
基于C#.NET的高端智能化网络爬虫
本篇故事的起因是携程旅游网的一位技术经理,豪言壮举的扬言要通过他的超高智商,完美碾压爬虫开发人员,作为一个业余的爬虫开发爱好者,这样的言论我当然不能置之不理。

有人评论我上一篇的简单爬虫:代码太过简单以至于弱爆了,真是被这群有文化的孩子给雷到了!不得不猜测你是不是携程网的托儿,我还没写完你咋就知道弱爆了?看来不下点猛料你是得不到满足啊!

今天我们就来学习高级爬虫的开发,同时我们还要利用之前的简单爬虫程序,来实现分布式爬虫的Links Master部分,以提高分布式抓取的效率。
下边的我们要讲的内容,涉及了众多开源软件。先别太紧张,越是高级的东西通常都封装的越好,只要放开心态综合运用就行了,我先假设你对下边这些工具都有过了解:
RabbitMQ:用于分布式消息传递。
Shadowsocks:用于代理加密。
PhantomJS:用于Web页面渲染。
Selenium:用于Web自动化控制。
一、什么是高级爬虫?
我们长谈到的高级爬虫,通常是说它具有浏览器的运行特征,需要第三方的类库或工具的支持,比如说以下这些常见的东东:
Webkit
WebBrowser
PhantomJS + Selenium
很多人都觉得,分布式爬虫才能算是高级的爬虫。这绝对是一种错误的理解,分布式只是我们实现爬虫架构的一种手段,而并非是用来定义它高级的因素。

我们之所以称它们为高级爬虫组件,主要是因为他们不但可以直接抓取网页源代码,同时还能能渲染网站页面的HTML、CSS、Javascript等内容。
这样的功能,对于开发爬虫到底有什么好处呢?说起这好处那是有点谦虚了,丝毫不夸张的说:这玩意简直可以称为“爬无敌”!!!

我猜你还是这个表情,因为它的强大机制,让我们可以直接在网站页面:执行Javascript代码、触发各类鼠标键盘事件、操纵页面Dom结构、利用XPath语法抓取数据,几乎可以做一切在浏览器上能做的事情。

很多网站都用Ajax动态加载、翻页,比如携程网的评论数据。如果是用之前那个简单的爬虫,是很难直接抓取到所有评论数据的,我们需要去分析那漫天的Javascript代码寻找API数据接口,还要时刻提防对方增加数据陷阱或修改API接口地。
如果通过高级爬虫,就可以完全无视这些问题,无论他们如何加密Javascript代码来隐藏API接口,最终的数据都必要呈现在网站页面上的Dom结构中,不然普通用户也就没法看到了。所以我们可以完全不分析API数据接口,直接从Dom中提取数据,甚至都不需要写那复杂的正则表达式。

二、如何开发一款高级爬虫?
现在我们就来一步一步实现这个高级爬虫,接下来就用目前潮到爆的两个组件,来完成一个有基本功能的高级爬虫,首先我们去下载开源组件:

PhantomJS:算是一个没有UI界面的浏览器,主要用来实现页面自动化测试,我们则利用它的页面解析功能,执行网站内容的抓取。下载解压后将Bin文件夹中的phantomjs.exe文件复制到你爬虫项目下的任意文件夹,我们只需要这个。
下载地址:http://phantomjs.org/download.html

Selenium:是一个自动化测试工具,封装了很多WebDriver用于跟浏览器内核通讯,我用开发语言来调用它实现PhantomJS的自动化操作。它的下载页面里有很多东西,我们只需要Selenium Client,它支持了很多语言(C#、JAVA、Ruby、Python、NodeJS),按自己所学语言下载即可。
下载地址:http://docs.seleniumhq.org/download/
这里我我下载C#语言客户端,将这4个DLL文件都添加到项目引用中,其他语言开发者请自行寻找方法,然后开始我们的编码之旅。
老规矩,打开Visual Studio 2015 新建一个控制台应用程序,增加一个简单的StrongCrawler类,由于这两个爬虫类具有公共部分,本着DRY的原则,需要对部分代码重构,我们先提取一个ICrawler接口:

然后我们用StrongCrawler类来实现这个接口:

接着我们来编写它的异步爬虫方法:

好了,这个高级爬虫的基本功能就定义完成了,还是用携程的酒店数据作为抓取的例子,我们测试一下抓取(酒店名称、地址、评分、价格、评论数量、评论当前页码、评论下一页码、评论总页数、每页评论数量)等详细数据试试。我们现在用控制台程序来调用一下:
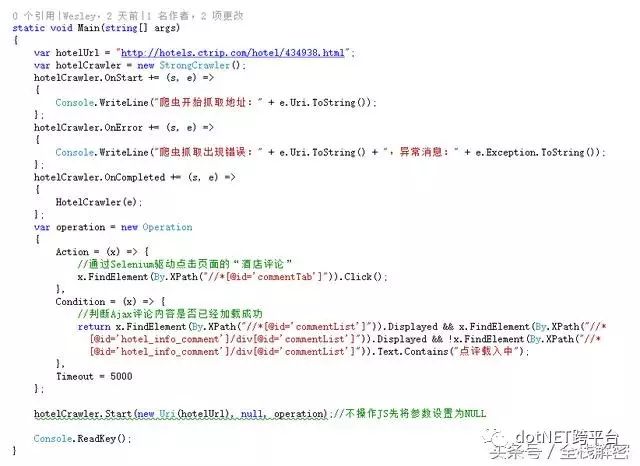
由上图可知,等待酒店页面加载完成后,我们通过XPath语法查找页面元素,首先点击了页面上的“酒店评论”按钮,再等待页面的Dom结构发生变化,也就是说等待Ajax加载成功,然后对需要的数据进行抓取。看看代码的执行结果:
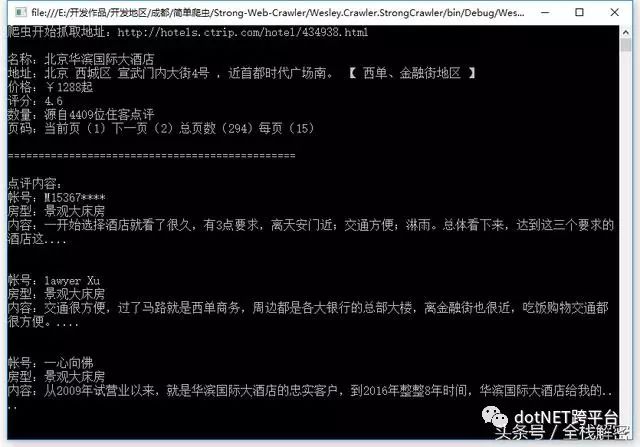
我们很轻松的抓取到了酒店的信息,以及酒店的第一页全部评论数据。因为携程网的评论数据是通过Ajax翻页的,因此要想抓取所有评论,还抓取了评论的页码等数据。再看看执行性能:
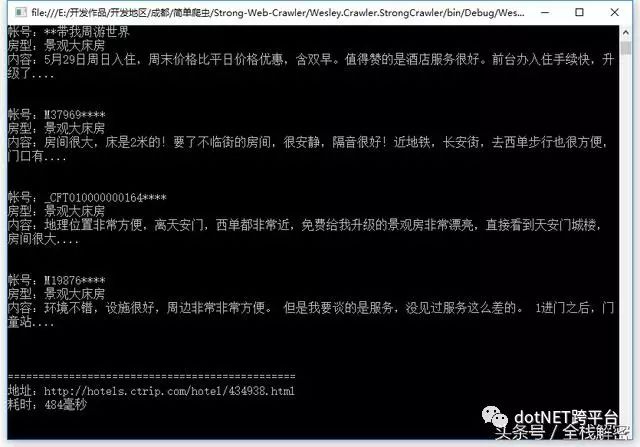
还算不错,484毫秒,可以说在所有高级爬虫组件中,PhantomJS的效率应该是最高的了,几乎没有其他组件可以直接与之抗衡。有了页码数据,我们就可以对评论进行执行翻页抓取操作,以这个速度,抓取几百页的评论数据根本不需要搞分布式。
三、如何实现分布式?
分布式爬虫通常使用消息队列来实现,目前互联网上的开源消息队列非常多,今天我们就来介绍一款非常拉风的分布式消息队列开源组件:

RabbitMQ是一个开源的AMQP实现,服务器端用Erlang语言编写,支持多种客户端,如:.NET、Python、Ruby、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX。用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现都非常好。
下载地址:
http://www.rabbitmq.com/download.html
分布式爬虫通常需要两个端:
控制端
爬虫端
控制端主要负责控制爬虫运行、监控爬虫状态、配置爬虫抓取方式等。爬虫端主的功能就是抓取数据并将数据提交给数据清洗服务。
爬虫端还需要分出Master爬虫及Worker爬虫,Master爬虫主要利用简单爬虫的运行方式实现高性能的超连接(Links)的抓取。Worker爬虫则利用高级爬虫特性来采集精细化的数据,例如Ajax加载的内容。把最擅长的事情交给最合适的爬虫来做。
聪明的你应该想到了,他们之间的沟通方式就是消息队列。Master爬虫只需要将抓取的Links扔进数据抓取队列。Worker爬虫通过定时拉去队列中的Links来实现数据抓取,抓取完成后将数据再提交至数据清洗队列。
原理应该都讲清楚了吧?那就自己实现代码吧,RabbitMQ官网上都有示例代码,我就不再这里啰嗦了。
四、如何实现稳定的加密代理?
在这个互联网时代,免费的东西基本上快消失殆尽了,就算有也肯定很垃圾。所以今天我要讲的Shadowsocks,也是一个需要付少量费用的东西,这个东西的强大之处,就在于其流量特征不明显,可以非常稳定的提供上网代理。

下载地址:https://github.com/shadowsocks
Shadowsocks客户端会在本地开启一个socks5代理,通过此代理的网络访问请求由客户端发送至服务端,服务端发出请求,收到响应数据后再发回客户端。中间通过了AES-256来加密传输数据,因此要必普通的代理服务器安全得多,我们来看看它的运行方式:
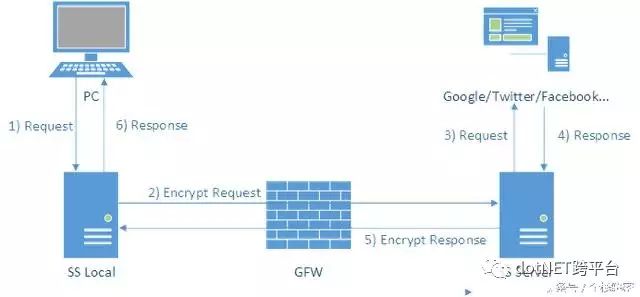
由图得知,它需要先在本地运行客户端程序,连接远程代理服务器的服务端程序实现加密通讯。再在本地模拟代理端口,让本机流量先经过本地客户端加密,然后再传输至远程服务端,完成代理的转发服务。
因此我们只需要买一台基于Linux的VPS服务器,成本大约在15元人民币每月,安装好服务端后,就可以实现一个非常稳定的加密代理服务。相关教材网上一大堆,我也就不再这里啰嗦。
五、结束语
迫于一些压力,我就不在这里公布详细的爬虫源代码了,看上面的例子肯定能自己完成一个更强大的高级爬虫。全部源代码下载:https://github.com/coldicelion/Simple-Web-Crawler
原文地址:http://www.toutiao.com/i6304492725462893058/
回复 【关闭】学关闭微信朋友圈广告 回复 【实战】获取20套实战源码 回复 【被删】学查看你哪个好友删除了你巧 回复 【访客】学微信查看朋友圈访客记录 回复 【小程序】学获取15套【入门+实战+赚钱】小程序源码 回复 【python】学微获取全套0基础Python知识手册 回复 【2019】获取2019 .NET 开发者峰会资料PPT 回复 【加群】加入dotnet微信交流群 微信终于可以免费提现了!

