
Apache Spark 完全替代传统数仓的技术挑战及实践
共 6317字,需浏览 13分钟
·
2021-08-18 21:10
7月30日,由 Kyligence 主办的 Data & Cloud Summit 2021 行业峰会在上海成功举办,此次峰会特设「开源有道」分论坛,邀请了来自 Apache Kylin,Apache Spark,Alluxio,Linkis,Ray 以及 MLSQL 等开源社区的技术大佬,分享了目前开源社区关于大数据、机器学习等多个热门话题的前沿技术和最佳实践。来自 eBay 数据团队的马刚分享了他们在用 Apache Spark 完全替代传统数仓中遇到的技术挑战及改进等话题,引起了现场观众的热烈讨论。
以下为马刚在大会演讲实录
大家好!我叫马刚,来自 eBay 的大数据团队,很高兴今天有机会在这里分享我们团队在过去 2 年做的工作,主要是基于开源的 Spark 和 Hadoop 替换掉传统数据仓库。今天我会讲到我们在用 Apache Spark 替换传统的数据仓库中遇到的技术挑战,以及我们怎么解决的。
今天我分享的 Agenda 如下:
系统介绍
技术挑战
- 功能性改进
- 性能改进
- 稳定性改进
总结
系统介绍
我们这个系统的名字叫 Carmel,它是基于开源的 Hadoop 和 Spark 来替换传统的数据仓库,我们是 2019 年开始做我们这个项目的,当时是基于 Spark 2.3.1,最近刚刚升到 Spark 3.0。面临的主要技术挑战,第一个是功能方面的缺失,包括访问控制,还有一些 Update 和 Delete 的支持;在性能方面跟传统数仓,特别是交互式的分析查询中性能方面存在较大差距,还有一些稳定性的问题。
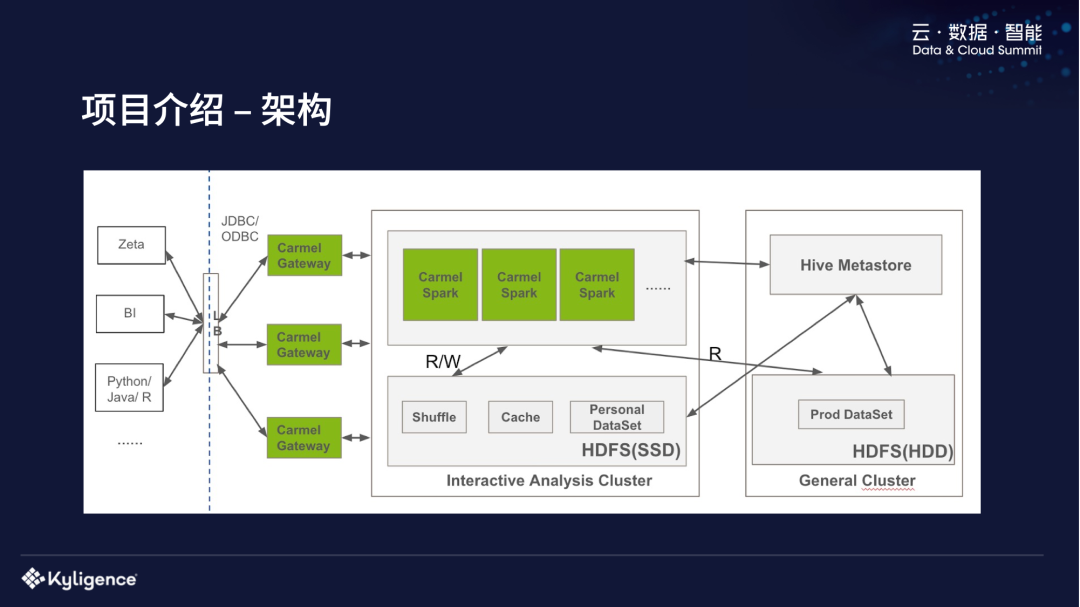
这是 Carmel 系统的整体架构,比较简单,可以看到我们自己开发了 ODBC 和 JDBC driver,对接一些 BI 工具,用户可以直接用 Python 或者 Java 来连我们的系统。中间是 Gateway,用来做用户认证以及权限检查,之后会把用户的 SQL 请求发到一个分析查询的集群。这里有两个集群,一个是我们主要使用的分析集群,另外一个是 eBay 内部比较通用的 Hadoop 集群,是用来跑大量的 Spark 或者 MapReduce 的任务,包括一些机器学习任务等,比较忙。
这个分析集群主要是服务于 eBay 内部的分析师,我们 Spark 也是跑在 YARN 上面,不同的部门会切不同的 Queue,这些不同部门的请求之后会分到对应 Queue 的 Spark Driver,是一个 long running 的服务,它是一直启动着的,给所有部门的用户,所有 SQL 都是它提供服务,去解析、去进行执行的。这个分析集群是 SSD 存储,存储的性能比较好。上面主要是存一些 Spark Shuffle 和 Cache 的数据,以及分析师个人的数据集。这个分析集群的 Spark Driver 还可以共享集群的 HDFS 数据,让用户也可以直接分析生产的一些数据集,这个分析的集群跟 General 集群是共享一个 Hive Metastore 的,表是可以互相访问的。
功能改进
接下来我会讲在功能性的改进方面做了哪些工作。
访问控制

第一是访问控制,前面提到我们有一个 Gateway 的服务器负责做一些用户权限认证,还有对一些集群和 Queue 的访问控制。我们通过一个系统账户来读写 HDFS,个人账户不能直接访问 HDFS,来避免一些安全方面的问题。对于一些数据库或者表级别的访问权限控制,我们是基于 SQL 来做访问控制,类似于传统数据库的访问控制 SQL 语句,例如 Grant、创建 Role 等。用户也是通过 view 来进行列级别的访问控制,可以针对每一个物理表建立不同的 view,让某些用户只能访问一些不敏感的列。
对 Update/Delete 支持
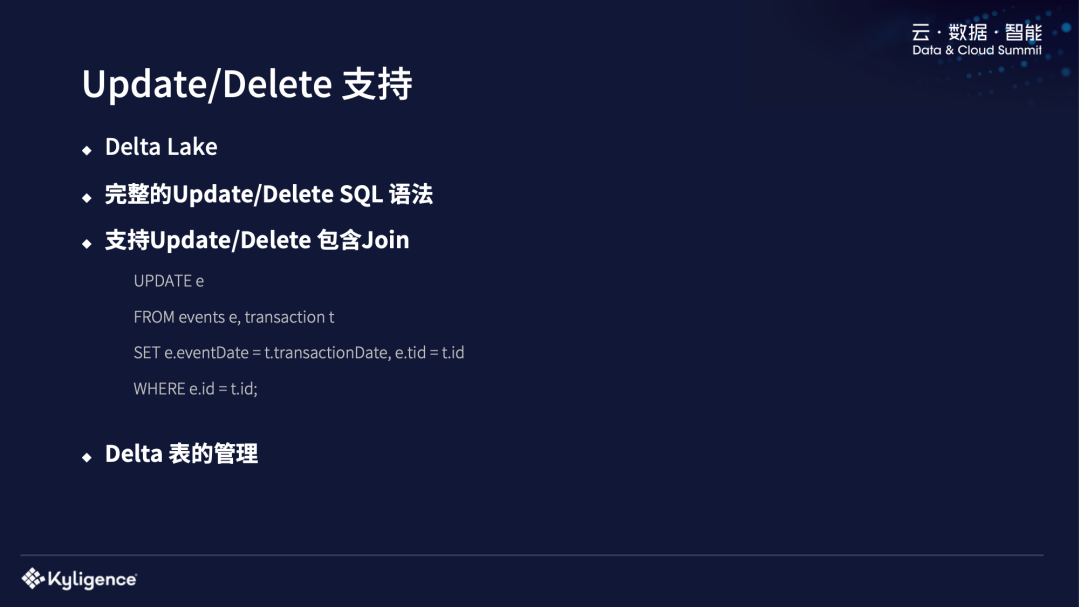
我们是基于 Delta Lake 来做 Update 和 Delete 的支持。刚开始做的时候是基于 0.4 的版本,现在升级到了最新版本。Delta Lake 当时只支持 Dataframe 的接口,我们提供了 Update/Delete 的 SQL 语法的支持,还支持了比较先进的传统数仓中会支持 Update/Delete with Join 语法。还有就是 Delta 表的管理,我们这个系统是基于 Hadoop 的,大家知道 Hadoop 最怕小文件,但是 Delta Lake 的特点就是每次都会创建比较多的小文件出来,会使 Hadoop 系统不是很稳定,我们会定期地去清除老版本的 Delta 文件,做一些 Delta 表的管理工作。
上传下载 API

我们还对一些缺失的功能进行了改进,比如上传下载的 API。用户经常会把一些外部数据传到数仓里面去做分析,比如对一些社交媒体的数据进行分析,我们需要支持这种上传 CSV 文件到某个表或者某个表的分区。其次就是下载,用户经常会用一些 BI 工具,比如 Tableau 或者 MicroStrategy 去做分析,这种分析工具经常会需要下载比较大规模的结果集到工具本身去进行操作,比如构建一些本地的 Cube 等,而且我们线上发现用户经常会下载 100G 到 200G 的数据到本地。Spark 原生的一些 API、thrift API 的性能是比较差的。我们也自己实现了一些下载的 API,来提升性能,把那些 Parquet 文件直接下载到文地,通过 ODBC driver 去迭代本地的 Parquet 文件,来提高它的性能。经过我们测试,通过这种方式去访问超大的数据集会比传统的 Thrift API 快 3 - 4 倍,因为减少了大量的 RPC 调用,还有每条记录的序列化、反序列化的开销。
其他新功能
我们还增加了很多其他新功能,比如支持 Volatile table,因为 Spark 社区版只支持一个 Temporary view,只定义一个 SQL,不会 materialized 到存储中去。传统数仓其实有这种功能,用户写的时候经常会建了很多 tmp table,把 tmp table 迁到 Spark 中去,如果直接用 Temporary view 来代替的话,最后生成的 SQL 执行计划会非常复杂,性能会非常差。
我们也实现了对 like any/like all 的支持,还有对压缩表的支持,主要也是解决 Hadoop 中一些小文件的问题,把小文件压缩成一些比较大的文件。
性能改进
接下来我会介绍我们在性能改进方面所做的一些工作。
性能改进 - 透明数据缓存
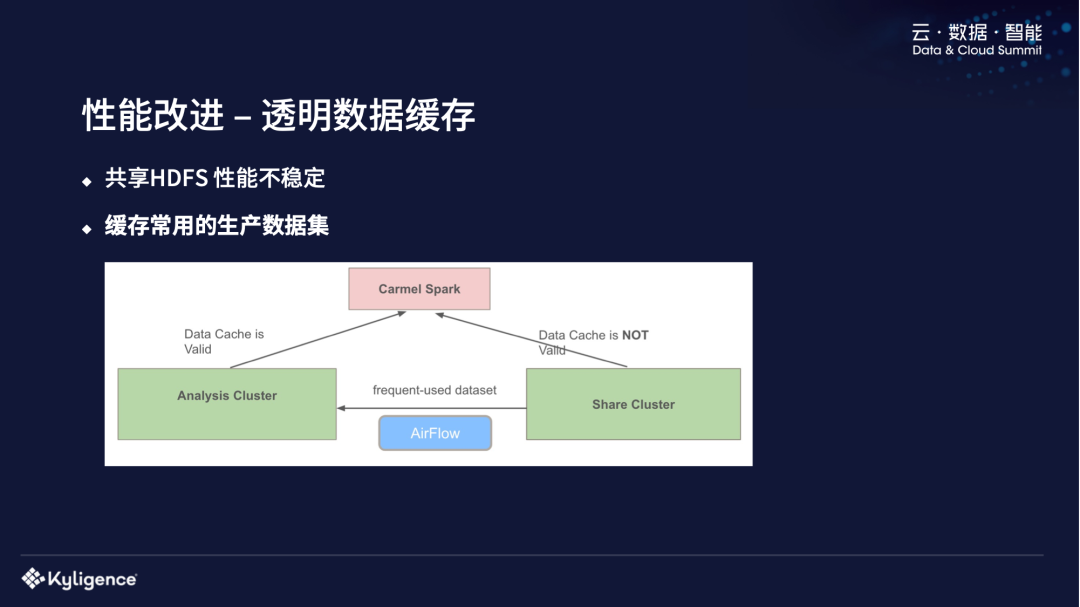
第一个,透明的数据缓存,前面介绍过我们系统的架构里面有 2 个 HFDS,一个是分析集群的 HDFS、一个是共享集群的 HDFS,共享集群的 HFDS Load 比较高,经常会跑一些机器学习的任务。如果用户要访问共享集群的 HDFS,经常会不稳定。比如说共享的 Namenode 不稳定,或者是后面的 Datanode 不稳定,会时快时慢。我们对常用的生产数据集做了数据缓存,会定期把这些常用数据集从共享集群复制到分析集群。用户分析的时候,生成物理执行计划的时候会把这些 HDFS 文件透明替换掉,用户是感知不到你在后面做了缓存的。
性能改进 - 索引
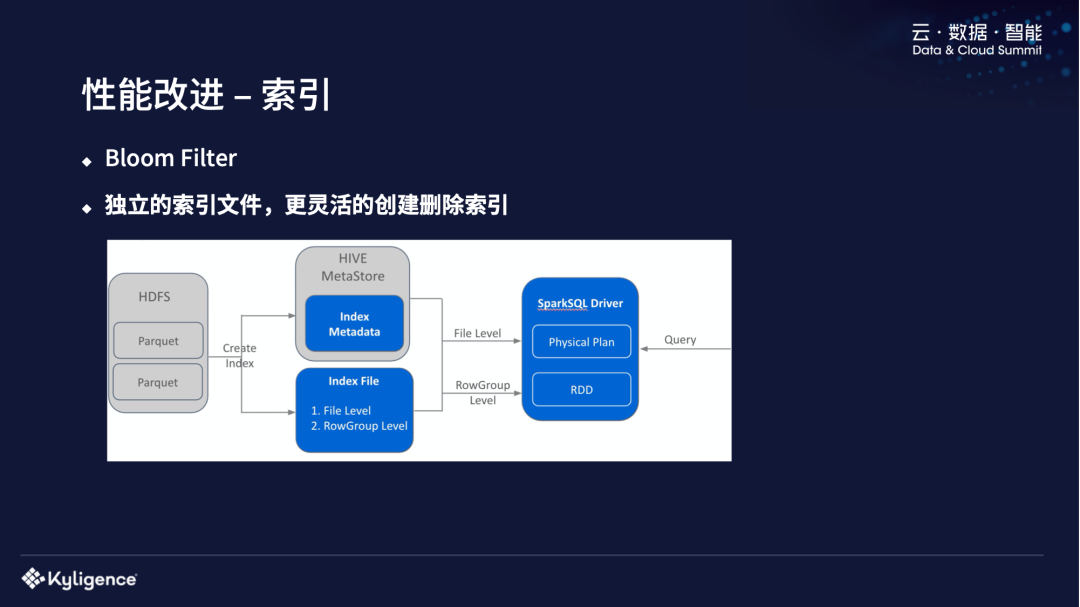
我们也做了一个 Bloom Filter 索引,因为我们线上还是有一些查询是点查的场景,从非常大的数据集中,最后结果只需要一点点的数据,这时候我们可以建一些索引。我们这个索引是单独的一个索引文件,跟数据文件是分开的,所以可以比较灵活地根据用户的需求,在表的不同列上建索引、删除索引。同时,我们提供了建索引的 SQL 语法,就跟普通的 OLTP 建索引的语法类似。我们也测试了一些比较常见的点查场景,在 80%-90% 的场景下,IO 和 CPU 使用降低比较多。
性能改进 - AQE
我们也对 AQE 进行了一些性能改进。之前提到我们系统最开始是基于 Spark 2.3.1 的,AQE 是 Spark 3.0 的时候引进来的,所以我们把 AQE Backport 进我们版本里面去了。AQE 对我们所在的场景的性能提升是非常重要的。我们是一个共享的 Spark Driver,用户是没办法设定 Spark 参数的,比如 shuffle partition 的数量都是固定的。在 AQE,你可以做 partition 数量的 coalesce,把一些小的 partition 压成一个大的 partition。还有就是把 SortMergeJoin 转成 BroadcastJoin 去处理一些 Skew Join 的 Case。在社区版本的 Spark 中的 Skew Join 的场景是比较简单的,两边是 shuffle stage,中间是一个 SortMergejoin,为了处理这种场景,我们做了更多改进。
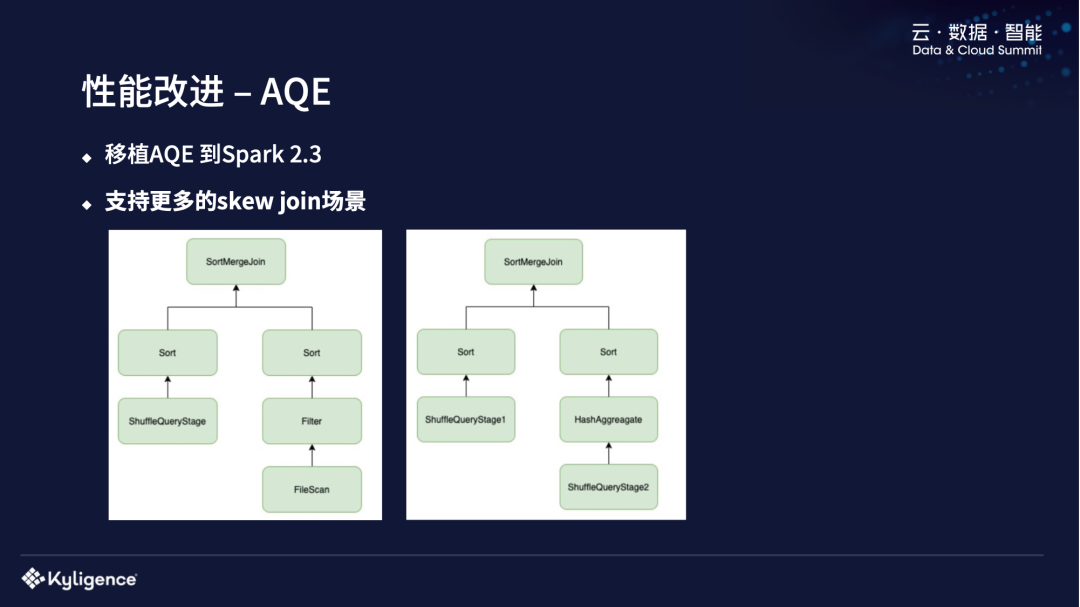
比如说第一个式子中,单个 Querystage,右边是一个 Parquet 表,他是没有 shuffle 在的。第二种不是这种比较经典的两个 shuffle stage,是后面加 sort 的,可能中间还有一些别的算子比如 Aggregation 算子,SortMergeJoin 等。
性能改进 - Bucket Join
我们做的另外一个性能改进是 Bucket Join,一些倍数关系的 Bucket 表的 join 是不用 shuffle 的。
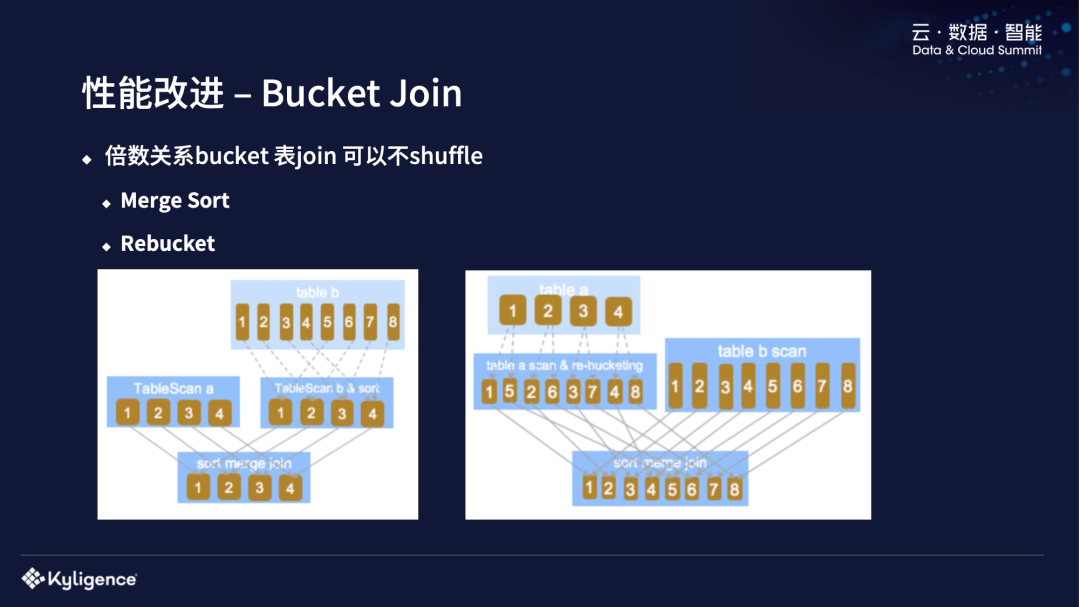
我们现在支持两种不用 shuffle 的方式,一种是 Merge Sort,把多的并到小的,把 Table A 和 Table B 进行 Join,左边表的 Bucket 数量是 4 个,右边 Bucket 数量是 8 个,可以按左边 4 个去做一个 Join,右边是不需要 shuffle 的。还有 Rebucket,相反的就把少变多,task 数量会变多。缺点可能在于会重复读数据,IO 会多一些,现在我们生产上是 enable merge sort 这种方式。
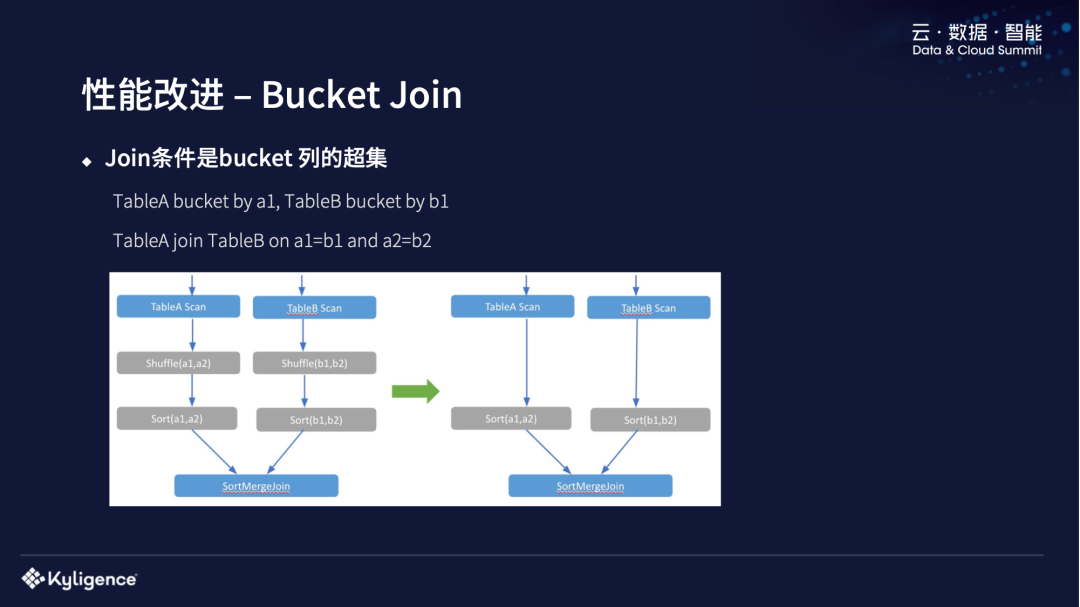
另外一个性能改进是 DPP,我们也把 Spark 3.0 中的 DPP 移植到 Spark 2.3 中,做了一些改进,使 DPP 和 AQE 可以协同工作。目前社区版 AQE enable 的时候,DPP 是没办法同时运行的。但是这两个功能对我们线上版本都还是很有用的,所以我们进行了一些改动,使它们可以同时工作。
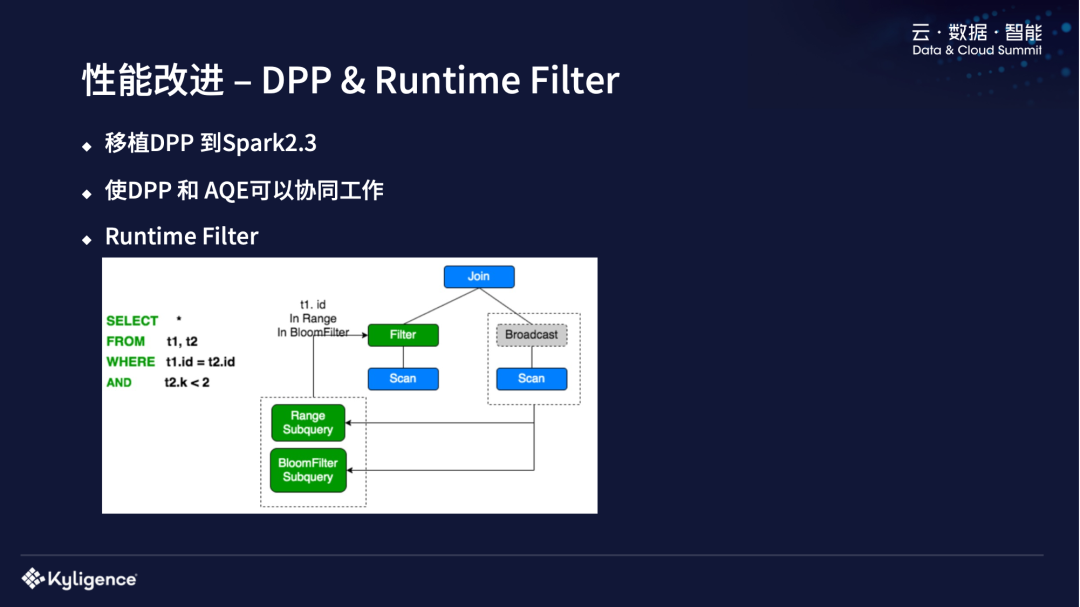
还有 Runtime Filter,它的原理和 DPP 类似,因为 DPP 要求你的 Join 条件中包含了 partition column 才会 enable 成 DPP,Runtime Filter 可以把一些非 partition 条件做一些 filter 放到左边,这对某些 case 比较有用,比如在右表很小、左表很大的情况下,如果 filter 效率比较高的话,可以使它的 shuffle 数据量减少非常多。
性能改进 - Range Join
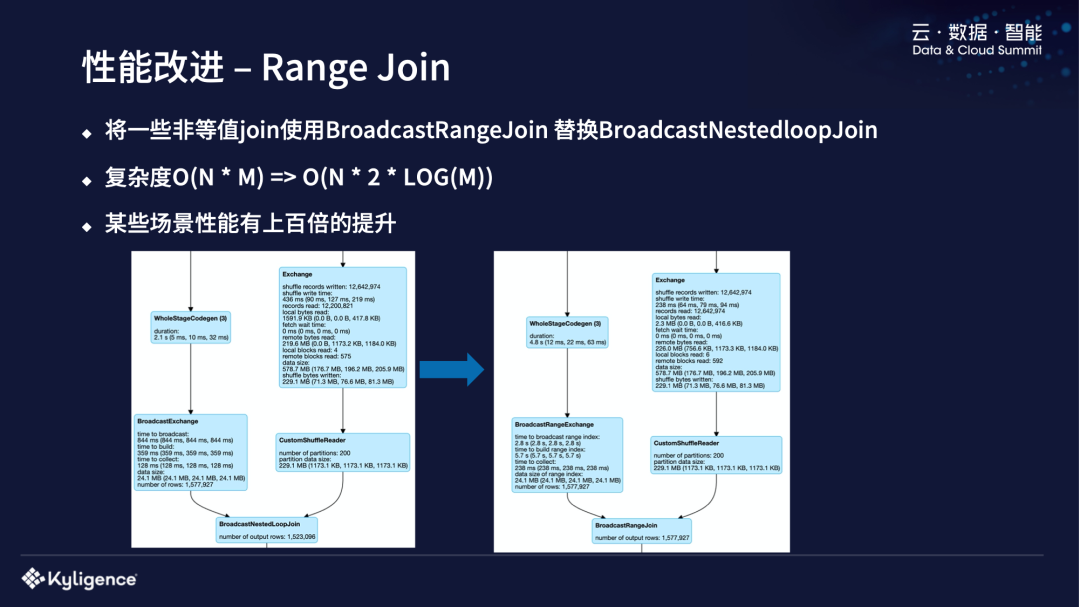
我们做的另外一个性能改进是 Range Join。目前我们线上大概每天有 2000 多个非等值的 Join,join 的条件里都是大于等于、小于等于或者是不等于这种条件,对这种Join,Spark 里面默认是用Broadcast NestedloopJoin,它的性能是比较差的,特别是对于Join和 Broadcast 的表都比较大,它的时间复杂度是 O(N*M)。我们对一些 Range join,比如 join 条件是 A Between B and C 这样的,我们会用 BroadcastRangeJoin,因为 Broadcast NestedloopJoin 会 Broadcast 那个小表,BroadcastRangeJoin 相当于是给那个小表做了索引,给它排个序,Join 时候就不需要每一条都扫描,只扫描一部分就可以了,他的复杂度就降为 O(N*2*LOG(M)),所以在某些场景下,性能会有上百倍的提升,比如左边有1000万,右边有100万 Join 的这种 Case。
Parquet 读优化

我们还做了一些对 Parquet 的读优化,主要是做了一些降低读 Parquet 文件时的 NameNode rpc 的调用,以及多线程读 Parquet 文件。为什么我们要用多线程去读呢?举个例子,在我们线上,有一个用户行为的表非常大,而且是一个 bucket 表,bucket 数量不能太多,数量太多的话会让 task 也非常多,系统非常忙。我们对这种 bucket 表进行扫描的时候,可能一个task要读的Parquet文件就非常多,这种 Hadoop 的“读”就成为查询的瓶颈了。对于这种场景,我们可以使用多线程去读 Parquet 文件。我们前面说了系统中有共享的集群,HDFS 本身不是很稳定,我们会使用多线程去读的话,会降低 HDFS 读等待的开销。还有下推更多的 filter 到 Parquet 文件。
其它性能改进
我们还做了其他方面的性能改进,比如调度性能改进,对 Spark 里 DAGScheduler 的改进等。因为我们是一个共享的 Spark Driver,很多用户对调度的要求比较高,希望 task 能够很快地调动起来,但是现有 Spark 社区版本里大部分都不是这种场景的,所以对调度的性能要求没那么高,我们做了很多异步化和多线程的改造。同时我们还做了 Spark Driver 里一些锁的优化,从比较大的锁粒度降到比较小的锁粒度。第三点是物化视图,目前这个功能已经完成,但是没有在线上用起来,因为还存在一些数据质量方面的问题,在物化视图更新这方面还没完善,所以说我们还在做。
稳定性改进
Driver 稳定性改进
接下来我会讲一下在稳定性方面的一些改进,主要讲Executor和Driver两个方面,很多用户需要Driver,Driver 是长期运行的一个服务,对稳定性要求非常高,我们做了以下改进:
大结果集溢写到磁盘;
限制最终结果集和中间结果集的大小;
Broadcast 的管理和限制。经过线上的跟踪,都是这个表太多引起内存的问题,我们对此进行了管理和限制;
单个 SQL 的 task 数量以及总 task 时间限制;
单次 table scan 的文件数和大小的限制;
SQL 优化阶段的限制;
Join 膨胀率的限制;
Spark UI 的分离;
DAGSchedule 线程模型改进。
Executor 稳定性改进
我们还做了一些 Executor 的稳定性改进,包括:
shuffle 内存控制;
UDF review/release 流程改进;
加各种限制保护 Executor 内存。
总结

最后,我简单做一个总结,上图是我们现在的一个系统状况。大概每天跑 30 多万个查询,80 分位的查询在 20 秒左右,95 分位是 100 秒左右,目前大概是这样的情况。