
清华张钹院士:迈向第三代人工智能
极市平台
共 22132字,需浏览 45分钟
·
2020-10-22 03:40

极市导读
清华大学人工智能研究院院长张钹教授认为,第三代AI需要结合前两代的知识驱动和数据驱动,利用好知识、数据、算法和算力等4个要素,从而使AI更强大。>>加入极市CV技术交流群,走在计算机视觉的最前沿

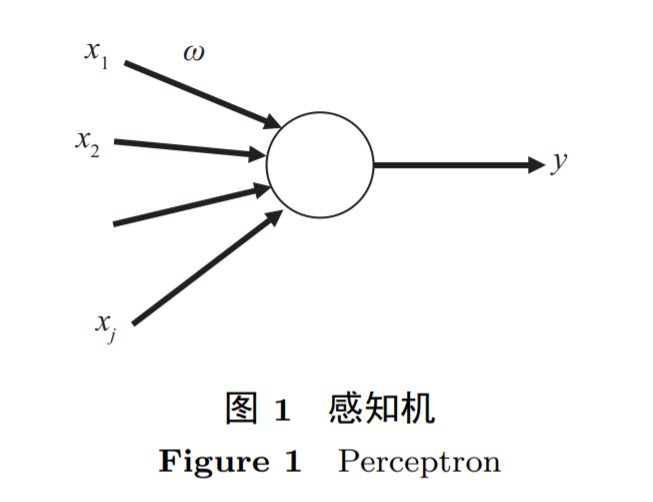
1 第一代人工智能
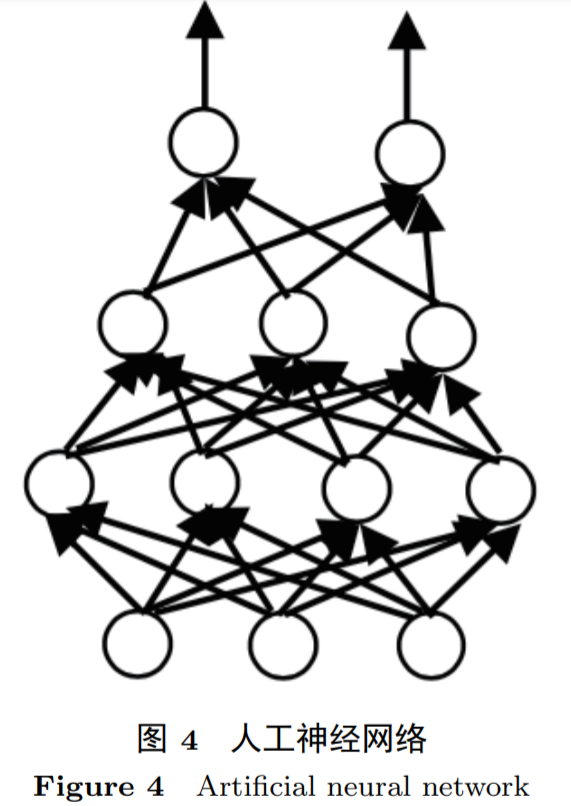
2 第二代人工智能

 ,对样本所反映的输入–输出关系 f:X→Y 做出估计,即从备选函数族(假设空间)F={fθ:X−→Y;θ∈A}中选出一个函数 f^∗使它平均逼近于真实 f。在深度学习中这个备选函数族由深度神经网络表示:
,对样本所反映的输入–输出关系 f:X→Y 做出估计,即从备选函数族(假设空间)F={fθ:X−→Y;θ∈A}中选出一个函数 f^∗使它平均逼近于真实 f。在深度学习中这个备选函数族由深度神经网络表示:
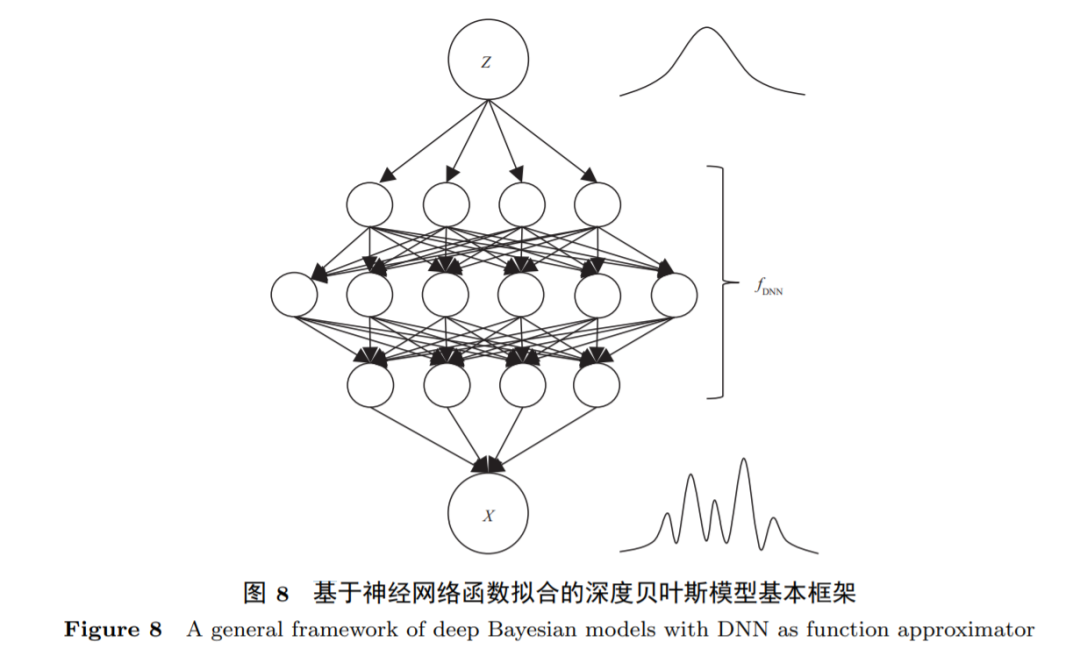
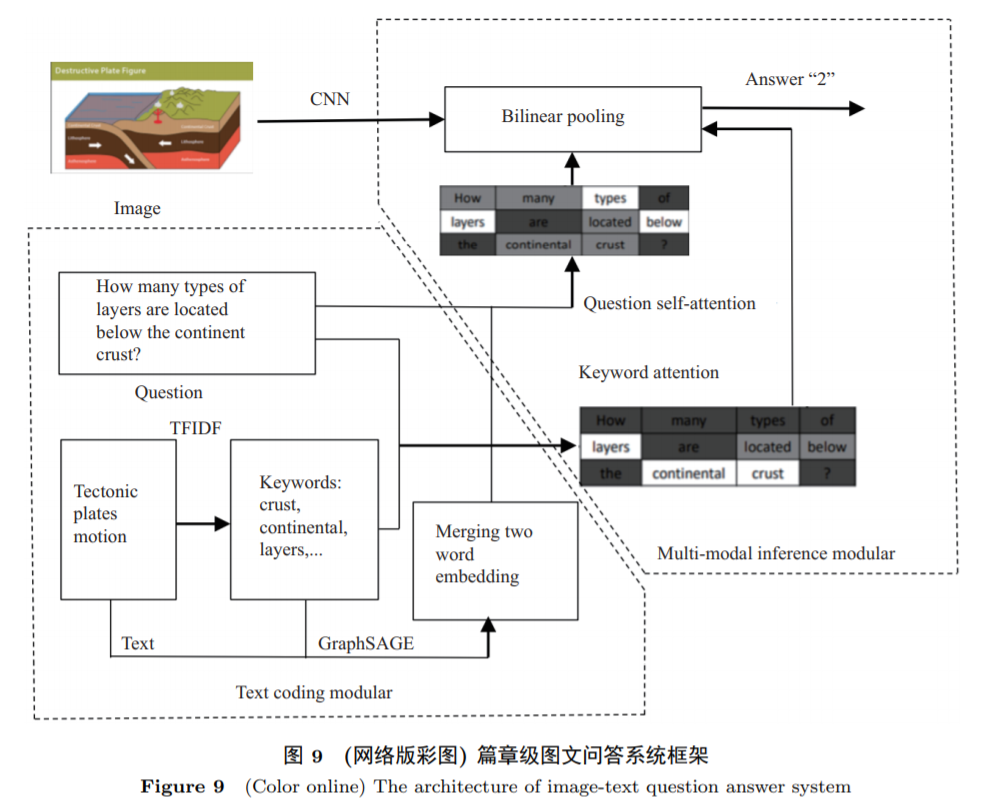
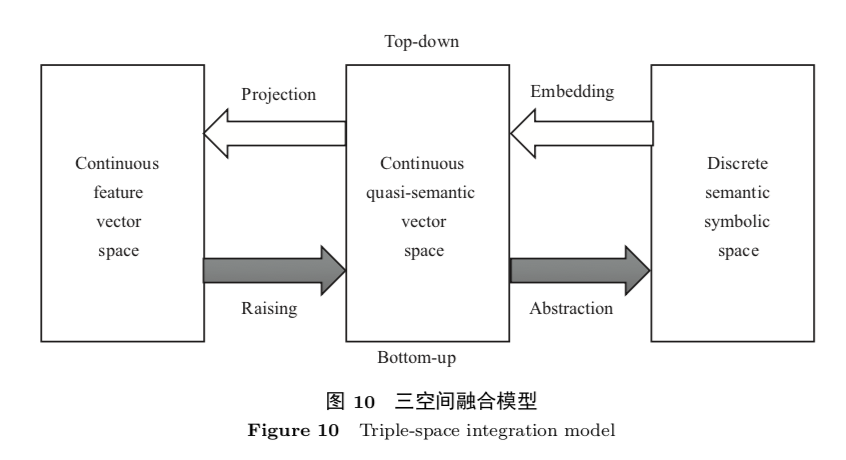
3 第三代人工智能
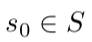 出发,取得起始观察值
出发,取得起始观察值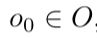 ,在 t 时刻,智能体根据其内部的推理机制采取行动
,在 t 时刻,智能体根据其内部的推理机制采取行动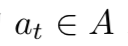 之后,获得回报
之后,获得回报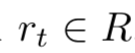 ,并转移到下一个状态
,并转移到下一个状态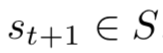 ,得到新的观察
,得到新的观察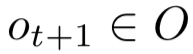 。强化学习的目标是,选择策略π(s,a)使累计回报预期 V^π(s):S→R 最优。如果我们考虑简单的马尔可夫(Markov)决策过程,即后一个状态仅取决于前一个状态,并且环境完全可观察,即观察值 o 等于状态值 s,即 O=S; 并假设策略稳定不变。如图 5 所示。以 AlphaZero 为例,智能体不依赖人类的标注数据,仅仅通过自我博弈式的环境交互积累数据,实现自身策略的不断改进,最终在围棋任务上达到了超越人类顶级大师的水平,代表强化学习算法的一个巨大进步[45]。
。强化学习的目标是,选择策略π(s,a)使累计回报预期 V^π(s):S→R 最优。如果我们考虑简单的马尔可夫(Markov)决策过程,即后一个状态仅取决于前一个状态,并且环境完全可观察,即观察值 o 等于状态值 s,即 O=S; 并假设策略稳定不变。如图 5 所示。以 AlphaZero 为例,智能体不依赖人类的标注数据,仅仅通过自我博弈式的环境交互积累数据,实现自身策略的不断改进,最终在围棋任务上达到了超越人类顶级大师的水平,代表强化学习算法的一个巨大进步[45]。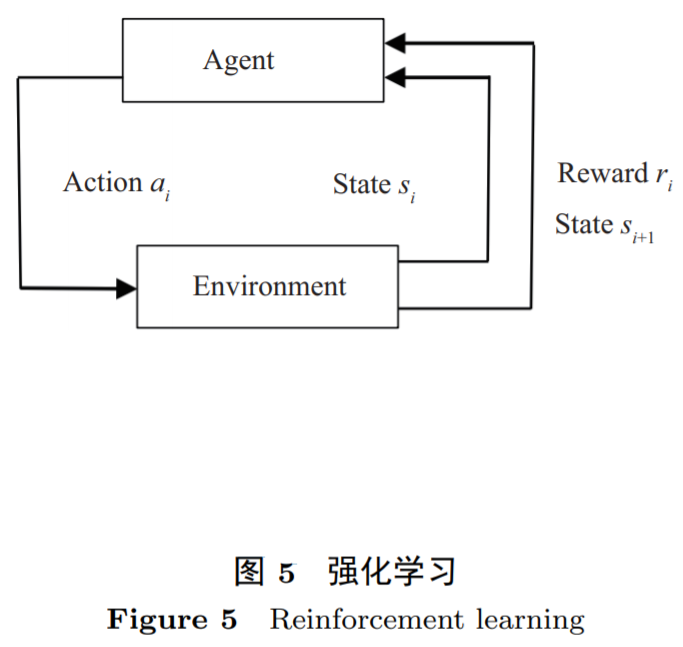

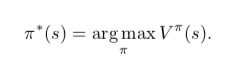

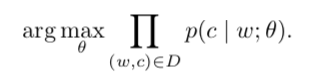
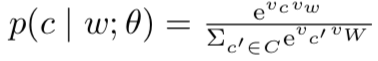
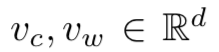 是词 c 和词 w 的向量表示,C 是所有可用文本。参数。
是词 c 和词 w 的向量表示,C 是所有可用文本。参数。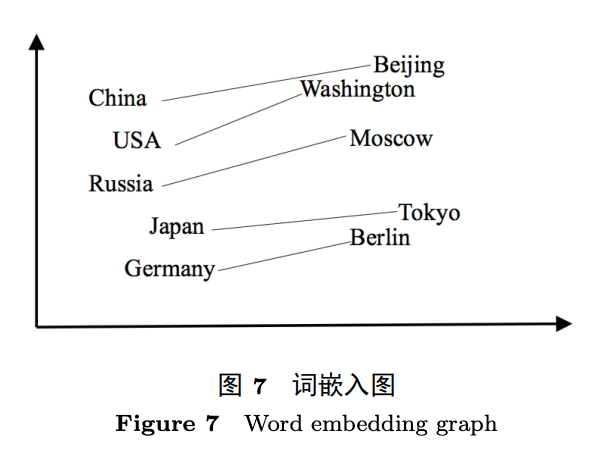
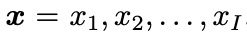 ,寻找目标句(比如英文)
,寻找目标句(比如英文)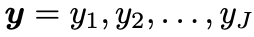 。神经翻译的任务是,计算词一级翻译概率的乘积,
。神经翻译的任务是,计算词一级翻译概率的乘积,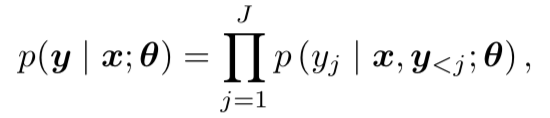
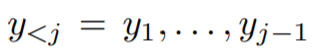 是部分翻译结果。词一级的翻译概率可用 softmax 函数 f(·)定义:
是部分翻译结果。词一级的翻译概率可用 softmax 函数 f(·)定义: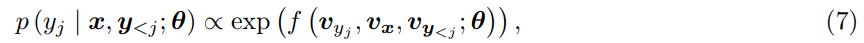
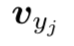 是目标句中第 j 个词的向量表示,v_x 是源句子的向量表示,
是目标句中第 j 个词的向量表示,v_x 是源句子的向量表示,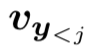 是部分翻译句的向量表示,y=y_j,j=1,2...,J 是要找的目标句。
是部分翻译句的向量表示,y=y_j,j=1,2...,J 是要找的目标句。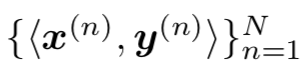 ,模型训练的目标是最大化 log 似然:
,模型训练的目标是最大化 log 似然: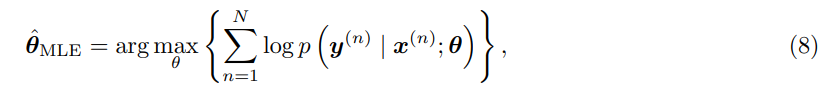
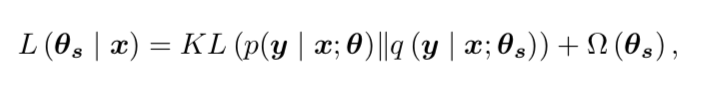
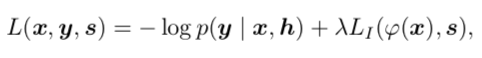
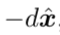 ,用对抗样本加上负噪声可以得到去噪图片
,用对抗样本加上负噪声可以得到去噪图片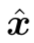 ,即
,即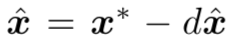 。研究表明该方法不仅去掉了一部分对抗扰动,还增加了一部分「反对抗扰动」,取得了非常好的防御效果,获得「NIPS2017 对抗性攻防竞赛」中对抗防御任务冠军,以及 2018 年在拉斯维加斯(LasVegas)举办的 CAADCTF 对抗样本邀请赛冠军。
。研究表明该方法不仅去掉了一部分对抗扰动,还增加了一部分「反对抗扰动」,取得了非常好的防御效果,获得「NIPS2017 对抗性攻防竞赛」中对抗防御任务冠军,以及 2018 年在拉斯维加斯(LasVegas)举办的 CAADCTF 对抗样本邀请赛冠军。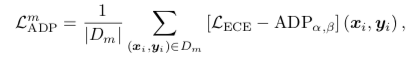
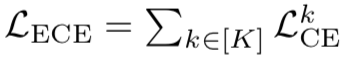 ;
;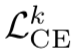 为每个子模型 k 的交叉熵(cross-entropy)损失函数。ADP_α,β(x,y)=α·H(F)+β·log(ED)是模型集成多样性的度量,鼓励不同的子模型形成尽量差异化的决策边界。实验结果表明,通过鼓励不同子模型的差异化决策性质,有效地提升了模型的对抗鲁棒性。但是,总体而言,目前多数的对抗防御方法是基于经验主义的,研究表明很多防御对抗样本的方法在很短的时间就会被后来的攻击算法攻破。其重要原因之一是深度学习只是在做简单的函数拟合,缺乏像人一样对问题的理解能力[67]。因此通过理解机器学习模型的内部工作机理,发展数据驱动和知识驱动融合的第三代人工智能理论框架,将成为提高人工智能算法鲁棒性的重要途径。
为每个子模型 k 的交叉熵(cross-entropy)损失函数。ADP_α,β(x,y)=α·H(F)+β·log(ED)是模型集成多样性的度量,鼓励不同的子模型形成尽量差异化的决策边界。实验结果表明,通过鼓励不同子模型的差异化决策性质,有效地提升了模型的对抗鲁棒性。但是,总体而言,目前多数的对抗防御方法是基于经验主义的,研究表明很多防御对抗样本的方法在很短的时间就会被后来的攻击算法攻破。其重要原因之一是深度学习只是在做简单的函数拟合,缺乏像人一样对问题的理解能力[67]。因此通过理解机器学习模型的内部工作机理,发展数据驱动和知识驱动融合的第三代人工智能理论框架,将成为提高人工智能算法鲁棒性的重要途径。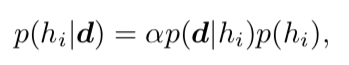
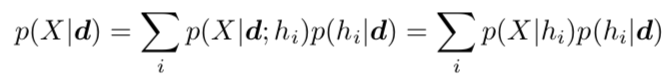
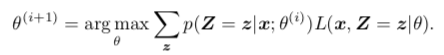
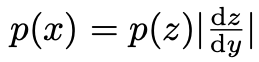
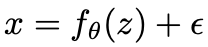
4 总结





推荐阅读
ACCV 2020国际细粒度网络图像识别竞赛正式开赛!

评论
张钹院士:从人工智能三要素走向四要素之路
来源:Datawhale 专知本文约7200字,建议阅读10分钟本文介绍了张钹院士讲解的从人工智能三要素走向四要素之路。2024年4月,中国科学院院士、清华大学计算机系教授、清华大学人工智能研究院名誉院长张钹,做客清华大学“人文清华讲坛”,以《走进“无人区”,探索人工智能之路》为题做了一场演讲。
数据派THU
1
张宏(科学院院士)
人物经历
张宏
1969年11月,张宏出生于安徽省黄山市。
1987年—1991年,本科就读于安徽大学,毕业获学士学位。
1991年—1994年,就读于北京大学医学部,毕业获硕士学位。
1994年—2001年,就读于美国爱因斯坦医学院,毕业获博士学位。
2001年—200
张宏(科学院院士)
0