
听声辨位,一个让我感到毛骨悚然的 GitHub 项目!
黑客与编程
共 3423字,需浏览 7分钟
·
2021-02-16 00:34
了解更多网络安全技术,
了解更多网络安全技术,
加入网络安全交流群!
不定期分享网安技术
扫码添加黑客小助手免费获取入群资格。
想必你永远不会想到,有一天你也会被自己的键盘出卖。
四步偷窥大法
一是,收集训练数据; 二是,搭建预测模型,学习一下数据; 三是,检测出有人在敲键盘; 四是,检测出 ta 在打什么字。
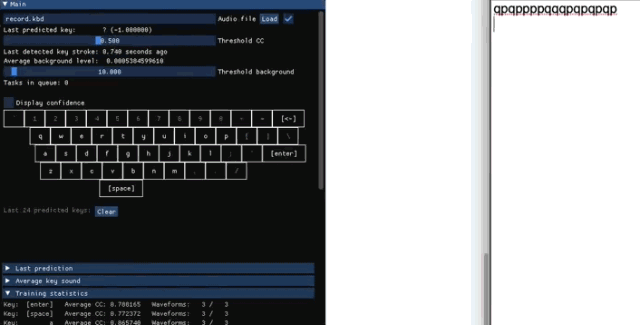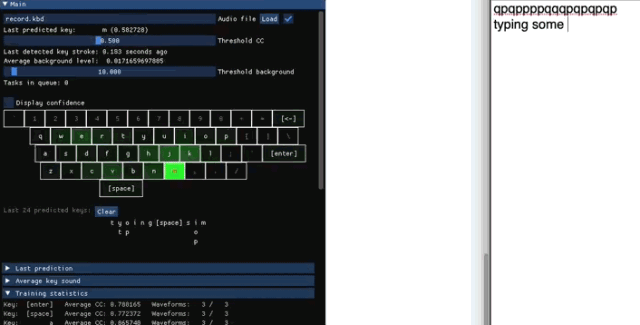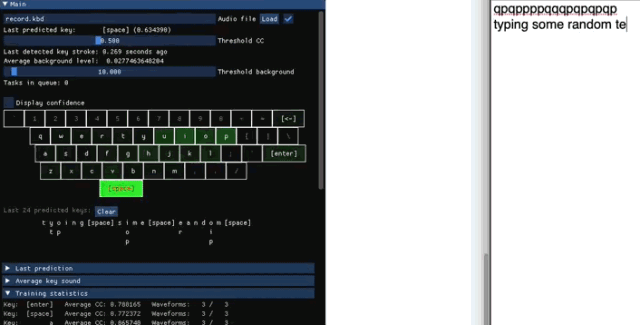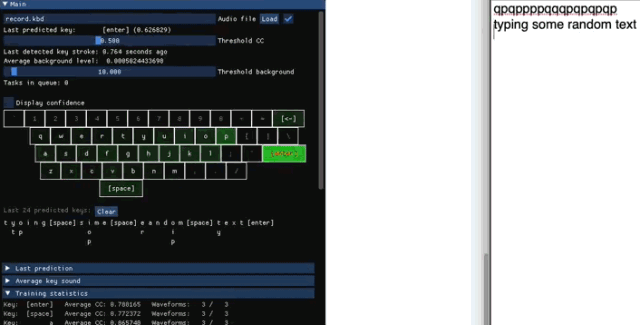
收集训练数据
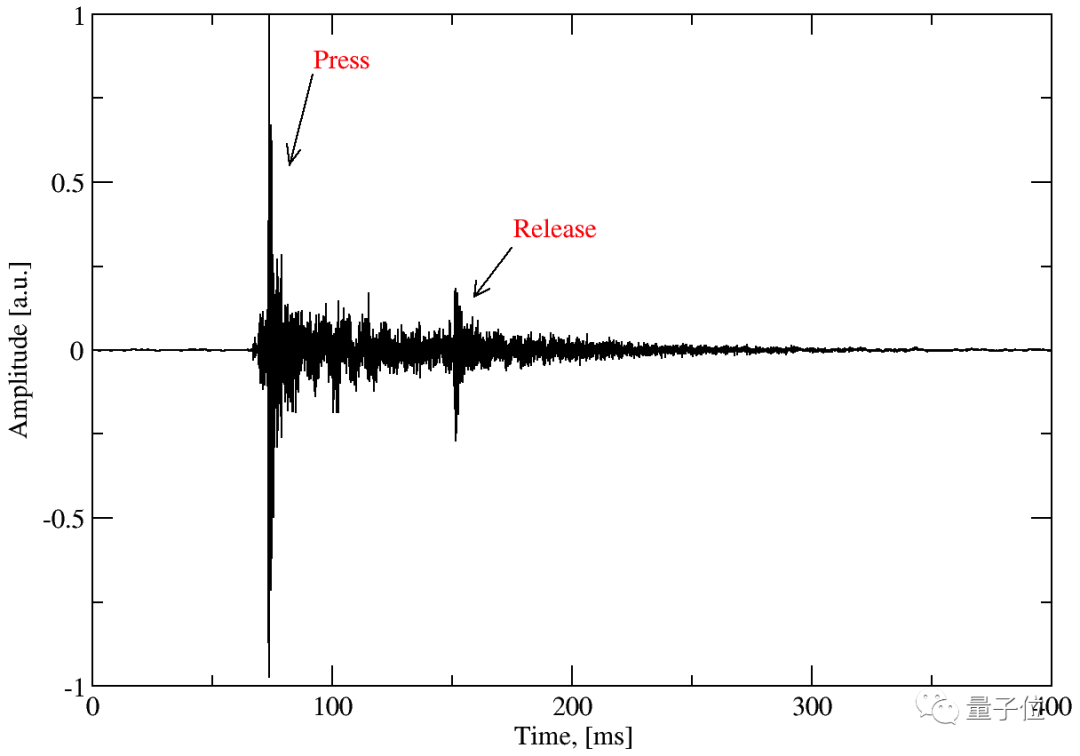
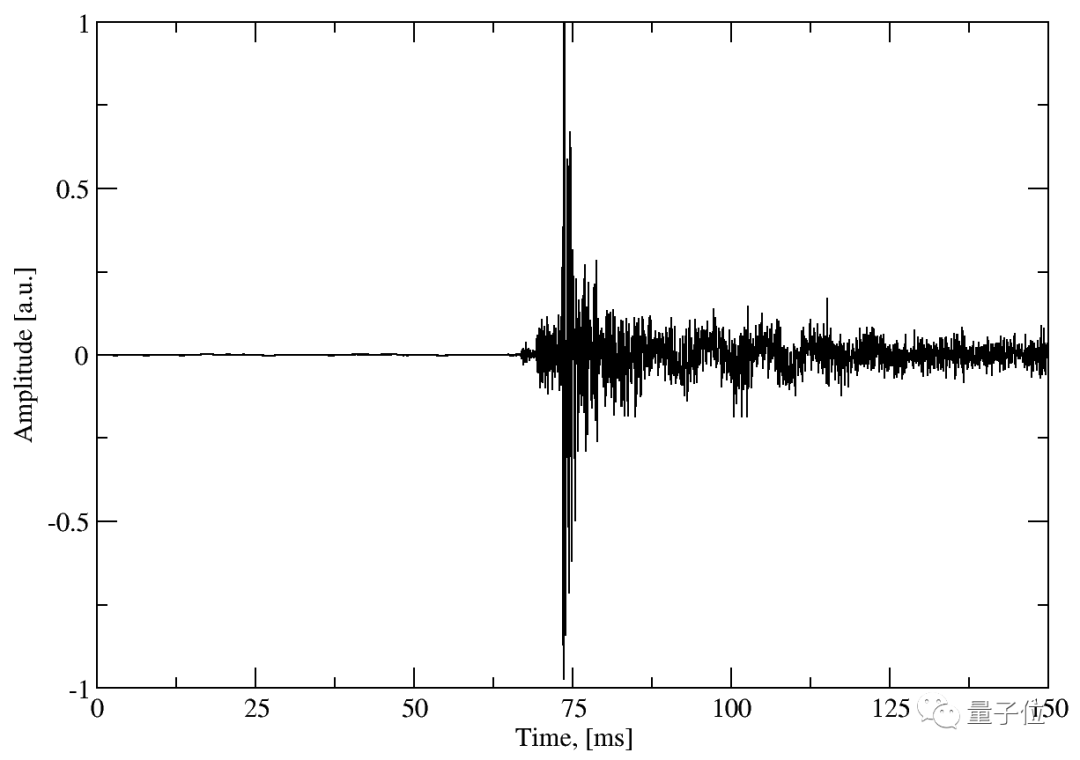
搭个预测模型
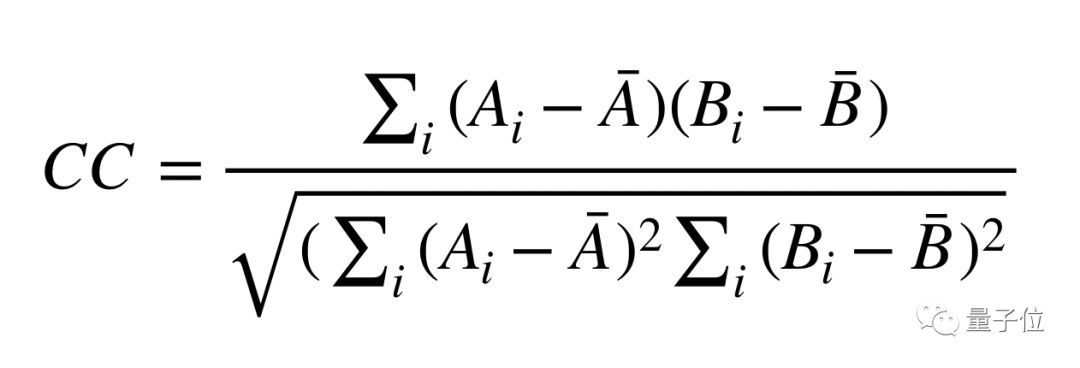
检测出在敲键盘
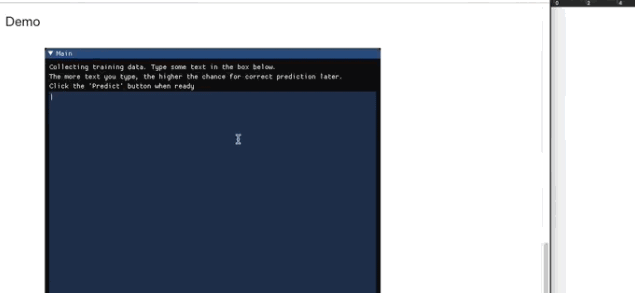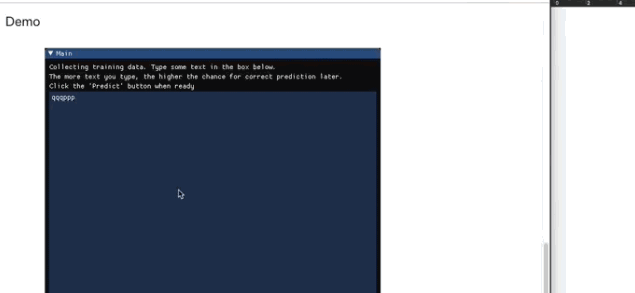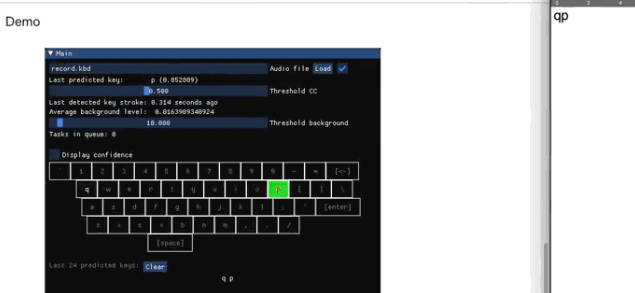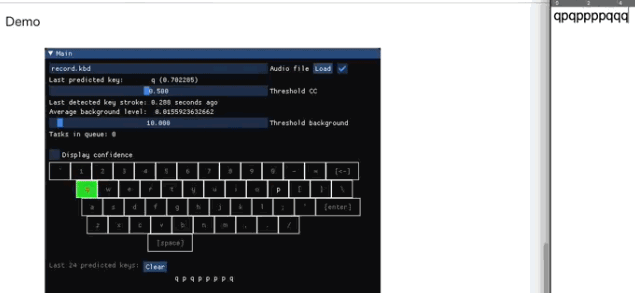
检测打了什么字
“薯片间谍”
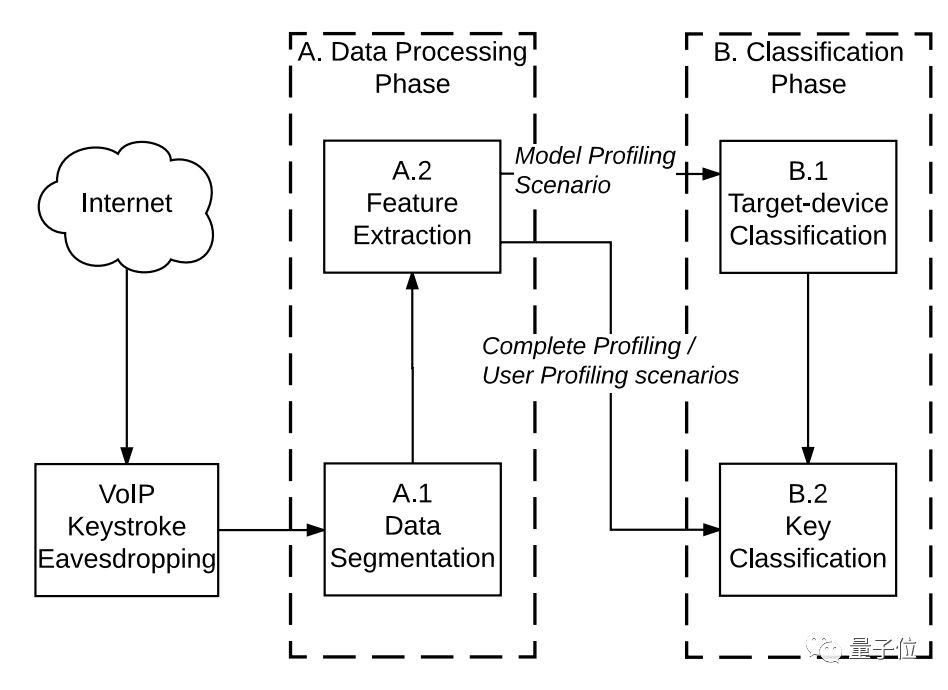


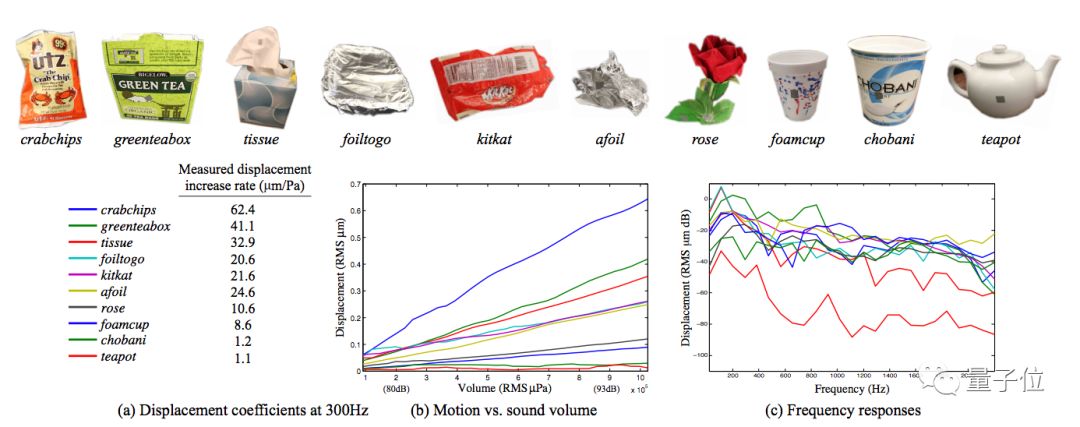
嘘,掩好口鼻,轻声撤退。
评论