录,还需要业务人员的和管理人员的审核,整个确认流程非常长,人工的大量介入让数据一键入湖的目标迟迟无法实现。
我的目标是让数据自动入湖,不需要人工干预,并且保证数据目录的质量。如果我们能开发出一个基于大模型的元数据生成API,并将其集成到流程中,我们就能实现这个目标。
下面就谈谈具体的做法。
1、选模型
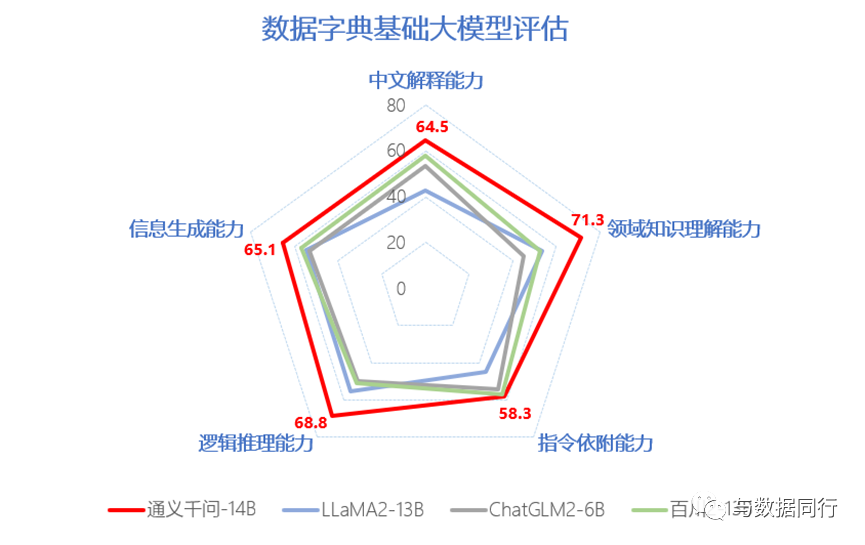
基础大模型的能力决定了“智典”的成败,我们的大模型需要私有化部署,又不可能自己去研发基础大模型,因此前期只能选择开源的方案。而每种开源的基础大模型的能力也是不同的,必须基于特定场景自己去做测试,比如LLAMA2-13B虽然推理能力还可以,但中文能力太差。
因此,我们制定了一个针对数据目录元数据生成的基础大模型的测试方法,从中文理解能力、领域知识理解能力、逻辑推理能力等五个维度出发,对模型的输出结果进行专家打分,选出最佳模型。最终选择了表现最为出色的通义千问模型作为基底大模型,下面是测试结果的示意:
2、备指令
由于企业数据目录涉及公司大量的领域知识,同时对格式等输出也有特定要求,因此我们还是需要在通义千问的基础上进行一定的微调,这就需要建立训练的指令集。我们梳理了存量的数据目录元数据信息、设计了提示词模板,构建了一个拥有6000余条规范化问答结构

3、做训练
基于通义千问大模型,同时使用LORA算法对指令数据集进行大模型微调训练,我们构建出了一个自动生成数据目录元数据信息的领域大模型。该过程的核心是通过冻结基底大模型的权重参数,在基底模型中追加并训练额外的神经网络,以达到注入领域知识和训练模型服从人工指令的目的。
为验证“智典”生成的字典信息准确性,我们随机选择各领域的430张表,并邀请业务专家进行人工审核。经验证,其准确率高达97%,在这个场景,大模型生成的内容质量可以达标。
以网络侧某无线资源表为例,该表的中文名称、字段的中文名称以及业务含义等数据字典信息,均由“智典”自动生成。相较于原始的字典信息,通过“智典”生成的内容语义更加准确,表达更加流畅,也更容易被使用人员理解,如下所示:

4、做推理
最后就是具体的部署了,我们采取CVL模式快速构建了数据目录元数据信息的自动生成服务。该服务通过数据处理、信息检索以及调用大模型推理等流程,能够智能、准确地生成元数据信息,将元数据信息补全的平均耗时由天缩短至秒级,信息准确率达到95%以上,下图示例了整个推理过程:
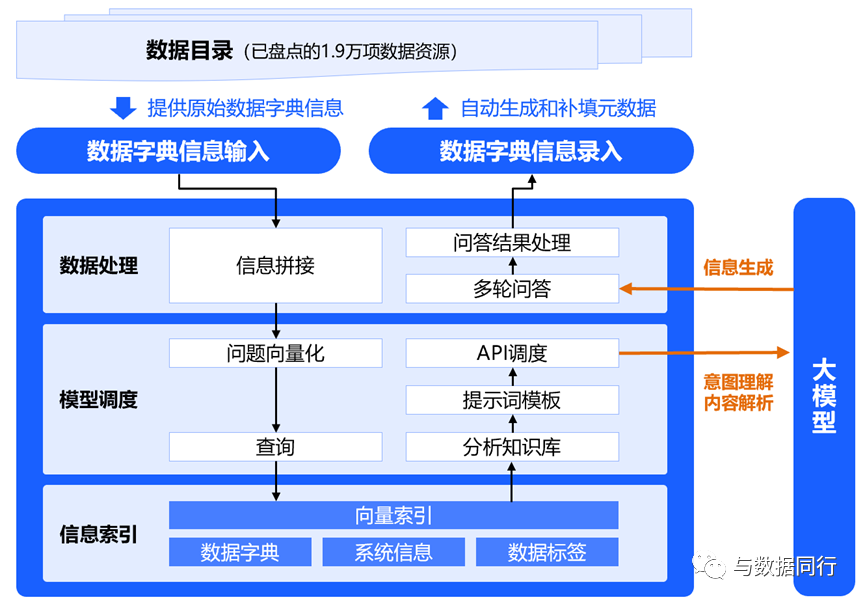
5、嵌流程
我们将推理能力封装成了一个API,替换了前面数据目录的闭环管理流程的元数据人工录入环节。我们保留了人工快速审核的环节,因为大模型生成会产生一定的错误,比如无法基于拼音进行准确的推理,审核人员需要保留这些错误的信息,作为下次调优的依据。
有了大模型的加持,企业数据目录的可用性得到了很大的提升,体现在三个方面:
第一,数据目录元数据信息的质量上了一个档次,专业人员的评估是:大模型生成的元数据质量不低于手工维护的水平。
第二、我们也降本增效了,裁撤了ETL团队,大家能把精力更多的投入到业务赋能中去。
第三,响应能力提升了,数据资源纳管的周期已经缩短至小时级。
“智典”是我们在数据领域做成的第一个比较成功的大模型应用,但仍然面临着诸多挑战:
第一,“智典”的生成只是第一步,“智典”的运营才是关键,我们需要将“智典”推送到需要它的地方,包括需求分析、数据开发及数据开放的场景,不能自嗨。
第二、“智典”在做推理的时候,输入的上下文信息并不完备,比如基本上是根据原始表名,字段名来做推理,这限制了内容的生成能力,实际上更多的上下文信息是藏在数据中的,而要生成这些上下文信息挑战巨大。
第三、“智典”只是对实体信息进行了业务描述,缺乏相互关系和血缘的描述,使用的场景还是非常受限的。可以这么说,这还是一个缺乏深度和内涵的数据目录,后续会考虑基于大模型去解析代码来生成更多的元数据。
第四、“智典”的目录分类是以系统为基础,大家通过“智典”看到的是流程割裂的业务数据,对业务人员并不友好,而要改善这一点,就涉及到业务对象管理等更为挑战性的工作。
李彦宏说,大模型值得企业把所有的应用都重构一遍,我对这个方向深信不疑。但也知道现在企业要做成一个成功的大模型应用不易,因为其对场景和技术的要求极度苛刻,特别是当前国内基础大模型的能力还不够,只能在一些对准确性要求不高的场景进行尝试,十分之一的成功率估计也没有吧。
但我们还是要努力去做出尝试,也期待国内基础大模型的进步。
(欢迎大家加入数据工匠知识星球获取更多资讯。)

扫描二维码关注我们
我们的使命:发展数据治理行业、普及数据治理知识、改变企业数据管理现状、提高企业数据质量、推动企业走进大数据时代。
我们的愿景:打造数据治理专家、数据治理平台、数据治理生态圈。
我们的价值观:凝聚行业力量、打造数据治理全链条平台、改变数据治理生态圈。
了解更多精彩内容
长按,识别二维码,关注我们吧!
数据工匠俱乐部
微信号:zgsjgjjlb
专注数据治理,推动大数据发展。