
ViT攻陷检测,CNN还有多久被弃用?
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
ViTDet是Meta AI团队(kaiming团队)在MAE之后提出的基于原生ViT模型作为骨干网络的检测模型。在最早的论文中,作者初步研究了以ViT作为骨干网络的检测模型所面临的挑战(架构的不兼容,训练速度慢以及显存占用大等问题),并给出了具体的解决方案,最重要的是发现基于MAE的预训练模型展现了较强的下游任务迁移能力,效果大大超过随机初始化和有监督预训练模型。而最新的论文对上述工作做了进一步的拓展和优化,给出了性能更好的ViTDet,目前代码已经开源在detectron2的,这篇文章将主要结合第二篇论文和代码解读ViTDet。
模型设计
ViTDet选用Mask R-CNN架构作为主要研究对象,这里采用了优化版本,具体的改进主要包括以下几点:
RPN采用2个隐含的卷积层(默认是1个); ROI heads的box head由原来的2个全连接层变为4个卷积层+1个全连接层; ROI heads的box head和mask head的卷积层之间均采用LayerNorm(最早的版本是采用BatchNorm,但往往需要SyncBN,而LN则不受batch size的影响)。
model.roi_heads.box_head.conv_norm = model.roi_heads.mask_head.conv_norm = "LN"
# 2conv in RPN:
model.proposal_generator.head.conv_dims = [-1, -1]
# 4conv1fc box head
model.roi_heads.box_head.conv_dims = [256, 256, 256, 256]
model.roi_heads.box_head.fc_dims = [1024]
对于这个优化版本,采用较强的数据增强(large scale jittering,LSJ)和训练时长(100 epcohs),输入的图片大小为1024x1024,其中LSJ是谷歌在论文中提出的,如下图所示,相比标准的scale jittering,LSJ的resize range更大(0.1~2.0)。 采用ViT作为Mask R-CNN的骨干网络,首先是要解决的就是特征金字塔的问题。对于采用金字塔结构的CNN来说,可以通过提取它的1/4,1/8,1/16和1/32特征送入FPN来构建特征金字塔;但ViT采用同质架构,这使得ViT只能得到一种尺度(1/16)的特征。为了解决这个问题,论文提出了一种简单的方法来从ViT中构建特征金字塔,如下图右所示:
采用ViT作为Mask R-CNN的骨干网络,首先是要解决的就是特征金字塔的问题。对于采用金字塔结构的CNN来说,可以通过提取它的1/4,1/8,1/16和1/32特征送入FPN来构建特征金字塔;但ViT采用同质架构,这使得ViT只能得到一种尺度(1/16)的特征。为了解决这个问题,论文提出了一种简单的方法来从ViT中构建特征金字塔,如下图右所示: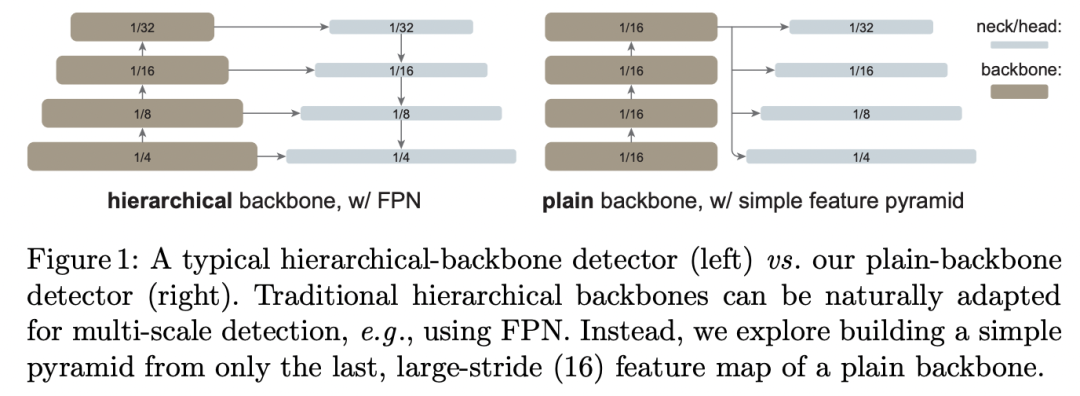 ViT的最后一层特征的大小是1/16尺度(这里ViT的patch size=16x16,论文中所有ViT模型均是如此),然后直接通过strides={2, 1, 1/2, 1/4}的卷积来产生多尺度的特征:1/32,1/16,1/8和1/4。具体地,stride=2时采用stride=2的2x2 maxpooling;stride=1时不进行任何操作即采用identify;stride=1/2时采用stride=2的2x2反卷积;而stride=1/4时采用2个连续的stride=2的2x2反卷积,两个反卷积之间增加LN+GeLU。代码实现如下所示:
ViT的最后一层特征的大小是1/16尺度(这里ViT的patch size=16x16,论文中所有ViT模型均是如此),然后直接通过strides={2, 1, 1/2, 1/4}的卷积来产生多尺度的特征:1/32,1/16,1/8和1/4。具体地,stride=2时采用stride=2的2x2 maxpooling;stride=1时不进行任何操作即采用identify;stride=1/2时采用stride=2的2x2反卷积;而stride=1/4时采用2个连续的stride=2的2x2反卷积,两个反卷积之间增加LN+GeLU。代码实现如下所示:
self.stages = []
use_bias = norm == ""
for idx, scale in enumerate(scale_factors):
out_dim = dim
if scale == 4.0:
layers = [
nn.ConvTranspose2d(dim, dim // 2, kernel_size=2, stride=2),
get_norm(norm, dim // 2),
nn.GELU(),
nn.ConvTranspose2d(dim // 2, dim // 4, kernel_size=2, stride=2),
]
out_dim = dim // 4
elif scale == 2.0:
layers = [nn.ConvTranspose2d(dim, dim // 2, kernel_size=2, stride=2)]
out_dim = dim // 2
elif scale == 1.0:
layers = []
elif scale == 0.5:
layers = [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
raise NotImplementedError(f"scale_factor={scale} is not supported yet.")
layers.extend(
[
Conv2d(
out_dim,
out_channels,
kernel_size=1,
bias=use_bias,
norm=get_norm(norm, out_channels),
),
Conv2d(
out_channels,
out_channels,
kernel_size=3,
padding=1,
bias=use_bias,
norm=get_norm(norm, out_channels),
),
]
)
layers = nn.Sequential(*layers)
stage = int(math.log2(strides[idx]))
self.add_module(f"simfp_{stage}", layers)
self.stages.append(layers)
直接对最后一层的1/16特征进行4个不同的操作之后,就可以得到4个不同尺度的特征,然后每个尺度特征再经过1x1 conv + LN + 3x3 conv来转换到同一特征维度(这里采用256),从而完成特征金字塔的构建。可以看到,与层级的CNN+FPN相比,这种简单的方式不需要自上而下的结构以及横向连接,更简单了。论文也提出了其它的一些构建方式,如下图中的(a)和(b),其中图(a)是论文的第一个版本所采用的方案,它是完成模仿层级CNN+FPN这种方式:直接将ViT的transformer blocks均分为4个部分,分别用1/4,1/2,3/4和4/4位置处得到的特征来得到1/4,1/8,1/16和1/32尺度的特征(通过上采样和下采样),然后送入FPN。而图(b)是进一步简化了图(a),这里直接用最后一层输出通过下采样或者上采样来得到4个尺度特征,然后送入FPN。而图(c)就进一步做了简化,直接去掉了FPN,这也就是最后所采用的简化方式。
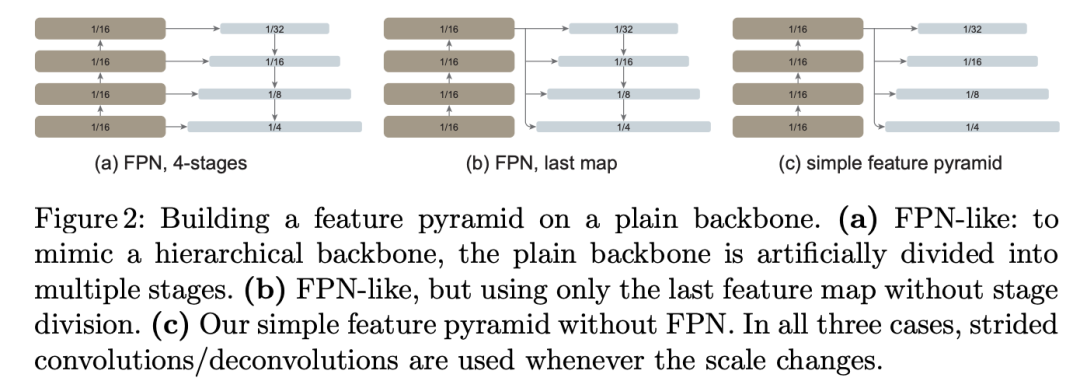 论文也对几种方式做了对比实验,如下表所示,可以看到采用特征金字塔效果是要明显优于单尺度模型的(直接用ViT的最后的1/16特征进行检测,这其实Faster R-CNN论文最早采用的方式,但是RPN放置了多尺度的anchors)。而采用最简单的方式效果并不比带FPN的(a)和(b)方式差,这说明FPN对ViT并不起效,这不难理解,FPN是为层级的CNN所设计,而ViT采用同质结构,所有层的特征分辨率是一样的,并没有必要再利用中间的特征来构建特征金字塔了。
论文也对几种方式做了对比实验,如下表所示,可以看到采用特征金字塔效果是要明显优于单尺度模型的(直接用ViT的最后的1/16特征进行检测,这其实Faster R-CNN论文最早采用的方式,但是RPN放置了多尺度的anchors)。而采用最简单的方式效果并不比带FPN的(a)和(b)方式差,这说明FPN对ViT并不起效,这不难理解,FPN是为层级的CNN所设计,而ViT采用同质结构,所有层的特征分辨率是一样的,并没有必要再利用中间的特征来构建特征金字塔了。 ViT用于检测模型的第二个挑战是计算效率问题,ViT中self-attention的计算量和图像大小的平方成正比,而检测模型往往需要较大的图像分辨率(224x224 -> 1024x1024),这会使得模型计算量爆炸,不仅导致训练速度变慢,而且显存消耗非常大。论文采用的优化思路是将ViT采用的global attention换成局部的window attention,这里的window size和ViT预训练的特征图大小设置为一样:14x14(ViT预训练的图像大小是224x224,此时特征图大小就为224/16=14),这样做的好处可以直接采用重新设计预训练而直接采用原生ViT的预训练权重。采用window attention虽然大大降低了模型的计算量,但是各个windows之间就缺少了信息交流,一种解决方案是像swin transformer那样采用shifted window,不过论文采用了更简单的方法:将ViT的blocks均分成4个部分,然后每个部分的最后一个block上采用一些特定的传播策略来实现跨windows间的信息交互。这里共考虑两种策略:
ViT用于检测模型的第二个挑战是计算效率问题,ViT中self-attention的计算量和图像大小的平方成正比,而检测模型往往需要较大的图像分辨率(224x224 -> 1024x1024),这会使得模型计算量爆炸,不仅导致训练速度变慢,而且显存消耗非常大。论文采用的优化思路是将ViT采用的global attention换成局部的window attention,这里的window size和ViT预训练的特征图大小设置为一样:14x14(ViT预训练的图像大小是224x224,此时特征图大小就为224/16=14),这样做的好处可以直接采用重新设计预训练而直接采用原生ViT的预训练权重。采用window attention虽然大大降低了模型的计算量,但是各个windows之间就缺少了信息交流,一种解决方案是像swin transformer那样采用shifted window,不过论文采用了更简单的方法:将ViT的blocks均分成4个部分,然后每个部分的最后一个block上采用一些特定的传播策略来实现跨windows间的信息交互。这里共考虑两种策略:
Global propagation:每个部分的最后一个block不再采用window attention,而是采用原始的global attention; Convolutional propagation:每个部分的最后加上一个residual conv block,它包括1个或者多个卷积层(比如采用1x1 conv + 3x3 conv + 1x1 conv的bottleneck结构)和一个shortcut,如果我们将这个block的最一个conv层初始化为0,那么这个block的初始状态就是一个identify,这意味着不会影响预训练模型的初始状态。
由于global attention具有全局性,所以Global propagation是可以实现跨windows间的信息传递;虽然卷积是局部操作,但是它也却能联通相邻的windows边缘像素,通过后面的window attention就可以实现所有像素的连接。其中window attention + Global propagation结构示意图如下所示(这里采用的是 FPN 4-stage,第一个论文版本中的图):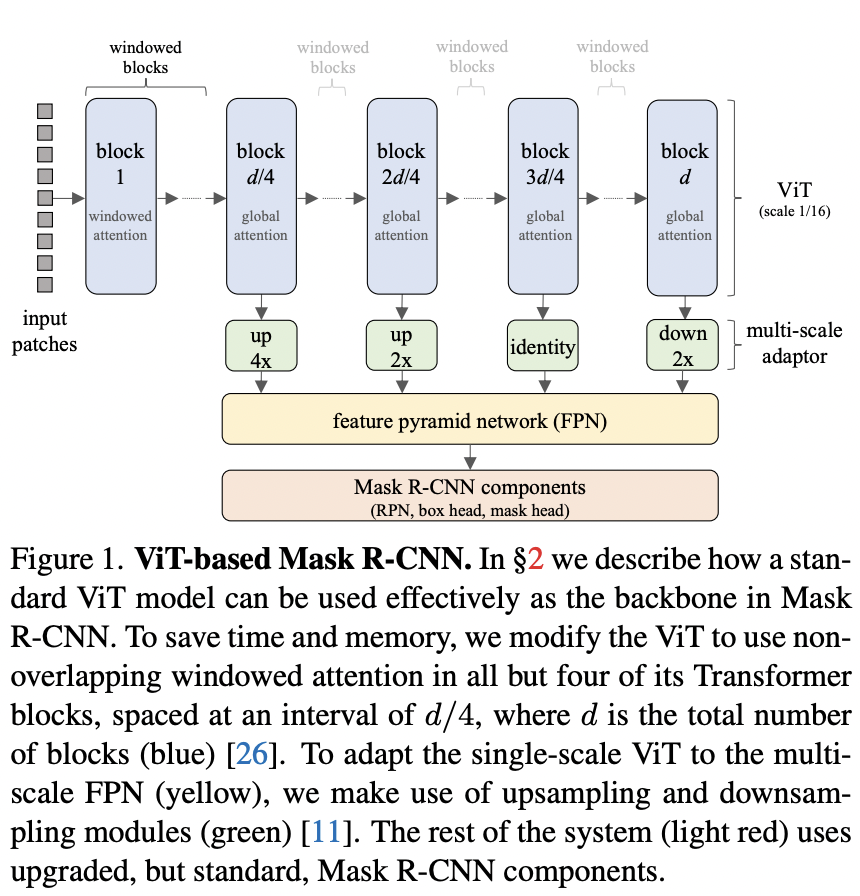
下表为不同方案的对比效果,其中none指的是只采用window attention,此时效果是最差的;而在window attention的基础上采用Global propagation(4 global)或者Convolutional propagation(4 conv, bottleneck)均可以得到较好的结果,而且训练显存和测试时间增加较少。如果所有的blocks均采用global attention(24 global,即最原始的ViT)虽然可以取得更好的结果,但是训练显存和测试时间均大幅度增加,对于ViT-L模型需要49GB的显存,如果不进行显存优化,单卡的A100也无法训练一张图像。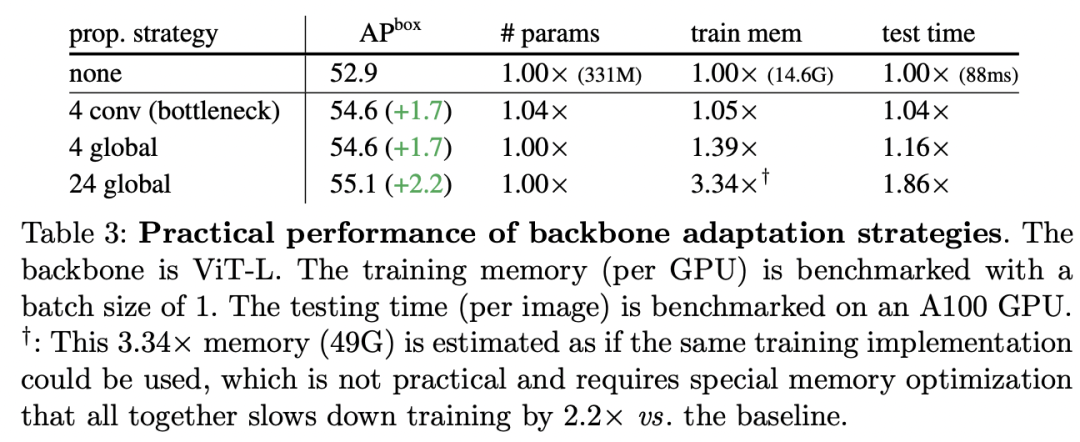 除此之外,论文还有更详细的对比实验,如下表所示:(a)中和shifted window做了对比,可以看到并不比global propagation和conv propagation更有效;(b)中对比了不同conv block类型,差别并不是特别明显;(c)对了global propagation中的global attention的位置,均匀地放置或者放置最后4个block均可以取得较好的结果,但是在最前4个block效果就差一些,因为在后面的windows间就缺乏信息传递了;(c)对比了global attention数量对模型效果的影响。
除此之外,论文还有更详细的对比实验,如下表所示:(a)中和shifted window做了对比,可以看到并不比global propagation和conv propagation更有效;(b)中对比了不同conv block类型,差别并不是特别明显;(c)对了global propagation中的global attention的位置,均匀地放置或者放置最后4个block均可以取得较好的结果,但是在最前4个block效果就差一些,因为在后面的windows间就缺乏信息传递了;(c)对比了global attention数量对模型效果的影响。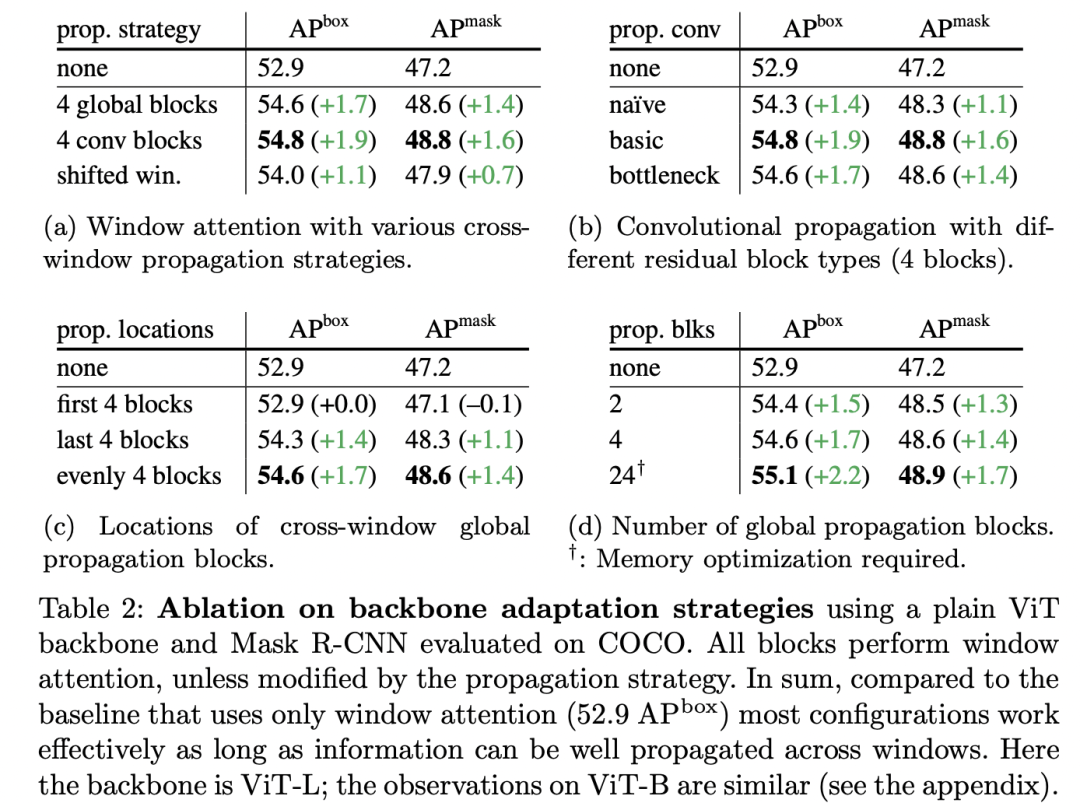 除了结构上的改进,预训练策略对ViTDet性能有较大的影响,如下表所示,随机初始化效果要比有监督预训练模型要好,而采用无监督MAE预训练模型可以大幅度提升效果。
除了结构上的改进,预训练策略对ViTDet性能有较大的影响,如下表所示,随机初始化效果要比有监督预训练模型要好,而采用无监督MAE预训练模型可以大幅度提升效果。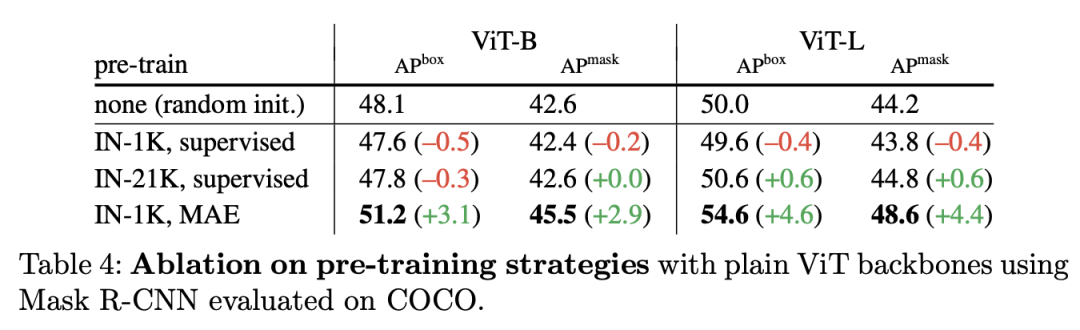 第一个版本论文给出了不同预训练策略下不同epoch下的性能曲线,可以看到虽然有监督预训练模型收敛速度比随机初始化快,但是也出现了更早的收敛,当训练时长较长时,随机初始化反而能得到更好的性能(heavy的数据增强+较长的训练时长往往不需要预训练模型)。相比之下,MAE预训练模型表现了更好的收敛和性能。
第一个版本论文给出了不同预训练策略下不同epoch下的性能曲线,可以看到虽然有监督预训练模型收敛速度比随机初始化快,但是也出现了更早的收敛,当训练时长较长时,随机初始化反而能得到更好的性能(heavy的数据增强+较长的训练时长往往不需要预训练模型)。相比之下,MAE预训练模型表现了更好的收敛和性能。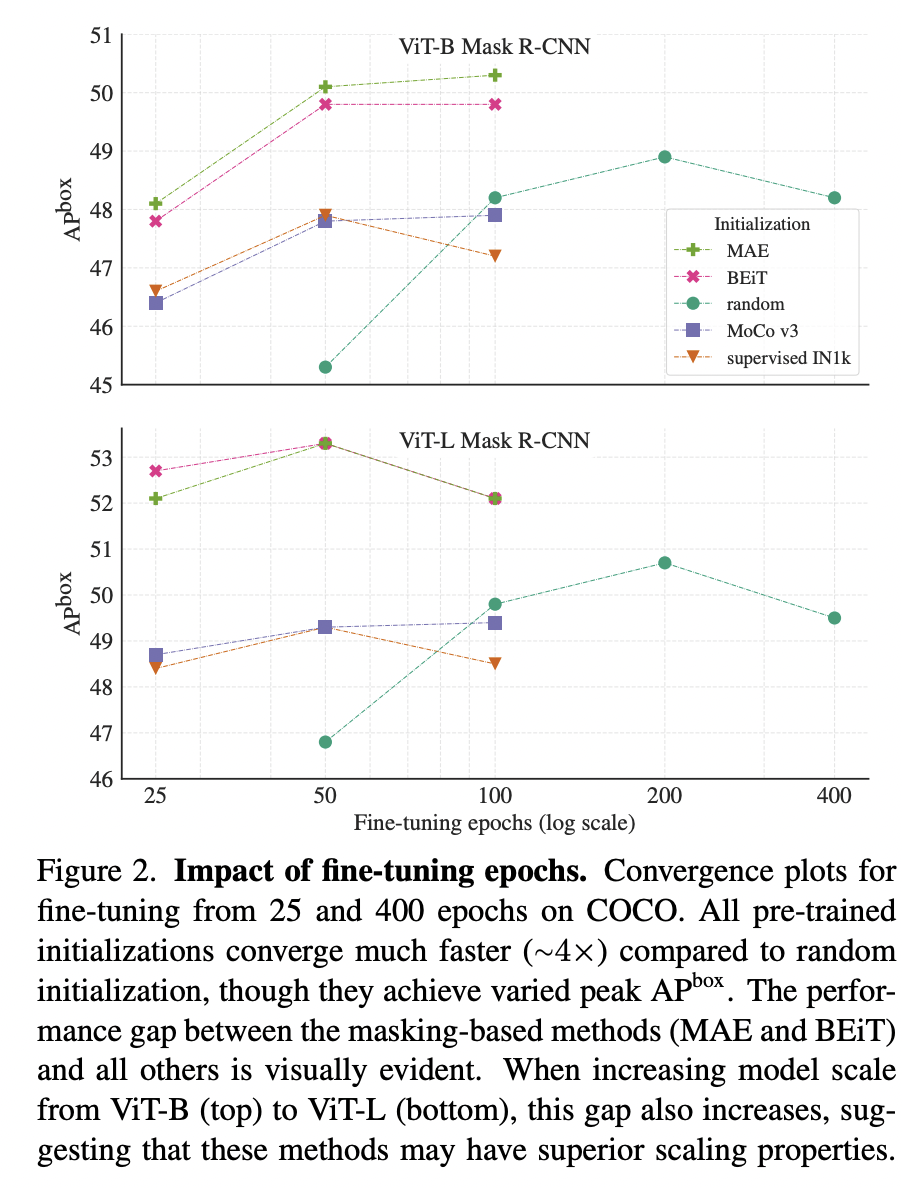
对比实验
论文中主要有两个主要的对比实验,第一个就是ViTDet和其它基于层级backbone的检测模型对比,这里选择了两个backbone:Swin和MViTv2,它们均采用和CNN一样的金字塔结构,检测的neck采用FPN。这里的检测模型采用两个架构:Mask R-CNN和Cascade Mask RCNN。Swin和MViTv2均使用了relative position bias,所以为了公平对比,也在ViT中增加了relative position bias(只是finetune时增加),这里的策略和MViTv2相同(和Swin略有不同)。对比结果如下所示,可以看到对于较小的模型ViT-B,它能和同量级的Swin-B和MViTv2-B取得相似的性能,但是对于更大的模型ViT-L和ViT-H,其效果要更好一点。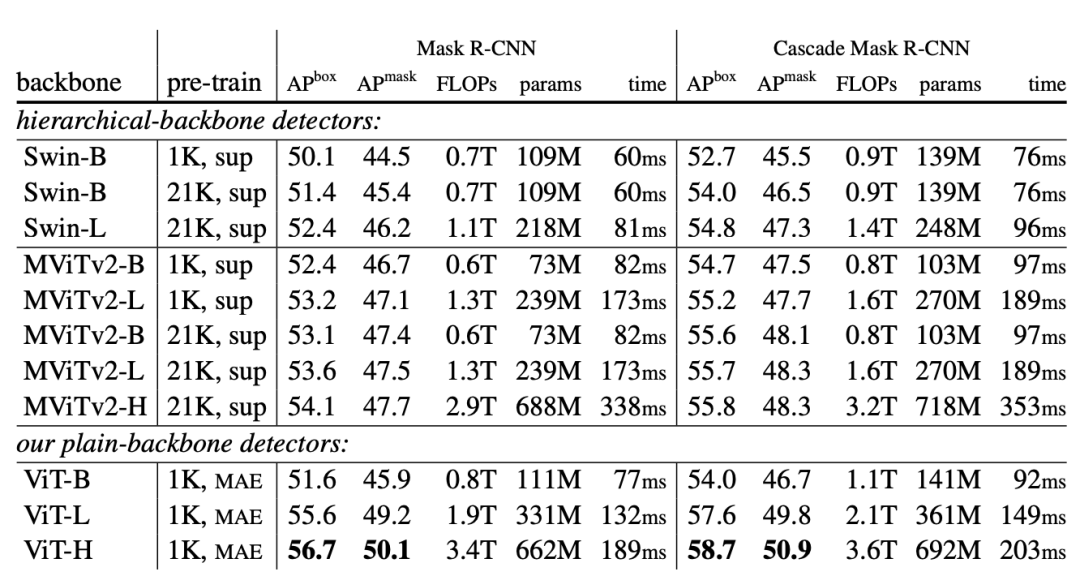 下图给出了AP和模型参数量,FLOPs和测试时长的关系图,可以更明显地看出ViTDet的优势:
下图给出了AP和模型参数量,FLOPs和测试时长的关系图,可以更明显地看出ViTDet的优势: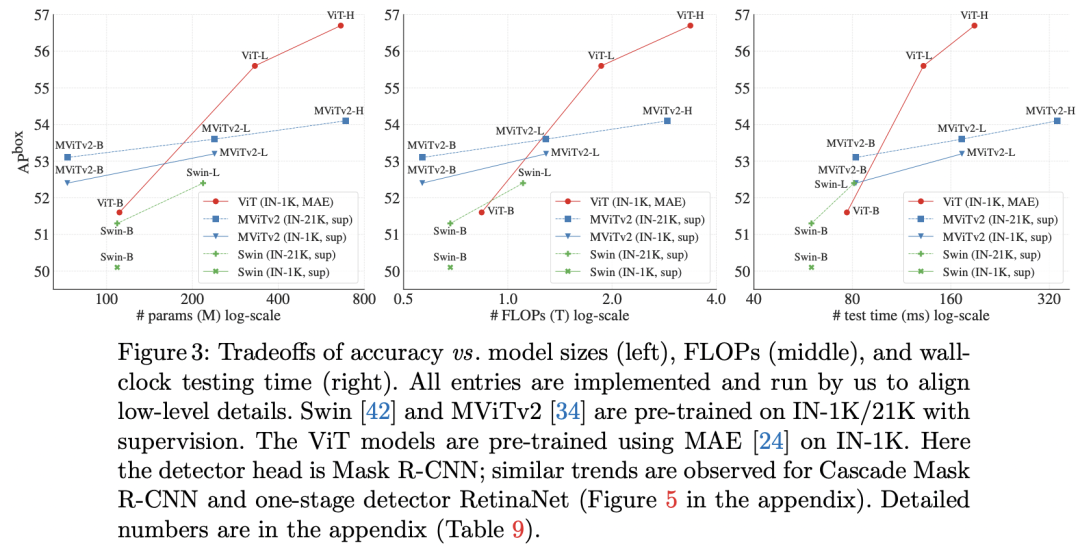 另外,论文还补充了基于one-stage的检测模型RetinaNet的对比,和Mask R- CNN模型的趋势一致。
另外,论文还补充了基于one-stage的检测模型RetinaNet的对比,和Mask R- CNN模型的趋势一致。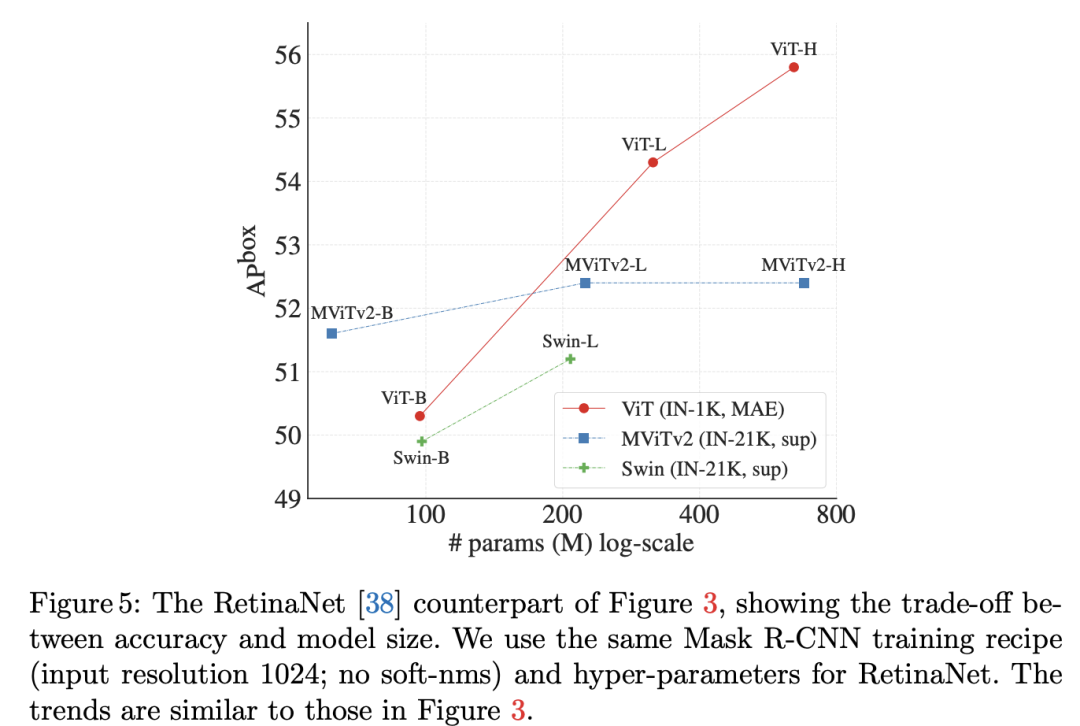
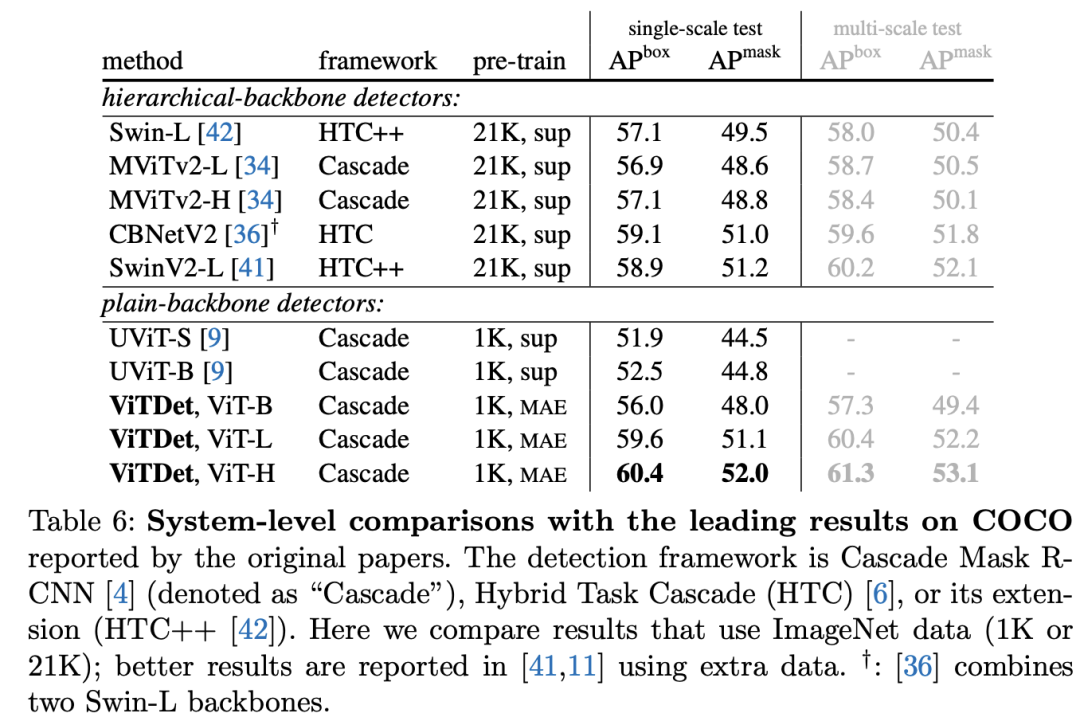
第二个对比是和其它SOTA模型的对比,这里做了两个改进,一是采用soft-nms,二是将输入图像大小从1024增加到1280。对比结果如下表所示,其中基于ViT-H的ViTDet采用mutli-scale测试能达到61.3的box AP,稍差于现在的SOTA模型DINO(63.3)。
小结
ViTDet这个工作系统地探讨了如何将ViT更好地应用在下游检测任务,它不直接对改变原生ViT的预训练过程,而是在适应下游任务上做适当地改进,并实现了和层级ViT模型类似甚至更好的性能,而且也证明了MAE预训练对性能的提升所起到的巨大作用。
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
